
【机器学习】支持向量机实验报告——基于SVM进行分类预测

实验题目描述
实验题目:基于SVM进行分类预测
实验要求:通过给定数据,使用支持向量机算法(SVM)实现分类预测,具体为:
筛选变量(如:行程距离、费用、时间等),进行数据预处理(如:处理缺失值、异常值、归一化/标准化数据),关于数据量过大的问题,可以从中筛选部分数据,但要求数据总量不可少于10w条,解释数据选取依据。使用SVM算法实现对芝加哥出租车出行支付方式(现金/信用卡)的分类预测(注:要求使用给定数据集,并且使用python进行数据处理)。训练和预测的数据比例为:80%:20%,给出明确的实验准确度验证过程。此外根据数据集中的其他变量进行进一步分析,探索不同因素对支付方式的影响强度,期待有新的发现,并完成报告。
实验报告内容:实验问题,实验目标,数据介绍(需要文字介绍,并辅助配合时间、空间、多因素分布等图表),实验方法(统一要求使用支持向量机算法(SVM),并且要将算法流程及公式、数据处理流程、实验验证流程、完整写入方法章节),实验结果(需要标注参数设置,预测准确度等),实验结果分析(支持有多图表的实验结果,分析不同因素对实验结果的重要性等,有趣的发现额外加分)。
实验数据集说明:
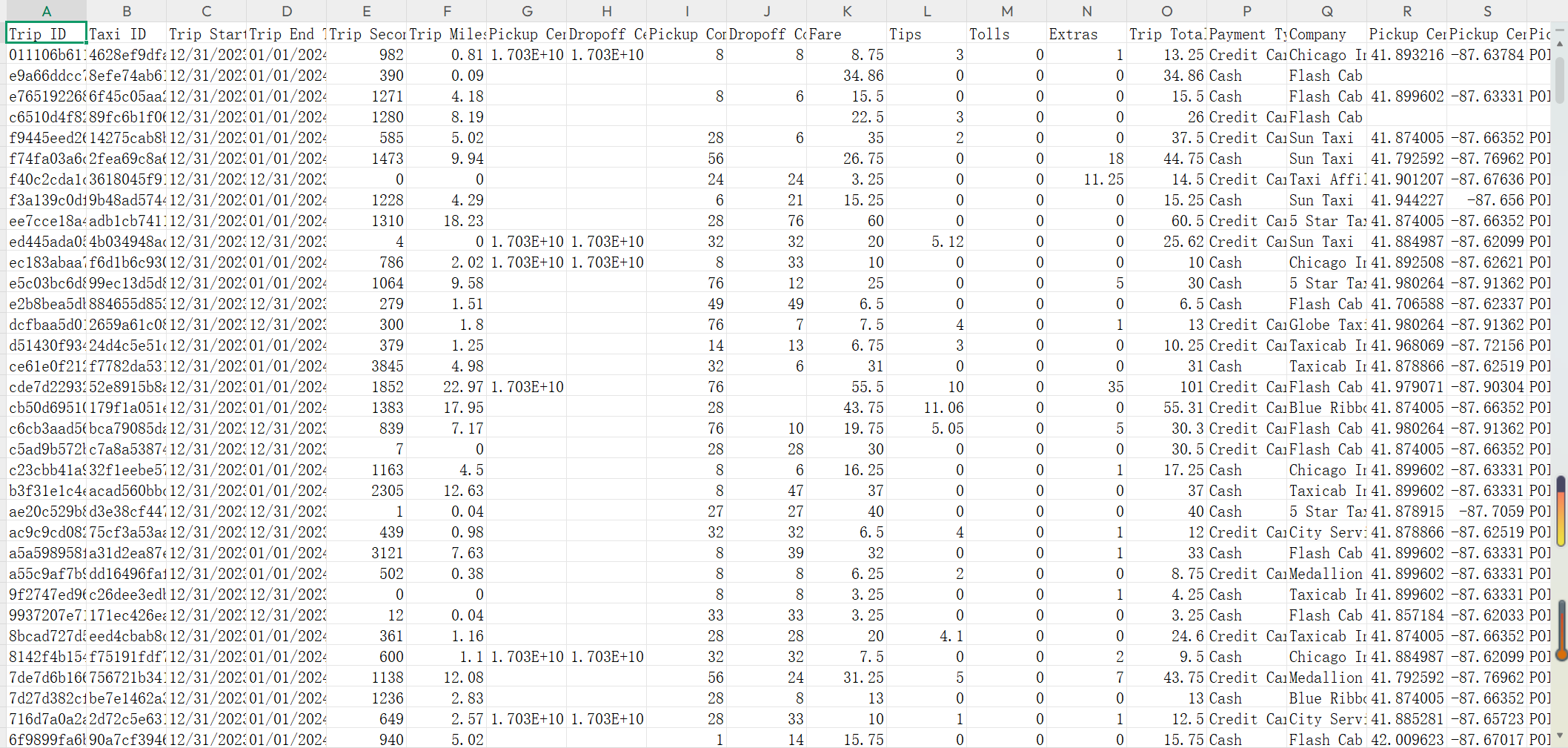
数据集:Chicago Taxi Trips Dataset (2023)-----包含芝加哥出租车出行记录
Trip ID:出行编号 Taxi ID:出租车编号
Trip Start/End Timestamp 上车/下车时间 Trip Seconds:行程时长(秒) Trip Miles:行程距离(英里)
Pickup/ Dropoff Census Tract:上车/下车人口普查区编号:乘客上车位置所在的美国人口普查地块编号
Pickup/Dropoff Community Area:上车/下车社区区域编号:芝加哥市规划划分的77个社区区域
Fare:基础车费 Tips:小费金额 Tolls:路桥费 Extras:额外费用 Trip Total:总
费用
Payment Type:支付方式 Company:所属出租车公司
Pickup Centroid Latitude/Longitude:上车点纬度/经度
Pickup Centroid Location:上车位置坐标:上车地点的地理坐标(格式为纬度, 经度)
Dropoff Centroid Latitude/Longitude:下车点纬度/经度
Dropoff Centroid Location:下车位置坐标:下车地点的地理坐标(格式为纬度, 经度)
