
3D脑部MRI:脑部影像AI如何突破2D限制


在精密复杂的医学影像领域,脑部磁共振成像(MRI)无疑是最具挑战性的AI应用场景之一。
传统AI依赖大量标准数据的深度学习,且只能在2D切片和特定成像协议表现良好,无法理解大脑的真实空间联系。
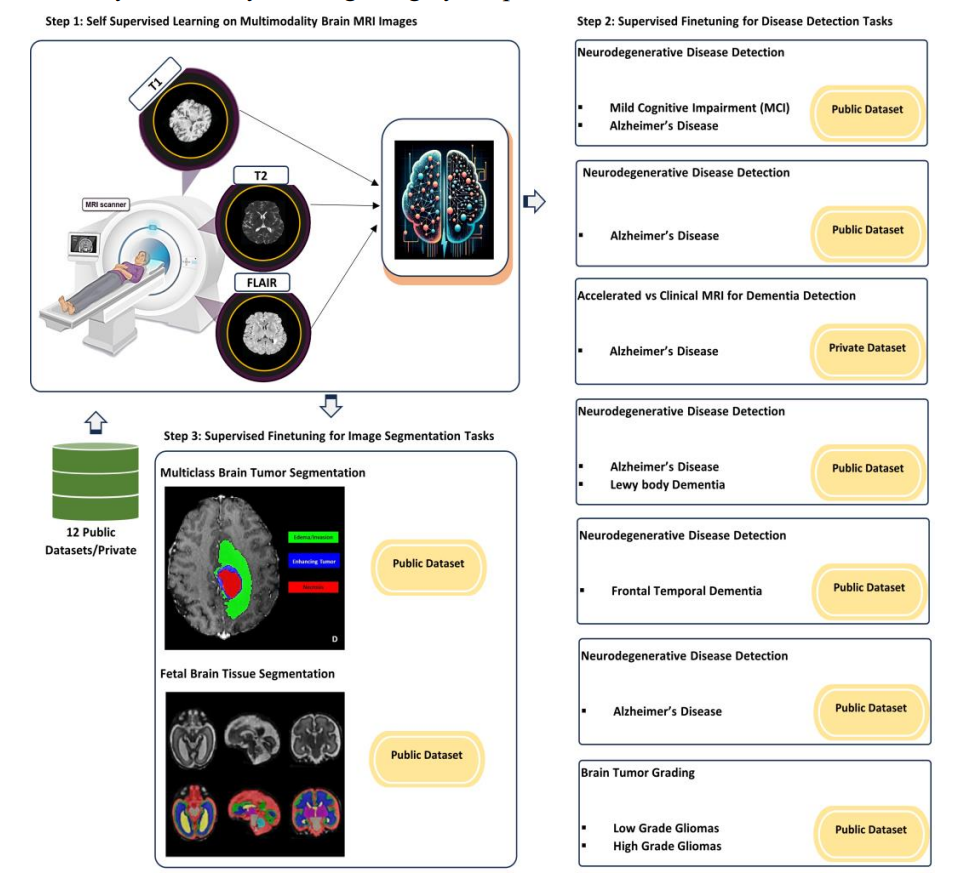
伦敦大学的最新研究引入了BrainFound新模型,通过大规模无标签数据进行预训练,专为3D脑MRI设计。

