
NVIDIA新模型:医疗诊断过程全透明


目前,医疗AI在胸部X光(CXR)的诊断准确率上,早已达到甚至超越了人类专家。
但他们在临床落地上存在一个根本上的难题,诊断过程不透明。
它们的输出只是一个冷冰冰的预测结果,无法提供像人类医生那样从异常到诊断的推理过程,所以准确,但不可信。
NVIDIA在最新发布的NV-Reason-CXR-3B模型中提到了这点,并首次让AI在胸片诊断中具备推理链能力。
这是医学AI从黑箱判断迈向透明思考的关键拐点。

AI新能力:从判断到推理
传统医学AI的局限是输出结果、但不解释原因。
NV-Reason-CXR-3B通过推理优先的训练模式,让模型学习医生的思维过程,而非仅学习标签结果。
包括两阶段:
阶放射科式微调(SFT) —— 模型通过10万份推理文本学习放射科医生观察顺序、语言风格与诊断逻辑;
强化学习(GRPO) —— 模型根据可验证的异常集正确度奖励机制实现自我优化,学会自查与修正。
数据显示,该模型在CheXpert测试集中实现60.6%的宏平均F1分数,超越了Google Gemini Ultra(42.6)和MedGemma-4B(48.1)等通用医学模型。
在双盲读片实验中,美国执业放射科医生在三种条件下对比:
1. 无AI辅助;
2. 仅有AI标签(如肺部阴影);
3. AI完整推理输出(含思维链与结构化报告)。
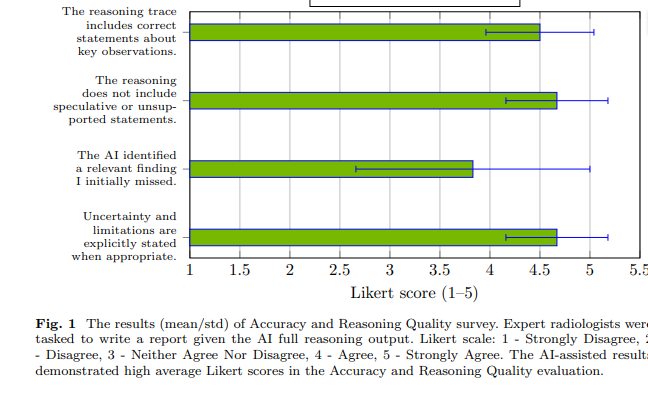
结果显示:在第三种条件下,医生诊断时间缩短55%,置信度平均提升0.5分(Likert量表,满分5),在复杂异常病例中,AI推理输出帮助医生发现遗漏异常的比例提升近30%。
一位参与者评论:
以前AI像一个会答题的学生,现在它更像一个会思考的实习医生——你能看到它的思路、甚至它的不确定性。
技术底层创新:AI自证推理机制
NVIDIA采用了一种名为GRPO(Group Relative Policy Optimization)的强化学习算法。
它不依赖昂贵的标注推理数据,而是通过多组采样、相对奖励的机制评估每个推理路径的优劣。
若推理结果与真实异常集合高度一致,则该路径得分高;若逻辑结构缺失(如未标注<think>区块),得分直接清零;模型还需在输出中控制篇幅,保持600–700 token的完整思维链。
这种奖励可验证推理的机制让AI学会像医生一样推演、验证、排除错误假设,而不仅仅是模式匹配。
更关键的是:错误推理也被记录,使AI具备自我审计能力,为医疗AI的责任追踪和监管提供基础。

NV-Reason-CXR-3B开放源代码的意义
在图像准确率已逼近天花板的当下,可解释性成为AI医疗系统能否落地的决定性因素。
英伟达模型的开源,让医院可追溯医疗AI每一步判断过程,医生可编辑AI生成的报告,监管部门也能量化推理合规性。
未来,推理质量评分与预测准确率将成为AI医学模型的新KPI。
