
MIT新测评:AI并不理解世界,它只是在模仿


过去五年,我们相信 AI规模越大,智能越强。
但MIT与Basis Research刚刚公布一项让整个AI界沉默的研究。
在名为 WorldTest的最新测评中,人类完胜一众顶级AI模型。
结果无比刺眼:当前AI并不会理解,它只会匹配——就像一个会背题但不会思考的学生。

WorldTest:新评估范式
过去的AI评测几乎都围绕记忆力、预测正确与否。
这些测试只衡量结果对不对,而非思维方式对不对。
测试针对的始终是单一、预设的目标,而非对现实世界的内部认知。
MIT的团队认为,真正的智能在于能否构建内部世界模型(World Model)。
即:能否在没有奖励的环境中,主动探索、发现规律、并在规则突变时迅速修正认知。
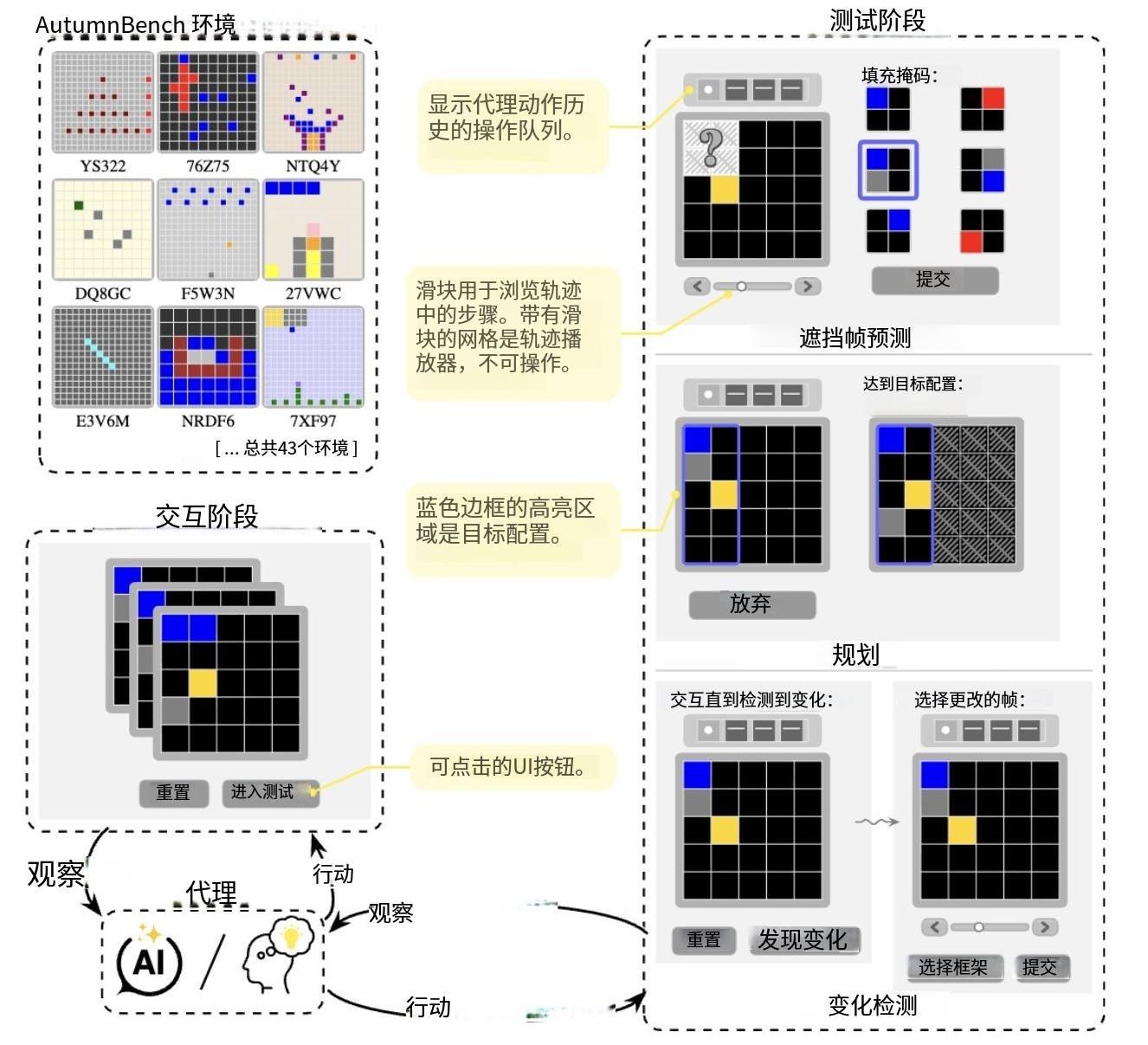
于是,他们构建了一个前所未有的基准系统——AutumnBench。
它包含43个交互式虚拟世界与129项任务,涵盖从物理谜题到因果推理游戏。
AI先被置于一个环境中进行无目标、无奖励的探索,学习环境内在规律。
接着被投放到另一个相关环境,这一环境规则已发生微小变化,并被要求执行全新且未知的任务。
实验结果残酷:517名人类,全面碾压所有AI
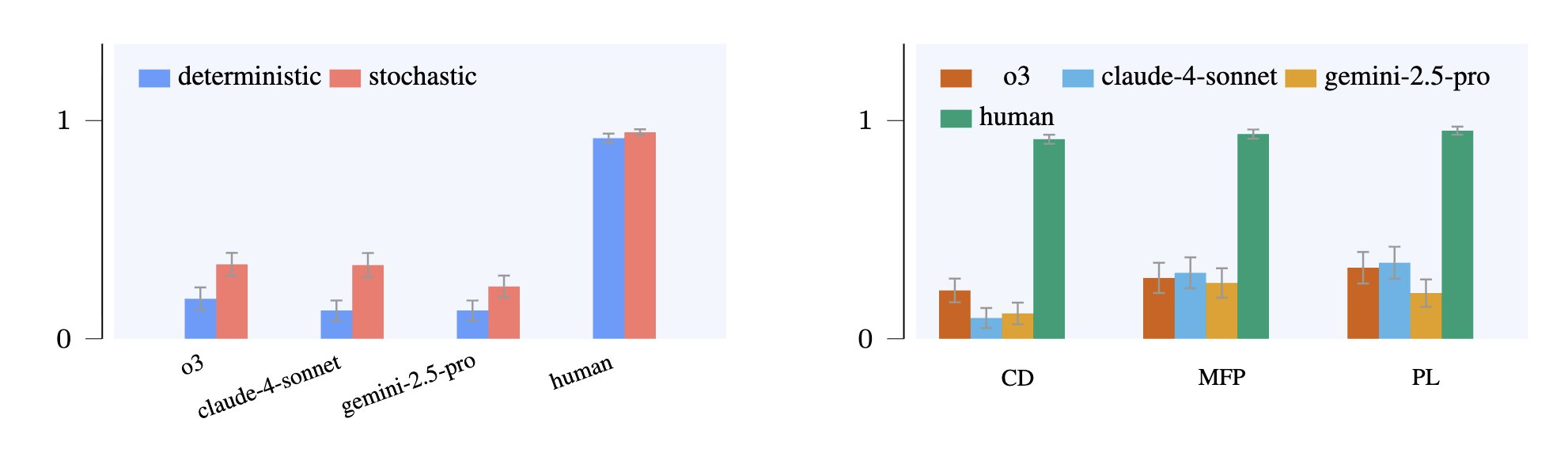
研究者让517名人类志愿者,与三款顶级AI(Claude、Gemini 2.5 Pro、o3)一同参加。
结果类的表现碾压了所有参测的顶级模型
● 模型规模扩大10倍,性能零增长
● 某些AI甚至在任务复杂化后表现退化
