
【机器学习】概率图模型

一、引言
在本文中,我们将讨论无监督学习中的数据分布建模问题。当我们需要在一个数据集上完成某个任务时,数据集中的样本分布显然是最基本的要素。面对不同的数据分布,我们可能针对同一任务采用完全不同的算法。例如,如果样本有明显的线性相关关系,我们就可以考虑用基于线性模型的算法解决问题;如果样本呈高斯分布,我们可能会使用高斯分布的各种性质来简化任务的要求。如果在数据分布不明显的情况下,我们可能会使用数据降维算法(如主成分分析算法)来尽可能提取出数据的关键特征。因此,如何建模数据集中样本关于其各个特征的分布,就成了一个相当关键的问题。
在生活中,我们常常会看到这样的情况:秋天时,一群人在路上行走,黄叶遍地,风光无限。但是,在同一个温度下,不同人的衣着也有差异。有人穿了厚厚的大衣,有人穿了长袖长裤,还有人穿着短袖或者裙子。可以设想,如果气温再高一些,穿短袖或者裙子的人会增加;如果气温再低一些,恐怕就不会有人再穿短袖或者裙子了。因此我们可以认为,人群穿衣选择的概率分布受到天气的影响。
我们先从最简单的表格数据看起,假设表中是天气和人群中衣服选择的部分数据,我们可以直接从中写出最简单的数据分布:
P(天气 = 热,衣服 = 衬衫) = 0.48
天气 | 衣服 | 概率 |
热 | 衬衫 | 0.48 |
热 | 大衣 | 0.12 |
冷 | 衬衫 | 0.08 |
冷 | 大衣 | 0.32 |
以此类推,我们可以把表中的每一行都写出来,得到样本的分布。但是,这样的做法显然过于低效。当特征的数目增加时,我们按此建模的复杂度将呈指数增长。因此,我们需要设法寻找不同特征之间的相关性,降低模型的复杂度。例如,根据生活常识,我们可以认为人们选择衣服的概率应该是和天气有关的。天气热时,人们更倾向于选择衬衫,而天气冷时倾向于大衣。这样,我们可以将上面的分布转化为条件概率:
P(天气 = 热) = 0.6,P(衣服 = 衬衫|天气 = 热) = 0.8
通过这种方式,我们可以建立起样本不同特征之间的关系。如果用随机变量t表示天气,c表示衣服,那么上述的关系可以表示为图中的结构。
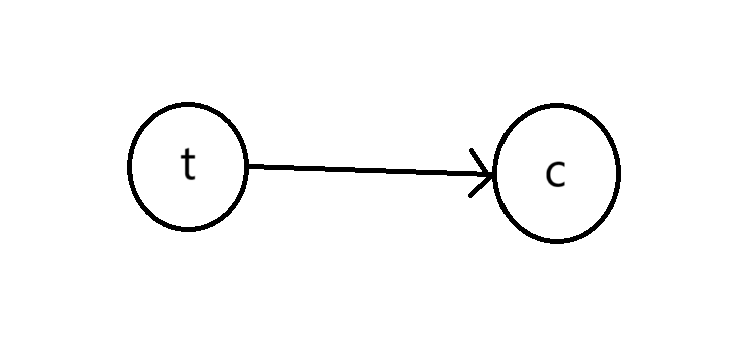
在图中,从t指向c的箭头表示随机变量c依赖于t。把样本的所有特征按依赖关系列出来,每个特征作为一个顶点,每对依赖关系作为一条边,就形成了一张概率图。我们可以通过概率图中体现的不同特征之间的关系,推断出数据的概率分布。由依赖关系构成的图是有向图,称为贝叶斯网络。如果我们知道两个特征之间相关,但没有明确的单向依赖关系,就可以用无向图来建模,称为马尔可夫网络。下面,我们就来介绍这两种概率图模型的具体内容。
二、贝叶斯网络
1. 核心思想与结构
朴素贝叶斯网络是一种基于贝叶斯定理的简单概率分类器,其核心假设是:给定类别标签时,所有特征之间是条件独立的。
2. 数学公式详解
(1)贝叶斯定理 (Bayes' Theorem):

(2)朴素的特征条件独立性假设:
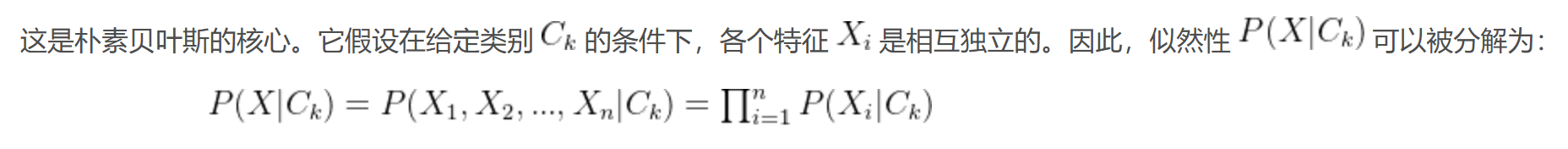
(3)后验概率计算:

(4)分类决策规则:

(5)参数估计 (Parameter Estimation):

3.优点
简单高效: 算法逻辑简单,计算速度快,易于实现。
对小数据集表现良好:即使训练数据量不大,也能获得不错的效果,因为它只需要估计先验概率和条件概率。
处理高维数据:在特征数量很多的情况下(如文本分类中的词汇表大小),依然能有效工作。
对无关特征不敏感: 如果数据中存在与分类任务无关的特征,朴素贝叶斯受到的影响相对较小。
4. 缺点
特征条件独立性假设过于理想化: 这是其“朴素”的来源。在现实世界中,特征之间往往存在一定的关联性。这个强假设可能会限制模型的精度,尤其是在特征高度相关的情况下。
零概率问题: 如果在训练阶段某个特征值在某个类别下从未出现过,那么整个后验概率为0。这通常通过平滑技术(如拉普拉斯平滑/加法平滑)来解决,即给所有计数都加上一个小的正数。
5. 常见变体
根据特征的数据类型不同,朴素贝叶斯有几种常见变体:
高斯朴素贝叶斯 (Gaussian Naive Bayes): 适用于连续型特征,假设特征服从高斯分布。
多项式朴素贝叶斯 (Multinomial Naive Bayes):常用于文本分类,特征通常是词频计数。
伯努利朴素贝叶斯 (Bernoulli Naive Bayes):也用于文本分类,特征是二值的(表示词语是否出现)。
6. 应用
广泛应用于文本分类(垃圾邮件过滤、情感分析、新闻分类)、医疗诊断、推荐系统等。
三、最大后验估计 (Maximum A Posteriori Estimation, MAP)
1. 定义与目的

2. 数学公式详解


3.作用与优势
正则化/防止过拟合:先验分布 P(θ) 可以起到正则化项的作用。例如,如果先验倾向于选择较小的参数值,那么即使数据本身可能导致参数值很大(可能过拟合),MAP也会将其拉向一个更“合理”的范围。这在数据量较少时尤其有用。
引入先验知识:允许分析者将关于参数的已有信念或领域知识整合到估计过程中。
提供点估计:像MLE一样,MAP也提供参数的一个具体估计值,而不是一个完整的后验分布(像完全贝叶斯推断那样)。
四、马尔可夫网络 (Markov Network / Markov Random Field, MRF)
1. 定义与结构

2. 核心特性 (马尔可夫性质)

3. 因子分解与势函数 (Hammersley-Clifford Theorem)

4. 对数线性模型与吉布斯分布 (Log-Linear Models and Gibbs Distribution)

5.与贝叶斯网络的区别
图结构:贝叶斯网络是有向无环图 (DAG),边表示因果关系或条件依赖。马尔可夫网络是无向图,边表示变量间的对称关系或软约束。
概率分解:贝叶斯网络的联合概率通过条件概率链式法则分解 。马尔可夫网络通过团上的势函数分解。
表达能力:马尔可夫网络可以自然地表示贝叶斯网络难以直接表示的循环依赖关系(例如,图像中相邻像素的相互影响)。
6.推断 (Inference)
推断任务包括计算边缘概率或条件概率。
精确推断在一般MRF中是NP难的,因为需要计算配分函数Z。
常用的近似推断算法包括:
置信传播 (Belief Propagation, BP)及其变体(如Loopy Belief Propagation,用于有环图)。
变分推断 (Variational Inference):用一个更简单的分布来近似真实的后验分布。
马尔可夫链蒙特卡洛 (MCMC) 方法:如吉布斯采样 (Gibbs Sampling),通过从目标分布中采样来近似期望值。
7. 学习 (Learning)
参数学习:给定图结构,从数据中学习势函数的参数。由于配分函数Z的存在,直接的最大似然估计很困难。常用的方法有:
伪似然估计 (Pseudo-Likelihood Estimation)。
对比散度 (Contrastive Divergence, CD),常用于训练受限玻尔兹曼机 (RBM) 等能量模型。
最大间隔马尔可夫网络 (Max-Margin Markov Networks)。
结构学习:从数据中学习图的结构(即哪些变量之间应该有边)。这是一个比参数学习更具挑战性的问题。
8. 应用
马尔可夫网络在许多领域都有重要应用,特别是在需要对变量间的局部依赖关系和上下文信息进行建模的场景:
计算机视觉:图像去噪、图像分割、图像恢复、物体识别、立体视觉。
自然语言处理:词性标注、命名实体识别、信息抽取(通常以条件随机场CRF的形式出现,CRF是MRF的一种判别式模型)。
生物信息学:基因序列分析、蛋白质结构预测。
社交网络分析:分析网络结构和影响力传播。
统计物理:如伊辛模型,用于描述粒子系统。
