
【自然语言处理】Transformer模型

一、引言
Transformer 结构是由 Google 在 2017 年提出并首先应用于机器翻译的神经网络模型架构。机器翻译的目标是从源语言(Source Language)转换到目标语言(Target Language)。Transformer 结构完全通过注意力机制完成对源语言序列和目标语言序列全局依赖的建模。如今,几乎全部大语言模型都是基于 Transformer 结构的。
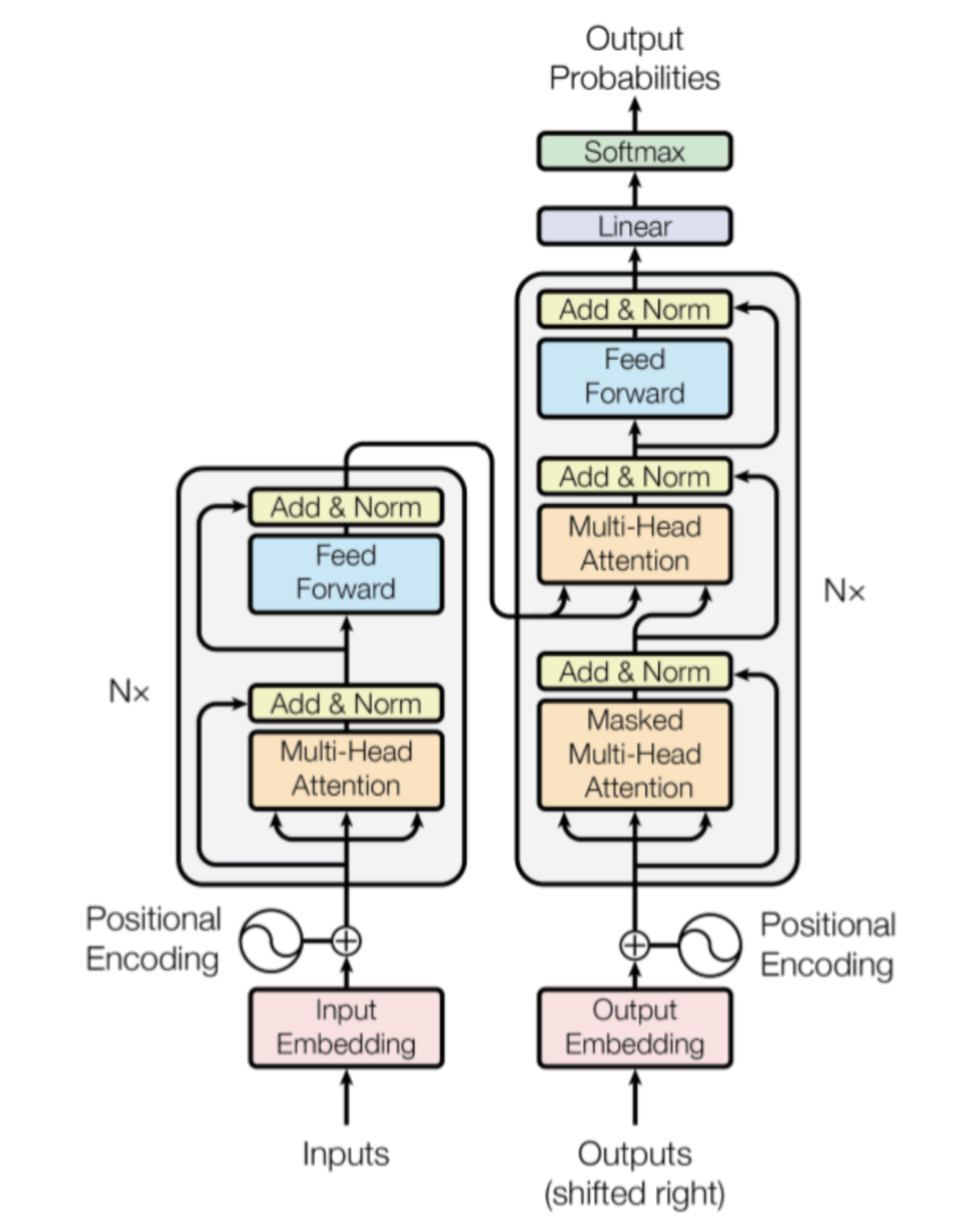
左侧和右侧分别对应编码器(Encoder)和解码器(Decoder)结构,它们均由若干个基本的 Transformer 块(Block) 组成(对应图中的灰色框)。这里 N× 表示进行了 N 次堆叠。每个 Transformer 块都接收一个向量序列 作为输入,并输出一个等长的向量序列作为输出 。这里的 和 分别对应文本序列中一个词元(Token)的表示。 是当前 Transformer 块对输入 进一步整合其上下文语义后对应的输出。在从输入 到输出 的语义抽象过程中,主要涉及如下几个模块:
注意力层:使用多头注意力(Multi-Head Attention)机制整合上下文语义。多头注意力并行运行多种独立注意力机制,进而从多维度捕捉输入序列信息。它使序列中任意两个词之间的依赖关系可以直接被建模(而非基于传统的循环结构),从而更好地解决文本的长程依赖问题。
位置感知前馈网络层(Position-wise Feed-Forward Network):通过全连接层对输入文本序列中的每个单词表示进行更复杂的变换。
残差连接:对应图中的 Add 部分。它是一条分别作用在上述两个子层中的直连通路,用于连接两个子层的输入与输出,使信息流动更高效,有利于模型的优化。
层归一化:对应图中的 Norm 部分。它作用于上述两个子层的输出表示序列,对表示序列进行层归一化操作,同样起到稳定优化的作用。
图中包含 “输入→词元嵌入表示→位置编码→多头注意力→位置感知前馈网络→Add & Norm” 的编码器流程,以及解码器侧的 “掩码多头注意力→多头交叉注意力→位置感知前馈网络→Add & Norm” 流程,最终输出概率经Linear层和Softmax输出。
二、基础组件构建
基础组件是 Transformer 功能实现的核心单元,每个组件各司其职,为后续层堆叠和模型运行提供支撑。
1. 位置编码
