
AI真的懂药理机制吗?一场医学测试告诉你


大模型能写病例、解剖病理,但在个性化医疗领域,LLM要发挥作用必须具备对药物作用机制的深度理解。
它是否真正懂药物机制?
国内的最新研究首次构建了一个知识+推理双层评测体系,系统检验了GPT-4、Claude、Med-PaLM等医学LLM在药理学认知中的真实水平。

论文链接:https://arxiv.org/pdf/2511.06418
研究背景:AI的药理认知问题
医学大模型的强大语言生成能力掩盖了一个关键问题,它们往往只复述知识,而非真正理解药物机制。
传统评测(如MedQA、PubMedQA)主要考察记忆能力,即模型能否复述正确答案。
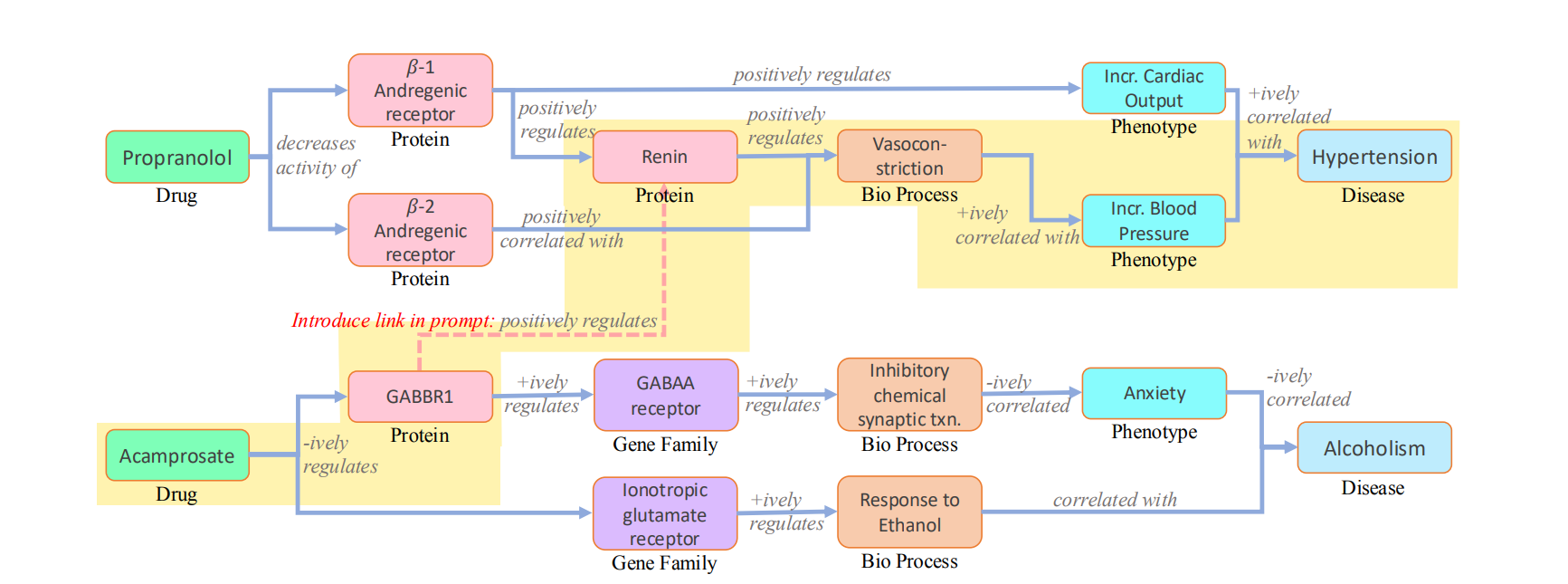
但药物机制的理解要求AI具备因果链式推理,也就是从“靶点-作用途径-生理反应-副作用”建立系统性逻辑。
研究团队提出了一个基于药理知识图谱的评测数据集,既考察模型是否知道事实,也检验其是否能推理出因果链。
研究设计:双层评测体系
研究团队构建了 DrugMechanQA 数据集,覆盖超过500种药物与2000个临床场景,包含两类任务:
知识层任务
测试模型是否掌握药物基础属性:靶点、代谢途径、作用部位、副作用。如β受体阻滞剂为何可降低心率?
推理层任务
测试模型是否能基于知识推导出新的临床结论。如若患者因肝功能受损导致CYP3A4活性下降,某药物血药浓度会如何变化?
为确保科学性,研究采用了专家注释+多模型对比+逻辑链评分。
评估维度包括:
● 事实准确率
● 推理一致性
● 解释透明度
结论:GPT-4懂药,但不懂为什么
根据研究数据,在DrugMechanQA评测中:
GPT-4在知识任务上准确率达87%,表现接近药理学硕士水平,但在推理任务上准确率骤降至58%,Claude 3和Med-PaLM 2在复杂因果题上正确率不足50%。
关键问题出在推理链断裂,模型往往能正确指出药物与靶点,但在推导“药效变化-副作用风险”逻辑时频繁出现幻觉或跳步结论。
例如,当问“他汀类药物为何与葡萄柚汁同服风险高”时,GPT-4给出的理由仅为代谢冲突,而未指出关键CYP3A4抑制机制。

医学AI未来方向的重新校准
未来医学LLM应具备因果图谱能力,将药理知识结构化编码,而非仅依赖语料学习。
当模型能真正理解药物机制,它将不再只是搜索工具,而是能根据患者病理生理特征进行个体化药理推理。
这将极大提升AI在药物相互作用预测、剂量优化与临床试验设计中的应用价值。
