
根治大模型“胡说八道”:高级检索增强生成(RAG)实战入门


正文:
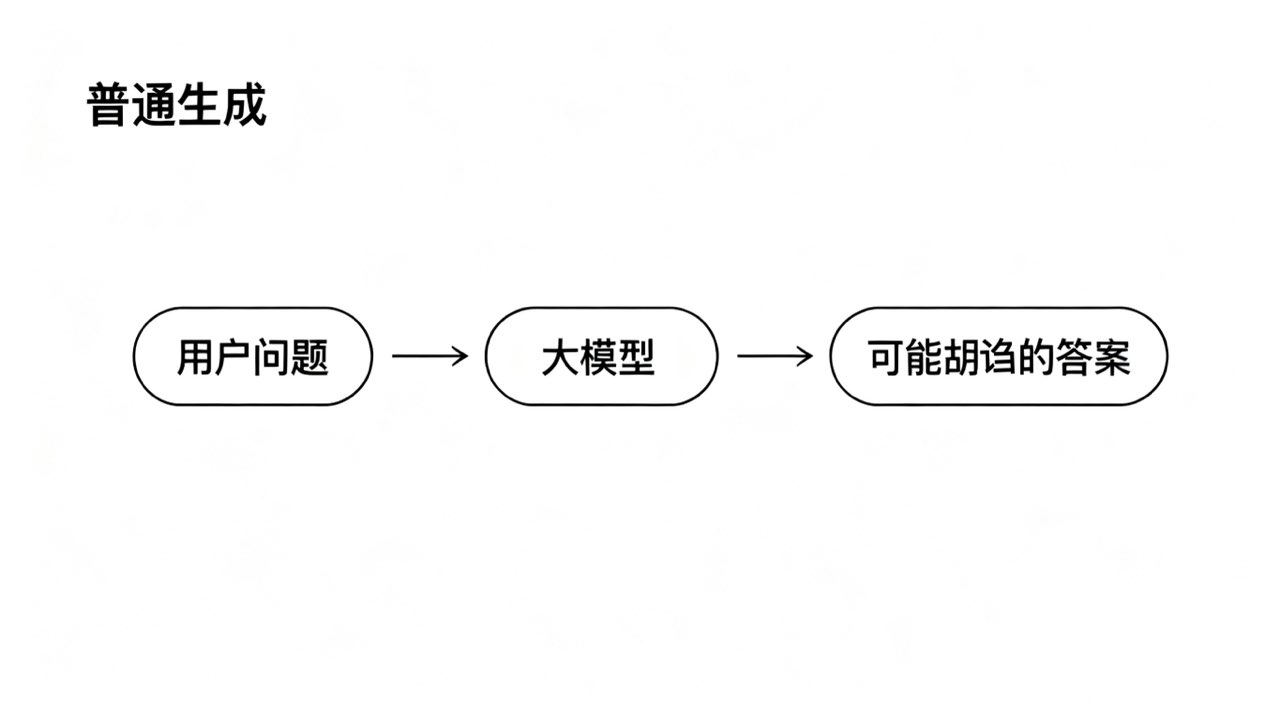
1. RAG是什么?为什么能解决“胡诌”?
· 核心思想: 在让大模型生成答案之前,先从你的私有知识库(如文档、数据库、Wiki)中检索相关的准确信息,然后将这些信息作为“参考依据”和问题一起增强地送给模型,最后让它基于这些依据来生成答案。
· 效果: 相当于给模型配了一个专业的“秘书”,先帮它找好资料,它再基于资料作答,答案的准确性因此大幅提升。
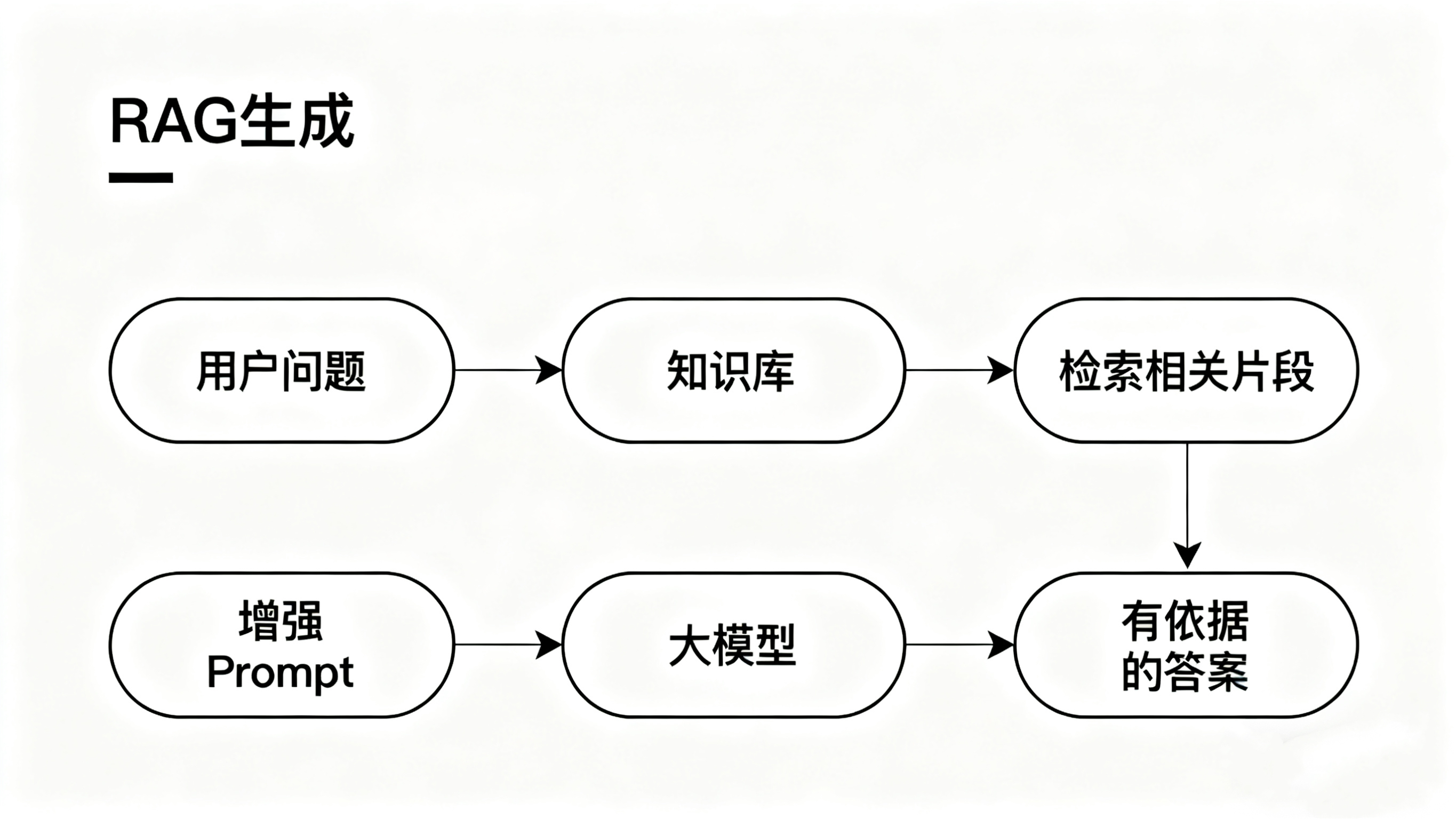
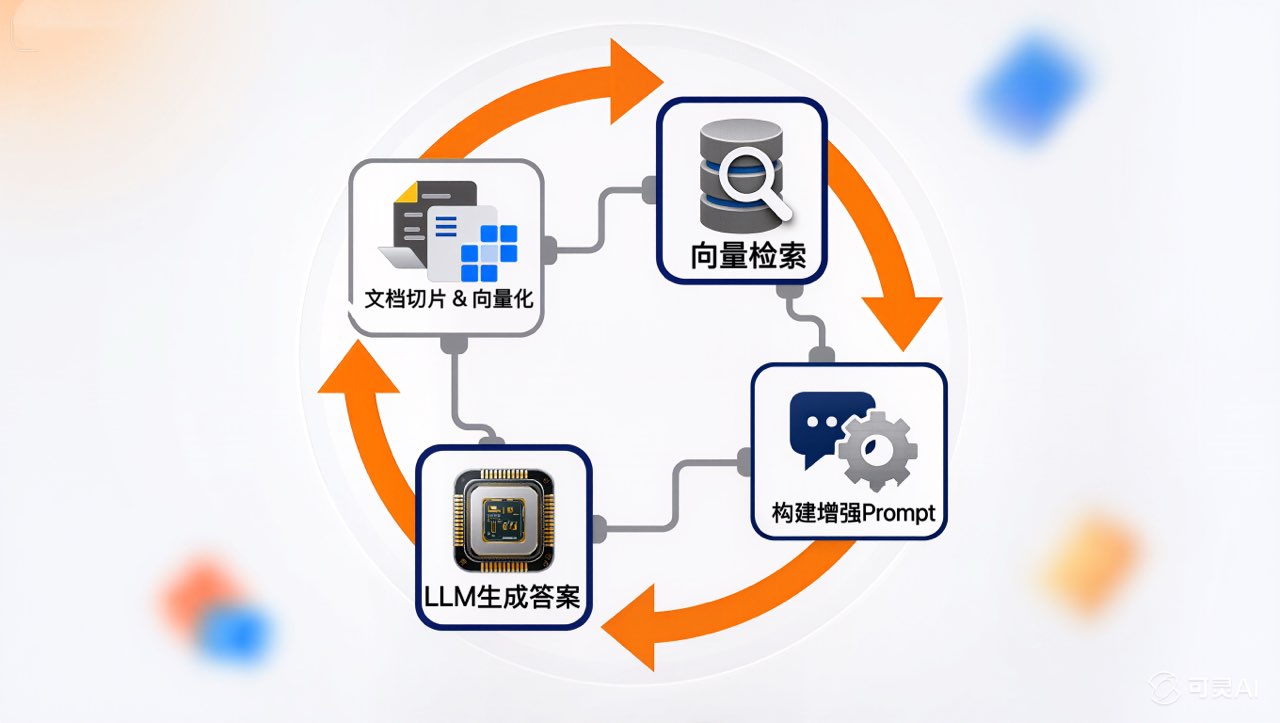
2. 搭建一个最简单的RAG系统(四步流程)