实验数据集可以参考https://download.csdn.net/download/2401_84149564/90962954?spm=1011.2124.3001.6210。
实验步骤
(一)实验题目:基于SVM进行分类预测
程序输出:
============================================================
基于SVM进行分类预测
============================================================
(二)加载CSV文件
数学模型:输入数据矩阵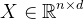 和标签向量
和标签向量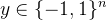
筛选数据:根据CSV文件(文件中一共有2002行,23列数据,不能完全满足实验要求,因为CPU跑10万条的数据集效率很低,运行时间太长,感觉等不到运行结果),数据类型的输出如下:
步骤1: 数据加载
文件 linear.csv 原始形状: (2001, 23)
前几行数据:
Trip ID ... Dropoff Centroid Location
0 011106b6114f83af0c17aace3867a464a7fc742b ... POINT (-87.6262149064 41.8925077809)
1 e9a66ddcc78cfd79f419165314cbe5ee380f16c3 ... NaN
2 e765192268db3480b5d9bd0443f7ce7fd5ba047d ... POINT (-87.6559981815 41.9442266014)
3 c6510d4f82541cfacf8c20cab44fbb7c0b2c5efe ... NaN
4 f9445eed26da9a0eff247350df942616cb51e764 ... POINT (-87.6559981815 41.9442266014)
[5 rows x 23 columns]
数据类型:
Trip ID object
Taxi ID object
Trip Start Timestamp object
Trip End Timestamp object
Trip Seconds float64
Trip Miles float64
Pickup Census Tract float64
Dropoff Census Tract float64
