
DeepSeek-V3.2-Exp模型优势与DSA工作原理,token降价性能不减的背后


今天给大家介绍一下《DeepSeek-V3.2-Exp模型优势与 DSA 工作原理,token降价性能不减的背后》,本文基于所给文章,对 DeepSeek-V3.2-Exp 的模型优势与其核心技术 DSA(DeepSeek Sparse Attention)进行不改变原意的系统阐述,并辅以必要的数学表达与通俗示例,帮助读者把握该机制在“先筛选、后计算”范式下实现“长文本训练与推理效率显著提升”的关键思路。
1. 背景与定位
实验性质与架构演进:DeepSeek-V3.2-Exp 是迈向新一代架构的中间步骤,在 V3.1-Terminus 的基础上引入 DSA。其有效性已在公开评测集获得验证,但仍需在真实使用场景中进行更广范围、更大规模测试,以排除在特定场景下效果欠佳的可能。官方诚邀用户反馈(链接:`https://feedback.deepseek.com/dsa`)。
版本目标与技术路线:以“细粒度稀疏注意力”为抓手,在几乎不影响模型输出效果的前提下,显著提升长文本训练与推理效率。
定位直观理解
把 V3.2-Exp 理解为“上新架构前的关键试验田”:一边保证公开基准已过关,一边用更大规模的真实流量检验在各种场景的稳定性。
2. 模型优势
高性价比
API 价格最高降幅高达 75%,而“性能不减”的核心在于 DSA 带来的“在不牺牲输出质量前提下的效率提升”。同样的长文问答任务,单位成本显著降低,但回答可靠性维持在公开评测已验证的水平。
长文本效率大幅提升
首次实现细粒度稀疏注意力,让计算集中在“真正相关”的位置,显著减少无效计算与内存占用。面对一本几十万字的文档,模型不会对每个字都做“全量精算”,而是先“快速找重点”,再“对重点精算”。
工程优化链路完备
轻量筛选在自研 DeepGEMM 上高效运行;稀疏阶段用 FlashMLA 稀疏核执行,使硬件效率最大化(针对 NVIDIA Hopper/Blackwell 优化)。就像高速路上同时优化“导航(选路快)”与“车道(通行快)”,整体路程自然更快。
风险边界明确
当上下文长度 ≤ 2048 时,DSA 退化为“等同全注意力”的行为,确保在短上下文场景下与传统全注意力一致。短短信对话(不到 2048 tokens),不会因为“稀疏”而忽略信息。
3. DSA 的两大核心组件
DeepSeek 表示 DeepSeek-V3.2-Exp 是实验版本。作为迈向下一代架构的过渡,V3.2-Exp 在 V3.1-Terminus 的基础上引入了 DeepSeek 稀疏注意力机制(DeepSeek Sparse Attention,DSA)—— 一种旨在探索和验证在长上下文场景下训练和推理效率优化的稀疏注意力机制。DSA 也是 3.2 版本的唯一架构改进。
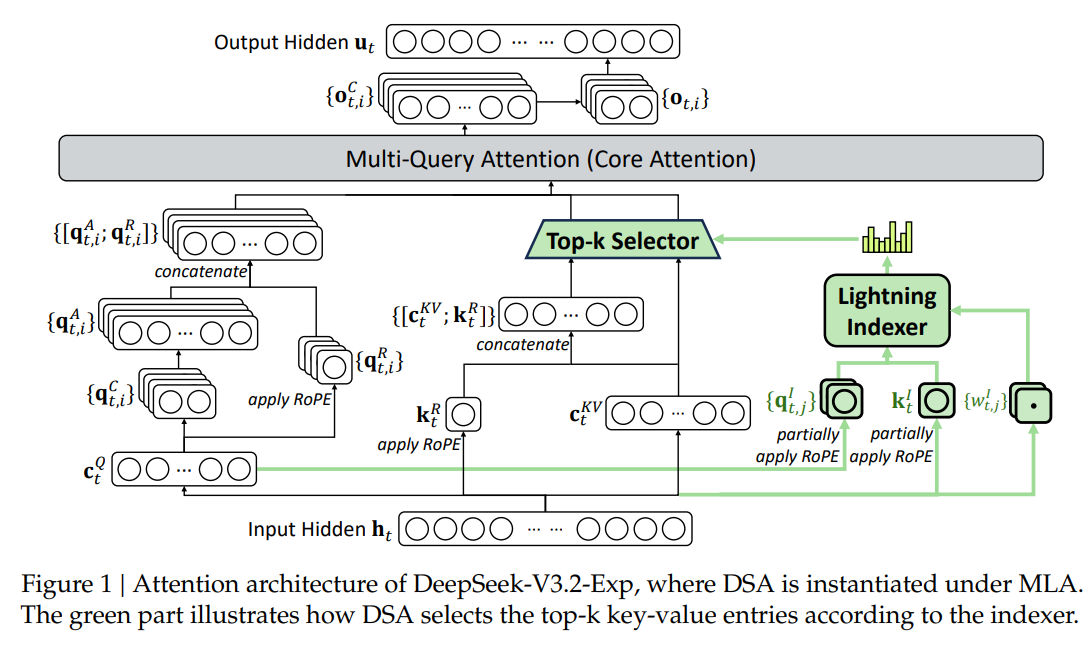
DeepSeek-V3.2-Exp 的架构,其中 DSA 在 MLA 下实例化。DeepSeek 称该实验版本代表了他们对更高效的 Transformer 架构的持续研究,特别注重提高处理扩展文本序列时的计算效率。
1) 闪电索引器(Lightning Indexer,轻量筛选器)
职责:快速扫描完整上下文,为每个查询(Query)选出少数最相关的关键信息(Key)。
设计要点:使用非常小的键缓存(每个 token 仅 128 维)以追求极致速度;在 DeepGEMM 上高效实现点积分数计算、掩码与缩放。像“极速目录检索”,先用超轻索引把整本书里最可能相关的段落标出来,而不是逐字细读。
2) 稀疏多潜在注意力(Sparse Multi-Latent Attention, MLA,重量计算器)
职责:仅对索引器筛出的关键信息做“完整维度”的注意力计算,避免对无关信息的无效计算。
设计要点:更大的键缓存(每个 token 512 维)保证精度;在 FlashMLA 稀疏核上执行,聚焦“优中选优”的子集。像专家只对已经圈定的“重点段落”做深入研判,从而既快又准。
4. DSA 的四步工作流程
记隐藏状态为 H。以下表达式用于帮助理解流程,保持与“标准 Transformer 类似”的设定,同时严格对应原文描述(投影、掩码与缩放、逐头权重重加权、Top-k、稀疏执行)。
步骤一:查询与键的投影