Transformer 并行处理序列时无法天然感知元素顺序,位置编码的核心作用是为每个序列元素注入位置信息。它通过特定函数生成唯一的位置向量,既保证不同位置的编码可区分,又能通过函数特性让模型捕捉相对位置关系 —— 任意两个固定偏移的位置,其编码差异保持一致。在实现时,会预计算一个覆盖最大序列长度的位置编码矩阵,避免重复计算;使用时将位置向量与词嵌入向量相加,且在相加前会对词嵌入进行缩放,确保两者量级相当,避免位置信息被淹没。
2. 多头自注意力
多头自注意力的核心是从多个视角捕捉序列内的依赖关系。首先通过线性变换将输入的查询、键、值映射到适配的特征空间,再将其拆分为多个并行的注意力头,每个头在独立的子空间中计算注意力。注意力计算过程中,会先衡量查询与键的相似度,通过掩码过滤无效信息(如填充位置或未来的序列元素),再经归一化得到注意力权重,最终用权重对值进行加权求和。所有头的输出会被拼接,再通过线性变换映射回模型维度,确保输出格式统一。
3. 前馈层
前馈层负责对注意力输出进行非线性特征变换,增强模型的表达能力。其实现流程为 “升维 - 非线性激活 - 降维”:先通过线性变换将输入特征维度提升至更高维度,再通过非线性激活函数引入复杂特征模式,最后通过另一层线性变换将维度降回模型维度,与后续组件无缝衔接。中间层的高维度设计让模型能充分挖掘深层语义关联,非线性激活则让模型可学习文本中的隐式逻辑关系。
4. 层归一化
层归一化的目的是解决深层网络训练中的内部协变量偏移问题,稳定训练过程。它对每个样本的特征维度进行归一化处理,将特征分布调整为均值为 0、方差为 1 的标准形式,再通过可学习的缩放和偏移参数,恢复特征的表达能力,避免归一化导致的信息丢失。与依赖批次数据的归一化不同,它仅依赖单个样本的特征统计,适配 NLP 任务中的变长序列场景。
三、核心层堆叠
核心层是基础组件的有序组合,通过多层堆叠实现渐进式的特征优化,分为编码器层和解码器层两类。
1. 编码器层
每个编码器层包含 “多头自注意力” 和 “前馈层” 两个核心子层,配合残差连接和层归一化。实现时,输入先经过多头自注意力层捕捉全局依赖,输出与原始输入通过残差连接相加,再经层归一化稳定分布;随后进入前馈层进行非线性特征增强,同样通过残差连接和层归一化处理。多个结构相同的编码器层堆叠,让序列特征从浅层的局部短语关联,逐步深化为深层的全局语义关联。
2. 解码器层
解码器层在编码器层的基础上增加了 “交叉注意力层”,且第一个自注意力层带有掩码机制。第一个自注意力层通过掩码防止模型关注未来的序列元素,保证生成的时序合理性;交叉注意力层将解码器特征与编码器输出的源序列上下文特征关联,让生成过程能动态参考源序列的相关信息;最后通过前馈层增强特征表达,全程配合残差连接和层归一化。多个解码器层堆叠,实现目标序列从初始符号到完整输出的渐进式生成。
四、整体模型组装
完整的 Transformer 模型由编码器、解码器和输出层组成,实现从源序列到目标序列的端到端转换。