Pickup Community Area float64
Dropoff Community Area float64
Fare float64
Tips float64
Tolls float64
Extras float64
Trip Total float64
Payment Type object
Company object
Pickup Centroid Latitude float64
Pickup Centroid Longitude float64
Pickup Centroid Location object
Dropoff Centroid Latitude float64
Dropoff Centroid Longitude float64
Dropoff Centroid Location object
根据上述的数据类型的输出,我们容易发现,经度和纬度由于数据变化范围特别小,因此Python不用访问,对于非数值类型(object),根据观察可以发现Python只能处理第16列非数值类型的数据,可以采用映射的方式将Cash映射为-1,将Credit Card映射为1,第5到第15列数据是数值类型(float64),Python可以处理,因此可以筛选第5-16列数据。
2.处理数据:特征列处理函数
过程模型:对于特征矩阵的每一列 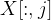 进行数值转换和缺失值填充:
进行数值转换和缺失值填充:
若转换成功,则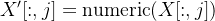
若存在缺失值NaN,则使用均值填充: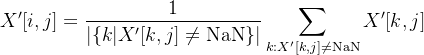
数值转换和缺失值处理
数学模型:对于向量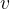 ,数值转换和缺失值填充的处理过程为:
,数值转换和缺失值填充的处理过程为:
尝试将转换为数值向量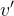
对于缺失值,计算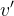 的均值
的均值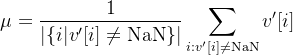
填充缺失值: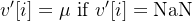
标签处理函数(特殊处理标签列)
数学模型:对于标签向量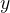 ,我们定义映射函数
