
骨折识别模型:ChexFract如何破解医学报告盲区


人工智能在医学影像报告生成领域,长期面临一个根本矛盾:模型越通用,越容易忽略稀有但关键的病灶。
以胸部X光为例,通用模型在常见病(如肺炎、积液)上表现优异,但一旦遇到骨折等罕见异常,识别率骤降。
通用模型一遇到骨折就掉链子,报告中骨折的遗漏,还可能导致诊断延误、治疗不当和患者预后不良。
这正是俄罗斯人工智能研究院AIRI要问题,新模型ChexFract应运而生。

论文链接:https://arxiv.org/pdf/2511.07983
模型链接:https://huggingface.co/AIRI-Institute
为什么骨折成为AI放射学的暗区?
胸部X光(CXR)是骨折筛查的核心手段,但传统视觉语言模型在生成报告时存在系统性缺陷。据
国外MIMIC-CXR数据集分析,骨折案例仅占整体数据的0.5%-2%,这种极端数据不平衡导致通用模型(如MAIRA-2和CheXagent)的骨折检测召回率低至4.5%。
漏诊骨折可能延误治疗,引发骨不连或畸形愈合等严重并发症。
研究团队,通用模型的平均化训练范式无法捕捉罕见病理的细微特征。例如,骨折描述依赖特定术语(如急性、愈合期)和解剖位置(肋骨、锁骨等),而通用模型倾向于输出高频病理模板。
数据重构和模型专项化
ChexFract以此为切入点,首次构建了一个面向骨折描述的专用视觉语言模型体系,并通过三个关键技术打破了这一瓶颈
1. GPT-4o标注引擎
研究团队用GPT-4o替代传统规则标注,构建了包含18,710个图像-描述对的ChexFract数据集。
关键创新在于双重标准化流程
- a. 句子提取:从多源CXR数据中自动筛选骨折相关描述,并标注属性(位置、侧别、分期、植入物)
- b. 描述模板化:针对7个骨折部位(如肋骨、脊柱)设计标准化模板,将自由文本转化为结构化的临床描述(例如左侧肋骨急性骨折,无植入物)
此举将语言变异度降低89%,让模型聚焦于关键临床特征。
2. Phi-3.5 Vision Instruct骨干
ChexFract采用3.8B参数的Phi-3.5作为语言模型骨干,搭配两种经胸部X光预训练的视觉编码器
