
【机器学习】主成分分析(PCA)

一、引言
在解决复杂的聚类问题时,我们会先用一些手段提取数据的有用特征。对高维复杂数据来说,其不同的维度所代表的特征可能存在关联,还有可能存在无意义的噪声干扰。因此,无论后续任务是监督学习还是无监督学习,我们都希望能先从中提取出具有代表性、能最大限度地保留数据本身信息的几个特征,从而降低数据维度,简化之后的分析和计算。这一过程通常称为数据降维,这同样是无监督学习的重要问题。因此在本文中将要介绍数据降维中最经典的算法——主成分分析(Principal Component Analysis,PCA)。
二、PCA的目标与核心思想
(一)主成分分析 (Principal Component Analysis, PCA) 是一种广泛应用的无监督线性降维技术。其主要目标是:
1. 降维 (Dimensionality Reduction):将高维数据集转换为一个低维数据集,同时尽可能多地保留原始数据的变异信息(方差)。
2. 特征提取 (Feature Extraction):通过原始特征的线性组合,创建一组新的、不相关的特征,称为主成分 (Principal Components, PCs)。这些新特征能够更好地概括数据的主要结构。
3. 去相关 (Decorrelation):生成的主成分是相互正交(不相关)的。
4. 噪声过滤 (Noise Filtering):通常假设方差较小的主成分可能对应于数据中的噪声,通过舍弃这些成分可以达到一定的去噪效果。
5. 数据可视化 (Data Visualization):通过将数据降至2维或3维,可以方便地进行可视化。
(二)核心思想:PCA 试图找到数据中方差最大的方向。第一个主成分 (PC1) 是数据方差最大的方向;第二个主成分 (PC2) 是与PC1正交(垂直)且方差次大的方向;以此类推。
(三)直观理解
想象一个三维空间中的点云(数据集)。如果这些点大致分布在一个扁平的椭球体上,PCA会找到这个椭球体的最长轴作为PC1。这个方向是数据点散布最开的方向。然后,在与PC1垂直的平面内,找到数据散布最开的下一个方向作为PC2(椭球体的次长轴)。对于三维数据,PC3将是与PC1和PC2都垂直的方向(椭球体的最短轴)。通过将数据点投影到由最重要的几个主成分(如PC1和PC2)张成的子空间上,我们就能用更少的维度来表示数据,同时保留了数据的主要变化特征。
三、数学基础
(一)PCA 依赖于以下几个关键的数学概念:
1. 方差 (Variance):衡量单个变量(特征)数据的离散程度。
Var(X) = σ² = Σ(xᵢ - μ)² / (N-1)
2. 协方差 (Covariance):衡量两个变量(特征)之间的线性相关性程度和方向。
Cov(X,Y) = Σ((xᵢ - μₓ)(yᵢ - μᵧ)) / (N-1)
(1)正协方差:两个变量同向变化。
(2)负协方差:两个变量反向变化。
(3) 零协方差:两个变量线性不相关。
3. 协方差矩阵 (Covariance Matrix, Σ):对于一个包含 d 个特征的数据集,协方差矩阵是一个 d x d 的对称矩阵。其对角线元素是各个特征的方差,非对角线元素是特征对之间的协方差。