架构突破:从2D到3D的体积理解
BrainFound的核心创新是将2D视觉Transformer(ViT)扩展至三维空间,实现了从平面切片到全3D体积信息的飞跃。
传统医学AI模型往往把MRI扫描拆解成上千个独立切片训练,这就像用照片拼凑立体物体,无法捕捉空间连续性。
1. 而BrainFound的3D架构一次性读取整个脑部体积数据,工作机制: 脱离切片范式: BrainFound则通过巧妙的编码机制,将连续MRI切片的空间和解剖学关联整合到模型输入中,从而理解整个3D脑部解剖结构的拓扑关系。
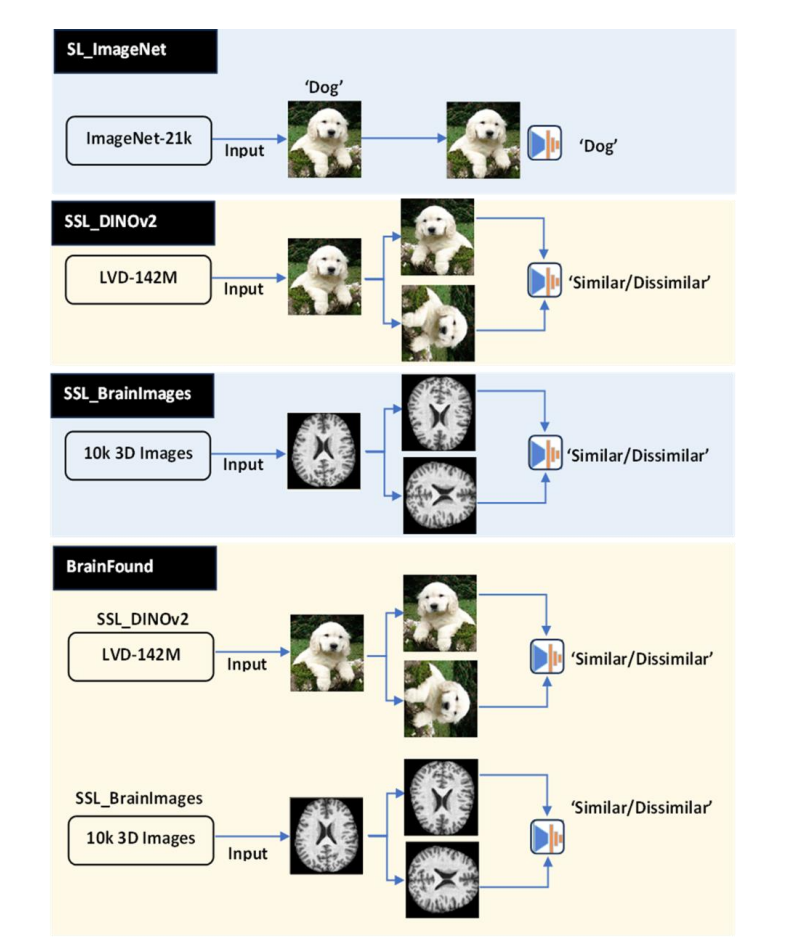
2. 自监督学习:BrainFound利用海量的无标签MRI数据,通过被遮挡或旋转的3D区域,从而学习通用、高阶的空间结构特征。这使其摆脱了对昂贵人工标注的依赖,是实现模型泛化的关键。
BrainFound的另一个关键突破,是增强了对不同对比度序列的理解能力。
传统模型往往只能处理单一模态(如T1或T2),而BrainFound通过多模态融合,将不同成像物理特征编码进统一空间。
在临床实践中,这意味着AI不再孤立分析影像,而是能跨模态推理,如同时识别解剖结构(T1)与病变水肿(T2/FLAIR),实现前所未有的影像理解深度。
据国外影像数据分析报告,BrainFound在多模态输入任务中提升平均分割精度达28%,并在小样本迁移学习中优于所有对照模型。
在标签稀缺场景(例如儿童罕见神经病变)下,其性能优势更为显著。
通用性:多场景复用
在实验中,研究团队将其在美国成人MRI数据上预训练的模型,直接迁移至欧洲多中心儿科数据集,仅需少量微调即可恢复原始性能的93%。
这意味着一个在大型数据集上训练的基础模型,可以高效的通过少量微调适应特定医院的特定任务,极大降低了医疗AI落地成本,加速神经科学研究和临床应用的落地。

3D体积建模打破2D切片范式
神经影像AI的未来不是更好的2D模型,而是原生3D模型。
随着SFM(自监督基础模型)在3D影像领域的普及,未来所有神经疾病AI应用(如阿尔茨海默早筛、肿瘤体积预测)将不再是独立模型,而是在同一基础脑模型上微调的智能体。