- a. MAIRA-2编码器:基于Rad-DINO架构,擅长全局特征提取
- b. CheXagent编码器:融合多标签分类知识,增强病理敏感性
实验表明,端到端微调(编码器解冻)比冻结编码器性能提升30%,证明模型需自适应骨折特征。
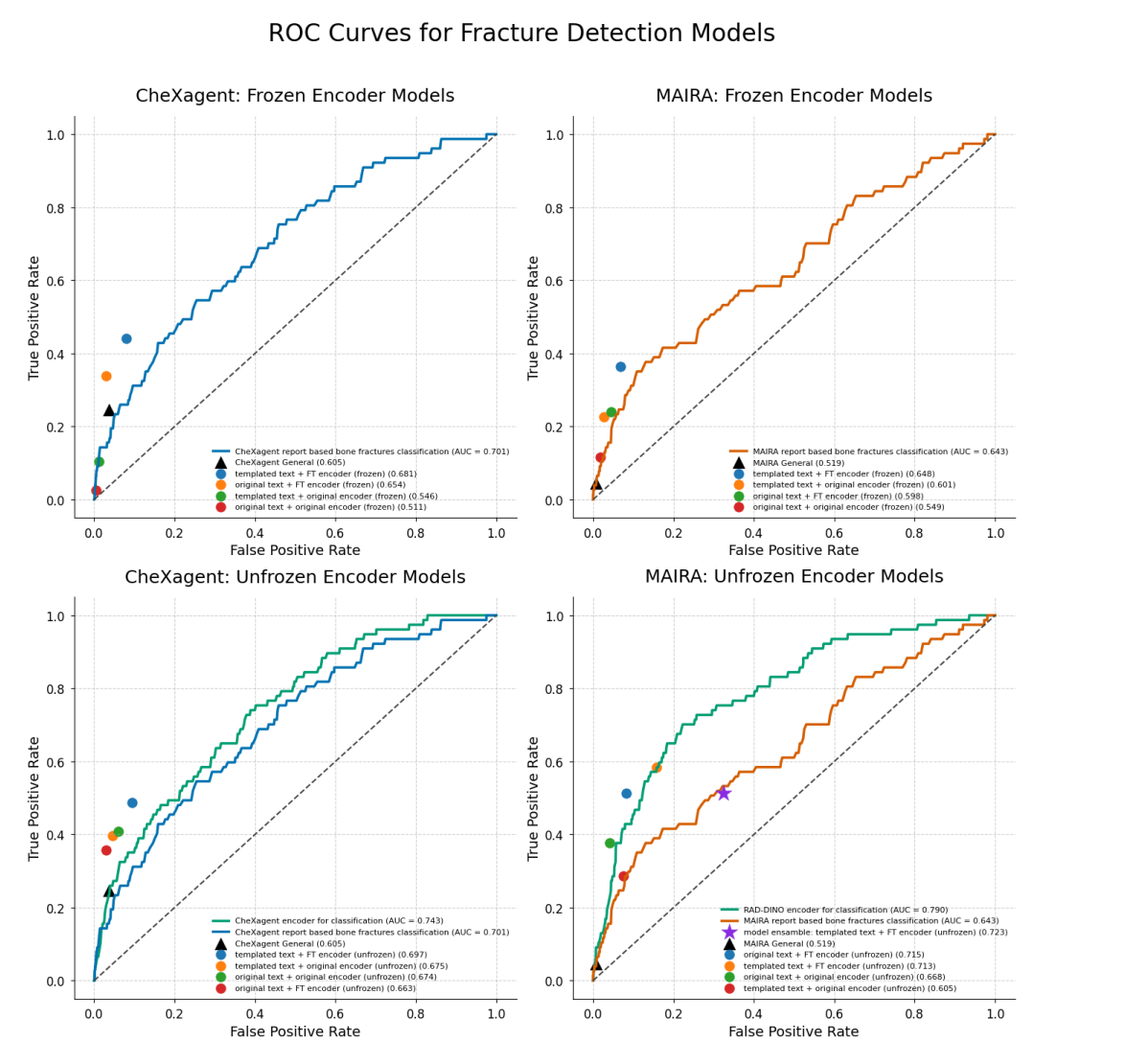
3. 平衡召回与精确度的临床权衡
为优化临床效用,团队引入集成学习策略,组合5个不同随机种子的模型预测,以任一模型检测即报警的规则提升召回率。
结果显示,集成后召回率从0.513升至0.584,但精确度从0.782降至0.682,这种权衡恰好适配筛查场景(放射科医生可二次复核)。
专项化模型的碾压
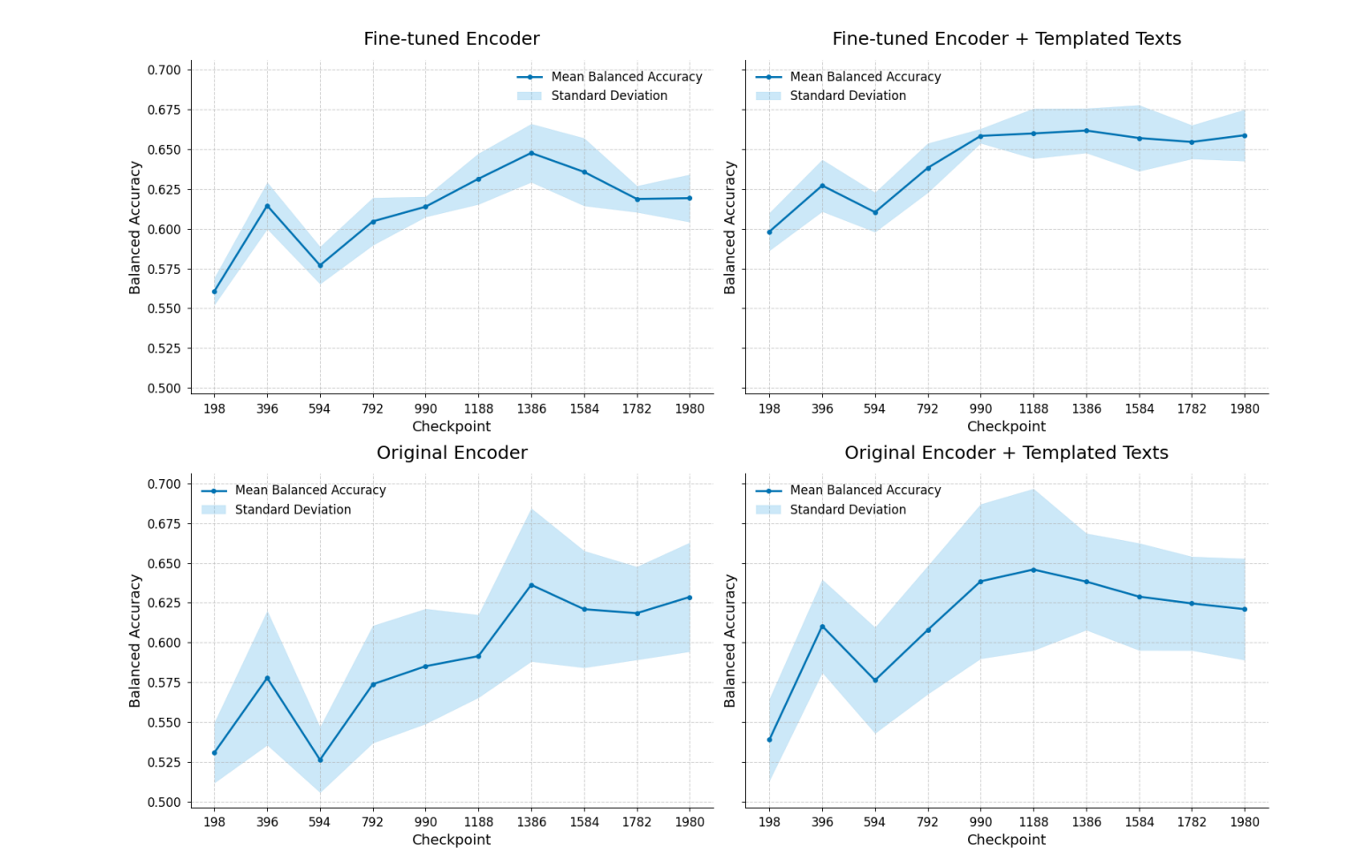
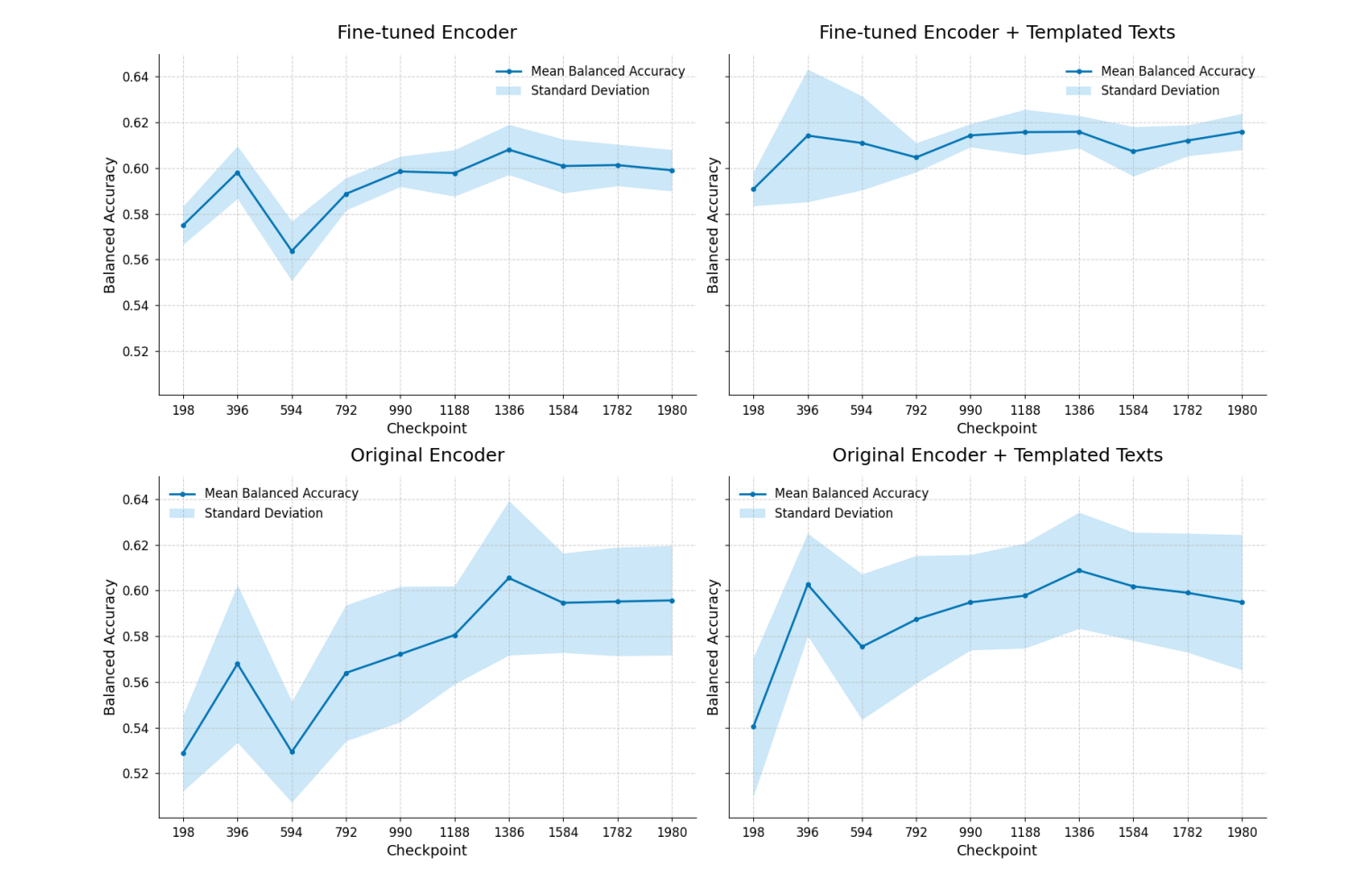
在2,921例测试集上,ChexFract的最佳配置(MAIRA-2编码器+模板化文本+端到端微调)实现ROC AUC 0.715,F1分数0.629,相比通用模型实现量级突破。
和MAIRA-2通用版对比,F1从0.085提升至0.629(7.4倍)。
和CheXagent通用版对比,F1从0.376提升至0.591(57%)。
而且模板化文本比原始文本性能更稳定,因减少了描述噪声。
临床启示
ChexFract的落地价值在于将AI角色从报告生成器升级为罕见病理哨兵。
当前模型仍存在49%的漏诊率,但已满足筛查辅助需求(敏感病例由医生复核)。
未来方向可以扩展至其他罕见病理,如气胸、纵隔移位等低频率但高风险疾病;也可以进行多模态融合,结合CT或临床病史数据,突破单模态局限。

通用模型到病种专项模型
ChexFract代表了用GPT-4类模型进行数据再标注、语义模板化和任务专化的全新范式,类似的思路也正在药理机制建模、病理切片分析等领域出现。
更重要的是,ChexFract开源了全部模型与数据集,这一举动也为未来专项病种模型生态提供了可验证模板,也让外部开发者能快速迁移到其他病种,如肺结节、骨质疏松或创伤评估。
对中国AI创业者而言,这意味着新的机会窗口,通用模型时代的红利已被巨头垄断,而病种专用模型+高质量私有数据,才是下一个竞争点。
