前言:在后端开发中,你是否遇到过这样的糟心场景?用户支付成功,余额扣了但订单却没生成;批量导入数据时突然断电,重启后部分数据重复、部分数据丢失……这些"数据翻车"的背后,几乎都藏着一个共同的漏洞——没用好 MySQL 事务。
如果把数据库比作一个繁忙的仓库,那数据操作就是工人搬运货物的过程。要是搬运到一半突然停电,货物扔在半路、货架空空如也,整个仓库就会陷入混乱。而 MySQL 事务,就是给这个搬运过程装了一道"安全锁":要么把所有货物完好地搬到位,要么一旦出问题就退回原点,绝不留下半拉子工程。今天我们就扒透事务的底层逻辑,教你用它把数据安全牢牢握在手里。
一、事务的概念以及使用场景
事务把一组SQL语句打包成为一个整体,在这组SQL的执行过程中,要么全部成功,要么全部失败。这组SQL语句可以是一条也可以是多条。
以一个转账例子为例:
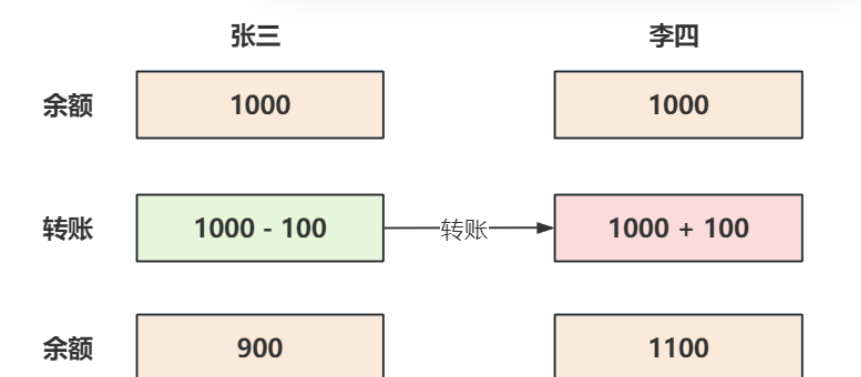
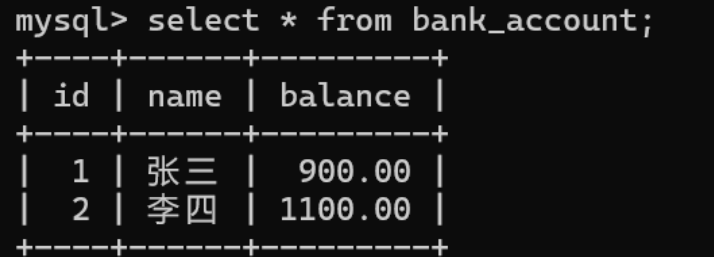
初始状态:
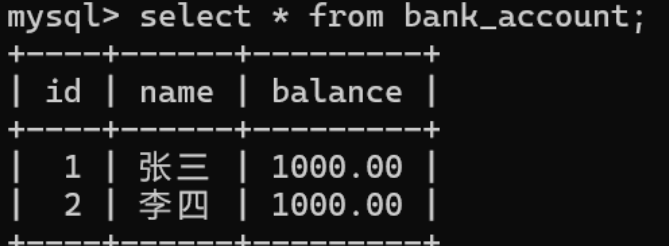
> 先进行张三余额减少100
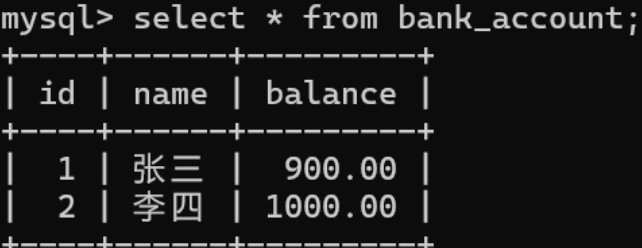
> 在进行李四余额增加100
如果转账成功,应该有以下结果:
1. 张三的账户余额减少 100 ,变成 900 ,李四的账户余额增加了 100 ,变成 1100 ,不能出现张三的余额减少而李四的余额没有增加的情况;
2. 张三和李四在发生转账前后的总额不变,也就是说转账前张三和李四的余额总数为1000+1000=2000 ,转账后他们的余额总数为 900+1100=2000 ;
3. 转账后的余额结果应当保存到存储介质中,以便以后读取;
4. 还有一点需要要注意,在转账的处理过程中张三和李四的余额不能因其他的转账事件而受到干扰;
> 这四点在事务的整个执行过程中必须要得到保证,这也就是事务的 ACID 特性
二、事务的ACID特性---数据安全的"四梁八柱"
事务的ACID特性指的是 Atomicity (原子性), Consistency (一致性), Isolation (隔离性) 和 Durability (持久性)。
2.1 Atomicity (原子性):
一个事务中的所有操作,要么全部成功,要么全部失败,不会出现只执行了一半的情况,如果事务在执行过程中发生错误,会回滚( Rollback )到事务开始前的状态,就像这个事务从来没有执行过一样;
2.2 Consistency (一致性):
在事务开始之前和事务结束以后,数据库的完整性不会被破坏。这表示写入的数据必须完全符合所有的预设规则,包括数据的精度、关联性以及关于事务执行过程中服务器崩溃后如何恢复;
2.3 Isolation (隔离性):
数据库允许多个并发事务同时对数据进行读写和修改,隔离性可以防止多个事务并发执⾏时由于交叉执行而导致数据的不一致。事务可以指定不同的隔离级别,以权衡在不同的应⽤场景下数据库性能和安全;
2.4 Durability (持久性):
事务处理结束后,对数据的修改将永久的写入存储介质,即便系统故障也不会丢失
三、为什么要使用事务?