1. 编码器
编码器以词嵌入和位置编码为输入基础:先将源序列的词汇索引转换为词向量,注入位置编码后,依次通过多个堆叠的编码器层,逐步整合全局上下文信息,最终输出包含源序列完整语义的特征矩阵,为解码器提供参考。
2. 解码器
解码器接收目标序列的前缀作为输入,同样经过词嵌入和位置编码处理,再通过多个堆叠的解码器层:先通过掩码自注意力捕捉目标序列内部依赖,再通过交叉注意力关联编码器输出的源序列特征,最后经前馈层优化特征,生成适配目标序列生成的特征矩阵。
3. 输出层
输出层是一个线性变换组件,将解码器输出的特征矩阵映射到目标词汇表的维度,让每个序列位置对应词汇表中所有词的得分,后续通过归一化得到概率分布,用于预测每个位置的输出词。
五、训练优化
训练过程的核心是让模型学习 “源序列 - 目标序列” 的映射规律,确保生成结果准确且符合逻辑。
首先进行参数初始化,对线性层、注意力层等高维参数采用特定初始化方式,保证初始梯度处于合理范围,避免训练中出现梯度消失或爆炸;配置优化器,适配模型的训练特性,平衡收敛速度和稳定性。
训练时迭代处理批次数据,对目标序列进行拆分,避免模型提前获取未来信息;生成适配的掩码,过滤源序列中的填充位置和目标序列中的未来元素;将源序列和目标序列前缀输入模型,得到预测结果后,通过损失函数衡量预测与真实目标的差异,再通过反向传播计算梯度,更新模型所有参数。训练过程中会监控损失变化,保存性能最优的模型参数。
六、推理生成
推理阶段通过自回归方式生成目标序列,实现从输入到输出的实际转换。
推理时先将源序列处理为模型可接收的格式,经编码器生成上下文特征;解码器从目标语言的起始符开始,逐词预测下一个输出词 —— 每次预测时,生成适配当前生成长度的掩码,确保仅依赖已生成的元素,再通过交叉注意力关联编码器特征,得到当前位置的词汇概率分布,选择概率最高的词作为输出;重复该过程,直到生成结束符或达到预设的最大长度,最终将生成的词汇索引转换为目标序列文本
七、总结
Transformer 以 “编码器 - 解码器” 为核心架构,通过自注意力机制解决序列建模的顺序感知与长程依赖问题,实现端到端序列转换。其实现过程可概括为:先构建位置编码(注入序列位置信息)、多头自注意力(多视角捕捉依赖)、前馈层(非线性特征变换)、层归一化(稳定训练)四大基础组件;再将组件组合为编码器层(堆叠实现全局语义整合)与解码器层(新增交叉注意力关联源序列,带掩码保证时序合理性);随后组装完整模型,通过编码器处理源序列、解码器生成目标序列、输出层映射词汇表;训练阶段通过参数初始化、掩码过滤、损失计算与梯度更新优化模型;推理时以自回归方式逐词生成目标序列,最终完成从输入到输出的转换。
