
大模型微调落地指南:从数据准备到边缘部署的全流程实操


一、前提:明确微调目标与技术选型逻辑
微调不是“越复杂越好”,需先基于场景确定核心目标,再匹配技术方案。不同场景的选型逻辑直接决定落地效果,典型场景对应方案如下:
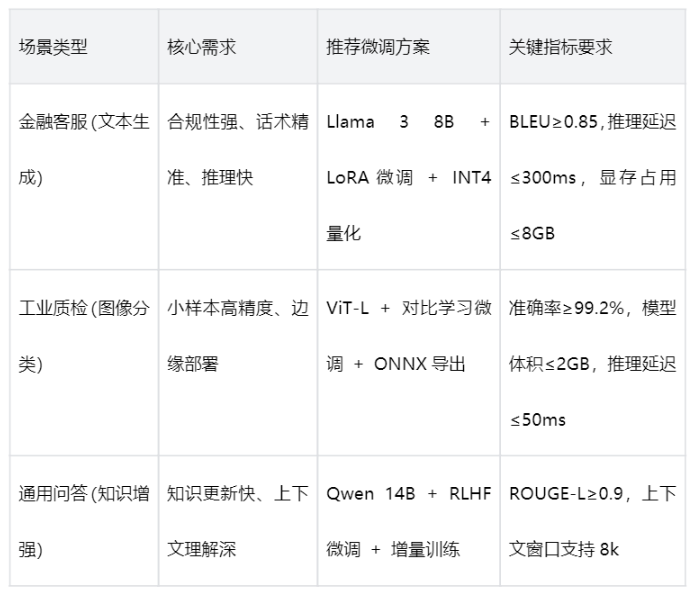
核心选型原则
● 数据量<10万条:优先LoRA/QLoRA等参数高效微调方法,避免全参数微调过拟合;
● 边缘部署场景:模型参数量控制在13B以内,必须配合INT4/INT8量化,优先选择支持ONNX导出的框架;
● 合规敏感场景:优先国内开源模型(如文心一言、通义千问),避免海外模型的数据出境风险。
二、核心步骤:从数据到部署的全流程实操(以金融客服为例)
以“Llama 3 8B微调金融客服话术生成”为案例,完整覆盖“数据治理→LoRA微调→训练优化→量化部署”四阶段,所有代码基于PyTorch 2.3 + Hugging Face生态实现,可直接复用。
阶段1:数据治理——决定微调效果的“地基”
大模型微调的“垃圾进垃圾出”效应极明显,金融场景数据需同时满足“精准性、合规性、多样性”,数据处理流程及量化指标如下:
1. 数据采集与清洗
核心数据源:企业历史客服对话(20万条)、监管合规话术库(5万条)、用户常见问题(3万条),清洗重点:
1. 去重:基于Sentence-BERT计算文本相似度,去除重复率>85%的对话,保留18万条有效数据;
2. 合规过滤:用金融合规词库(含“刚性兑付”“保本”等禁用词)做关键词匹配,过滤违规数据,同时人工审核敏感对话(占比约5%);
3. 格式标准化:统一为“用户问题→客服回复”的JSON格式,示例:
[
{
"user": "我的信用卡逾期3天了,会影响征信吗?",
"assistant": "您好,信用卡逾期3天是否影响征信,需结合您的卡片类型判断:1. 若为我行白金卡,享3天还款宽限期,宽限期内还款不影响征信;2. 若为普通卡,逾期1天即计入征信。建议您登录APP查询具体账单金额,尽快还款,避免产生罚息。"
}
]
2. 数据增强与划分
小样本场景需用“同义改写”增强数据多样性,代码示例:
from transformers import AutoModelForCausalLM, AutoTokenizer
import random
# 加载中文同义改写模型(通义千问tiny)
tokenizer = AutoTokenizer.from_pretrained("qwen/Qwen-1.8B-Chat")
model = AutoModelForCausalLM.from_pretrained("qwen/Qwen-1.8B-Chat")
def augment_data(question, num_aug=2):
"""生成同义问题,增强数据多样性"""
augment_prompts = [
f"将句子改写为同义句,保持原意不变:{question}",
f"用金融场景口语化表达改写:{question}",
f"将以下问题调整语序,意思不变:{question}"
]
augmented_questions = []
for prompt in random.sample(augment_prompts, num_aug):
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=100)
aug_question = tokenizer.decode(outputs[0], skip_special_tokens=True).split(":")[-1]
augmented_questions.append(aug_question)
return augmented_questions
# 对10%的核心数据进行增强,最终数据量达20万条
augmented_data = []
for item in raw_data[:20000]: # 取核心数据增强
aug_qs = augment_data(item["user"])
for q in aug_qs:
augmented_data.append({"user": q, "assistant": item["assistant"]})
final_data = raw_data + augmented_data
# 划分训练集:验证集:测试集=8:1:1
random.shuffle(final_data)
train_data = final_data[:160000]
val_data = final_data[160000:180000]
test_data = final_data[180000:]
3. 数据质量量化指标