事务具备的ACID特性,是我们使用事务的原因,在我们日常的业务场景中有大量的需求要用事务来保证。支持事务的数据库能够简化我们的编程模型, 不需要我们去考虑各种各样的潜在错误和并发问题,在使用事务过程中,要么提交,要么回滚,不用去考虑网络异常,服务器宕机等其他因素,因此我们经常接触的事务本质上是数据库对 ACID 模型的一个实现,是为应用层服务的。
四、那么该如何使用事务呢?
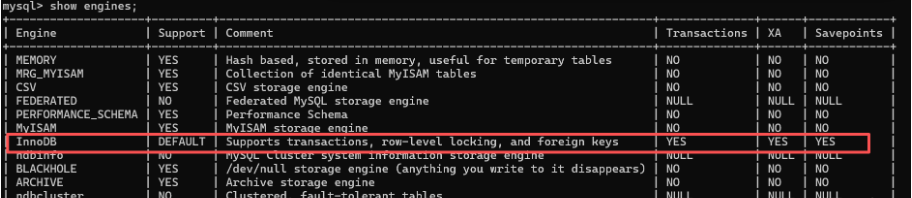
要使用事务那么数据库就要支持事务,在MySQL中支持事务的存储引擎是InnoDB,可以通过show engines;语句查看:
语法:
> 开始一个新的事务
> 提交当前事务,并对更改持久化保存
> 回滚当前事务,取消其更改
- START TRANSACTION 或 BEGIN 开始⼀个新的事务;
- COMMIT 提交当前事务,并对更改持久化保存;
- ROLLBACK 回滚当前事务,取消其更改;
- 无论提交还是回滚,事务都会关闭
开启一个事务,执行修改后回滚
开启事务

表中数据
执行sql使张三余额减少100
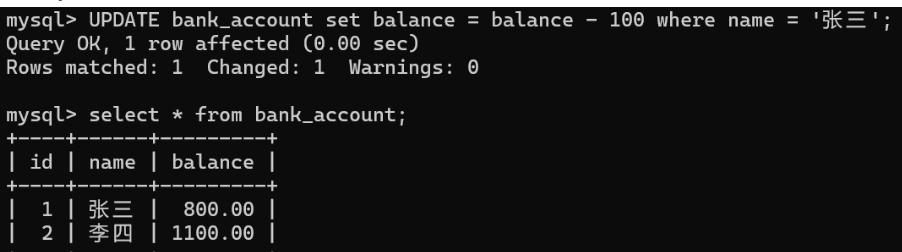
执行sql使李四余额增加100
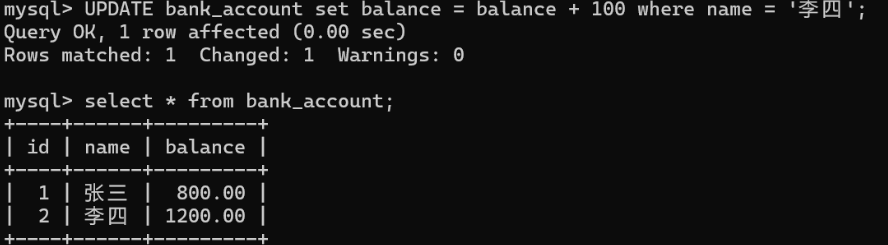
发现此时的余额相比之前已经修改了
> 执行回滚操作

发现回到了初始状态值
> 开启⼀个事务,执行修改后提交
开启事务,先查看表中的初始值
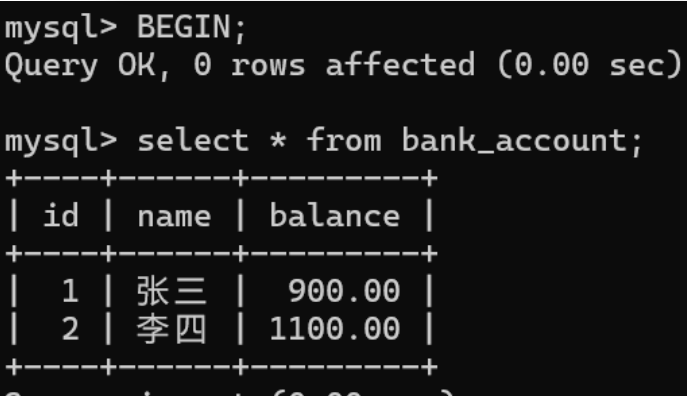
再次执行张三减100,李四加100操作

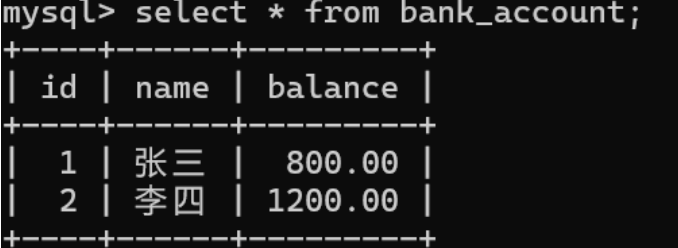
进行事务提交

再查询发现数据已被修改,说明数据已经持久化到磁盘
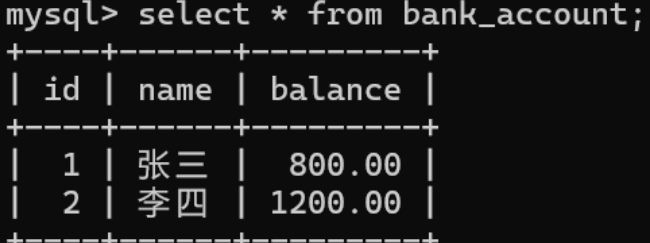