4. 特征值与特征向量 (Eigenvalues and Eigenvectors):对于一个方阵 A,如果存在一个非零向量 v 和一个标量 λ 使得 Av = λv,则 λ 称为特征值,v 称为对应于 λ 的特征向量。
(1)在PCA中,协方差矩阵的特征向量指出了主成分的方向。
(2)协方差矩阵的特征值表示数据在对应特征向量(主成分)方向上的方差大小。特征值越大,说明该主成分包含的原始数据信息越多。
四、PCA算法的完整步骤
(一)假设我们有一个数据集 X,包含 n 个样本和 d 个特征。
步骤 1:数据标准化(Standardization)
目的:PCA对特征的尺度非常敏感。如果不同特征的尺度差异很大,尺度较大的特征会在计算方差时占据主导地位,导致PCA结果偏向这些特征。标准化使得所有特征具有相同的贡献权重。
操作:对每一个特征(数据集的每一列),减去其均值并除以其标准差。
X_std_ij = (X_ij - μ_j) / σ_j
其中 μ_j 是第 j 个特征的均值,σ_j 是第 j 个特征的标准差。
标准化后的数据 X_std 的每个特征均值为0,标准差为1。
步骤 2:计算协方差矩阵 (Σ)
目的:协方差矩阵描述了数据中不同特征之间的线性关系以及各个特征自身的变异程度。
操作:使用标准化后的数据 X_std 计算协方差矩阵。
Σ = (1 / (n - 1)) * X_stdᵀ @ X_std
其中 n 是样本数量,X_stdᵀ 是 X_std 的转置。
结果是一个 d x d 的对称矩阵。
步骤 3:计算协方差矩阵的特征值和特征向量
目的:找到数据变化的主要方向(由特征向量给出)以及这些方向上的变化幅度(由特征值给出)。
操作:对协方差矩阵 Σ 进行特征分解。
Σv = λv
求解得到 d 个特征值 λ₁, λ₂, ..., λd 和对应的 d 个特征向量 v₁, v₂, ..., vd。每个特征向量 vᵢ 的维度是 d x 1。
步骤 4:对特征值和特征向量进行排序
目的:确定主成分的重要性。
操作:将特征值从大到小排序:λ₁ ≥ λ₂ ≥ ... ≥ λd。
同时,按照特征值的大小顺序重新排列对应的特征向量。
排序后,与最大特征值 λ₁ 对应的特征向量 v₁ 就是第一主成分 (PC1) 的方向。
与第二大特征值 λ₂ 对应的特征向量 v₂ 就是第二主成分 (PC2) 的方向,以此类推。
这些特征向量(主成分方向)是相互正交的。
步骤 5:选择主成分的数量 (k)
目的:确定要保留的维度数量,以在降维和信息保留之间取得平衡。
操作**:选择前 `k` 个主成分,其中 `k < d`。选择 `k` 的常用方法有:
1. 解释方差比例 (Explained Variance Ratio):计算每个主成分解释的方差占总方差的比例 (λᵢ / Σλⱼ),然后计算累积解释方差比例。选择一个 k,使得累积解释方差达到一个预设的阈值(例如,保留90%、95%或99%的方差)。
2. 碎石图 (Scree Plot):将排序后的特征值绘制成图表。通常在特征值急剧下降之后趋于平缓的地方(肘部)选择 k。肘部之后的特征值通常较小,可能对应噪声或不太重要的变化。
3. 根据应用需求:例如,如果目标是可视化,通常选择 k=1 或 k=2 或 k=3。
步骤 6:构建投影矩阵 (W)
目的:创建一个矩阵,用于将原始数据投影到选定的主成分子空间。