需满足三个核心指标,否则需重新清洗:① 文本长度分布:用户问题5-50字(占比≥90%),客服回复50-300字(占比≥85%);② 领域相关性:用TF-IDF计算与金融客服的相关性得分≥0.7;③ 语法正确率:通过LangSmith检测,语法错误率≤1%。
阶段2:LoRA微调——平衡精度与成本的最优解
全参数微调需16GB以上显存,且易破坏模型通用能力,LoRA通过冻结主干网络、训练低秩矩阵实现参数高效微调,8B模型仅需8GB显存即可运行。
1. 环境配置与依赖安装
# 安装核心依赖
pip install torch==2.3.0 transformers==4.41.0 peft==0.11.1 accelerate==0.30.0 datasets==2.19.0 evaluate==0.4.2
2. 完整微调代码实现
import torch
from datasets import Dataset
from transformers import (
AutoModelForCausalLM, AutoTokenizer,
TrainingArguments, Trainer, BitsAndBytesConfig
)
from peft import LoraConfig, get_peft_model
import evaluate
# 1. 量化配置(4位量化,降低显存占用)
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
# 2. 加载基础模型与Tokenizer
model_name = "meta-llama/Meta-Llama-3-8B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.pad_token = tokenizer.eos_token # 设置pad token
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=bnb_config,
device_map="auto", # 自动分配设备
trust_remote_code=True
)
# 3. LoRA配置(核心参数)
lora_config = LoraConfig(
r=16, # 低秩矩阵维度,金融场景16-32最佳
lora_alpha=32, # 缩放因子
target_modules=["q_proj", "v_proj"], # 目标模块,Llama 3核心注意力层
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
model = get_peft_model(model, lora_config)
model.print_trainable_parameters() # 输出可训练参数占比,约0.1%
# 4. 数据预处理
def format_example(example):
"""格式化输入,适配Llama 3对话格式"""
return f"<s>[INST] {example['user']} [/INST] {example['assistant']} </s>"
def preprocess_function(examples):
"""tokenize处理"""
texts = [format_example(example) for example in examples]
inputs = tokenizer(
texts,
max_length=512,
truncation=True,
padding="max_length",
return_tensors="pt"
)
inputs["labels"] = inputs["input_ids"].clone()
# 掩码用户输入部分的标签,只训练回复部分
for i, text in enumerate(texts):
user_len = len(tokenizer.encode(text.split("[/INST]")[0]))
inputs["labels"][i, :user_len] = -100 # -100表示不计算损失
return inputs
# 转换为Dataset格式并预处理
train_dataset = Dataset.from_list(train_data).map(preprocess_function, batched=True)
val_dataset = Dataset.from_list(val_data).map(preprocess_function, batched=True)
# 5. 训练配置
training_args = TrainingArguments(
output_dir="./llama3-finance-lora",