> 在事务执行的过程中设置保存点,回滚时指定保存点可以把数据恢复到保存点的状态
在次进行开启事务并对张三减100,李四加100操作
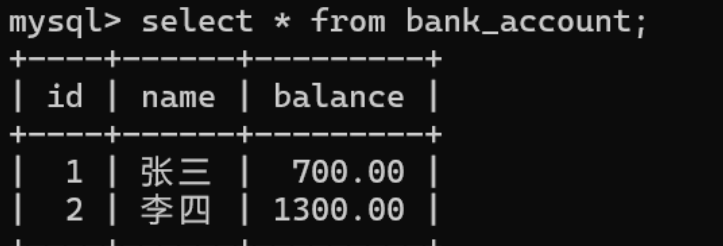
我们来设置保存点,看看最终效果如何
对张三减100,李四加100操作
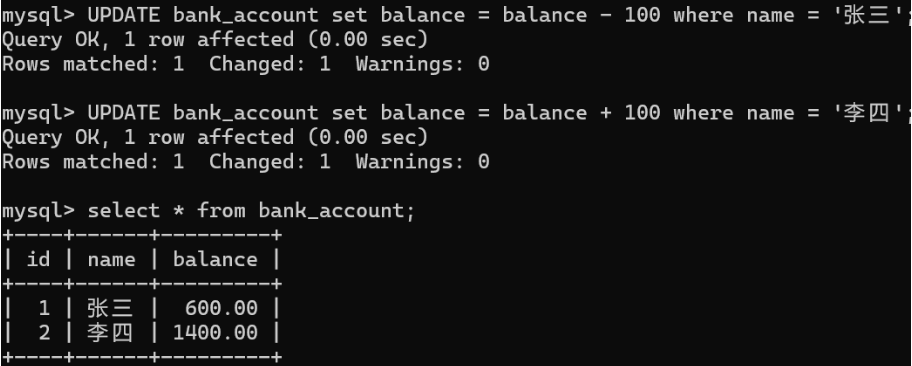
设置第⼆个保存点
插入一条新记录
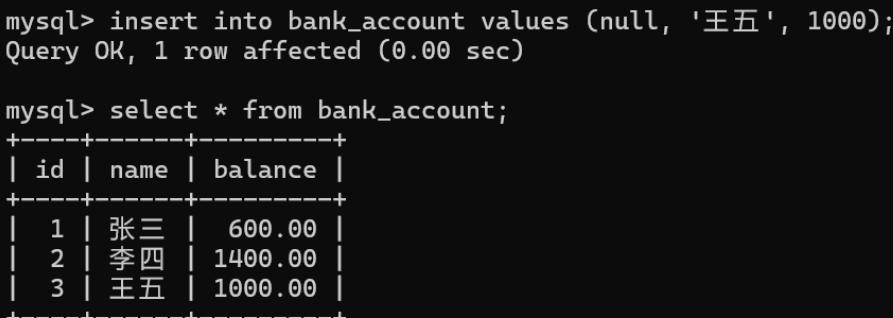
回滚到第二个保存点
发现回滚到了插入王五数据前
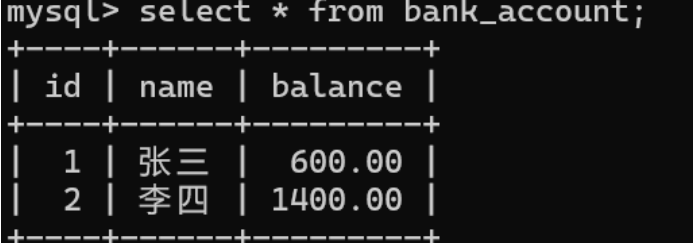
回滚到第⼀个保存点
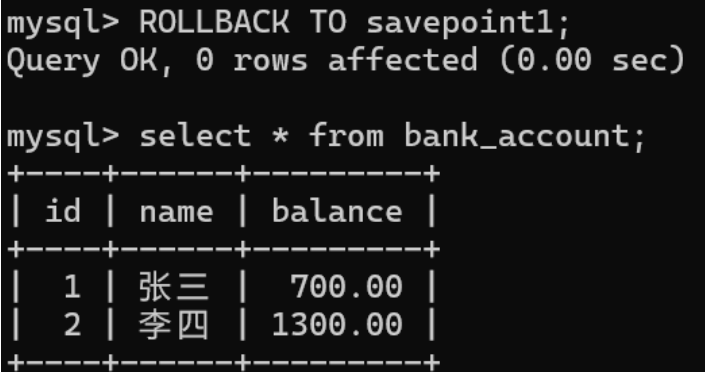
当回滚时不指定保存点,直接回滚到事务开始时的原始状态,事务关闭
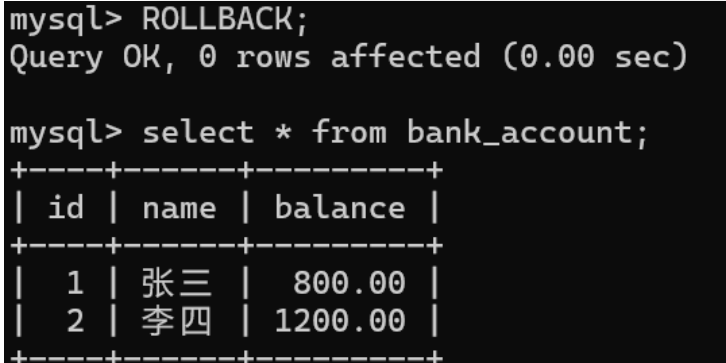
自动/手动提交事务
默认情况下,MySQL是自动提交事务的,也就是说我们执行的每个修改操作,比如插⼊、更新和删除,都会自动开启⼀个事务并在语句执行完成之后自动提交,发生异常时自动回滚。
查看当前事务是否自动提交可以使⽤以下语句
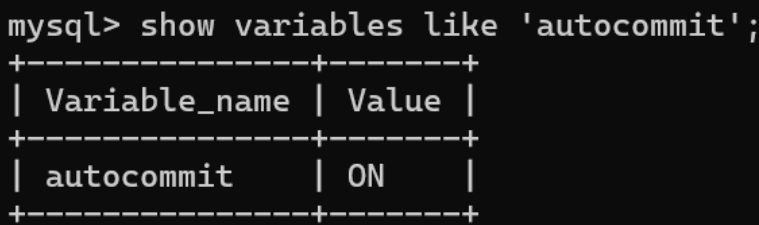
设置事务自动提交
设置事务手动提交
- 只要使用START TRANSACTION 或BEGIN 开启事务,必须要通过COMMIT提交才会持久化,与是否设置SET autocommit 无关。
- 手动提交模式下,不用显示开启事务,执行修改操作后,提交或回滚事务时直接使用commit或 rollback
- 已提交的事务不能回滚
五、进阶:隔离级别——解决"并发事务"的冲突