操作:选择在前一步中确定的前 k 个特征向量 v₁, v₂, ..., vk。
将这 k 个特征向量作为列向量,构建一个 d x k 的投影矩阵 W。
W = [v₁ | v₂ | ... | vk]
步骤 7:投影数据到新的低维子空间
目的:得到降维后的数据集。
操作:将标准化后的原始数据 X_std (一个 n x d矩阵) 乘以投影矩阵 W。
X_pca = X_std @ W
得到的结果 X_pca 是一个 n x k 的矩阵。X_pca的每一行是原始数据中对应样本在新主成分空间中的坐标,每一列对应一个主成分的得分。
(二)解释PCA结果
1.. 主成分 (Principal Components):是原始特征的线性组合,代表数据中方差最大的方向。它们是相互正交的。
2. 载荷 (Loadings):投影矩阵 W 中的元素(即特征向量的元素)称为载荷。第 j 个原始特征在第 i 个主成分上的载荷,表示该原始特征对构成这个主成分的贡献程度和方向。载荷的绝对值越大,说明该原始特征对该主成分越重要。
3. 得分 (Scores):降维后的数据 X_pca 中的值称为得分。每个样本在每个主成分上的得分,表示该样本在该主成分方向上的位置。
4. 解释方差 (Explained Variance):每个特征值 λᵢ 代表对应主成分 PCᵢ 所解释的方差量。解释方差比例 (λᵢ / Σλⱼ) 更直观地表示了每个PC的重要性。
(三)PCA的假设与局限性
1. 线性假设:PCA假设数据的主要变化方向是线性的。如果数据结构是非线性的,PCA可能无法有效捕捉。
2. 方差越大越重要:PCA假设方差最大的方向是最重要的。在某些情况下,方差较小的方向可能包含对特定任务(如分类)更重要的信息。
3. 均值和方差足以描述数据:PCA依赖于数据的二阶统计量(均值和协方差)。对于非高斯分布的数据,这可能不是最佳选择。
4. 对数据缩放敏感:如前所述,需要进行数据标准化。
5. 主成分的解释性:虽然主成分在数学上是最优的,但它们是原始特征的混合,有时可能难以赋予直观的物理解释。
6. 信息损失:降维必然会导致一部分信息损失,尤其是当舍弃的主成分仍包含一些有用信息时。
(四)PCA的优点
1. 简单高效:算法基于线性代数,计算相对简单。
2. 无参数调整(除了k):除了选择主成分数量 k 外,没有其他超参数需要调整。
3. 去相关性:生成的主成分相互正交,消除了原始特征间的线性相关性,这对于某些后续的机器学习算法是有益的。
4. 有效降维:能显著减少数据维度,同时保留大部分信息。
5. 可视化:是高维数据可视化的有力工具。
(五)PCA的缺点
1. 线性限制:不能很好地处理非线性数据结构(此时可以考虑核PCA等非线性降维方法)。
2. 可能丢失重要信息:如果重要信息存在于方差较小的方向,PCA可能会将其舍弃。
3. 对异常值敏感:异常值可能显著影响均值和协方差的计算,从而影响主成分的方向。
4. 解释性可能较差:主成分是原始特征的组合,其物理意义可能不明确。
(六)PCA的应用场景
1.数据压缩与降维:减少存储需求和计算复杂度。
2.特征工程:作为机器学习模型的预处理步骤,生成新的特征集。
3.数据可视化:将高维数据投影到2D或3D空间进行观察。
4.噪声消除:通过去除方差较小的主成分来过滤噪声。