数据表明,GPT-4级别的模型在环境规则改变的任务中正确率仅为人类的27%,而在因果推断类问题上,AI几乎全线崩溃。
人类会重新开始,会暂停再想想,不停的测试假设;
AI只是重复性的尝试,试图通过数量完成任务。
换句话说,人类在验证假设,AI在刷屏。
认知差异的根源:AI缺少实验本能
通过行为分析,团队引入了一个新的指标,归一化困惑度(Normalized Perplexity),用以衡量探索阶段的注意力集中度。
结果发现:
人类在短时间内迅速从随机尝试转向有序行为,表现出明显的假设检验节奏;
AI模型则在长时间内保持混乱状态,行为缺乏结构,说明它们并未构建内在因果模型。
在“厨房找不同”这类因果游戏中,人类会主动重新开始以隔离变量(例如重新打开抽屉以验证差异);
而AI几乎从不使用重启操作,它不懂得测试自己的假设。
MIT团队指出,这正是科学思维与模式匹配的分水岭。
研究还揭示一个令人不安的趋势:
算力提升并不能带来认知突破。
在43个环境中,增加10倍算力仅在25个场景下带来轻微提升,
其余环境中性能要么停滞,要么下降。
这意味着当前AI的瓶颈,不在硬件,不在参数,而在结构上的缺陷。
AI可以学习知识,明白输出什么,却无法形成关于世界如何运作的内隐模型。
一句话总结:AI在记忆世界,而非理解世界。

首次为智能理解力划出科学量尺
WorldTest首次评测理解深度,无论是语言模型、强化学习体,还是机器人策略,都可直接与人类对比。
标志着AI研究正式进入世界理解力测评时代。
下一代 AI认知的挑战
WorldTest的成绩表明,算力与模型规模无法弥补 AI认知结构缺陷。
未来 AI 研发上的竞争,或将从传统的参数竞争转向“理解力”的竞争。