,我们定义映射函数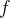 :
:
对于字符串标签,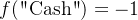 ,
,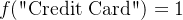
对于数值标签,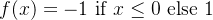
对于缺失值NaN,直接跳过该样本
由于第5-16列数据可能有缺失值,异常值的情况,需要标准化和归一化进行处理。处理结果如下:
dtype: object
处理列 '特征列 Trip Seconds', 原始类型: int64
处理列 '特征列 Trip Miles', 原始类型: float64
处理列 '特征列 Pickup Census Tract', 原始类型: float64
列 '特征列 Pickup Census Tract' 中有 1287 个值无法转换为数字,将使用均值填充
处理列 '特征列 Dropoff Census Tract', 原始类型: float64
列 '特征列 Dropoff Census Tract' 中有 1337 个值无法转换为数字,将使用均值填充
处理列 '特征列 Pickup Community Area', 原始类型: float64
列 '特征列 Pickup Community Area' 中有 66 个值无法转换为数字,将使用均值填充
处理列 '特征列 Dropoff Community Area', 原始类型: float64
列 '特征列 Dropoff Community Area' 中有 317 个值无法转换为数字,将使用均值填充
处理列 '特征列 Fare', 原始类型: float64
列 '特征列 Fare' 中有 2 个值无法转换为数字,将使用均值填充
处理列 '特征列 Tips', 原始类型: float64
列 '特征列 Tips' 中有 2 个值无法转换为数字,将使用均值填充
处理列 '特征列 Tolls', 原始类型: float64
列 '特征列 Tolls' 中有 2 个值无法转换为数字,将使用均值填充
处理列 '特征列 Extras', 原始类型: float64
列 '特征列 Extras' 中有 2 个值无法转换为数字,将使用均值填充
处理列 '特征列 Trip Total', 原始类型: float64
列 '特征列 Trip Total' 中有 2 个值无法转换为数字,将使用均值填充
成功加载文件: linear.csv, 特征数据形状: (2000, 11), 标签数量: 2000