5.图像处理:如人脸识别中的“特征脸”(Eigenfaces)。
6.生物信息学:如基因表达数据分析。
7.金融领域:如风险因子分析。
五、主成分分析(PCA)实战的算法步骤
1.核心目标:这份代码旨在全面探索和比较主成分分析 (PCA) 及其多种变体(稀疏PCA, 核PCA, 增量PCA)在不同类型数据集上的表现。它通过可视化和量化指标(如解释方差、重构误差、计算时间、稀疏度)来评估这些降维技术。
2.整体代码结构:
(1) 环境设置:
a.导入必要的库 (numpy, matplotlib, pandas, sklearn.decomposition, sklearn.datasets, time, os, shutil)。
b.设置 matplotlib 以支持中文显示(如果配置了中文字体)。
c.创建一个目录 (pca_analysis_images) 用于保存生成的图像。
(2) 数据集生成与加载 (函数 generate_pca_friendly_dataset 和第2部分):
a.目的:提供一个可控的合成数据集,其中包含明确的强主成分和噪声,便于验证PCA的效果。
b.步骤:
(a)定义样本数 (n_samples)、原始特征数 (n_features)、强主成分数 (n_components_strong)。
(b) 生成一个随机正交基 (q_strong) 作为强主成分的真实方向(载荷)。
(c)生成服从高斯分布的得分(scores),并乘以指定的方差 (strong_component_variance_val),然后通过真实载荷投影回原始特征空间,构成数据的主要结构部分。
c.数学上:Data_strong = Scores_strong @ Loadings_true^T
d. (可选)类似地生成弱主成分部分,其方向与强主成分正交,方差较小 (weak_component_variance_val)。
e. 添加高斯噪声 (noise_std)。
f. (可选)添加一个随机的均值偏移。
g. 将生成的数据保存为CSV文件 (pca_synthetic_data_for_report.csv)。
(a)数据加载:脚本首先尝试从CSV文件加载数据;如果文件不存在,则调用 generate_pca_friendly_dataset 生成新的数据。
(b)数据中心化:对加载或生成的数据进行中心化处理,即每个特征减去其均值。这是PCA的标准预处理步骤。
(c)X_centered = X - mean(X) (按列计算均值)
(3) 标准PCA分析 (第3部分):
a.核心思想:找到数据中方差最大的方向(主成分),将数据投影到这些方向上以实现降维,同时保留尽可能多的原始信息(方差)。
b.数学步骤:
(a) 计算中心化数据 X_centered 的协方差矩阵 Σ:
Σ = (1 / (n_samples - 1)) * X_centered^T @ X_centered
(b)对协方差矩阵 Σ 进行特征值分解:
ΣV = VΛ
其中 V 是特征向量矩阵(其列向量是主成分方向/载荷),Λ 是对角矩阵,对角线元素是特征值(表示对应主成分的方差)。
(c) 按特征值大小降序排列特征向量。选择前 k 个特征向量构成投影矩阵 W (k x d, d是原始特征数)。
