
新技术MedSAE:“查岗”医疗AI每步决策


医疗AI的最大矛盾是高准确率与低信任度。
例如强大的医学视觉语言模型(MedCLIP),虽然能诊断胸部X光片,但其内部决策过程对人类而言仍是不可审计的 “黑箱”。 这样的黑箱正是医疗AI信任的最大障碍。
一项来自意大利都灵大学的研究正让这一黑箱透明化,他们首次将稀疏自编码器(SAE)应用于此领域,成功命名了MedCLIP内部的深层特征。
AI终于能告诉我们:它在图像里看到了什么。

从MedCLIP到MedSAE:神经元说出的医学语言
基于自监督学习的MedCLIP是目前医学影像界最强大的视觉语言模型之一,它通过对胸部X光与放射学报告的对比学习,实现了跨模态特征理解。
但问题在于它缺乏透明度 。它们的内部通常由数亿甚至数十亿的参数构成,一个神经元同时对多个、不相关的概念(如心脏扩大和肺纹理异常)做出反应,
难以追踪AI的真正推理逻辑。
在临床场景中,这种“混乱”导致模型决策过程无法被追溯和验证,使放射科医生难以信任AI的诊断 。
MedSAE的核心创新正在打破这一混乱。
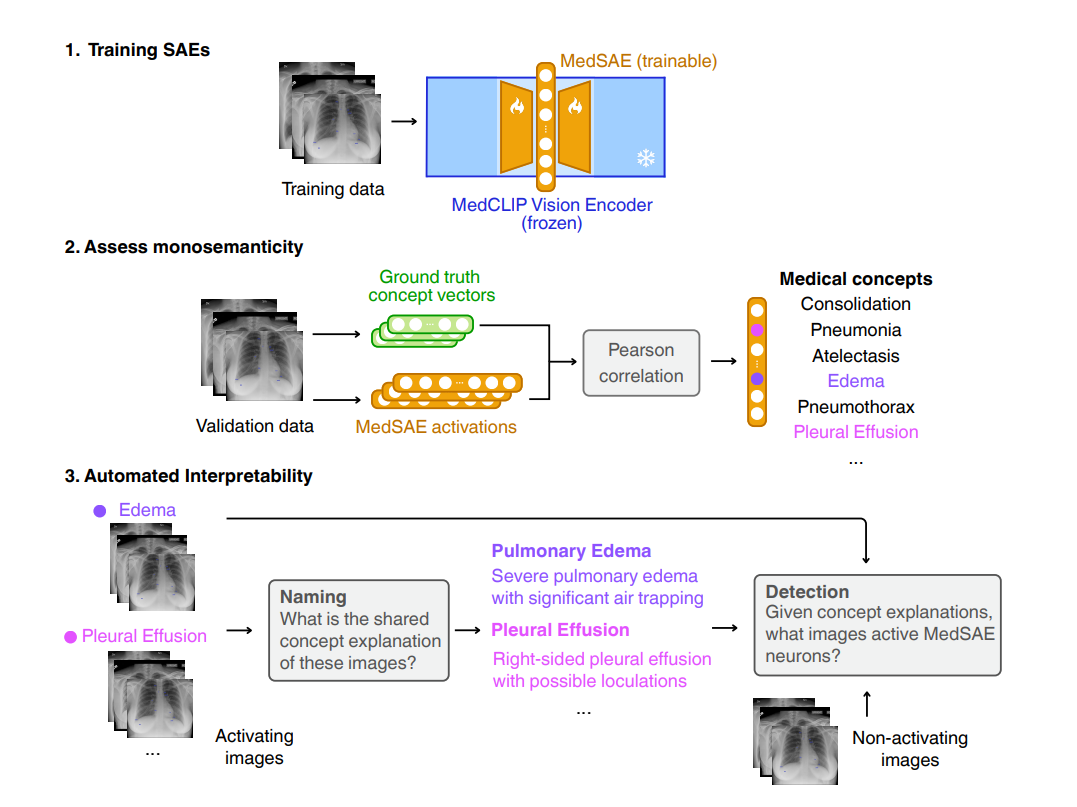
它通过稀疏自编码器(SAE),对MedCLIP进行了三个阶段的解析,将抽象空间转化为可命名的临床特征
特征解耦: 首先,在冻结的MedCLIP所产生的图像嵌入上训练MedSAE。通过SA的稀疏性特性,模型被迫在更高维度的空间中学习使用少量特征来重构输入,从而有效地解耦了MedCLIP中叠加的多义性特征。
单义性评估: 采用Pearson相关系数来量化每个SAE经元激活与特定医学发现(如肺水肿、气胸)标签之间的线性关系。并通过熵分析来度量这种相关性分布的集中度:熵值越低,单义性越高。
自动化命名与验证: 这是一个关键创新。研究利用 MedGEMMA基础模型,通过结构化提示,根据激活最高的X光图像集,自动生成该SAE神经元所编码的共享概念解释。随后,通过检测任务来验证命名准确性。
结果显示,MedSAE的平均神经元熵为2.25,显著低于原始MedCLIP的2.38,意味着其内部特征被更成功地“拆解”为医学语义单元。
实验成功:21个可信赖的临床语义锚点
据实验数据显示,MedSAE在CheXpert胸片数据集上识别出21个可验证的临床特征神经元,涵盖水肿、气胸、心脏肥大等关键病理模式。
这些概念与临床诊断高度一致,例如“严重的肺水肿伴明显的空气滞留”、“右侧胸腔积液伴可能的小叶间隔 ”$。相比之下,原始MedCLIP嵌入仅能识别出两个这样的概念。
这21个高准确率的神经元概念,为 AI诊断提供了可审计、可追溯的临床语义锚点,通过MedGEMMA生成的神经元标签,再反向用于构建疾病特征知识库,未来或将形成机器可读的医学概念体系。

从性能导向到透明导向
稀疏自编码器SAE的加入,为医疗AI的机器可读提供了一种可扩展且自动化的路径
未来医学AI的核心竞争力不再是准确率,而是可解释性。能清晰说明为何做出某种判断的AI,将更容易获得医疗机构的信任与监管机构批准。
这一框架不仅限于医疗影像,可被推广到金融、遥感等高复杂性领域,用以克服AI的机制可解释性。
