
为什么鲁棒性是医疗AI获得FDA批准的下一道强制门槛?


人工智能在医疗领域的应用,尤其在皮肤病学等领域,已展现出媲美甚至超越人类专家的能力。
但在高风险临床环境中,一个肉眼不可见的像素偏移就能将恶性病错误分类为良性 ,直接威胁患者生命 。
准确率不再是衡量医疗AI的唯一标准,鲁棒性(即抗攻击能力)正成为决定医疗AI生死存亡的重要指标。

AI医疗的软肋:看不见的攻击,看得见的风险
医疗AI的革命性在于它能识别复杂模式,例如皮肤病变、肿瘤影像、肺部阴影等。
国外研究团队测试发现,当引入数据投毒攻击时,AI模型的诊断准确率骤降。攻击者仅需在训练数据中加入几张被修改过的图片,就能让系统错误学习(例如把恶性病变误判为良性)。
这类攻击并不依赖黑客访问医院服务器,只要能渗透模型训练流程,整个诊断系统就可能长期中毒而无人察觉。
1. 医疗AI系统面临的对抗性威胁可以分为三大类: 数据投毒攻击(Data Poisoning Attacks): 这种攻击在模型的训练阶段损害其完整性 。攻击者通过将恶意制作的输入嵌入训练集 ,使模型在遇到特定触发器时,学会错误的行为 。一个典型的案例是 Nightshade 技术 ,它以人类不可察觉的方式修改图像纹理 ,从而在模型的部署后造成难以检测和修复的长期漏洞。
2. 规避攻击(Evasion Attacks): 不同于投毒,规避攻击在推理时执行 。通过在已训练的模型输入样本中引入难以察觉的微小扰动 ,攻击者可以利用模型的决策边界,导致误分类 。著名的技术包括快速梯度符号法(FGSM)和投影梯度下降(PGD) 。在医疗影像中,像素级的扰动可能导致X光片或皮肤镜图像被错误地归类为良性,即使病理学迹象明显存在 。
3. 模型提取与逆向工程(Model Extraction and Reverse Engineering): 这种更阴险的攻击涉及对手通过查询API来推断公开AI模型的内部结构和决策边界 。攻击者可以构建一个替代模型来模仿目标系统的行为 ,进而生成高度可迁移的对抗性样本 。更严重的是,如果原始模型使用敏感医疗数据训练 ,提取攻击可能导致私人信息泄漏 ,引发HIPAA和GDPR等数据保护框架下的严重担忧 。
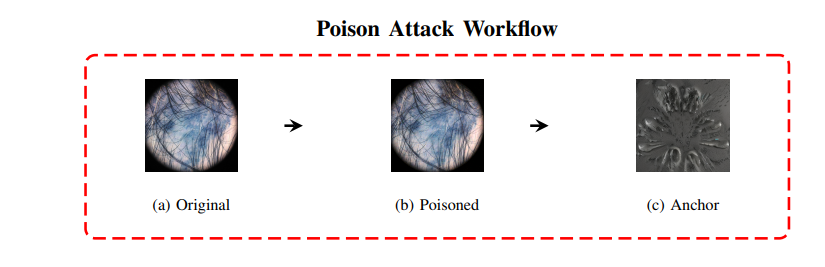
防御策略:精度、鲁棒性与算力成本
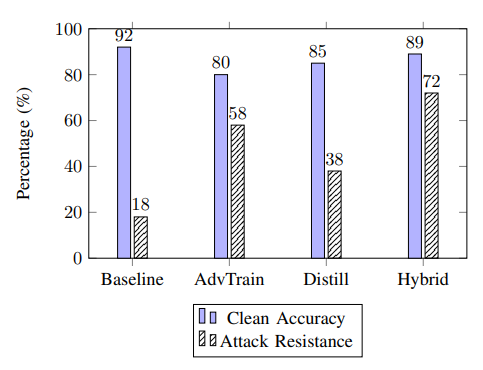
研究团队系统的比较了三种主流防御机制,
1. 对抗性训练:在训练中加入被攻击样本,让模型学会防御。测试结果,攻击成功率下降58%,但准确率下降12%,训练时间增加1.8倍,鲁棒性强但牺牲了模型准确率率。
2. 防御蒸馏:通过教师-学生模型的决策边界,减少对输入微扰的敏感性。测试结果,攻击成功率下降38%,准确性影响较小,推理时间增加15%,适用于轻度攻击,但对PGD等迭代攻击效果不佳。
3. 混合策略:结合输入预处理(JPEG压缩、中值滤波等)与对抗性训练。防御成功率达72%,准确率下降3%,成本增加但收益最高,是当前临床环境中的最佳实践方案。
据研究团队测算,混合策略的核心优势在于多层防御与冗余设计,即使一层算法被突破,输入清洗层仍可拦截大部分异常数据。

医疗AI监管的新拐点
未来的监管框架,必须将鲁棒性(即AI在受到攻击或异常输入时的稳定性)纳入核心评估标准。FDA或CE医疗AI认证未来或将增加鲁棒性测试环节,并要求企业公开其防御策略与训练透明度。
未来5年,全球医疗AI市场预计突破600亿美元,如果医疗模型持续暴露在隐形攻击下,其商业化进程将被严重拖慢,对AI厂商而言,能否在算法精度与鲁棒性之间找到动态平衡,将决定其能否在高风险医疗领域立足。