处理标签数据,类型: <class 'numpy.ndarray'>, 形状: (2000,)
标签的唯一值: ['Cash' 'Credit Card']
处理后的标签分布: -1 (Cash): 969, 1 (Credit Card): 1031
数据处理完成 - 特征维度: (2000, 11), 标签分布: 负类(-1): 969, 正类(1): 1031
成功加载CSV文件
(三)数据检查与预处理
检查数据维度与类型分布,输出结果如下:
步骤2: 数据检查与预处理
数据维度: X=(2000, 11), y=(2000,)
类别分布 - 类别(-1): 969, 类别(1): 1031
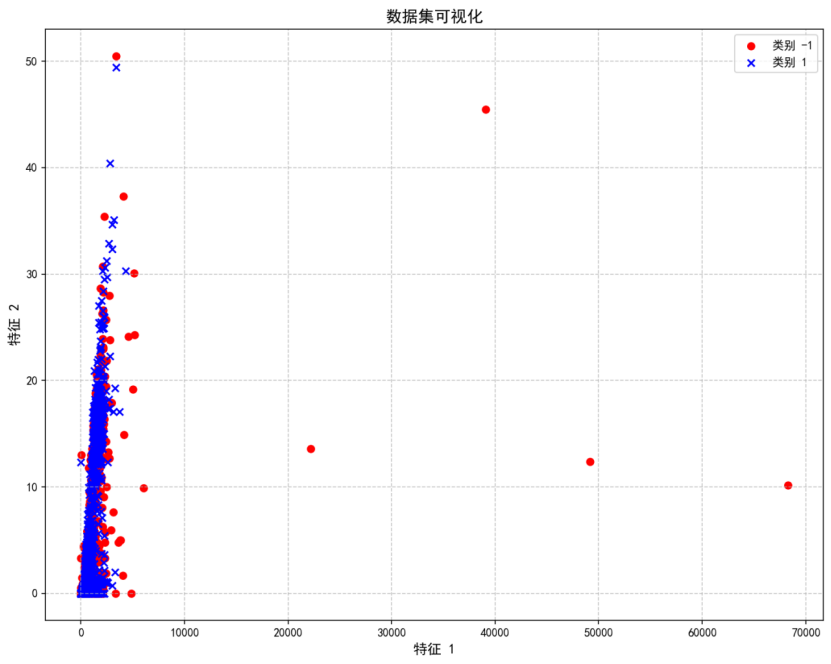
(四)数据标准化
划分为训练集和测试集,输出结果如下:
步骤3: 数据标准化
训练集大小: (1600, 11)
测试集大小: (400, 11)
(五)手动SMO算法训练

 、
、

显示支出项两个数,权重向量和偏置项,输出结果如下:
步骤4: 手动SMO算法训练
支持向量个数: 1384
权重向量 w = [-0.1751, 0.9524]
偏置项 b = -0.2822
决策边界可视化

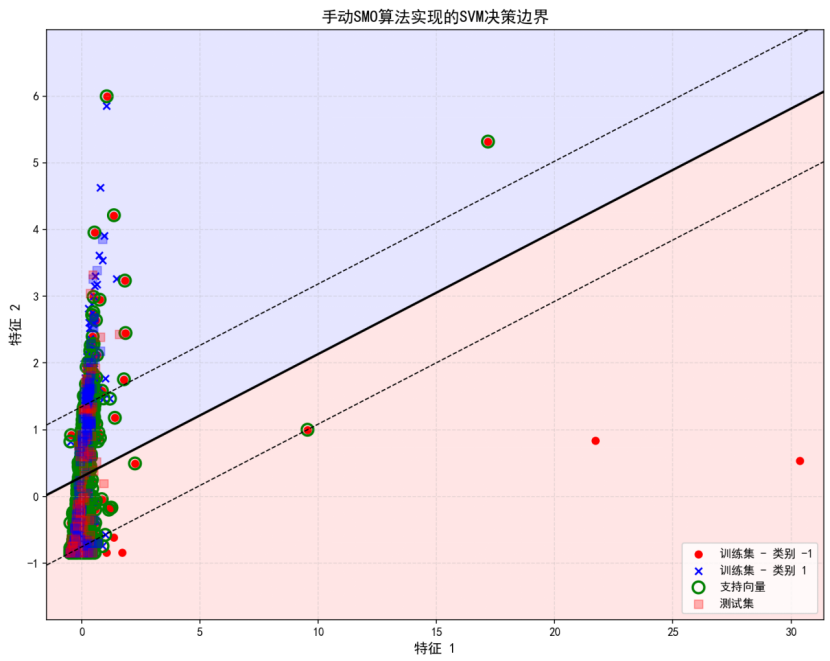
手动SMO SVM - 准确率: 0.5975, 精确率: 0.7068, 召回率: 0.4352, F1: 0.5387
(六)不同核函数比较
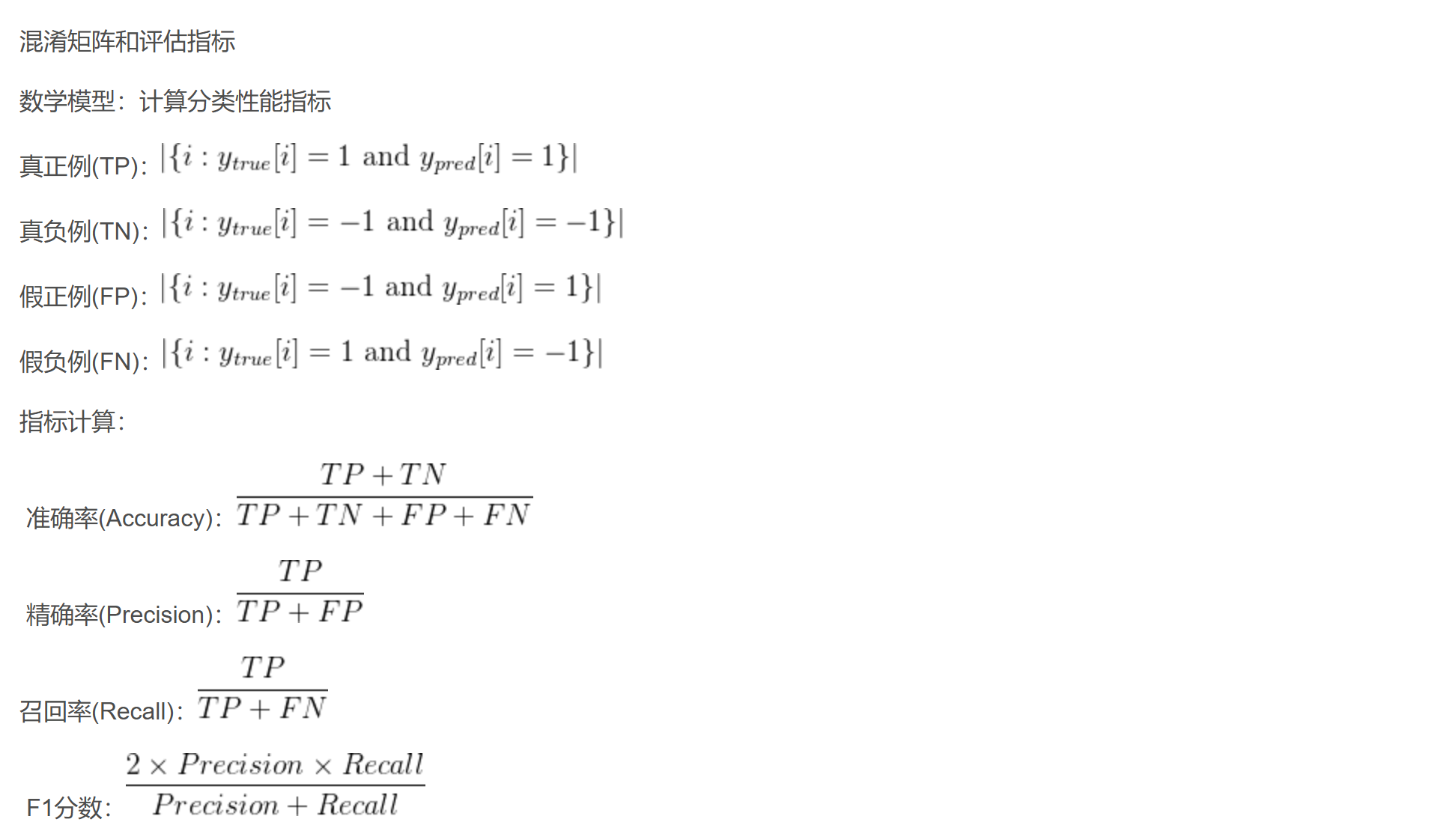
比较线性核SVM,RBF核SVM,多项式核SVM,Sigmoid核SVM,依次计算这些核函数的准确率,精确率,召回率,F1的值,输出结果如下:
步骤5: 不同核函数比较
线性核 SVM - 准确率: 0.9275, 精确率: 1.0000, 召回率: 0.8657, F1: 0.9280
RBF核 SVM - 准确率: 0.9300, 精确率: 0.9896, 召回率: 0.8796, F1: 0.9314
多项式核 SVM - 准确率: 0.8875, 精确率: 0.9476, 召回率: 0.8380, F1: 0.8894
Sigmoid核 SVM - 准确率: 0.7600, 精确率: 0.7857, 召回率: 0.7639, F1: 0.7746
(七)自动参数调优
网格搜索自动调参
数学模型:通过网格搜索和交叉验证寻找最优超参数

输出结果如下:
步骤6: 自动超参数调优
对通用数据集进行调参...
