
GraphRAG:融合知识图谱与RAG的下一代信息检索框架

前言
在大语言模型广泛应用于文本问答与信息检索场景的今天,基于检索增强生成(Retrieval-Augmented Generation,简称 RAG)的方法成为了提升回答准确性的重要手段。然而,传统 RAG 模型在处理文本时面临诸多挑战,特别是在信息切分、语义保持以及深层次理解方面存在明显不足。
为了解决这些痛点,GraphRAG 作为一种新型的信息检索与生成架构,融合了知识图谱与 RAG 的优势,通过结构化的图谱构建和智能问答策略,显著提升了模型的推理与检索能力。本文将围绕 GraphRAG 的设计理念、技术架构与优势展开深入解析。
1 GraphRAG 的设计背景与动机
1.1 传统 RAG 模型的瓶颈
RAG 模型的核心机制是在生成回答前检索相关文档片段,然后基于这些片段生成答案。但在实际应用中,传统 RAG 面临以下挑战:
- 信息切分粒度问题:切分过大导致细节丢失,切分过小则破坏语义联系。
- 上下文缺失问题:无法跨段理解文本中的长程依赖与复杂关系。
- 知识整合困难:难以识别多段文字中的共通实体与隐含关系。
例如,用户提出“文中某个词汇出现了几次?”这类具体问题时,如果相关词汇被分散在多个切片中,系统很可能无法准确响应。
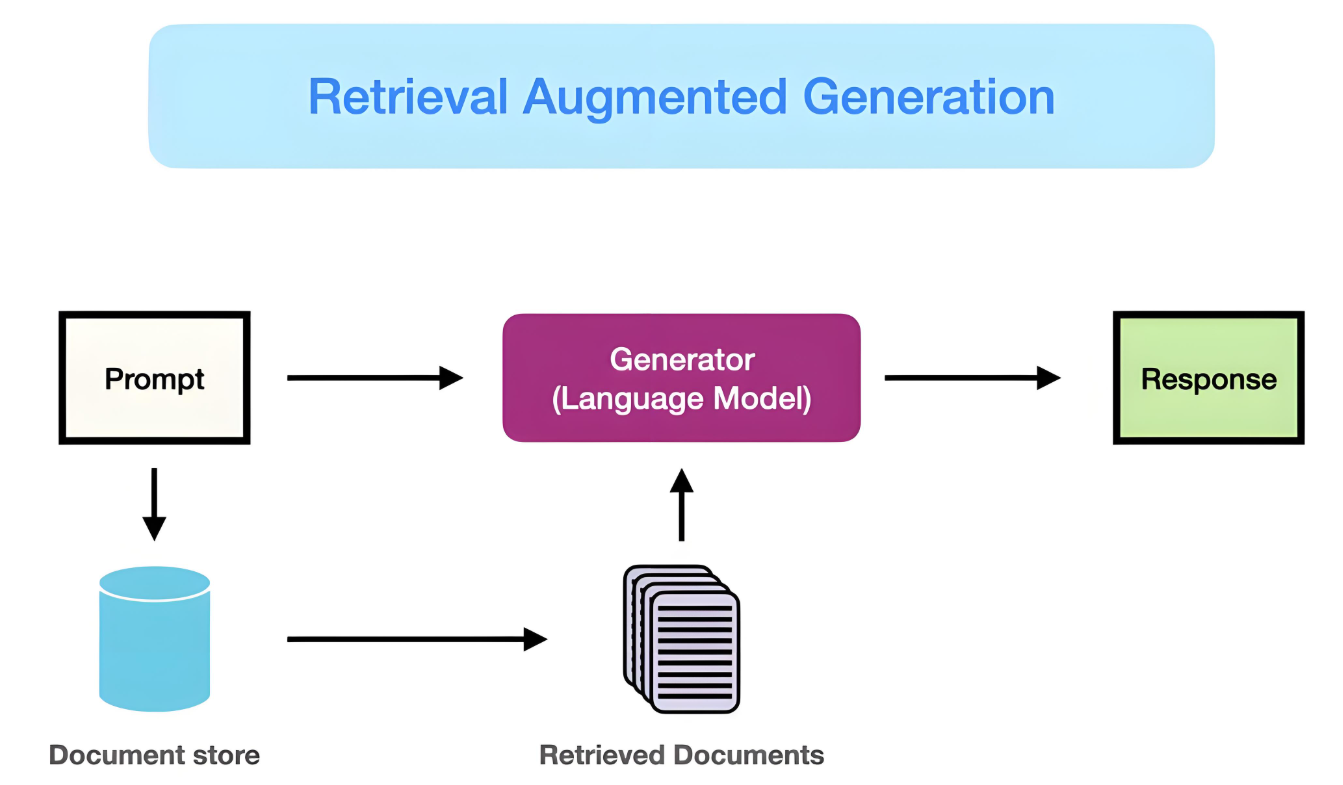
1.2 知识图谱作为补充机制
为弥补上述不足,知识图谱被引入作为增强机制。知识图谱具备以下显著优势:
- 能够保留信息的结构化语义关系;
- 提供清晰的实体-关系网络,利于推理;
- 可作为高效索引,辅助快速检索。
因此,结合知识图谱与大语言模型生成能力的 GraphRAG 便应运而生。
2 GraphRAG 的核心机制与架构
2.1 从文本到图谱的转换流程
GraphRAG 首先将原始文本转化为结构化的知识图谱,基本流程如下:
步骤 | 描述 |
|---|---|
文本切分 | 将长文本按段落或语义分块处理 |
