
Dify工作流深度解析


过去这一年,大家都见识了大型语言模型(LLM)那令人惊叹的潜力。
但你问一个问题,模型给你答案,这远远不够。
真正的生产级AI应用需要的是:多步骤推理、工具调用、条件判断、循环处理,将复杂逻辑一起组织起来。
Dify的工作流给出了一个教科书般的答案。
今天我们深入到架构层面,看看这套系统是如何实现可视化拖拽 → 复杂AI编排。
一、工作流的本质
1. DAG
当我们谈论 Dify 工作流的执行原理时,脑海中浮现的第一个专业名词必须是:
有向无环图(DAG,Directed Acyclic Graph)
让我们拆解这个概念
● 有向(Directed):数据只能从上游节点流向下游节点
● 无环(Acyclic):意味着流程不会陷入无限循环,确保任务总能执行完毕
● 图(Graph):由节点(Node)和边(Edge)组成
节点(Node)是工作流图上的每一个方块,都代表一个独立的任务单元。
边(Edge)是 连接节点的箭头,代表数据流的方向和任务的依赖关系。
2. 执行流程示意
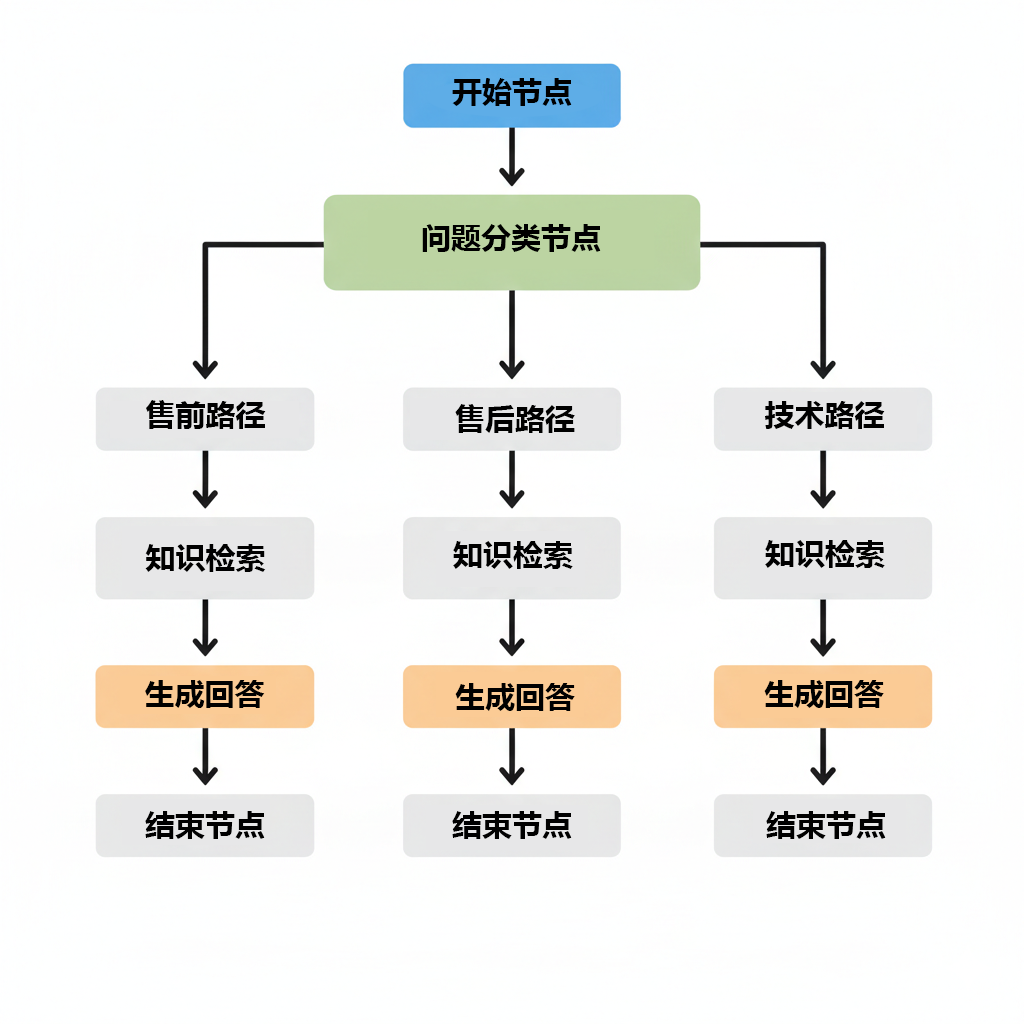
执行引擎会:
1. 解析整个DAG结构
2. 识别可执行节点(依赖已满足)
3. 执行节点并传递输出
4. 触发下游节点执行
5. 直到流程结束
二、核心组件深度剖析
1. 工作流引擎(Workflow Engine)
这是整个系统的大脑,负责:图解析与构建
class GraphEngine:
def __init__(self, graph: dict):
self.nodes = graph.get("nodes", [])
self.edges = graph.get("edges", [])
self.build_execution_graph()
def build_execution_graph(self):
"""构建执行依赖关系"""
for edge in self.edges:
source = edge["source"] # 源节点ID
target = edge["target"] # 目标节点ID
# 建立依赖关系
上下文管理(Context)
工作流执行时维护一个全局上下文对象:
context = {
"user_input": "我的订单什么时候到货?",
"question_type": "售后",
"retrieved_docs": [...],
"llm_response": "...",
"api_result": {...}
}
```
节点通过变量引用访问数据:
```
${{ user_input }}
${{ question_classifier.output.type }}
${{ knowledge_retrieval.documents }}
这个设计类似于Jinja2模板引擎的变量系统。
执行调度
引擎采用事件驱动模型:
1. 节点执行完成 → 触发事件
2. 检查下游节点依赖是否满足
3. 将满足条件的节点加入执行队列
4. 支持并行执行(多个无依赖节点同时运行)
2. 节点系统(Node System)
Dify提供了16+种节点类型,每种节点都遵循统一接口:
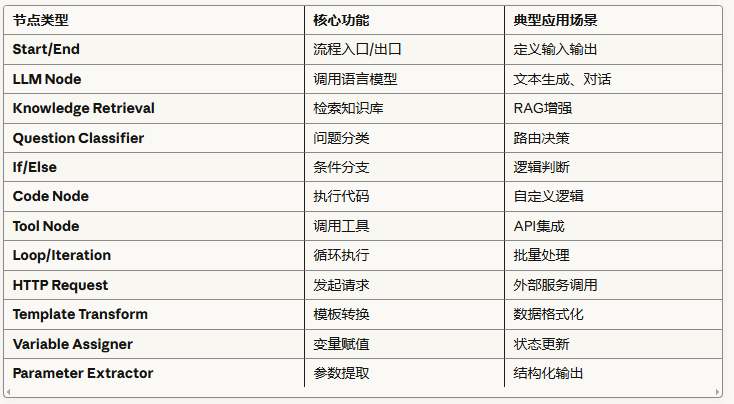
节点的标准结构:
class BaseNode:
def __init__(self, config: dict):
self.id = config["id"]
self.type = config["type"]
self.inputs = config.get("inputs", {})
self.outputs = {}
self.status = "pending" # pending/running/done/failed
def run(self, context: dict) -> dict:
"""执行节点逻辑"""
try:
self.status = "running"
result = self._execute(context)
self.outputs = result
self.status = "done"
return result
except Exception as e:
self.status = "failed"
raise
def _execute(self, context: dict) -> dict:
"""子类实现具体逻辑"""
raise NotImplementedError
3. 变量系统:工作流的数据流
Dify的变量系统有三个层级:
环境变量
● 跨节点共享的全局配置
● 例如:API密钥、模型参数
● 支持加密存储(敏感信息)
对话变量
● 会话级别的状态保持
● 例如:用户身份、历史偏好
● 用于多轮对话场景
节点变量
● 节点执行产生的输出
● 例如:${{ llm_node.output.text }}