开始自动调参...
自动调参失败: 'ascii' codec can't encode characters in position 18-20: ordinal not in range(128)
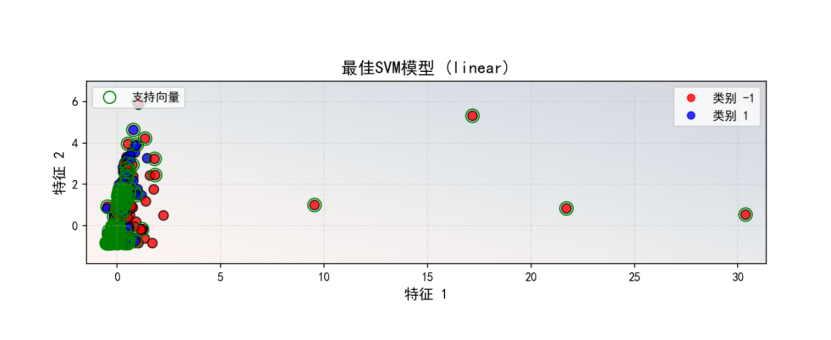
(八)参数对性能的影响
步骤7: 参数对性能的影响
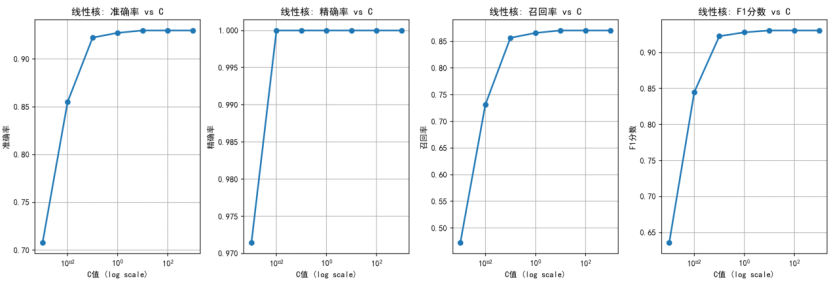
(九)学习曲线分析
步骤8: 学习曲线分析
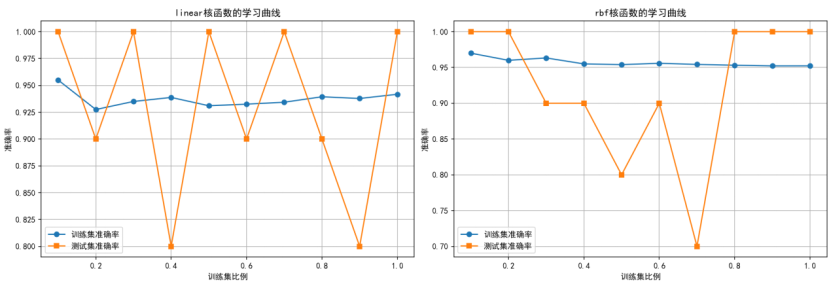
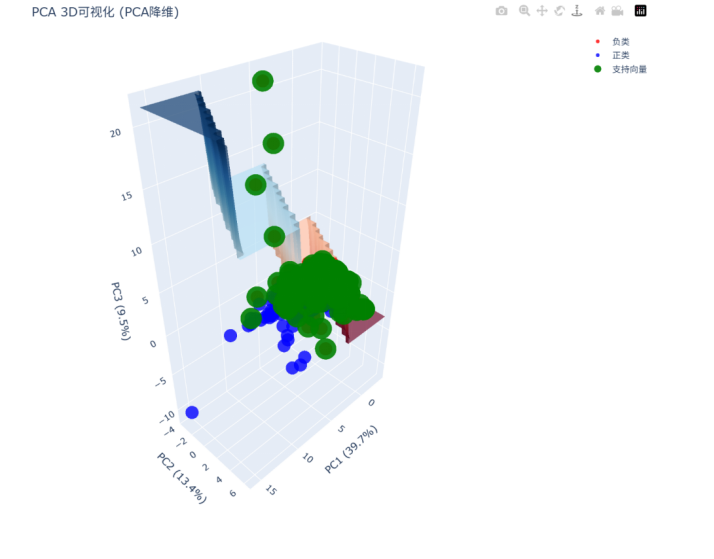
(十)生成3D可视化(网页版)