> MySQL服务可以同时被多个客户端访问,每个客户端执行的DML语句以事务为基本单位,那么不同的客户端在对同一张表中的同一条数据进行修改的时候就可能出现相互影响的情况,为了保证不同的事务之间在执行的过程中不受影响,那么事务之间就需要要相互隔离,这种特性就是隔离性。
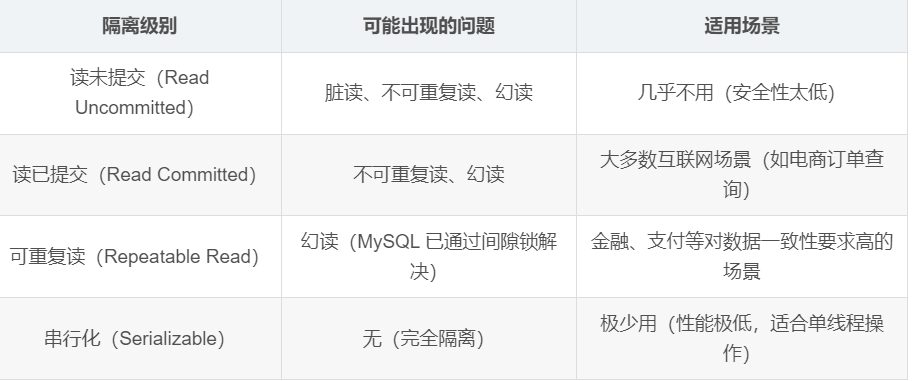
隔离性是为了解决"多个事务同时执行"的冲突。但"隔离"的程度不同,性能和安全性也会有差异。MySQL 提供了 4 种隔离级别,从低到高分别是:
事务的隔离级别分为全局作用域和会话作用域,查看不同作用域事务的隔离级别,可以使用以下的方式:
> 全局作用域
> 会话作用域
可以看到默认的事务隔离级别是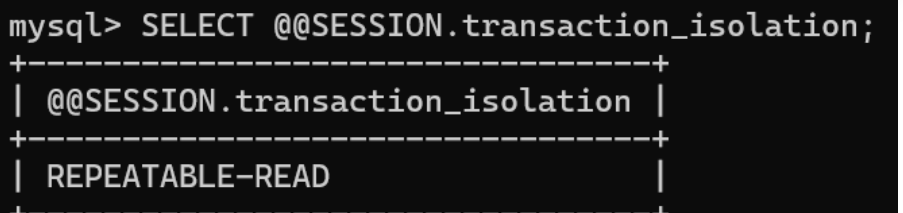 REPEATABLE-READ(可重复读)
REPEATABLE-READ(可重复读)
设置事务的隔离级别和访问模式,可以使用以下语法:
> 通过GLOBAL|SESSION分别指定不同作用域的事务隔离级别
不同隔离级别存在的问题:
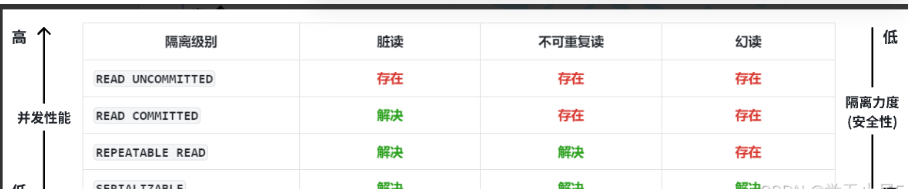
> READ UNCOMMITTED - 读未提交与脏读
出现在事务的 READ UNCOMMITTED 隔离级别下,由于在读取数据时不做任何限制,所以并发性能很高,但是会出现大量的数据安全问题,比如在事务A中执行了⼀条 INSERT 语句,在没有执行COMMIT 的情况下,会在事务B中被读取到,此时如果事务A执行回滚操作,那么事务B中读取到事务A写入的数据将没有意义,我们把这个理象叫做 "脏读"。
-*脏读:事务A修改了工资(但没提交),事务B读到了这个"未提交的修改";之后事务A回滚,事务B读到的就是"脏数据"(比如A把工资从5000改成8000,B看到8000,A回滚后,B以为工资还是8000)。
> READ COMMITTED - 读已提交与不可重复读
