
Kimi K2 Thinking实战指南:比肩GPT-5的开源推理模型


一个开源模型,不仅在成本上是GPT-5的1/4、Claude 4.5 的1/6,在某些核心能力上还能超越这两个闭源巨头,这听起来像天方夜谭。
但 Moonshot AI在2025年11月发布的 Kimi K2 Thinking做到了。
更关键的是,K2能够自主执行200~300次连续的工具调用,而大多数模型只能处理几十次。
这意味着什么?意味着你可以让它自主完成复杂的研究任务、数据分析流程和调试工作流,中间完全不需要人工干预。
技术架构
模型类型:Mixture-of-Experts(专家混合)架构
总参数量:1万亿(Trillion)
单次激活参数:约320亿
上下文长度:256K tokens(可处理整份代码库或长篇报告)
量化支持:INT4(延迟减半,精度损失小)
一、Kimi K2 Thinking 为什么特别?
1. 架构设计上实现性能与成本的平衡
大多数大模型要么参数少(推理快但能力弱),要么参数多(能力强但成本高)。
K2采用了一种巧妙的折中方案,混合专家架构(Mixture-of-Experts)。
想象一个拥有1万亿参数的超级大脑,但每次只激活其中320亿参数来处理任务。就像一个大公司有很多专家,但每个项目只调动最相关的那几个人参与,既保证了专业性,又控制了成本。
实际意义上,上下文窗口256,000 tokens(约 19 万汉字),足以容纳整个代码库或长篇文档;推理成本上,输入$0.60/百万tokens,输出$2.50/百万 tokens。
对比来看,GPT-5的输出成本是$10/百万tokens,Claude 4.5更是高达$15/百万tokens。
2. 两个版本
Moonshot AI 发布了两个版本
K2 Instruct:适合快速响应场景,如文本分类、简单问答
K2 Thinking::专为复杂推理任务设计,本文的主角
如果你的任务需要多步推理、工具调用或复杂决策,必须用 Thinking 版本。
3. 两大核心能力
推理过程透明
传统模型是"黑箱",你只能看到最终答案,不知道它是怎么想的。K2 不同,它会把完整的思考过程暴露给你。
例如在调试AI系统时,当模型给出错误答案,你能看到它在哪一步出错。
超长工具编排
工具调用就是让AI使用API来获取信息和执行操作。比如让AI查询数据库、调用天气 API、运行代码等。
K2的独特之处在于,大多数模型处理20~50次连续工具调用后就会掉链子,K2 能稳定处理 200~300 次。
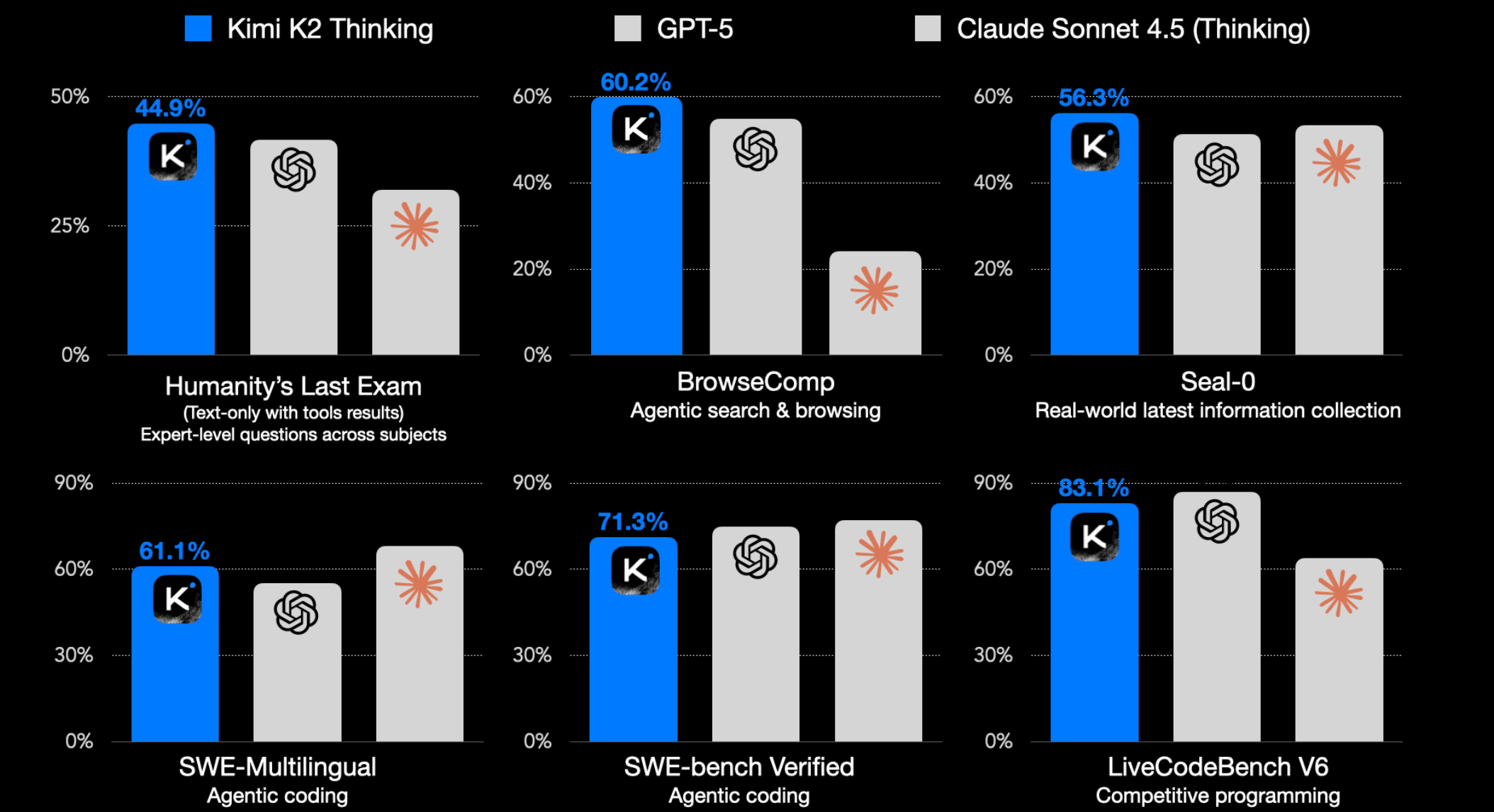
二、性能对比:K2 vs GPT-5 vs Claude 4.5
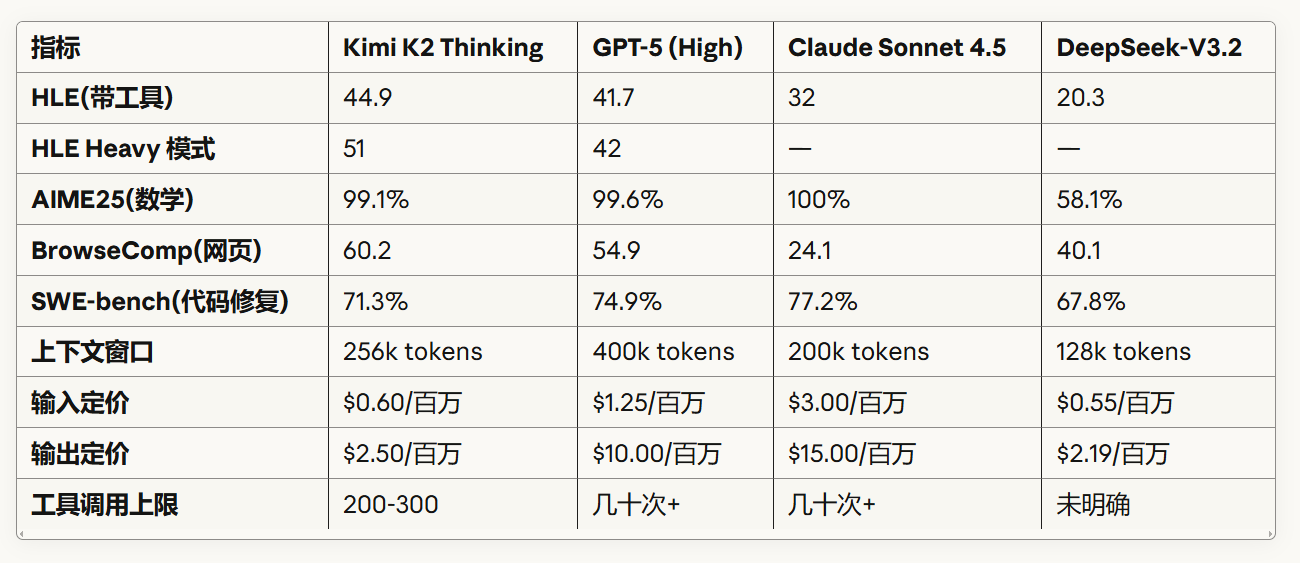
K2的优势
智能体任务:在Heavy模式下,K2 领先GPT-5达9分,因为它并行运行8条推理路径并选择最佳答案
网页导航:K2显著领先,这对需要自主网络研究的应用至关重要
成本敏感场景:输出成本仅为GPT-5的1/4,Claude的1/6
三、Ollama本地部署
# 下载模型
ollama pull kimi-k2:1t-cloud
# 运行交互模式
ollama run kimi-k2:1t-cloud
启动 Ollama API 服务
# 在后台启动 Ollama 服务
ollama serve
服务会在 http://localhost:11434 启动。
验证服务:
curl http://localhost:11434/api/tags
安装 Python 依赖
pip install openai python-dotenv
运行第一个 Python 脚本
from openai import OpenAI
# 连接到本地 Ollama
client = OpenAI(
base_url="http://localhost:11434/v1",