步骤二:索引器评分

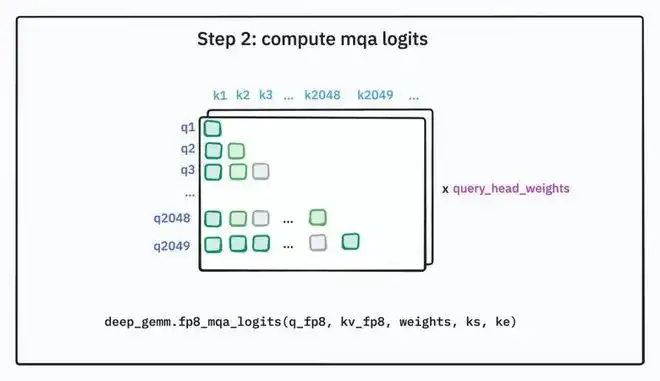
步骤三:Top-k 选择

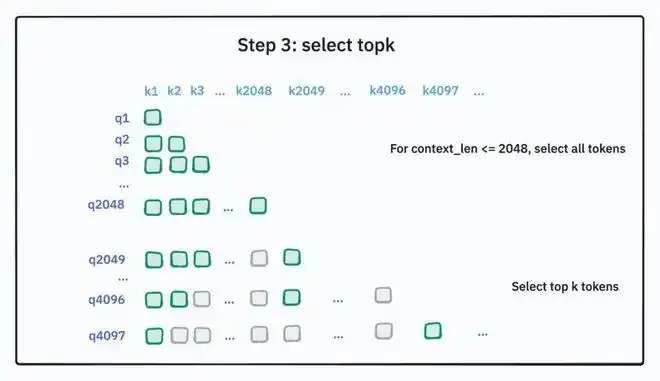
步骤四:执行稀疏 MLA(Sparse MLA)

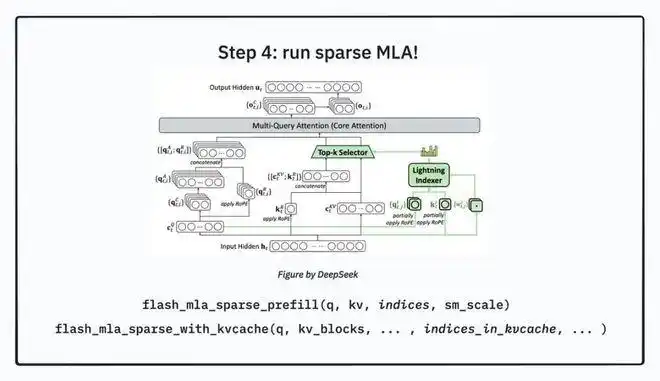
要点小结
- 先“轻筛”后“精算”,在不牺牲精度的前提下,跳过大量无关位置,大幅提升速度与内存效率。
- 当上下文不长(≤ 2048)时,行为与全注意力一致,保证一致性与稳定性。
5. 设计权衡与效果直观
- 精确性(原文要点):Top-k 使注意力聚焦最相关信息,避免在无用信息上分散注意力,保持高精度。问“合同第 7 条违约责任是什么”,模型主要看第 7 条及其上下文,而不是把整本合同均匀考虑。
- 高速度(原文要点):闪电索引器、稀疏核(FlashMLA)与小/大缓存分工协作,显著降低计算与内存占用,实现“闪电般速度”。像“先导航再高速巡航”,路线短、速度快、油耗低。
6. 面向实践的边界与调用者心智
- 可预期行为:长上下文下,先筛后算;短上下文(≤2048)等同全注意力。
- 实验性质:公开基准验证有效,但仍需更广泛真实场景测试;欢迎对比后反馈实际体验与边界案例(见前述链接)。
7. 一句话理解 DSA
“用一个微型的全注意力索引器作为导航,精准地指导后续的大规模稀疏计算。”这是一条通往高效通用人工智能的前景路径。