● 单向传递,下游可引用上游
循环变量的特殊性:
在Loop节点中,Dify引入了前序迭代引用机制:
{
"findings": "当前迭代发现的内容",
"previous_findings": "上一次迭代的累积",
"knowledge_gaps": "待解决的问题"
}
这允许节点同时访问当前迭代和历史迭代的数据,实现知识累积。
4. 状态持久化
Dify将工作流状态保存在PostgreSQL中:
核心表结构
-- 工作流定义表
CREATE TABLE workflow (
id VARCHAR PRIMARY KEY,
tenant_id VARCHAR,
app_id VARCHAR,
type VARCHAR, -- workflow/chatflow
version VARCHAR,
graph TEXT, -- JSON格式的DAG定义
features TEXT, -- 特性配置(JSON)
environment_variables TEXT, -- 环境变量(JSON)
conversation_variables TEXT -- 对话变量(JSON)
);
-- 工作流运行记录表
CREATE TABLE workflow_run (
id VARCHAR PRIMARY KEY,
workflow_id VARCHAR,
graph TEXT, -- 执行时的图快照
inputs TEXT, -- 输入参数(JSON)
outputs TEXT, -- 输出结果(JSON)
status VARCHAR, -- running/succeeded/failed
created_at TIMESTAMP
);
-- 节点执行记录表
CREATE TABLE workflow_node_execution (
id VARCHAR PRIMARY KEY,
workflow_run_id VARCHAR,
node_id VARCHAR,
node_type VARCHAR,
inputs TEXT,
outputs TEXT,
status VARCHAR,
elapsed_time FLOAT,
created_at TIMESTAMP
);
这种设计实现了
● 可复现性:通过图快照重现任意历史执行
● 可调试性:查看每个节点的输入输出
● 可追溯性:完整的执行链路记录
三、工作流存储与解析机制
1. Graph的JSON结构
工作流在数据库中以JSON字符串存储:
{
"nodes": [
{
"id": "start_1711527768326",
"data": {
"type": "start",
"title": "开始",
"variables": [
{
"variable": "research_topic",
"type": "text-input",
"label": "研究主题",
"required": true
},
{
"variable": "max_loop",
"type": "number-input",
"label": "最大迭代次数",
"default": 5
}
]
},
"position": {"x": 100, "y": 100}
},
{
"id": "llm_1711527784865",
"data": {
"type": "llm",
"title": "意图分析",
"model": {
"provider": "openai",
"name": "gpt-4",
"completion_params": {
"temperature": 0.7,
"max_tokens": 2000
}
},
"prompt_template": [
{
"role": "system",
"text": "你是一个研究助手"
},
{
"role": "user",
"text": "分析研究主题:{{#start_1711527768326.research_topic#}}"
}
],
"context": {
"enabled": true,
"variable_selector": ["start_1711527768326", "research_topic"]
}
},
"position": {"x": 300, "y": 100}
}
],
"edges": [
{
"id": "edge_1",
"source": "start_1711527768326",
"target": "llm_1711527784865",
"sourceHandle": "source",
"targetHandle": "target"
}
]
}
2. 解析与执行流程
class Workflow:
@property
def graph_dict(self) -> dict:
"""解析graph JSON为字典"""
return json.loads(self.graph) if self.graph else {}