api_key="ollama" # Ollama 不需要真实密钥,随便填
)
# 调用 Kimi K2
response = client.chat.completions.create(
model="kimi-k2:1t-cloud",
messages=[
{"role": "user", "content": "15 乘以 24 等于多少?请展示计算步骤。"}
]
)
print(response.choices[0].message.content)
流式输出(实时显示生成过程)
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:11434/v1",
api_key="ollama"
)
# 启用流式输出
stream = client.chat.completions.create(
model="kimi-k2:1t-cloud",
messages=[
{"role": "user", "content": "写一首关于程序员的打油诗"}
],
stream=True # 关键参数
)
# 逐字输出
for chunk in stream:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
print() # 换行
效果:你会看到诗句一个字一个字地出现,就像 ChatGPT 的打字效果。
四、K2 Thinking的思考模式
K2的核心特征是推理可见性:
每次API响应都包含两部分内容
● content:最终答案
● reasoning:模型的完整思考链
示例
response = client.chat.completions.create(
model="kimi-k2-thinking:cloud",
messages=[{"role": "user", "content": "一台850元的笔记本打8折后再加8%的税,实付多少?"}],
temperature=1.0
)
print("最终结果:", response.choices[0].message.content)
print("思考过程:", response.choices[0].message.reasoning)
输出
最终结果:实付734.40元
思考过程:
1. 850×0.2=170(折扣)
2. 850-170=680(折后价)
3. 680×0.08=54.4(税)
4. 680+54.4=734.4(总价)
建议:
● 设置 temperature=1.0以确保模型能充分探索推理空间。
● 使用 max_tokens=4096以上,否则推理链可能被截断。
五、打造可调用外部数据的工具工作流
K2 Thinking支持标准JSON工具定义(与OpenAI格式兼容)。
以下示例展示如何让模型调用一个分析CSV文件的工具
tools = [{
"type": "function",
"function": {
"name": "analyze_csv",
"description": "分析CSV文件,返回列名、样例行、总行数和文件大小。",
"parameters": {
"type": "object",
"properties": {
"filepath": {"type": "string"},
"num_rows": {"type": "integer", "default": 10}
},
"required": ["filepath"]
}
}
}]
实现函数
import csv, os, json
def analyze_csv(filepath: str, num_rows: int = 10):
if not os.path.exists(filepath):
return {"error": f"未找到文件:{filepath}"}
with open(filepath, 'r') as f:
reader = csv.DictReader(f)
columns = reader.fieldnames
sample_rows = [dict(row) for i, row in enumerate(reader) if i < num_rows]
total_rows = sum(1 for _ in open(filepath)) - 1
return {
"columns": columns,
"sample_rows": sample_rows,
"total_rows": total_rows,
"file_size_kb": round(os.path.getsize(filepath) / 1024, 2)
}
核心循环逻辑(模型自主多轮调用工具)
messages = [{"role": "user", "content": "分析 employees.csv 中工程部门的平均薪资"}]
while True:
resp = client.chat.completions.create(
model="kimi-k2-thinking:cloud",
messages=messages,
tools=tools,
temperature=1.0
)
msg = resp.choices[0].message
if resp.choices[0].finish_reason == "tool_calls":
for call in msg.tool_calls:
args = json.loads(call.function.arguments)
result = analyze_csv(**args)
messages.append({"role": "tool", "content": json.dumps(result), "tool_call_id": call.id})
else:
print(msg.content)
break
输出示例
工程部门共有5名员工,平均薪资为97,400元。
六、多模型对比可视化应用(K2 / GPT-5 / Claude)
如果你想直观比较不同模型的推理差异,可使用 Streamlit 快速搭建一个多模型对比界面。
安装依赖
pip install streamlit openai anthropic python-dotenv
核心思路:
1. 同时向K2、GPT-5、Claude发送同一问题
2. 并行返回结果
3. 展示每个模型的答案与思考链。
关键代码段
cols = st.columns(3)
for idx, (name, data) in enumerate(responses.items()):
with cols[idx]:
st.markdown(f"### {name}")
if data["reasoning_content"]:
with st.expander("思考过程", expanded=False):
st.markdown(data["reasoning_content"])
st.markdown(data["content"])
运行
streamlit run model_comparison_chat.py
结论
总体而言,K2 Thinking 具备五大核心优势。
首先,它拥有透明推理能力,能让用户清楚看到模型的思考过程,真正实现可解释性AI。
其次是高级工具编排能力,单次会话中最多可连续调用三百个外部函数,支持复杂业务工作流的构建。
第三,它在运行效率上表现突出,通过INT4量化与专家混合架构,大幅降低了推理延迟与算力消耗。
第四,对于产品经理与开发团队而言,K2 的思考链输出让每一步决策逻辑都可验证,结果可控性极高,非常适合需要模型有理有据的应用场景。
最后,它在成本上具备显著优势,以同等复杂度任务计算,整体费用约为GPT-5的五分之一,大幅降低企业部署AI推理系统的门槛。