为了解决脏读问题,可以把事务的隔离级别设置为 READ COMMITTED ,这时事务只能读到了其他事务提交之后的数据,但会出现不可重复读的问题,比如事务A先对某条数据进⾏了查询,之后事务B对这条数据进行了修改,并且提交( COMMIT )事务,事务A再对这条数据进行查询时,得到了事务B修改之后的结果,这导致了事务A在同一个事务中以相同的条件查询得到了不同的值,这个现象要"不可重复读"。
- 不可重复读:事务B第一次查工资是5000,事务A修改工资为8000并提交;事务B再次查工资,变成了8000——同一事务内,两次读的结果不一致。
> REPEATABLE READ - 可重复读与幻读
为了解决不可重复读问题,可以把事务的隔离级别设置为 REPEATABLE READ ,这时同一个事务中读取的数据在任何时候都是相同的结果,但还会出现⼀个问题,事务A查询了一个区间的记录得到结果集A,事务B向这个区间的间隙中写入了一条记录并提交,事务A再查询这个区间的结果集时会查到事务B新写入的记录得到结果集B,两次查询的结果集不一致,这个现象就是"幻读"。
- 幻读:事务B查询"工资>5000的员工数"是10人,事务A新增了一个工资6000的员工并提交;事务B再次查询,结果变成11人——像出现了"幻觉"。
注意:隔离级别越高,数据越安全,但并发性能越低。比如"串行化"会把事务变成"排队执行",虽然不会有任何冲突,但在高并发场景(如秒杀)下,会直接导致系统卡死——所以千万别盲目追求"最高隔离级别"。
六、避坑指南:这些事务"陷阱"一定要避开
即使理解了 ACID 和隔离级别,实际开发中还是容易踩坑。分享 3 个最常见的陷阱:
1. 陷阱1:把"非事务安全表"当事务表用
MySQL 中,只有 **InnoDB 引擎**支持事务,MyISAM、MEMORY 等引擎不支持事务。如果你的表是 MyISAM 引擎,就算写了 `BEGIN TRANSACTION` 和 `COMMIT`,也不会有任何事务效果——执行到一半失败,数据照样会"翻车"。