(d) 将数据投影到新的低维空间:
X_pca = X_centered @ W^T
c.代码实现 (sklearn.decomposition.PCA):
(a) pca_model_full = PCA(n_components=n_features_original):初始化PCA模型,保留所有主成分以分析其完整谱。
(b) pca_model_full.fit(data_centered):执行上述数学步骤(计算协方差、特征分解等)。
(c) explained_variance_ratio_:获取每个主成分解释的方差比例(特征值 / 总特征值之和)。
(d) cumulative_explained_variance:计算累积解释方差比。
( e) 碎石图 (Scree Plot):可视化每个主成分的解释方差比和累积解释方差比。这有助于决定保留多少主成分。
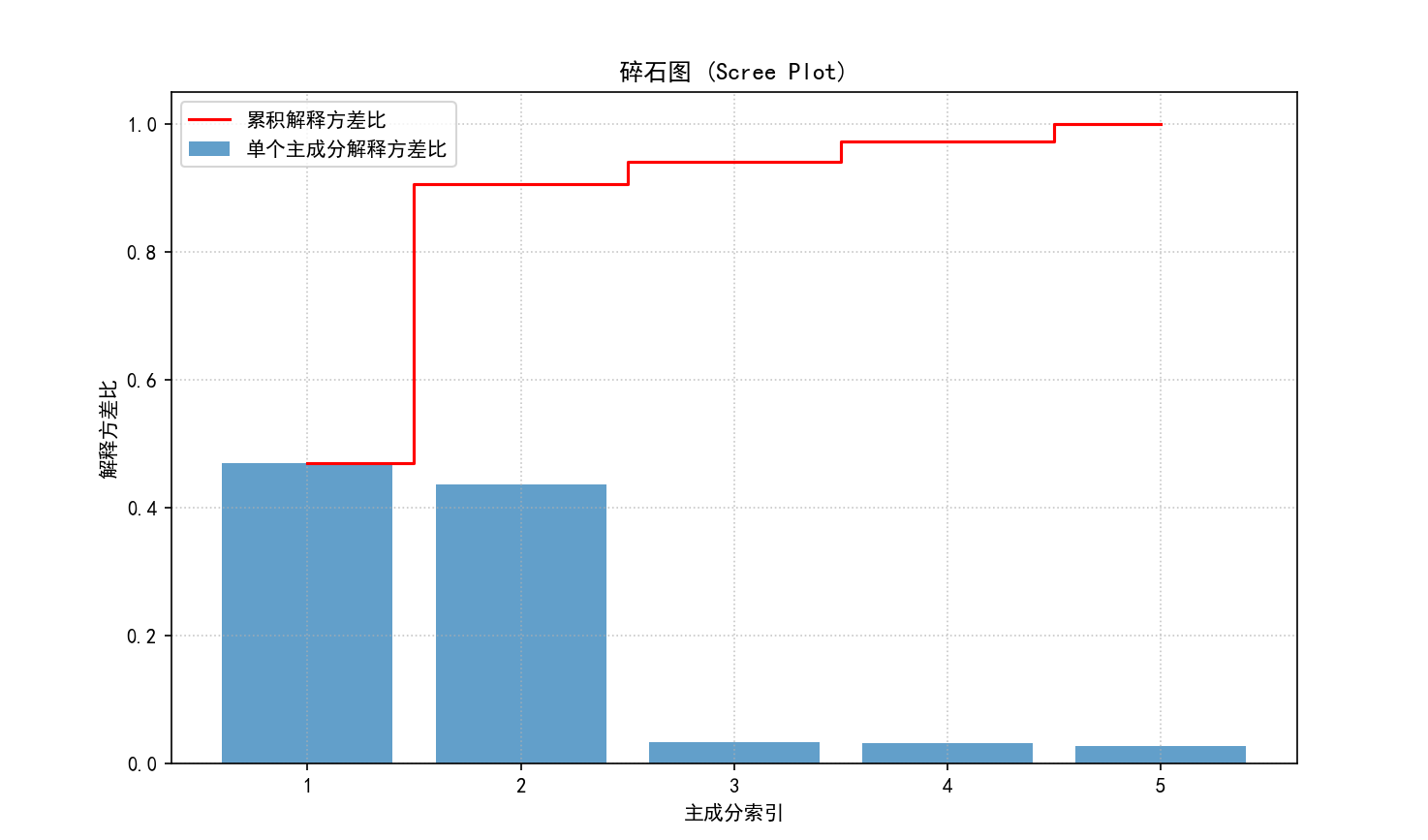
保存图像为 01_scree_plot.png。
(f)主成分载荷可视化:如果特征数大于等于2,可视化前两个主成分的载荷(特征向量的元素)。载荷表示原始特征对主成分的贡献程度。
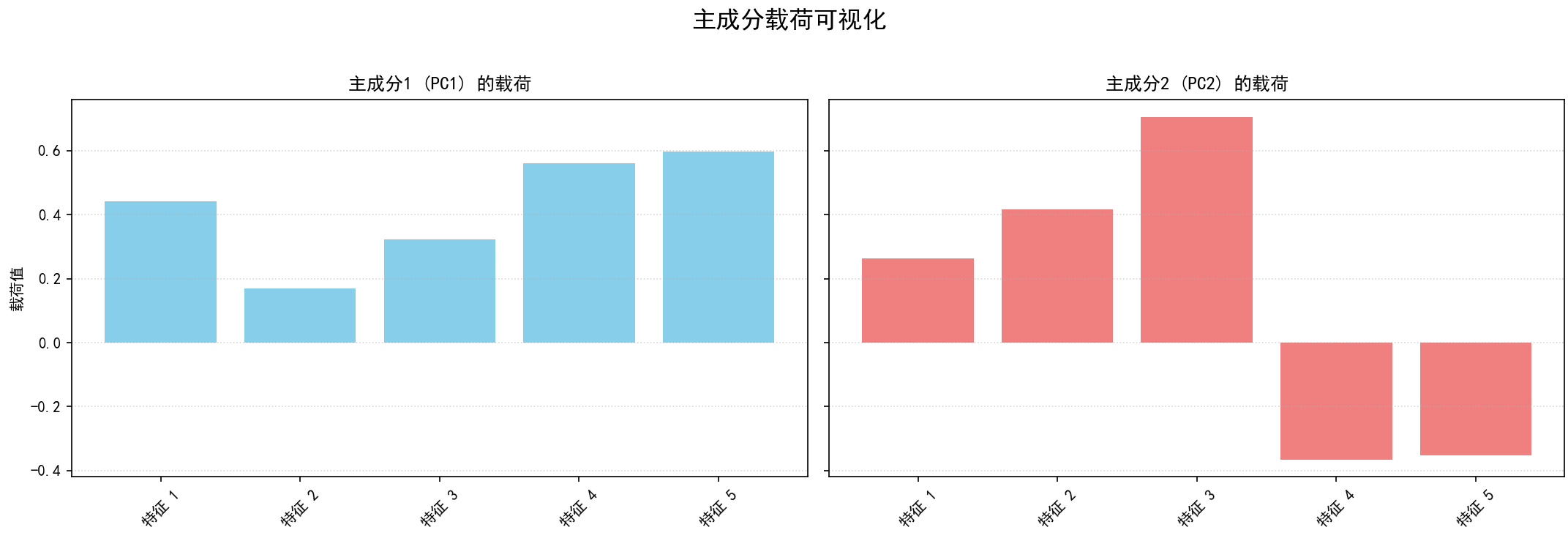
保存图像为 02_pca_loadings.png。
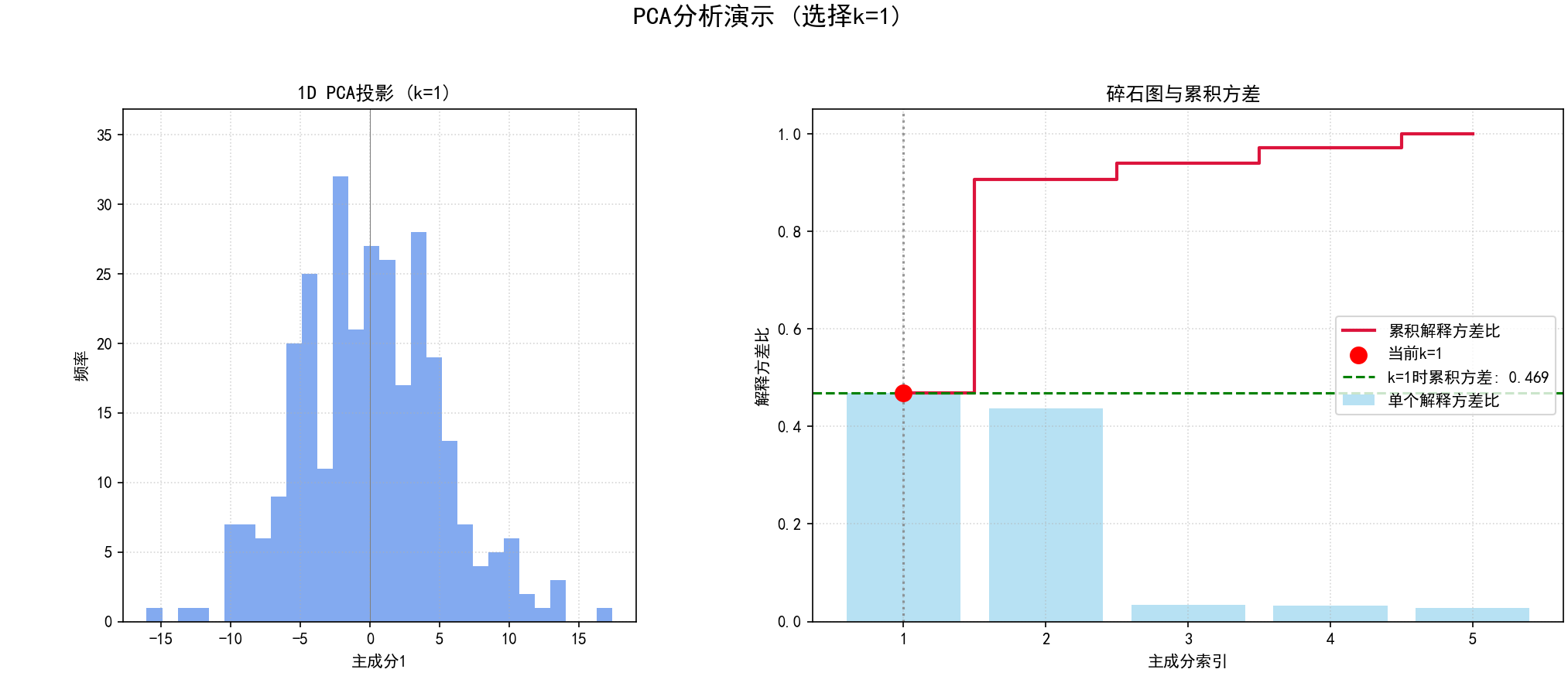
(4) “交互式”PCA图的静态演示 (函数 static_pca_plot_demonstration 和第4部分):
a.目的:模拟选择不同数量主成分 (k) 时,数据的2D投影(通常是PC1 vs PC2)和碎石图的变化。
b.步骤:
(a)使用 pca_model_full.transform(data_centered) 获得所有主成分上的投影 X_pca_full。
(b)对于预设的几个 `k` 值(例如1, 2, 3):
PCA投影图:
如果 k=1,绘制第一主成分的直方图。
如果 k>=2,绘制前两个主成分(PC1, PC2)的散点图,点按PC1的值着色。
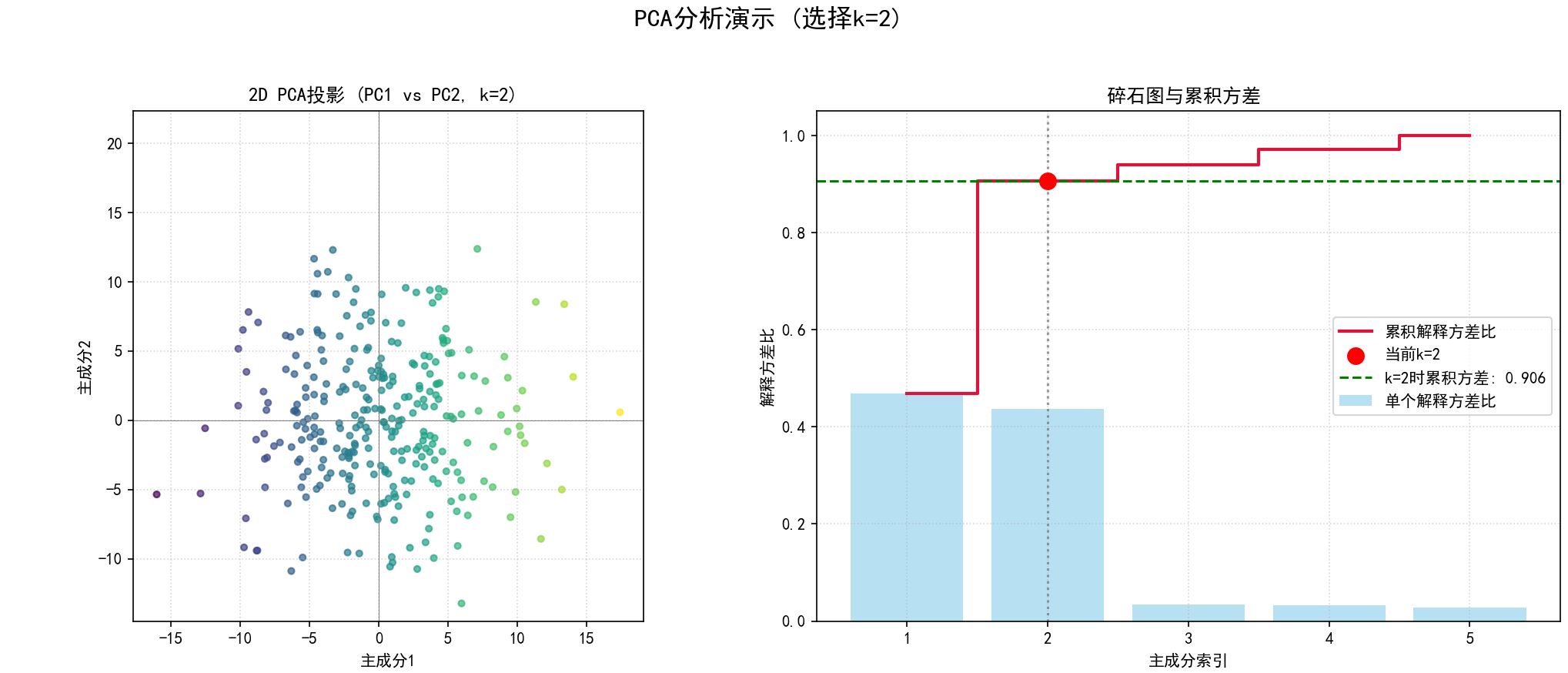
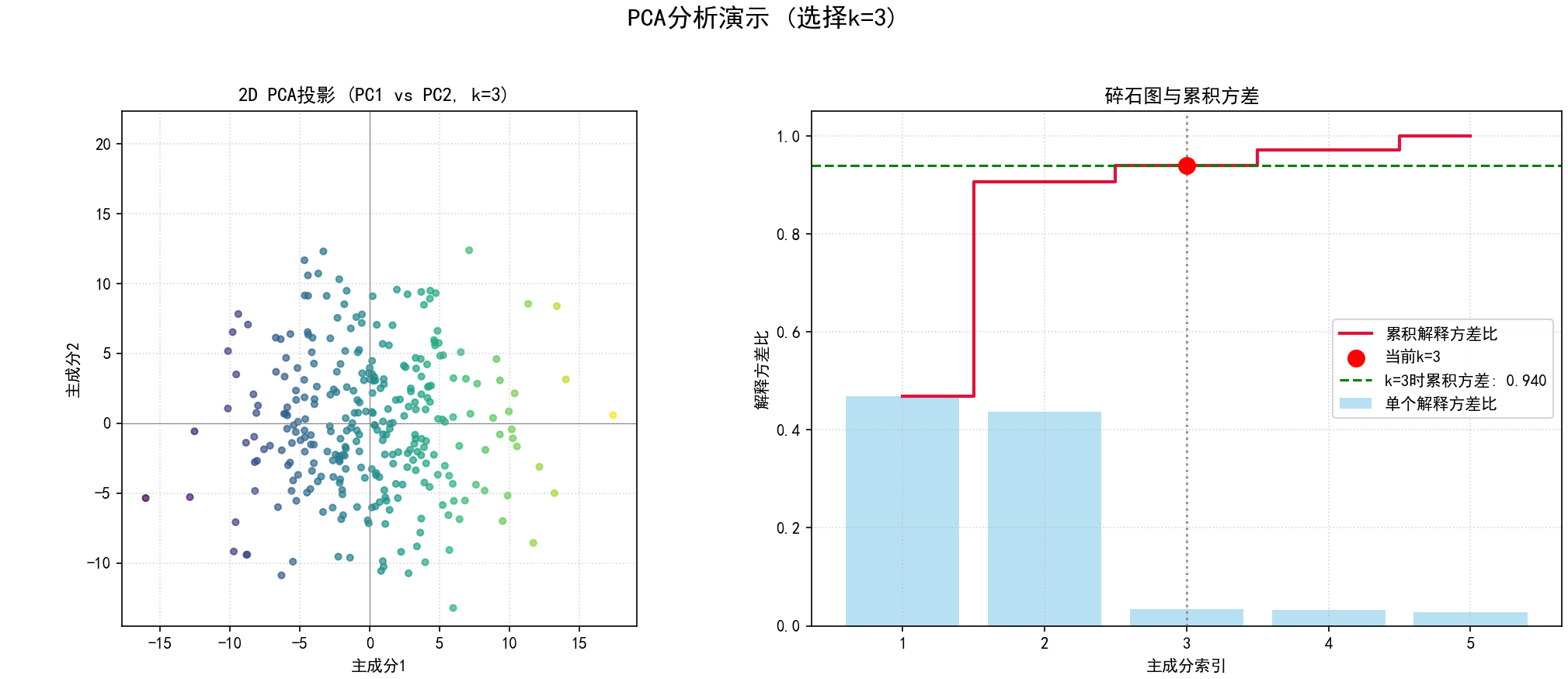
碎石图:与标准PCA分析中的碎石图类似,但会高亮显示当前选择的 k 值及其对应的累积解释方差。
(c) 为每个 k 值生成的组合图保存为 03_static_pca_demo_k{k_val}_{idx}.png。
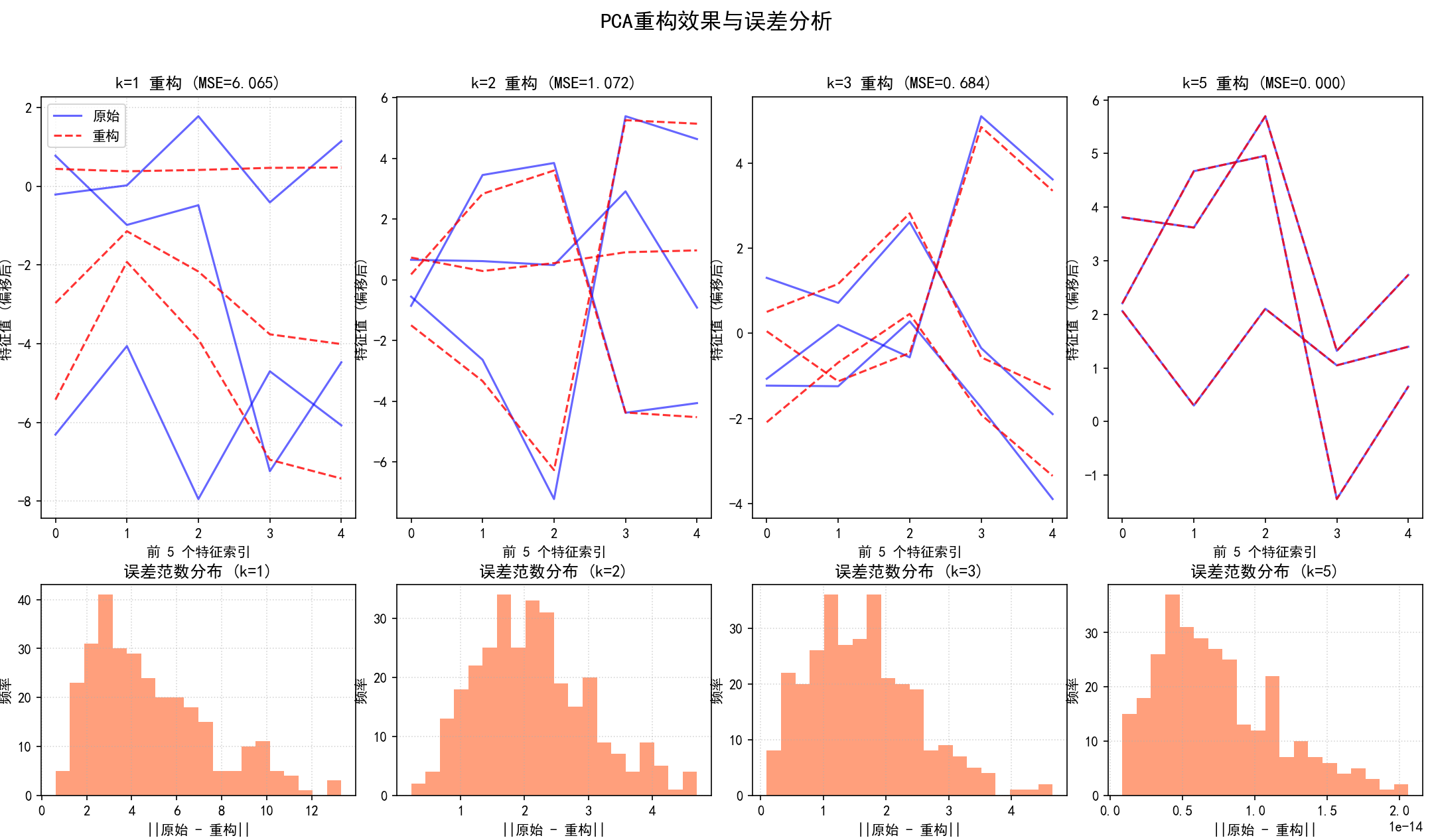
(5) PCA逆变换与重构误差评估 (函数 visualize_pca_reconstruction 和第5部分):
a.目的:评估使用不同数量主成分 k 重构原始数据时的精度。
b.数学步骤 (逆变换):
X_reconstructed = X_pca_k @ W_k + mean(X_original)
其中 X_pca_k 是使用前 k 个主成分降维后的数据,W_k 是由前 k 个主成分载荷组成的矩阵。sklearn 的 inverse_transform 会自动处理均值的加回。
* 步骤:
(a)对于一系列 `k` 值:
使用 PCA(n_components=k) 训练模型并对数据进行降维 (fit_transform)。
使用 inverse_transform 将降维后的数据重构回原始特征空间。
计算均方误差 (MSE):MSE = mean((X_original_centered - X_reconstructed_centered)^2)。
可视化重构对比:随机选择几个样本,绘制它们原始特征值与重构特征值的对比图。
可视化误差分布:绘制每个样本的重构误差范数(||原始 - 重构||)的直方图。
(b) 将上述对比图和误差分布图组合显示,保存为 04_pca_reconstruction_comparison.png。
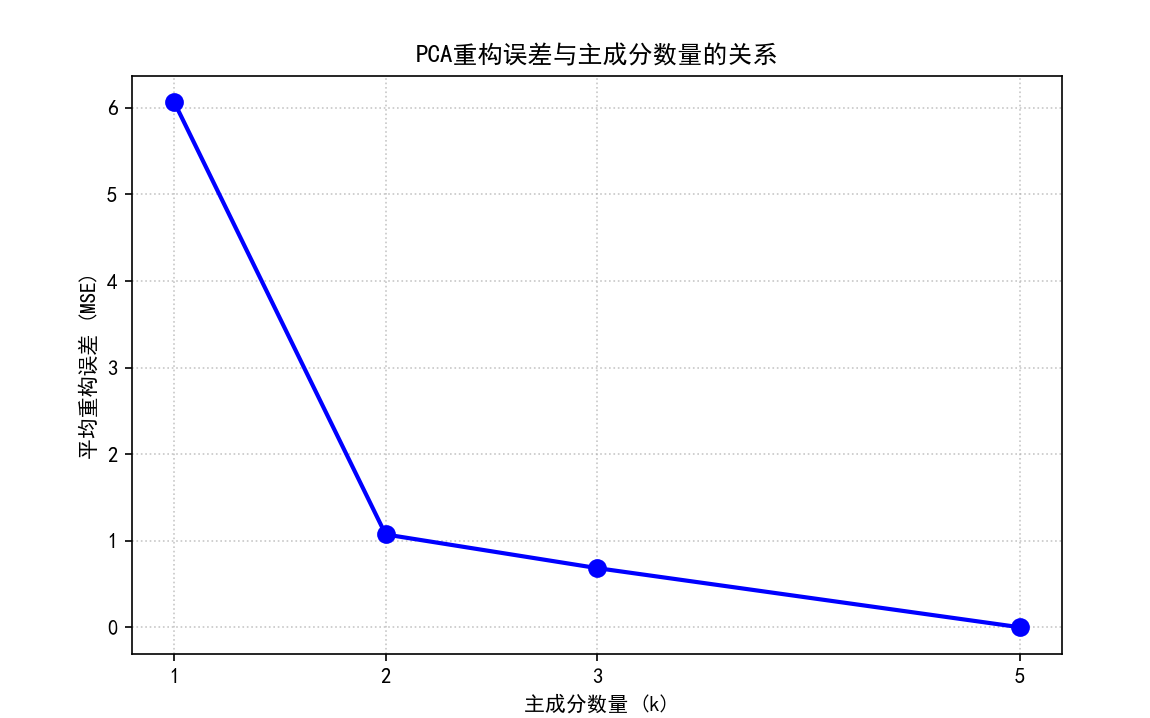
(c) 绘制 MSE 与 k 值的关系曲线图,保存为 05_pca_reconstruction_mse_vs_k.png。
(6) 稀疏PCA (Sparse PCA) (函数 implement_sparse_pca 和第6部分):
a.核心思想:在PCA的基础上引入稀疏性约束,使得主成分的载荷向量中包含许多零元素。这有助于识别对主成分贡献最大的少数几个原始特征,提高模型的可解释性。
b.数学目标 (简化形式,实际优化更复杂):
最小化 ||X - UV^T||_F^2 + α * ||V||_1
其中 U 是降维后的数据 (scores),V 是稀疏载荷矩阵 (components),α 是稀疏度控制参数(L1正则化项的系数)。
c.步骤 (sklearn.decomposition.SparsePCA):
(a) 初始化 SparsePCA(n_components=n_comp, alpha=alpha_val, n_jobs=1)。alpha 控制稀疏程度,n_jobs=1 避免并行化问题。
(b) fit_transform(X_cent) 学习稀疏主成分并转换数据。
(c) 载荷可视化:
将标准PCA的载荷和稀疏PCA的载荷并排用热图 (imshow) 展示,以对比其稀疏性。
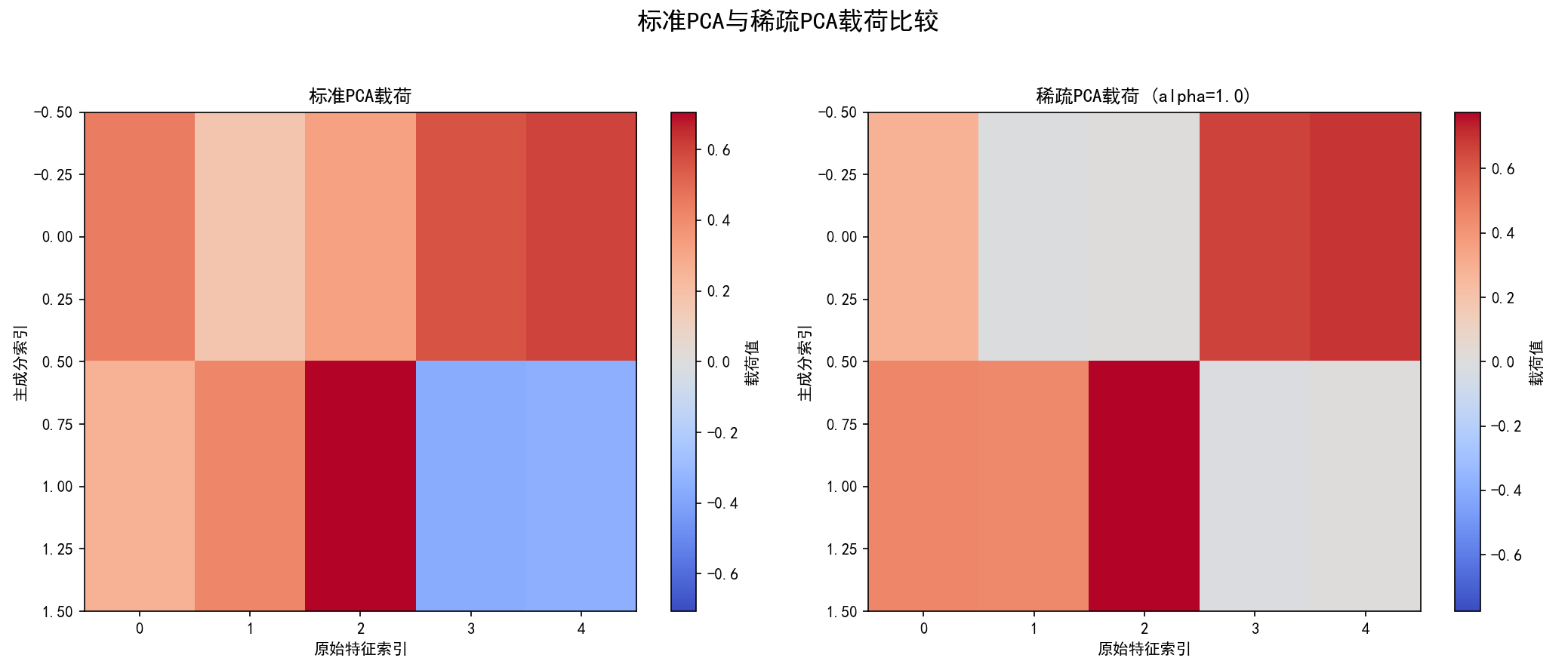
保存图像为 06_sparse_pca_loadings_alpha{alpha_val}.png。
(d) 降维结果可视化:如果 n_comp >= 2,绘制标准PCA和稀疏PCA降维后的前两个主成分的散点图进行比较。
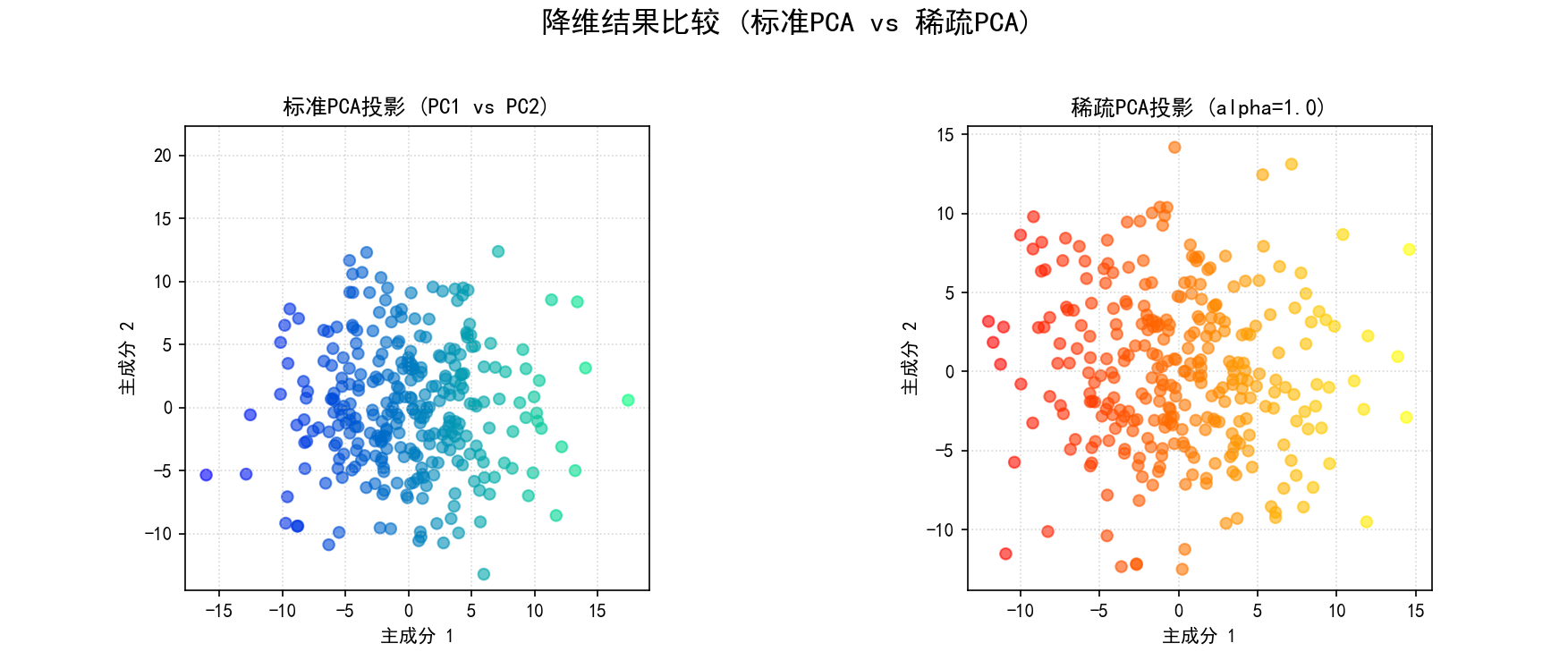
保存图像为 07_sparse_pca_projection_alpha{alpha_val}.png。
(e) 稀疏度分析:计算并打印标准PCA和稀疏PCA载荷矩阵中非零元素的比例。
(7) 核PCA (Kernel PCA) (函数 implement_kernel_pca 和第7部分):
a.核心思想:通过核技巧将数据映射到高维特征空间,然后在该高维空间中执行PCA。这使得KPCA能够发现原始特征空间中的非线性结构。
b.数学步骤:
(a)选择一个核函数 κ(x_i, x_j) (如线性核、多项式核、RBF核、Sigmoid核)。
(b) 构建核矩阵 K,其中 K_ij = κ(x_i, x_j)。