实体识别 | 使用提示语识别人物、地点、组织等命名实体 |
关系抽取 | 抽取实体间的关系,形成结构化边 |
图谱构建 | 构建属性图(LPG)并嵌入数据库 |
图谱合并 | 自动整合相同名称的实体,形成全图 |
通过上述流程,GraphRAG 将散乱的文本转化为具有语义关系的结构化知识图谱。
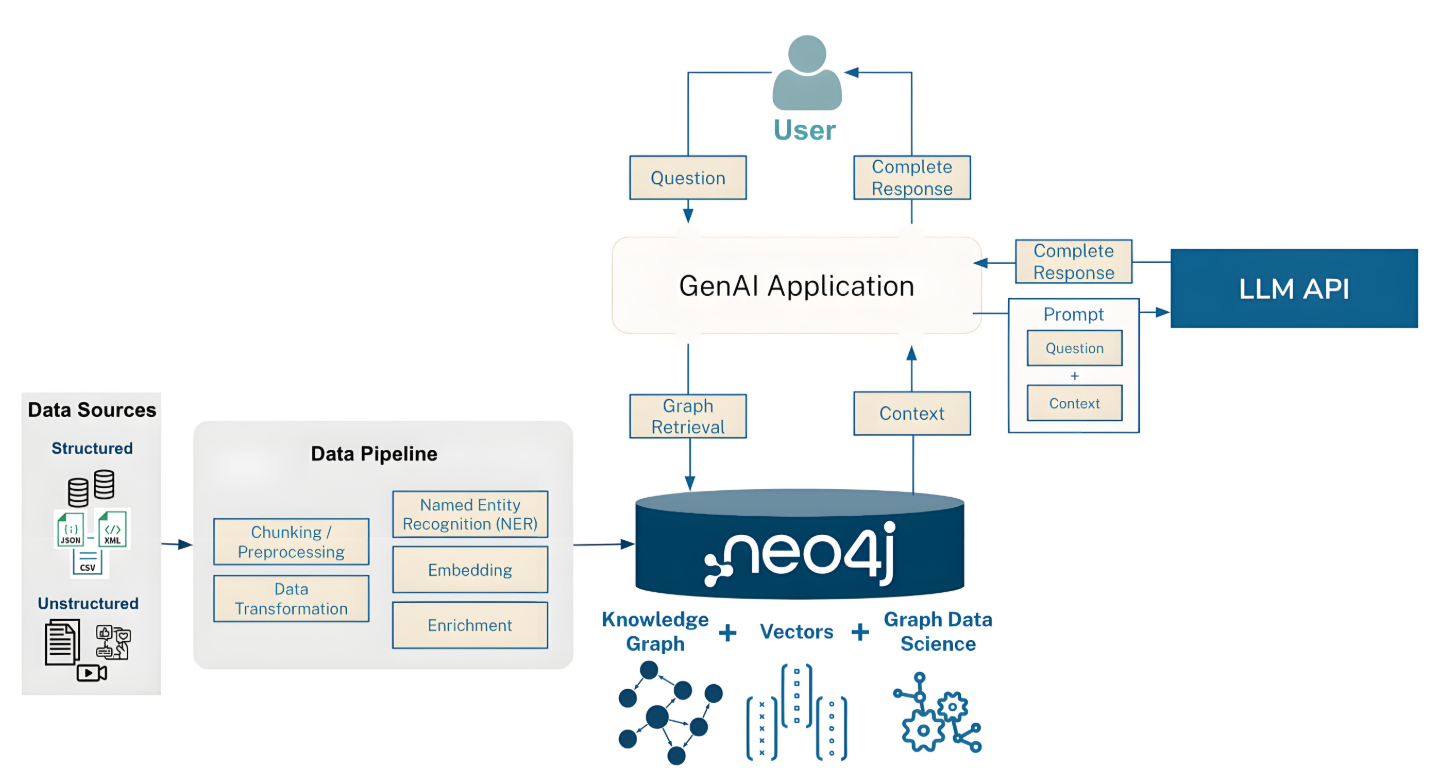
2.2 实体与关系的建模策略
知识图谱的基础包括三要素:
- 实体(Entity):如“王”、“苹果公司”、“北京”;
- 关系(Relation):如“属于”、“位于”、“聘用”;
- 属性(Property):提供补充上下文,如“时间”、“职位”等。
GraphRAG 默认识别四类实体:人物、组织、地点、事件,也支持用户自定义扩展。关系识别通过提示工程实现,大大降低了建图门槛。
2.3 图谱的优化与抽象
在构建初始图谱后,GraphRAG 会:
- 对相同实体进行合并;
- 使用 Leiden 社区检测方法聚合高密度子图;
- 生成段落级、文档级图谱;
- 提取推理信息,如隐藏关系与属性推断。
最终输出结构紧凑、语义清晰的知识网络,并嵌入向量数据库以支持后续查询。
3 信息检索与问答策略
3.1 局部搜索与全局搜索并用
GraphRAG 在问答阶段采用双重策略:
- 局部搜索:从知识图谱底层节点出发,定位与问题最相关的实体,适用于精细问题,如“王在哪一年创办公司?”
- 全局搜索:从图谱高层结构出发,把握整体语义脉络,适用于抽象问题,如“这篇文章的主题是什么?”
这种策略有效地弥补了传统 RAG 中局部过强、整体理解不足的问题。
3.2 图谱映射与原文链接
GraphRAG 在构建知识图谱的同时,保留了图谱与原始文本之间的映射关系。这使得:
- 用户查询时可直接跳转到对应文本片段;
- 系统能在回答中引用原文依据;
- 增强了回答的可解释性与可信度。
3.3 数据获取与反复提问机制
