
腾讯、清华联合发布:从离散token到连续向量


在大型语言模型(LLM)逼近物理算力极限的今天,其自回归生成机制正成为效率的“阿喀琉斯之踵”。
据国外研究机构估算,GPT-4生成千字文本的推理成本超过0.1美元,而长达数秒的响应延迟更制约了实时应用场景
当传统LLM仍在逐token缓慢生成时,腾讯微信AI团队已让每个计算步骤承载4倍语义信息,计算成本降低34%,性能反而提升。

论文链接:https://arxiv.org/pdf/2510.27688
项目链接:https://github.com/shaochenze/calm
传统LLM的根本性缺陷:离散token的信息密度天花板
当前语言模型普遍存在计算效率瓶颈,其自回归生成过程需要逐步预测每个离散token。
由于词汇表大小限制(通常3.2万-25.6万),每个token仅携带15-18比特信息。若要提升信息密度,词汇表需指数级扩张,导致softmax计算成为不可承受之瓶颈。
CALM框架的核心突破在于将离散token序列压缩为连续向量,通过训练一个高保真自编码器,可将K个token(实验显示K=4最优)压缩为单个连续向量,重构准确率超99.9%。
这意味着生成步骤直接减少K倍,从根本上重构了计算效率曲线。
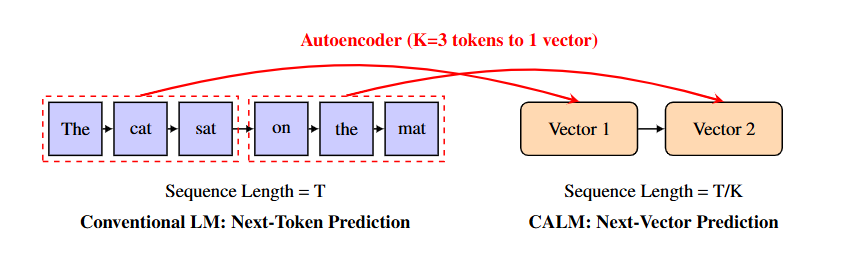
三大技术支柱支撑
1. 自编码器(VAE)
单纯追求重构准确率的自编码器会学习到脆弱表示,潜在空间缺乏平滑性。CALM引入变分正则化,使编码器输出高斯分布参数(μ, σ),通过KL散度损失约束潜在分布接近标准正态。采用KL裁剪策略(λ=0.5)防止后验坍塌,确保所有维度都参与信息编码。
2. 能量变换器
传统softmax无法处理连续向量空间的概率分布。CALM采用能量分数作为训练目标:
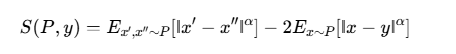
其中α∈(0,2)保证严格恰当性。通过蒙特卡洛估计,只需从生成头采样即可计算损失,完全避开似然计算。
3. BrierLM评估体系
传统困惑度指标在此失效。团队提出BrierLM评分,基于Brier分数的严格恰当评分规则:
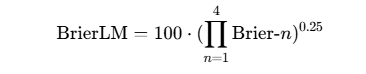
实证显示与交叉熵损失相关系数达-0.966,成为衡量连续语言模型性能的可靠指标。

性能突破:计算成本降低34%
在Pile数据集上的测试表明:
● CALM-M(371M参数)达到Transformer-S(281M参数)相当性能,训练FLOPs降低44%,推理FLOPs降低34%
● 潜在维度l=128时最优,过小导致表征脆弱,过大引入噪声特征
● 缩放模型规模时,CALM展现比传统Transformer更陡峭的学习曲线,说明其能从参数增加中获得更大收益
温度采样:精确控制无需似然
● 传统温度采样依赖概率分布显式操作。CALM提出精确拒绝采样算法:对温度T=1/n(n为整数),通过n次采样拒绝机制实现分布
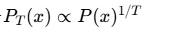
● 支持任意温度扩展,采用两阶段采样处理整数和小数部分
● 批量近似算法通过组合搜索提升采样效率,渐近无偏性得到理论保证

语义带宽带来的竞争新维度
CALM 不是一次预测一个词元,而是预测代表多个词元的连续向量。也就是说,模型不再是逐字思考,而是按步骤思考想法。
1. 预测步骤减少 4 倍
2. 训练计算量减少 44%
3. 不使用离散词汇,纯粹的连续推理
4. 新指标(BrierLM)完全取代了困惑度
模型开始从说摩尔斯电码,到能流畅的表达完整想法,加上框架开源,这场连续向量革命可能重新定义2026年语言模型的竞争格局。