3D可视化
数学模型:使用PCA或t-SNE进行降维,在3D空间中可视化数据分布和决策边界

输出结果如下:
步骤9: 生成3D可视化
(十一)创建决策边界动画(网页版)
动画可视化
数学模型:创建不同核函数决策边界的平滑过渡动画

输出结果如下:
步骤10: 创建决策边界动画
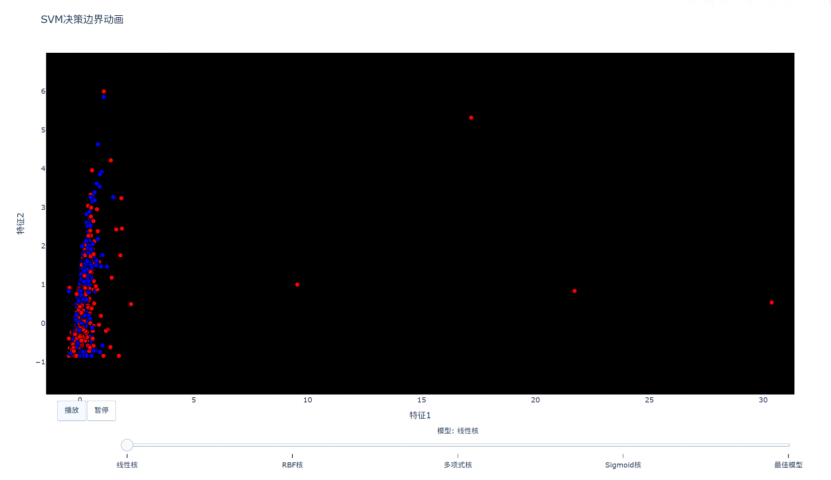
(十二)生成综合性能报告(网页版)
步骤11: 生成综合性能报告
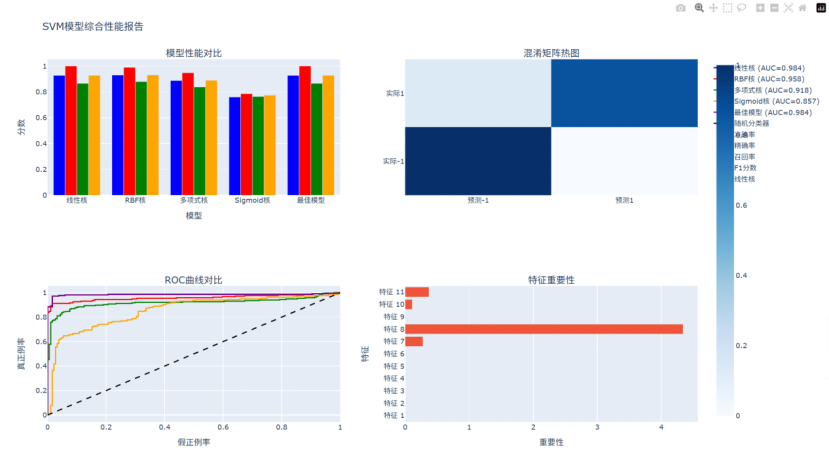
=== 所有演示完成 ===
最佳模型参数: {'kernel': 'linear', 'C': 1.0}
数据处理、模型训练、可视化和性能评估已全部完成!