解决办法:创建表时明确指定 InnoDB 引擎:
2. 陷阱2:在事务中执行"非事务操作"
比如在事务里执行 `DROP TABLE`、`ALTER TABLE` 等 DDL 语句——这些语句会**自动提交事务**,导致之前的操作被强制 COMMIT,后续的 `ROLLBACK` 失效。
例子:
解决办法:DDL 语句不要放在事务里执行;如果必须执行,先确保当前没有未提交的事务。
3. 陷阱3:事务过大,导致锁等待或死锁
如果一个事务包含大量操作(比如批量更新10万条数据),会导致事务执行时间过长,占用数据库锁的时间也变长——其他事务需要等待这个锁释放,容易出现"锁等待超时";如果两个事务互相等待对方的锁,还会导致"死锁"。
解决办法:
- 拆分大事务:把"批量更新10万条"拆成100次"每次更新1000条",每次执行完一个小事务就提交;
- 避免长事务:事务中不要包含用户输入、网络请求等耗时操作(比如在事务里调用第三方支付接口,接口卡30秒,事务就会锁30秒)。
七、总结:事务不是"银弹",但没有事务万万不能
MySQL 事务不是"万能药",它不能解决所有数据问题(比如硬件物理损坏需要靠备份恢复),但它是保障"数据一致性"的基础——没有事务,任何涉及多步操作的数据场景,都可能出现"翻车"风险。
最后,用三句话总结事务的核心用法:
1. 牢记 ACID:原子性保障"不丢步",一致性保障"不违规",隔离性保障"不冲突",持久性保障"不丢失";
2. 选对隔离级别:默认用"可重复读",互联网场景可降为"读已提交",金融场景不升为"串行化";
3. 避开常见陷阱:用 InnoDB 引擎,不混放 DDL 语句,拆分大事务。
掌握了这些,你就能让数据从"脆弱易翻车"变得"稳如泰山",再也不用为"钱扣了没到账""库存超卖"这类问题头疼了!