
5分钟部署本地私有大模型(Ollama 安装教程)


很多人下载好了coze、dify,却在为api发愁。
顶级模型供应商都只提供免费额度,托管平台免费但有的速率限制。
如何能免费运行真正的AI大模型?
不需要租服务器,不需要复杂配置,跟着这篇文章,5分钟内你就能拥有自己的本地DeepSeek。
一、Ollama是什么?
Ollama是一个让你在本地运行大语言模型的开源工具。
能把复杂的模型部署流程简化成几条命令。
想象一下,原本需要配置Python环境、安装CUDA、调整模型参数这一系列操作,现在只需要:
ollama run qwen # 一条命令启动
一、为什么是Ollama?
● 支持国产模型,千问、DeepSeek等都有适配版本
● 参数量可选 - 从1.5B到70B,按电脑配置选择
● 完全离线 - 数据不出本地,隐私有保障
关于硬件要求:
1.5B模型:8GB内存就能跑
7B模型:16GB内存推荐
不需要独立显卡(但有GPU会更快)
二、安装Ollama
步骤1:
下载安装包
点击Download → 选择系统版本
步骤2:
直接双击 OllamaSetup.exe:
默认安装到C盘(无需修改)
等待自动安装完成
步骤3:
验证安装是否成功(可跳过)
# 按 Win+R,输入 cmd,回车
ollama
# 看到帮助信息就是安装成功
```
**方法2:浏览器验证**
```
访问:http://localhost:11434
显示 "Ollama is running" 即成功
三、下载并运行大模型
选择模型
访问 https://ollama.com/library,这里有模型仓库。以千问(Qwen)为例:
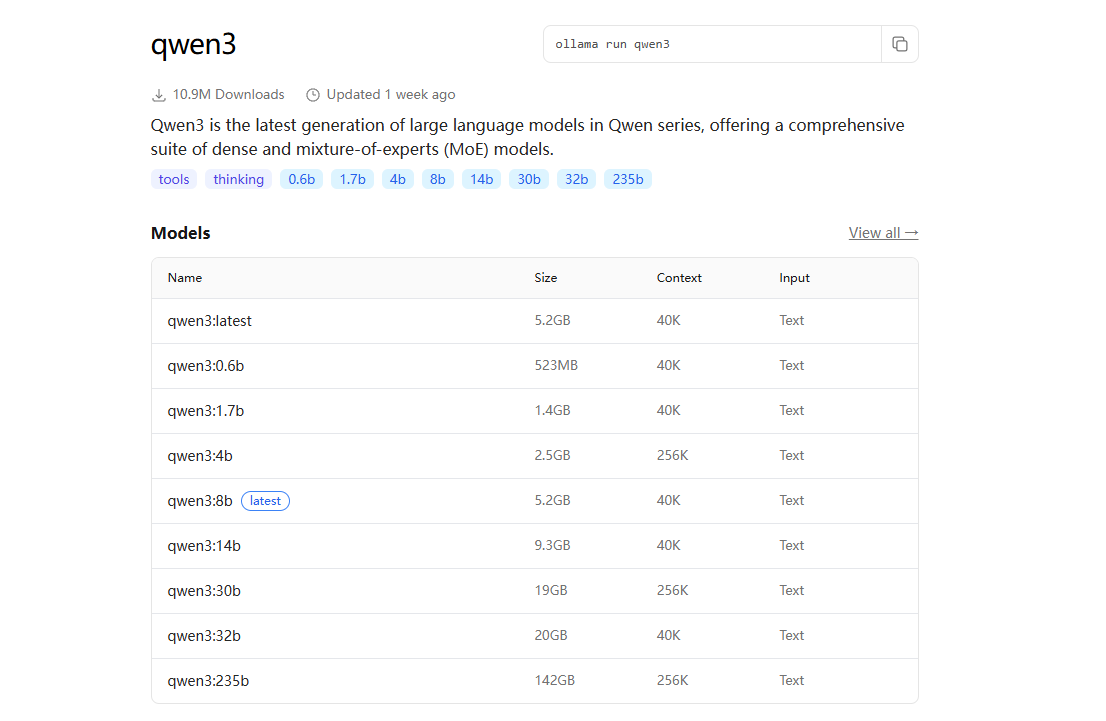
参数量(B = Billion = 10亿)越大,模型越聪明,但也越占资源。
这里我们以qwen3:8b为例,复制命令后打开cmd,粘贴并回车
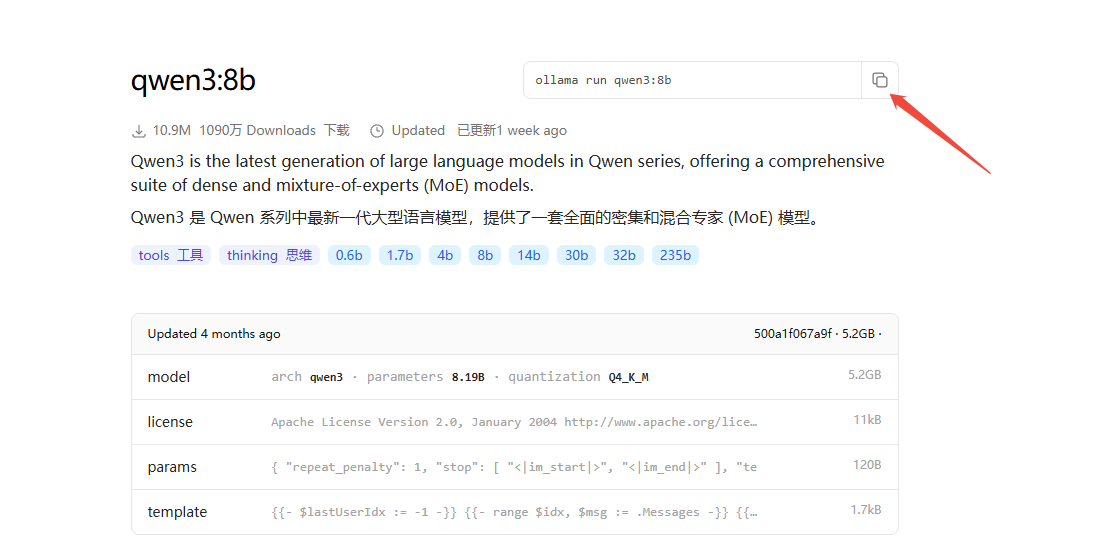