(c) 中心化核矩阵 K_centered (在特征空间中中心化)。
(d) 对 K_centered 进行特征值分解:K_centered α = λ α。
(e) 选择前 k 个特征向量 α_1, ..., α_k。
(f) 对于新的数据点 x,其在第 m 个核主成分上的投影是:
projection_m(x) = Σ_i α_m_i * κ(x_i, x)
c.步骤 (sklearn.decomposition.KernelPCA):
(a) 对于不同的核函数 (linear, poly, rbf, sigmoid):
初始化 KernelPCA(n_components=n_comp, kernel=kernel_name, gamma=gamma_val, fit_inverse_transform=True)。fit_inverse_transform=True 允许(近似的)逆变换。
fit_transform(X_cent) 执行KPCA。
(b)降维结果可视化:将标准PCA和各种核PCA降维后的前两个主成分的散点图并排展示。
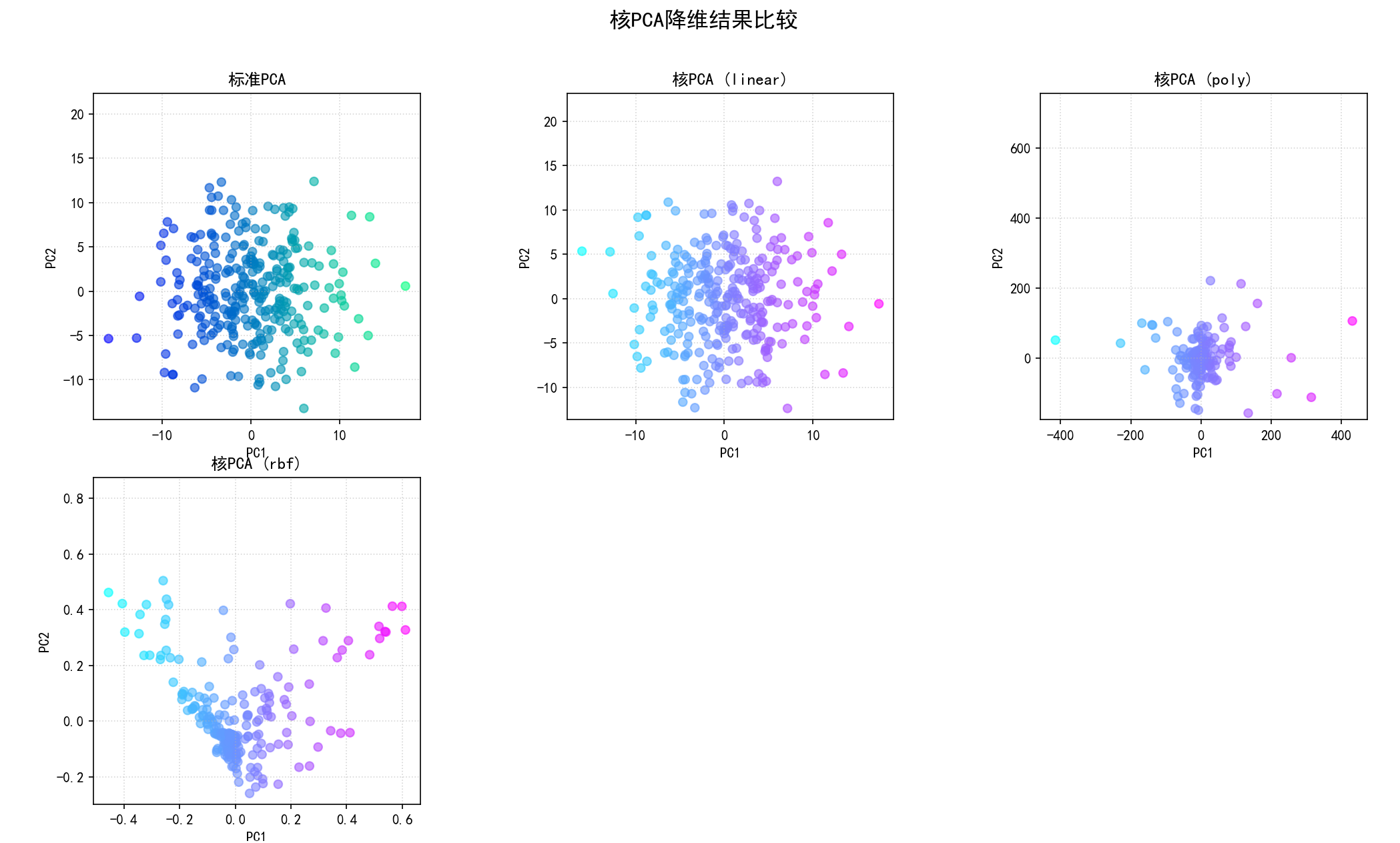
保存图像为 08_kernel_pca_projections.png。
(c) 重构误差计算:如果可能(fit_inverse_transform=True 且模型支持),计算并打印使用不同核函数重构原始数据时的MSE。
(8) 增量PCA (Incremental PCA) (函数 implement_incremental_pca 和第8部分):
a.核心思想:允许在不加载整个数据集到内存的情况下,分批次地训练PCA模型。适用于非常大的数据集。它通过对数据块进行部分PCA,并结合先前计算的结果来近似完整PCA。
b.步骤 (sklearn.decomposition.IncrementalPCA):
(a) 初始化 IncrementalPCA(n_components=n_comp, batch_size=batch_s)。batch_size 定义每次处理的数据块大小。
(b) fit_transform(X_cent) 分批次处理数据并学习主成分。
(c) 与标准PCA比较:
降维结果可视化:绘制标准PCA和增量PCA降维后的前两个主成分的散点图,并标注计算时间。
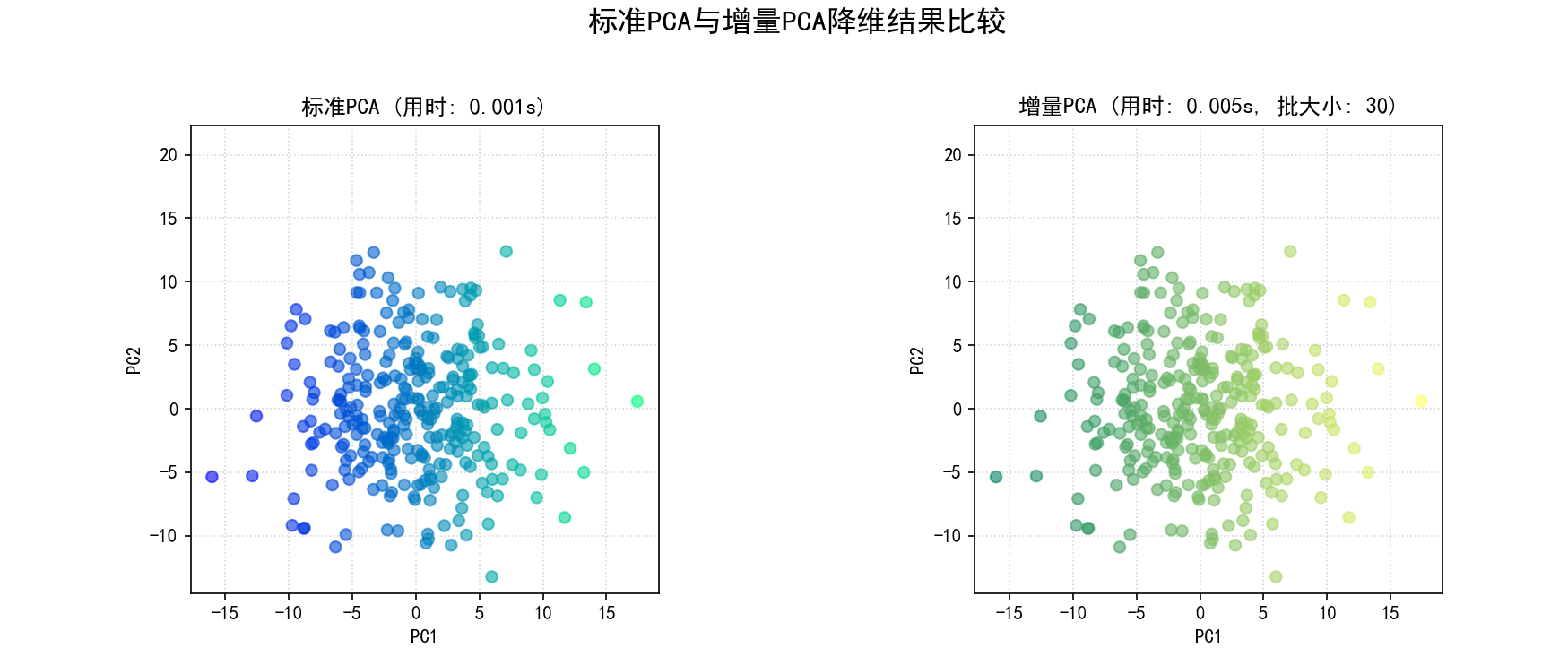
保存图像为 09_incremental_pca_comparison.png。
解释方差比比较:打印两者的解释方差比。
主成分相似性:计算两者主成分向量的点积(余弦相似度的近似)。
重构误差比较:计算并打印两者的MSE。
(9) 全面比较PCA变体 (函数 compare_all_pca_variants 和第9部分):
a.目的:在一个统一的框架下,对比标准PCA、稀疏PCA、核PCA(如果数据集不大)和增量PCA在关键指标上的表现。
b.步骤:
(a) 对中心化后的数据,依次应用上述四种PCA变体(稀疏PCA使用固定alpha,核PCA使用RBF核,增量PCA使用自动确定的批大小)。
(b) 为每种方法记录:
计算时间。
(近似的)累积解释方差比(如果可用)。
重构误差(如果可用)。