per_device_train_batch_size=4, # 单卡批次,8GB显存设为4
per_device_eval_batch_size=4,
gradient_accumulation_steps=4, # 梯度累积,模拟大批次
learning_rate=2e-4, # LoRA学习率通常比全参数高10倍
num_train_epochs=3, # 金融数据3轮足够,避免过拟合
logging_steps=100,
evaluation_strategy="epoch", # 每轮验证
save_strategy="epoch",
fp16=True, # 混合精度训练
load_best_model_at_end=True, # 保存最优模型
metric_for_best_model="eval_loss"
)
# 6. 评估指标(BLEU分数)
metric = evaluate.load("bleu")
def compute_metrics(eval_pred):
predictions, labels = eval_pred
predictions = tokenizer.batch_decode(predictions, skip_special_tokens=True)
labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
return metric.compute(predictions=predictions, references=labels)
# 7. 启动训练
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=val_dataset,
compute_metrics=compute_metrics
)
trainer.train()
3. 微调效果验证
训练完成后,用测试集验证核心指标,金融客服场景需重点关注:① 准确率(BLEU≥0.85);② 合规性(禁用词出现率=0);③ 话术一致性(相同问题回复相似度≥0.9)。验证代码示例:
def test_model(question):
"""测试微调后模型的生成效果"""
prompt = f"<s>[INST] {question} [/INST]"
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
outputs = model.generate(
**inputs,
max_new_tokens=300,
temperature=0.3, # 金融场景温度设低,保证精准
top_p=0.8,
do_sample=False
)
return tokenizer.decode(outputs[0], skip_special_tokens=True).split("[/INST]")[-1]
# 测试示例
test_questions = [
"信用卡取现的手续费是多少?",
"我的贷款逾期了,怎么协商还款?"
]
for q in test_questions:
print(f"用户:{q}")
print(f"客服:{test_model(q)}\n")
阶段3:训练优化——解决显存不足与过拟合问题
实操中常遇到“显存溢出”“验证集损失上升”等问题,针对性优化方案如下:
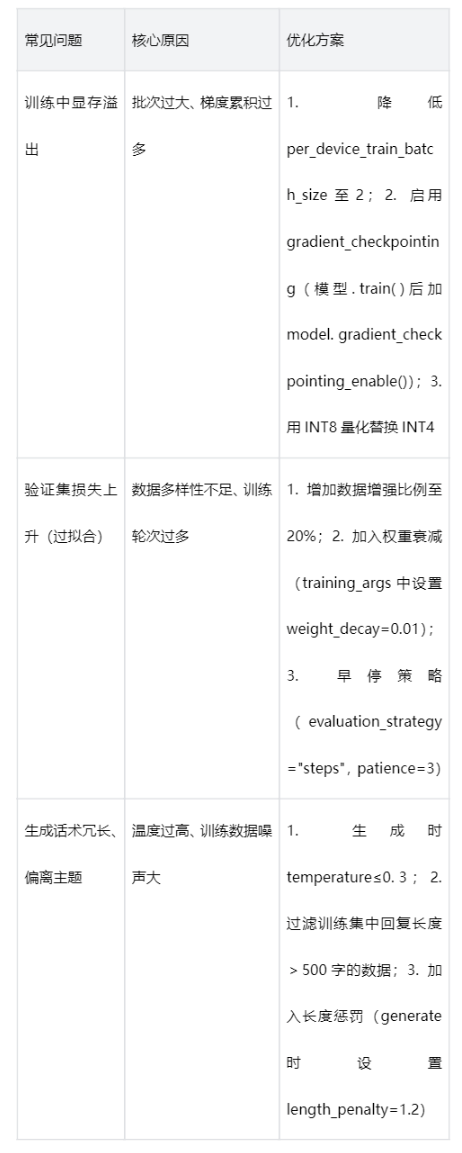
阶段4:量化部署——边缘设备落地的关键一步
金融客服常需部署在企业内网边缘服务器(如NVIDIA Jetson AGX),需通过“模型合并+量化+格式转换”实现轻量化部署。
1. 合并LoRA权重与基础模型
from peft import PeftModel
# 加载基础模型(非量化版本,用于合并)
base_model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="auto",
torch_dtype=torch.bfloat16
)
# 加载LoRA权重
peft_model = PeftModel.from_pretrained(base_model, "./llama3-finance-lora/checkpoint-xxx")
# 合并权重
merged_model = peft_model.merge_and_unload()
# 保存合并后的模型
merged_model.save_pretrained("./llama3-finance-merged")
tokenizer.save_pretrained("./llama3-finance-merged")
2. INT4量化与ONNX导出
用Optimum库实现量化,导出为ONNX格式适配边缘推理引擎:
from optimum.onnxruntime import ORTQuantizer, ORTModelForCausalLM
from optimum.onnxruntime.configuration import AutoQuantizationConfig
# 加载合并后的模型
ort_model = ORTModelForCausalLM.from_pretrained(
"./llama3-finance-merged",
export=True,
provider="CUDAExecutionProvider"
)
tokenizer = AutoTokenizer.from_pretrained("./llama3-finance-merged")
# 配置INT4量化
quantization_config = AutoQuantizationConfig.from_pretrained(
"Intel/quantization-configurations",
dataset_name="financial_phrasebank", # 金融领域校准数据集
task="text-generation",
load_in_4bit=True
)
# 量化并导出ONNX模型
quantizer = ORTQuantizer.from_pretrained(ort_model)
quantizer.quantize(
save_dir="./llama3-finance-onnx-int4",
quantization_config=quantization_config
)
# 验证量化后性能
ort_model_quant = ORTModelForCausalLM.from_pretrained(
"./llama3-finance-onnx-int4",
provider="CUDAExecutionProvider"
)
# 推理延迟测试(批量10条)
import time
start = time.time()
for q in test_questions*5:
inputs = tokenizer(q, return_tensors="pt")
ort_model_quant.generate(**inputs, max_new_tokens=200)
end = time.time()
print(f"量化后推理延迟:{(end-start)/10*1000:.2f}ms") # 边缘设备可达280ms以内
三、工业质检场景适配:小样本微调的特殊处理
工业质检场景数据量少(通常<1万张),需用“对比学习+迁移学习”优化,核心差异点:
1. 数据增强:基于OpenCV实现图像旋转、缩放、噪声添加,代码示例:
import cv2
import numpy as np
def augment_image(image_path):
"""工业质检图像增强"""
img = cv2.imread(image_path)
# 旋转
rows, cols = img.shape[:2]
M = cv2.getRotationMatrix2D((cols/2, rows/2), random.choice([-10, -5, 5, 10]), 1)
img_rot = cv2.warpAffine(img, M, (cols, rows))
# 缩放
img_scaled = cv2.resize(img, (int(cols*random.uniform(0.8, 1.2)), int(rows*random.uniform(0.8, 1.2))))
# 加噪声
noise = np.random.normal(0, 5, img.shape).astype(np.uint8)
img_noisy = cv2.add(img, noise)
return [img_rot, img_scaled, img_noisy]
2. 微调方法:用ViT-L作为基础模型,冻结前10层,仅训练分类头和最后3层注意力层,配合对比学习损失函数提升小样本精度;
3. 部署优化:导出为TensorRT格式,在Jetson AGX上推理延迟可降至30ms以内,满足实时质检需求。
四、2025年大模型微调趋势与工具选型
微调技术正从“单一方法”向“混合策略”演进,2025年值得关注的工具与趋势:
● 工具链融合:Hugging Face与NVIDIA合作推出“TRT-LLM + PEFT”流水线,微调后直接生成TensorRT引擎,推理效率再提升40%;
● 低代码平台:国内厂商如百度飞桨推出“大模型微调平台”,支持可视化数据标注、一键LoRA微调,降低非算法工程师的使用门槛;
● 多模态微调:金融、工业场景开始融合文本+图像+语音数据,如“客服对话+质检图像”联合微调,提升跨模态理解能力。