步骤一:文档预处理与向量化
· 将你的PDF、Word、TXT等文档拆分成小块(如每段或每页)。
· 使用一个嵌入模型将这些文本块转换成数学向量(一组数字),并存入向量数据库。这个过程的核心是让“语义相近的文本,其向量也相近”。
步骤二:用户提问与向量检索
· 当用户提问时,同样用嵌入模型将问题转换成向量。
· 在向量数据库中,进行相似度搜索,找出与问题向量最相似的几个文本块(即最相关的内容)。
步骤三:构建增强Prompt
· 将检索到的相关文本块作为“上下文”或“参考信息”,与用户的原始问题组合成一个新的、信息更全面的Prompt。
示例Prompt结构:
请严格根据以下提供的信息来回答问题。如果信息中不包含答案,请直接说“根据已知信息无法回答该问题”。
【提供的参考信息开始】
{这里插入从向量数据库检索到的相关文本块}
【提供的参考信息结束】
【用户问题开始】
{用户的原始问题}
【用户问题结束】
步骤四:调用大模型生成最终答案
· 将这个构建好的增强Prompt发送给GPT-4等大模型。
· 此时,模型生成的答案就有了坚实的依据,极大减少了幻觉(Hallucination)。
3. 技术栈推荐(供开发者参考)
· 向量数据库: Pinecone(云服务,简单),Chroma(开源,轻量),Milvus(开源,强大)。
· 嵌入模型: OpenAI的text-embedding-3-small,或开源的bge-large-zh(中文优)。

结语:
RAG技术是构建可信赖企业级AI应用的基石。它不需要重新训练模型,就能低成本、高效率地让大模型“掌握”你的私有知识。从今天这个简单的四步流程开始,你就能打造一个真正“懂你业务”的智能助手。
