
RAG穿戴式医疗AI:让大模型“上身”的关键突破


一位AI医生,它不仅能实时监测你的心率和血糖,还能结合你过去20年的完整医疗档案,给出完全个性化的健康建议。
这就是可穿戴医疗AI的未来。
但当AI部署到轻薄的边缘设备(如智能手表)上时,却存在着阻碍,能源和内存。
国内研究团队在该领域实现了突破,传统的检索增强生成(RAG)在翻阅你的档案时,会造成不可承受的能耗和延迟。这项突破将RAG的能耗降低了99.6%,内存访问量减少近50%。
这意味着,随身AI医生不再只是概念。

医疗AI的瓶颈:99%的能量消耗在"搬运数据"
当前医疗AI的核心矛盾是:用户希望AI能调取个人完整病历来提供精准建议,但延迟和隐私担忧要求数据必须存储在本地可穿戴设备中。
如何让大模型在不联网、不上云的前提下读取并理解个体健康数据,如血糖、脑电、心率与影像报告,成了医疗AI亟待解决的难题。
检索增强生成(RAG)技术原本是最理想的解决方案,它能将个人医疗文档转化为高维向量嵌入存储在设备离线数据库中,,询时通过相似度计算匹配最相关的文档片段,再送入大模型生成回复。
但问题出在RAG的检索阶段。
在1MB规模的INT8量化文档嵌入数据库中进行一次完整查询,外部DRAM的数据传输占据了总能耗的98.8%,片上处理逻辑仅占0.2%。
这是因为可穿戴设备的片上SRAM容量极其有限(通常不足1MB),必须频繁从外部存储器加载文档嵌入向量进行相似度计算,而DRAM的读取能耗高达40 pJ/bit,相当于每读取1KB数据就要消耗320纳焦能量。
这使得RAG无法真正运行在功率仅几十毫瓦的可穿戴设备上。
反直觉的突破:两阶段50%能耗节省
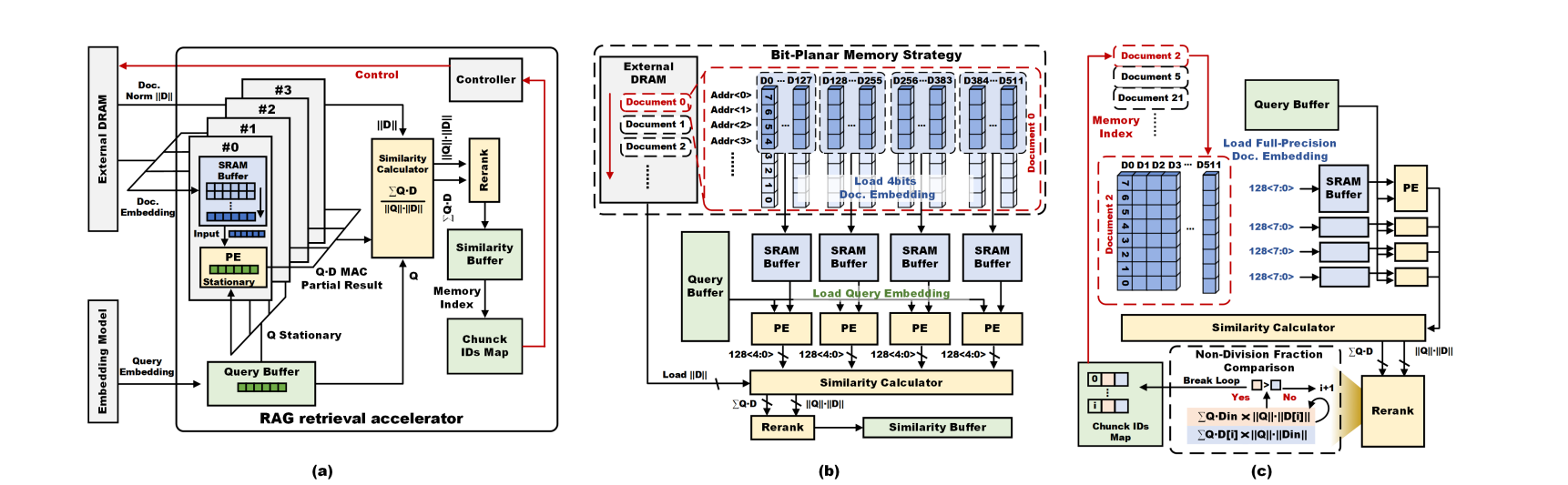
研究团队提出的层级检索架构,传统RAG系统要么使用全精度浮点数(FP32)导致能耗爆炸,要么统一量化到INT8但仍需全量扫描数据库。研究团队的方案巧妙的将检索过程拆解为两个非对称阶段:
第一阶段:近似检索(INT4)
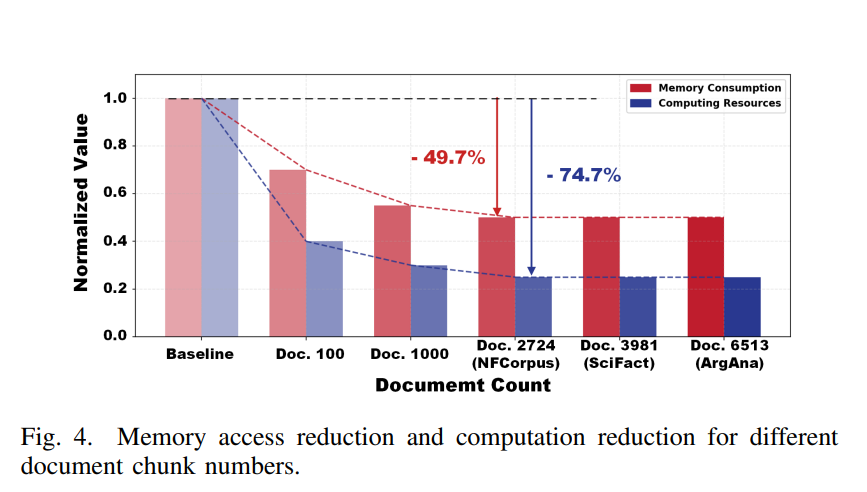
只读取每个嵌入向量最高的4位,快速筛选出前50个候选文档。这一步能将DRAM访问量直接减半,同时能耗降低约50%。
第二阶段:精确检索(INT8)
仅针对第一阶段选出的50个候选文档进行全精度(8位)计算,实现与原始检索几乎相同的准确率。
这种设计的精妙之处在于精度损失的不对称分布。
实验数据显示,在SciFact、NFCorpus、ArguAna三个医疗/科学领域数据集上,纯INT4检索的Precision@1分别为0.483、0.368、0.248,而分层检索达到0.497、0.412、0.253——已接近纯INT8的性能(0.507、0.421、0.253)。
这一整套架构让系统在TSMC 28nm工艺下,仅以0.077平方毫米芯片面积实现了与RTX 3090相近的检索精度。
实验验证:177微焦耳/次查询
这项研究的可信度在于全流程的后端验证。团队使用Synopsys Design Compiler完成数字电路综合,在Cadence Innovus平台进行自动布局布线,最终通过Synopsys VCS和PrimeTime进行后端时序与功耗仿真。
意味着所有数据都基于真实物理版图,而非理想化的RTL模型。
实验结果显示,完整查询1MB医疗嵌入数据,仅消耗177.76微焦耳(µJ)。
相比GPU级RAG系统(86毫焦耳),节能比例接近500倍。
换句话说,一块小型电池可支撑数十万次本地医疗问答而无需联网。

可穿戴医疗AI发展路径
本研究用28nm工艺却实现了性能超越8nm的RTX3090,暗示了未来可穿戴设备的发展路径,在特定任务场景下,架构创新对能效的提升远超制程演进带来的有收益。
在摩尔定律放缓的时代,针对垂直应用场景的定制化设计,可能比盲目追求先进制程更具商业价值。
当芯片算力被"喂数据"的速度拖累,优化单位带宽下的能效算力或许更有性价比。