常用命令:
ollama list # 查看已下载的模型
ollama run deepseek:1.5b # 运行DeepSeek模型
ollama rm qwen3:8b # 删除模型释放空间
ollama pull llama3 # 仅下载不运行
四、更改模型存储路径
默认模型存储在C盘,多下几个就爆了
Windows系统操作步骤:
右键此电脑 → 属性 → 高级系统设置

点击环境变量按钮
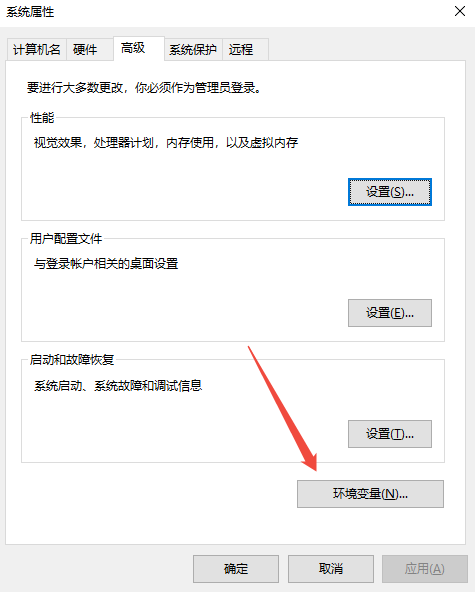
在用户变量区域,点击新建"变量名:OLLAMA_MODELS
变量值:D:\AI_Models
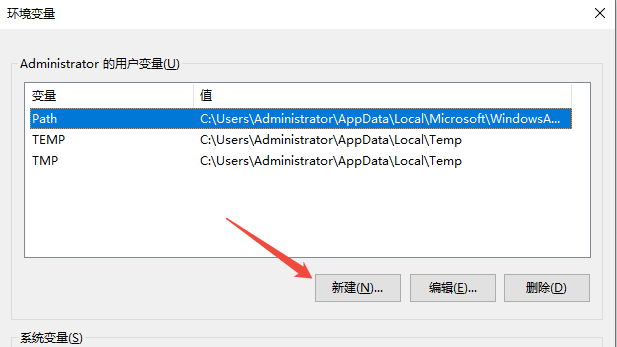
点击确定即可
五、搭配Web界面
命令行对话不够直观?
我们来部署一个网页版界面(Open WebUI)
它会自动识别Ollama的所有模型,支持多轮对话、历史记录。
步骤1:
下载Docker Desktop
访问:https://www.docker.com/products/docker-desktop
安装完成后会重启电脑
步骤2:
用 cmd执行命令
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --restart always --name open-webui ghcr.io/open-webui/open-webui:main
代码解读: 别被这一长串代码吓到,它只是告诉 Docker 帮你做几件事:
-d:在后台运行
-p 3000:8080:将容器的 8080 端口映射到你电脑的 3000 端口
--name:给这个运行的程序起个名字叫 open-webui
步骤3:
自动拉取并运行镜像成功后,打开你的浏览器,访问地址:
http://localhost:3000
首次访问需要注册一个本地账号(数据只会保存在你的本地电脑上)
进入界面后,WebUI 会自动检测并关联到你的 Ollama