def extract_user_inputs(self) -> list:
"""提取用户输入表单"""
nodes = self.graph_dict.get("nodes", [])
start_node = next(
(n for n in nodes if n["data"]["type"] == "start"),
None
)
return start_node.get("data", {}).get("variables", [])
def execute(self, inputs: dict) -> dict:
"""执行工作流"""
# 1. 构建执行图
engine = GraphEngine(self.graph_dict)
# 2. 初始化上下文
context = {"user_input": inputs}
# 3. 执行流程
result = engine.run(context)
# 4. 保存执行记录
self._save_execution_record(inputs, result)
return result
```
## 四、高级特性:Deep Research工作流实战
让我们看一个实际案例:如何用Dify构建类似ChatGPT Deep Research的功能。
### 4.1 核心设计思路
Deep Research的本质是**迭代式知识积累**:
1. 识别知识空白
2. 针对性搜索
3. 整合新知识
4. 重复直到满足需求
这需要三个关键技术:
- **Loop变量**:累积历史发现
- **结构化输出**:提取搜索问题
- **Agent节点**:自主决策工具使用
### 4.2 三阶段流程设计
**阶段1:研究基础建立**
```
Start Node (输入研究主题)
↓
Background Knowledge Node (获取初步信息)
↓
Intent Analysis Node (分析研究意图)
```
**阶段2:循环探索**
```
Loop Node {
current_loop = 0
findings = []
knowledge_gaps = []
while current_loop < max_loop:
↓
Reasoning Node (生成搜索问题)
↓
Agent Node (执行搜索 + 内容提取)
↓
URL Extraction (提取引用来源)
↓
Variable Assigner (更新状态)
current_loop += 1
findings += new_findings
knowledge_gaps = updated_gaps
}
Reasoning Node的结构化输出:
{
"reasoning": "当前已知X,Y,Z。缺失关于A的详细数据,需要查询...",
"search_query": "A领域的最新研究进展",
"knowledge_gaps": "缺少关于B的定量分析"
}
通过Dify的结构化输出编辑器,可以定义JSON Schema,确保输出格式一致。
Agent Node的工具配置:
tools = [
{
"name": "exa_search",
"description": "网络搜索工具",
"parameters": {"query": "string"}
},
{
"name": "exa_content",
"description": "获取网页全文",
"parameters": {"url": "string"}
},
{
"name": "think",
"description": "反思工具,整合当前发现",
"parameters": {"thoughts": "string"}
}
]
Agent节点会根据context自主选择工具,实现:
● 搜索 → 提取内容 → 整合思考 → 识别新问题
变量累积机制:
# 第1次迭代
findings = ["发现1"]
knowledge_gaps = ["问题A", "问题B"]
# 第2次迭代
findings = ["发现1", "发现2"] # 累加
knowledge_gaps = ["问题B", "问题C"] # 更新
# 第N次迭代
findings = ["发现1", ..., "发现N"]
knowledge_gaps = [] # 完全解决
```
**阶段3:综合报告**
```
Final Summary Node
↓
输入: findings + visited_urls + image_urls
↓
输出: Markdown格式报告 + 引用列表
3. 关键技术点
避免重复搜索
# 在Loop中维护搜索历史
executed_queries = []
# Agent搜索前检查
if query not in executed_queries:
results = search(query)