对于稀疏PCA,记录稀疏度。
(c) 可视化比较结果:创建三个条形图,分别比较不同变体在:
重构误差 (MSE)。
计算时间。
累积解释方差比。
(d) 将这三个比较图组合在一个大图中,保存为 10_pca_variants_comparison_metrics.png。
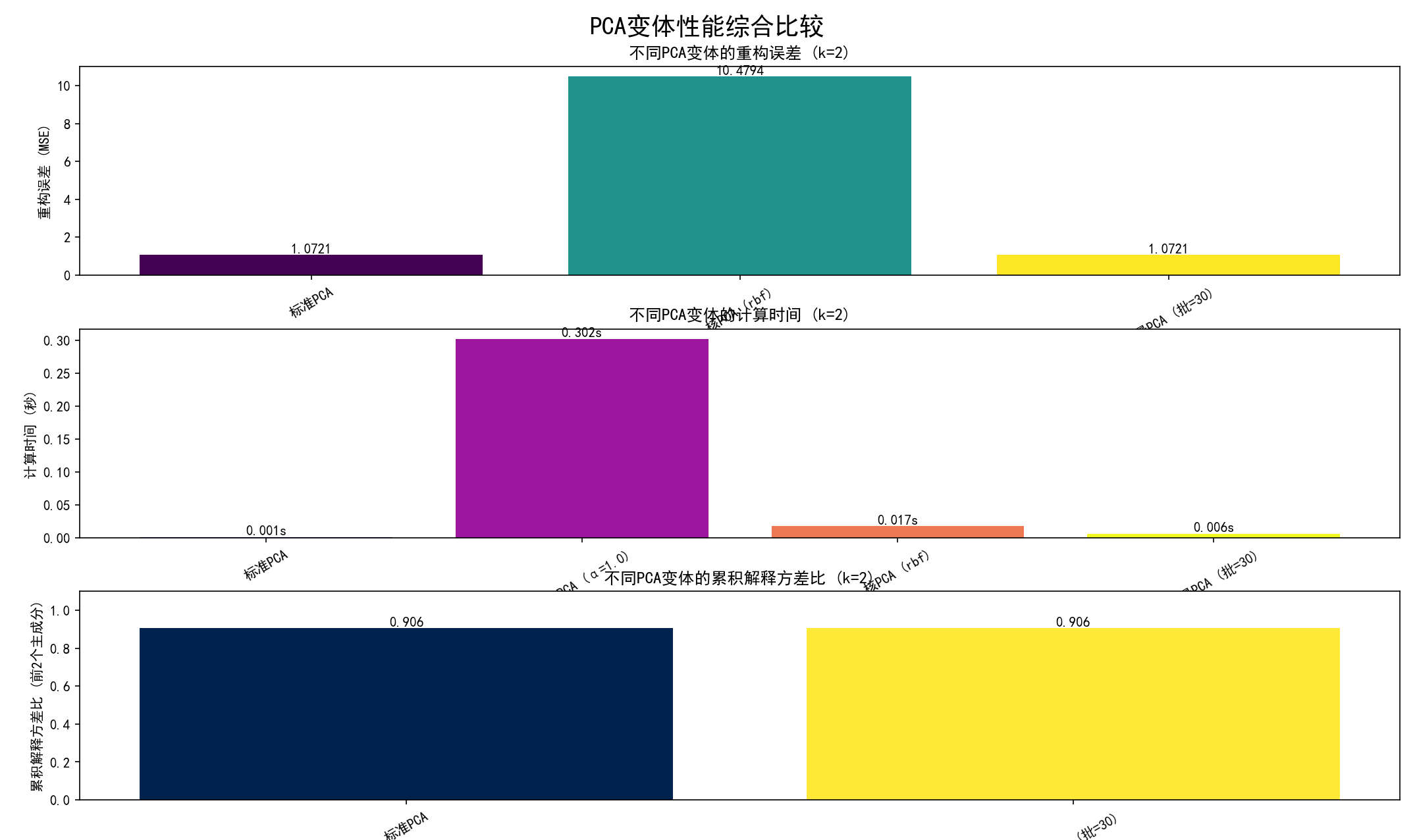
(10) 分析不同PCA变体的主成分特性 (函数 analyze_pca_components_properties 和第10部分):
a.目的:主要对比标准PCA和稀疏PCA的载荷特性。
b.步骤:
(a) 应用标准PCA和稀疏PCA。
(b) 载荷可视化:为每个选择的主成分(例如前2个),并排绘制标准PCA和稀疏PCA的载荷条形图。
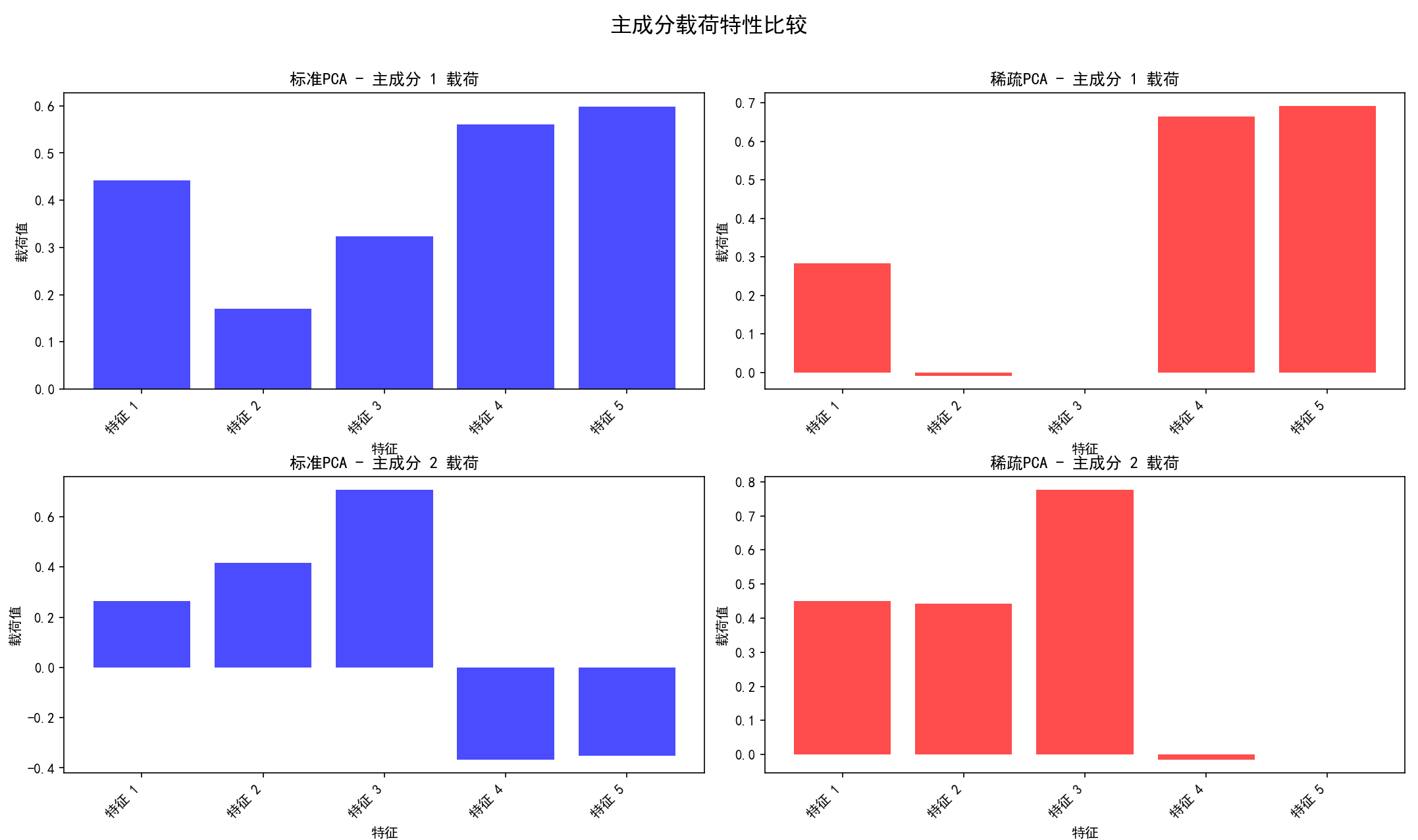
保存图像为 11_pca_component_properties.png。
(c) 稀疏度分析:计算并打印两种方法载荷的非零元素比例。
(d) 解释方差比较:打印标准PCA的累积解释方差和各主成分贡献,以及稀疏PCA的近似累积解释方差。
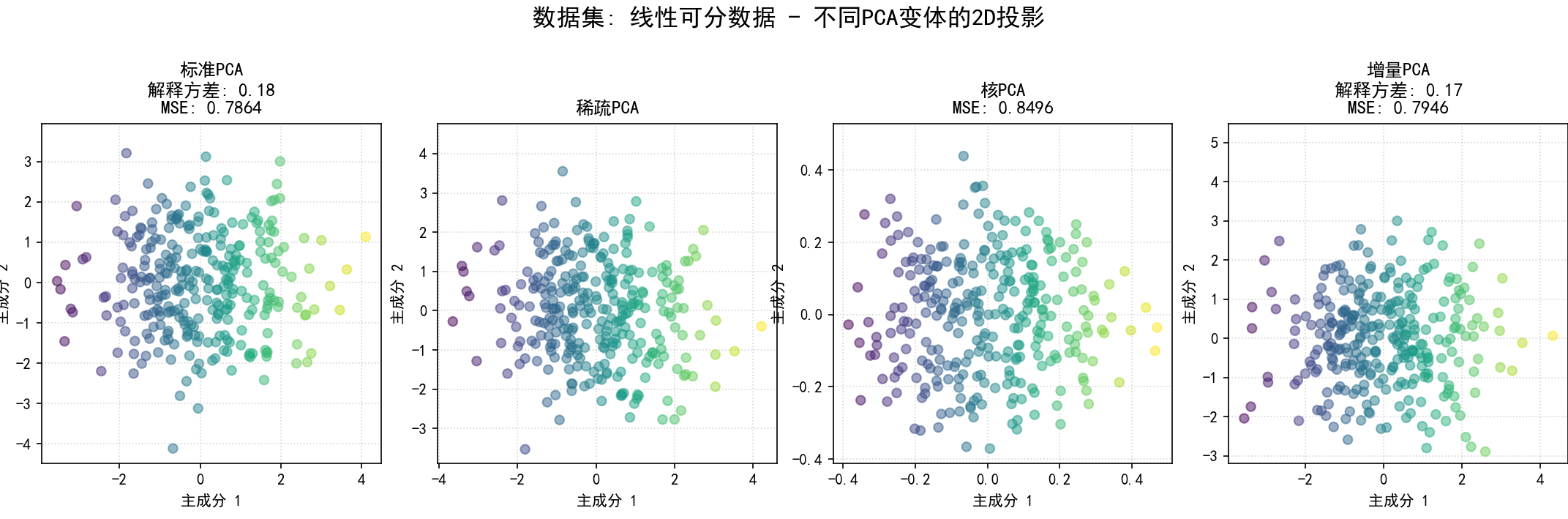
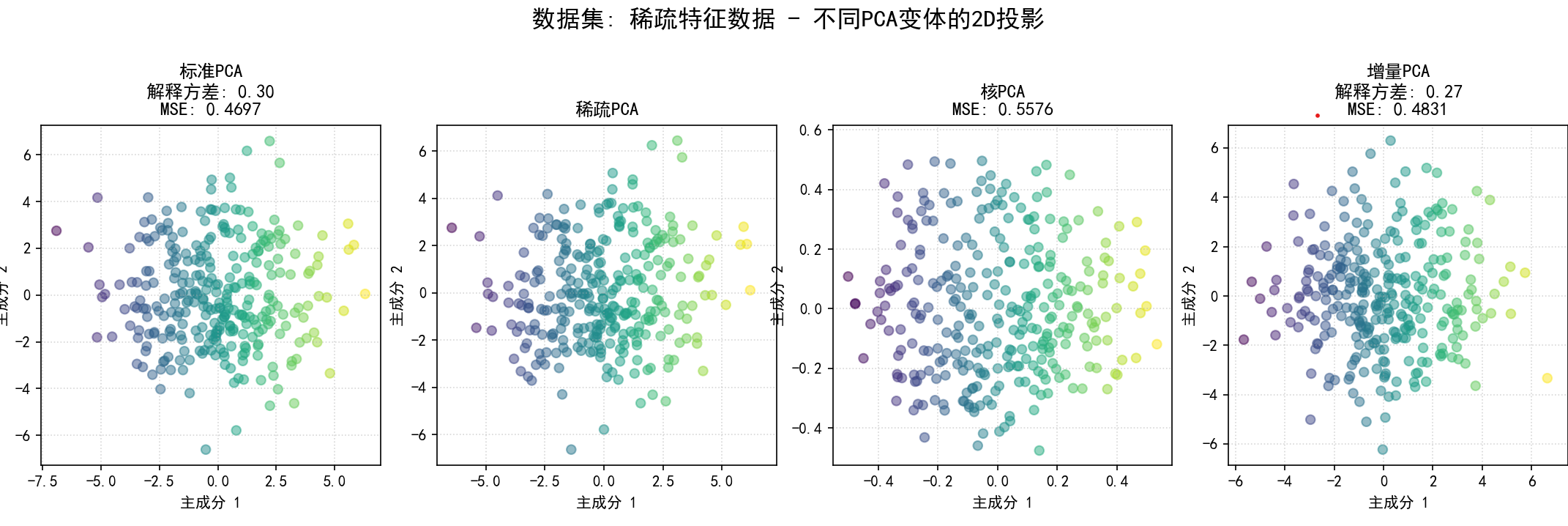
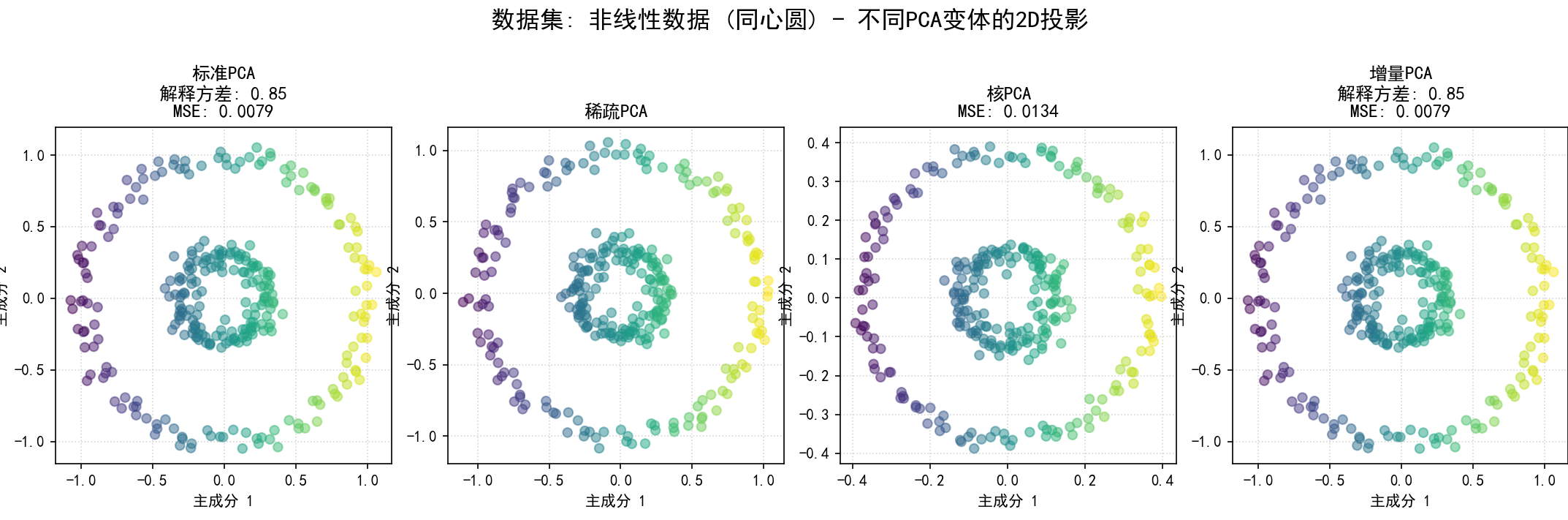
(11) 在不同类型数据集上应用PCA变体 (函数 pca_variants_on_different_datasets 和第11部分):
a.目的:展示不同PCA变体在不同数据结构(线性、稀疏特征、非线性、大规模)上的适应性和表现。
b.步骤**:
(a) 生成/定义数据集:
线性可分数据:通过混合高斯分布或引入特征间的线性相关性生成。
稀疏特征数据:大部分特征为零或噪声,少数特征包含主要信息。
非线性数据:使用 sklearn.datasets.make_circles (同心圆) 或 make_swiss_roll 生成。
大规模数据:样本量较大的随机数据。
(b) 对于每个生成的数据集:
中心化数据。
应用标准PCA、稀疏PCA(如果数据集不大)、核PCA(如果数据集不大,通常用RBF核)和增量PCA。
记录每种方法的降维结果、解释方差(如果可用)和重构误差(如果可用)。
可视化2D投影:为当前数据集,将所有成功应用的PCA变体降维后的前两个主成分的散点图并排显示,并在标题中注明方法名称、解释方差和MSE。
为每个数据集的比较图保存为 12_pca_on_dataset_{dataset_name_sanitized}.png。
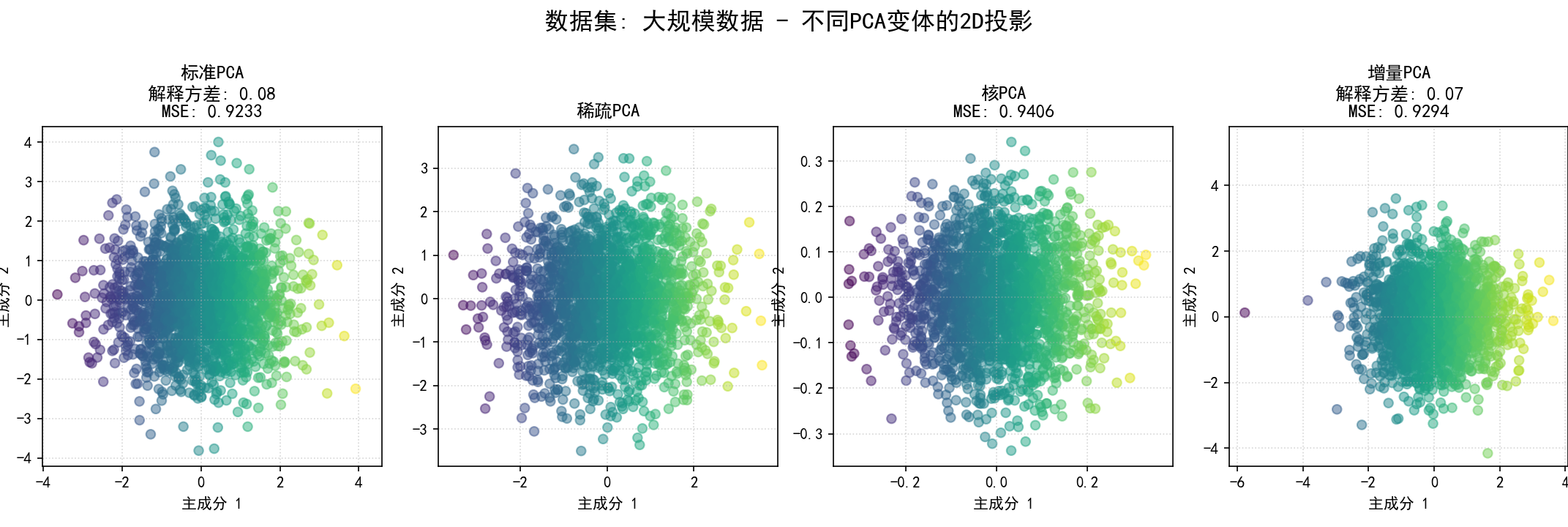
(12) 标准PCA结束语:
打印一条消息,指示标准PCA执行完毕以及图像保存的目录。
六、总结
本文系统介绍了主成分分析(PCA)这一经典的无监督线性降维技术。首先阐述了PCA的核心目标:降维、特征提取、去相关、噪声过滤和数据可视化。然后详细讲解了PCA的数学基础,包括方差、协方差、协方差矩阵、特征值与特征向量等概念,以及完整的算法步骤:数据标准化→计算协方差矩阵→特征分解→排序并选择主成分→构建投影矩阵→数据降维。