我的收获
支持向量机是一种强大而优雅的算法,它将优化理论、凸分析和核方法等高级数学概念与实用的分类器结合起来。通过这次实验,我不仅掌握了支持向量机SVM的理论和实现,更重要的是建立了理论与实践的连接,培养了分析问题和实现复杂系统的能力。特别是对标签列的特殊处理需求,让我意识到在实际应用中,算法往往需要根据具体业务需求进行定制和调整。因此,在本节的实验中,我的收获有:
(一)理论与实践的结合
支持向量机的理论在课本上看起来十分抽象,特别是涉及到拉格朗日乘子、对偶问题和KKT条件等数学概念时。然而,通过亲手实现SMO算法,我真正理解了这些理论的实际含义:
1.最大间隔的直观感受:通过可视化决策边界,我直观地看到了SVM如何在保证分类正确的前提下最大化间隔,这使得抽象的优化目标变得具体可感。
2. 对偶问题的意义:以前只知道SVM求解时会转化为对偶问题,但不理解为什么。通过编码实现,我发现对偶形式不仅计算效率更高,而且为核技巧的应用提供了可能性。
3. 支持向量的作用:观察到大部分训练点的拉格朗日乘子为零,只有少数支持向量真正影响决策边界,这极大地提高了模型的泛化能力和计算效率。
(二)核函数的选择与影响
实验中尝试了不同的核函数(线性、RBF、多项式、Sigmoid),对比它们在各类数据集上的表现:
1. 线性核:在线性可分数据上表现优秀,模型简单且计算速度快,但在复杂数据上无法找到有效的决策边界。
2. RBF核:适应性最强,能处理各种复杂模式,但调参难度大。特别是γ参数对模型影响显著 - 过小会导致欠拟合,过大则容易过拟合。
3. 多项式核:在某些特定问题上表现出色,但计算开销大且数值稳定性较差。度数参数需要谨慎选择。
4. Sigmoid核:虽然理论上很有趣,但在实际应用中往往不如其他核函数,参数调整也更为困难。
通过3D可视化和动画,我清晰地看到不同核函数如何在特征空间中构建决策边界,这大大加深了我对核方法本质的理解。
(三)数据处理的重要性
本项目特别关注CSV数据处理,尤其是标签列的特殊处理,这让我认识到数据预处理对机器学习模型的重要性:
1. 缺失值处理:对特征列使用均值填充是常见做法,但对标签列则需要更谨慎的处理策略。
2. 字符串到数值的映射:设计合理的映射函数,既保留原始数据语义又满足算法需求,这是实际应用中的关键挑战。
3. 标准化的必要性:未经标准化的数据可能导致某些特征主导模型决策,从实验中可以明显看到标准化对SVM性能的显著影响。
(四)可视化的价值
交互式可视化不仅美观,更是理解和调试模型的强大工具:
决策边界可视化:通过可视化决策边界和支持向量,我能够直观地判断模型是否过拟合或欠拟合。
2. 参数影响分析:3D图表展示了C和γ参数对模型性能的影响,帮助我更有针对性地调整参数。
3. 降维技术的应用:使用PCA和t-SNE进行3D可视化,让我理解了高维数据的结构以及模型在实际空间中的行为方式。
4. 动画效果:动态展示不同核函数的决策边界变化,这种动态视角比静态图表能提供更多信息。
(五)写Python代码的收获
从编码角度,这个项目也带给我很多收获:
1. 模块化设计:将复杂系统拆分为数据访问、算法实现、可视化和自动调参等模块,大大提高了代码的可读性和可维护性。
2. 错误处理:在实际数据处理中,异常情况远比预想的多,全面的错误处理和降级策略确保了系统的稳定运行。
3. 算法效率:通过实现SMO算法,我体会到了算法优化的重要性,特别是启发式选择变量和矩阵预计算等技巧。
4. 交互性设计:设计交互式界面比简单的数据处理要复杂得多,但带来的用户体验提升也是显著的。
(六)未来改进方向
1. 增加更多核函数:实现更多特殊核函数,如Chi-Square核、波形核等,探索它们在特定问题上的表现。
2. 优化SMO算法:当前实现的是简化版SMO,未来可以加入完整的启发式变量选择策略,进一步提高收敛速度。
3. 扩展到多分类:使用one-vs-one或one-vs-all策略将SVM扩展到多分类问题。
4. 集成学习:将SVM作为基学习器,探索集成方法如SVM-Bagging或多核融合的可能性。
5. 在线学习:探索增量SVM算法,使模型能够处理流式数据。
我的感受
支持向量机虽然在近年来被深度学习的热潮所掩盖,但它依然是机器学习领域的基石,在许多场景中有着不可替代的价值。这次实验不仅加深了我对机器学习的理解,也培养了我解决实际问题的能力,更加深了我对人工智能算法的兴趣,是一次非常有价值的学习经历。
