
即梦 AI 数字人教程丨 制作专属 MV


你有没有想过,让自己的照片活过来,甚至帮你完成一首深情款款的 MV?
现在,即梦 AI 的数字人 1.5 已经让这件事变得像呼吸一样简单!
今天,我就手把手拆解我制作MV 魔法的流程,教你如何用一张照片,轻松制作出情绪饱满、运镜专业的数字人唱歌视频!
一、先准备:一张的自拍照片
人脸细节决定了数字人的相似度与稳定性。
最好准备 1–3 张高质量人像(正面、侧面、微笑或中性表情)。
分辨率越高越好(建议 ≥2000px 宽)。
光线均匀、面部无遮挡、头发不乱、表情自然。
避免复杂背景。
准备好音频:如果用现成歌曲,准备 WAV/48kHz;如果没有下文会讲如何自制歌曲。
这是我准备的:

二、生成组图
把自拍的分镜图生成出来(豆包、香蕉、即梦都可以),保存到同一文件夹。
提示词示例:
以这张参考图的人物为核心主体,生成一套共 8 张、4K 超清分辨率的 MV 分镜背景图。场景主题为歌手在录音棚中深情演绎一首歌,要求场景基调温暖、深情、光线柔和。这 8 张图应展现不同景别和光影变化,例如:话筒特写、深情侧脸、远景录音室全貌、手部细节。
踩坑提示
人脸一致性: 即便 AI 强大,细节图的人脸仍可能微调。在生成组图后,对那些人脸发生微妙变化的分镜图,使用图生图功能,微调提示词,重新生成,确保人脸在所有分镜中都完美统一。


三、制作音频
先做歌词:用 DeepSeek / 豆包/ 其他写歌词模型生成草稿。
提示词示例:
帮我写一首适合年轻人听的深情情歌,主题为“错位时空的暗恋”,副歌简短上口,押韵自然,适合A段-副歌结构,总长度控制在3分钟。

用AI生成音乐:推荐 Suno、Mubert、AIVA 等生成音轨,导出高品质 WAV(48kHz)。
分段处理:把音频拆成与分镜对应的小段(每段 4–8 秒),方便生成与微调。
可选技巧:用假声合成或转唱功能,让声音更像歌唱(部分平台支持合成唱腔)。
四、生成数字人
进入即梦的 数字人 功能页面
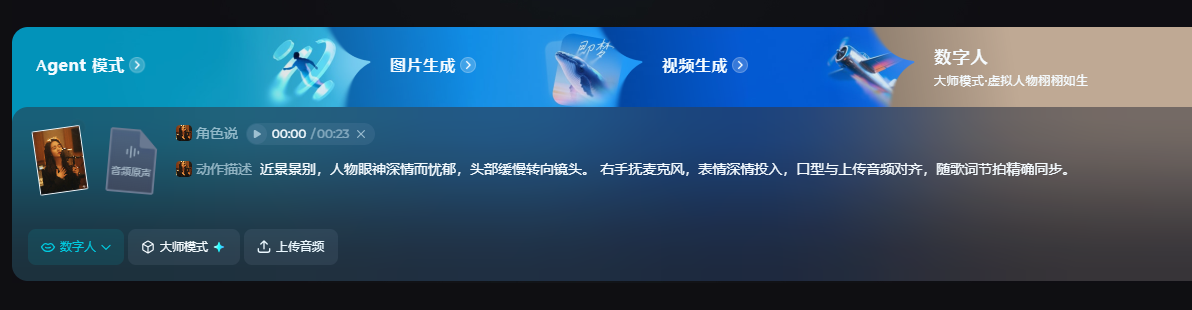
操作步骤:
上传角色: 上传你的数字人形象照片。
音频导入: 推荐选择上传音频,音频30s以内。
模式选择: 大师模式虽然消耗积分高,但其人物表情、口型同步、动作细节的生动自然度是基础模式无法比拟的!
提示词模板:
景别:[近景/半身/全身/背影], 运镜:[静帧/慢推/环绕/平移],速度[慢/中/快],动作:[嘴型/眼神/头部/手部/走位](如 “微微张口 → 低头含情注视 → 右手抚麦克风”),表情:情绪关键词(如“深情、怀旧、投入、微笑”),口型与上传音频对齐,随歌词节拍精确同步
五、合成视频
将数字人片段按照歌词顺序排列好,确保画面与歌词完美匹配。
再使用剪映的智能字幕功能识别歌词,并对字幕进行美化。
就这样,一个生动、流畅、充满情绪张力的 AI 数字人 MV 就完成了!
关注我,了解更多AI教程!