GraphRAG 的另一个核心创新在于数据获取过程:每次生成图谱后,系统会自动向 AI 提出“是否还有遗漏?”的追问。这种迭代提问与信息提取机制显著提升了图谱的覆盖度与完整性。
4 GraphRAG 的优势与应用场景
4.1 与传统 RAG 模型对比
对比维度 | 传统 RAG | GraphRAG |
|---|---|---|
切分粒度处理 | 固定切片,容易丢失语义 | 图谱层次化处理,语义完整 |
实体识别能力 | 弱,依赖片段上下文 | 强,图谱结构显性标注 |
多段整合能力 | 弱,难以跨段抽取信息 | 强,自动合并实体与关系 |
回答可解释性 | 弱,缺乏来源标注 | 强,支持反向索引与原文追溯 |
问题适应性 | 依赖检索片段质量 | 支持局部+全局双搜索 |
4.2 适用场景举例
- 企业知识库问答系统:自动构建产品文档图谱,提升技术支持效率;
- 学术论文理解工具:将科研文章转化为知识图谱,辅助读者把握核心观点;
- 法律条款解读平台:提取法条间的关联与推理路径,提升检索精准度;
- 历史事件学习平台:整合人物、时间、事件三维信息,构建历史图谱助力教学。
5 未来展望与挑战
尽管 GraphRAG 展现了强大的信息组织与理解能力,但仍存在挑战:
- 实体歧义处理:同名实体的区分仍需优化;
- 图谱动态更新:面对实时数据变更,图谱更新策略尚待完善;
- 跨模态扩展:图谱结构可否进一步用于图像、音频等多模态场景?
未来,GraphRAG 有望与多模态 AI、增强记忆体技术结合,成为通用知识管理平台的核心模块。
结语
GraphRAG 将知识图谱与 RAG 技术深度融合,不仅突破了传统文本检索的诸多限制,更为大语言模型在理解与推理层面的应用提供了新路径。它的设计理念不仅接近人类的认知方式,也为 AI 系统提供了更加结构化的知识组织方式。
随着语言模型能力的不断增强,GraphRAG 所代表的图谱增强型生成系统,将成为企业、科研和教育领域信息处理的新标配。在追求智能化与解释性的道路上,GraphRAG 正引领着生成式 AI 的新一轮进化。