executed_queries.append(query)
来源追踪
# 自动提取Agent响应中的URL
import re
def extract_urls(text: str) -> list:
pattern = r'https?://[^\s<>"{}|\\^`\[\]]+'
return re.findall(pattern, text)
visited_urls += extract_urls(agent_response)
```
**3. 流式输出**
在工作流中放置多个Answer节点,实现:
```
Intent Analysis → Answer节点1 (显示研究方向)
↓
Loop迭代中 → Answer节点2 (显示搜索进度)
↓
Final Summary → Answer节点3 (显示最终报告)
```
用户可以实时看到研究进展,而不是等待全部完成。
## 五、技术栈与系统协同
### 5.1 后端架构
Dify的工作流引擎基于以下技术栈:
| 组件 | 技术选型 | 作用 |
|------|---------|------|
| Web框架 | Flask 3.1.0 + gevent | 提供REST API,支持异步I/O |
| 任务队列 | Celery + Redis | 异步执行长耗时节点 |
| 数据库*| PostgreSQL | 存储工作流定义和执行记录 |
| 向量数据库 | Weaviate/Qdrant | 支持Knowledge Retrieval节点 |
| 对象存储 | MinIO/S3 | 存储文件和模型输出 |
| 模型调用 | 统一Provider接口 | 支持OpenAI/Claude/DeepSeek等 |
### 5.2 服务协同关系
```
┌──────────────────────────┐
│ Flask API 服务 │ ← 用户HTTP请求
│ (工作流定义、触发执行) │
└────────────┬─────────────┘
│
↓
┌──────────────────────────┐
│ Celery Worker │ ← 执行工作流节点
│ (异步任务处理) │
└────────────┬─────────────┘
│
┌──────┼──────┬──────────┐
↓ ↓ ↓ ↓
PostgreSQL Redis LLM API 向量DB
(状态存储)(缓存)(模型调用)(知识检索)
完整启动流程
# 1. 启动中间件
docker compose -f docker-compose.middleware.yaml --profile weaviate up -d
# 2. 数据库迁移
flask db upgrade
# 3. 启动API服务
flask run --host 0.0.0.0 --port=5001
# 4. 启动Celery Worker(异步任务)
celery -A app.celery worker -P gevent -c 1 -Q dataset,mail,ops_trace
# 5. 启动Celery Beat(定时任务)
celery -A app.celery beat
```
## 六、实际应用场景
### 场景1:智能客服路由
```
用户问题
↓
Question Classifier (分类)
├→ 售前 → 产品知识库检索 → LLM生成
├→ 售后 → 订单API查询 → 工单系统
└→ 技术 → 技术文档检索 → 代码示例生成
```
### 场景2:内容审核流水线
```
用户发布内容
↓
文本审核节点 (敏感词检测)
├→ 通过 → 发布
└→ 疑似违规 → LLM二次判断
├→ 确认违规 → 拦截 + 通知
└→ 误判 → 人工复审队列
```
### 场景3:数据分析报告生成
```
上传数据文件
↓
Code Node (数据清洗)
↓
Loop Node (逐列分析)
↓
LLM Node (生成洞察)
↓
Template Transform (格式化报告)
↓
输出PDF报告
```
## 七、性能优化与最佳实践
### 7.1 性能优化
**1. 节点并行执行**
如果三个节点互不依赖,引擎会自动并行:
```
Start
├→ 知识库A检索
├→ 知识库B检索
└→ 实时API调用
↓
汇总节点
Dify的工作流系统通过以下设计实现了生产级AI应用编排
架构层面:
● DAG引擎保证执行顺序可靠
● 状态持久化支持可复现调试
● 事件驱动模型提升并发性能
功能层面:
● 16+节点类型覆盖主流场景
● 变量系统实现灵活数据流转
● Loop变量支持复杂迭代逻辑
工程层面:
● JSON Schema定义保证可移植性
● 结构化输出确保数据一致性
● 流式响应提升用户体验
这套系统的核心价值在于,将复杂的 AI编排逻辑从代码层提升到可视化层,让非开发人员也能构建复杂的AI应用.
这正是低代码AI平台的魅力所在。
