引言:智能问答时代的技术革命
还记得几年前,我们向AI助手提问时,它们只能基于训练时的静态知识回答问题,经常出现信息过时、知识盲区或者"一本正经地胡说八道"的情况吗?如今,**检索增强生成(Retrieval-Augmented Generation,RAG)**技术正在彻底改变这一现状。
想象一下,有这样一个智能系统:它不仅具备大语言模型的强大生成能力,还能实时从海量知识库中检索最相关的信息,将检索到的知识与用户查询完美融合,生成既准确又具有时效性的回答。这就是RAG技术为我们带来的革命性突破。
作为一名在AI领域深耕多年的技术研究者,我深深被RAG技术的设计理念和实现方式所震撼。它不仅解决了传统大模型的知识局限性问题,更为企业级AI应用提供了一条可行的技术路径。本文将从技术原理、架构设计、实现方法到实际应用,全方位解析RAG技术的精髓所在。
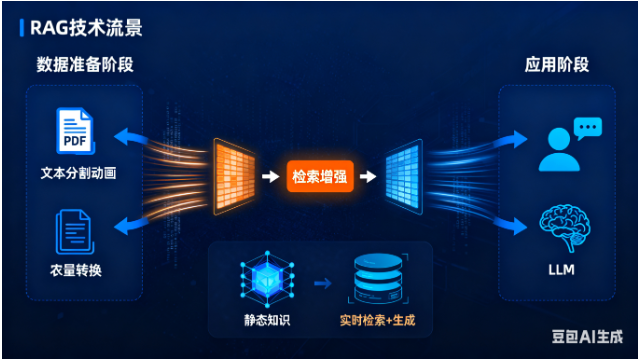
第一章:技术原理解构 - RAG的核心理念与工作机制
1.1 RAG技术的本质:检索与生成的完美融合
RAG技术的核心理念可以用一个简单的公式来表达:
RAG = 检索技术 + LLM生成 + 上下文融合
这种设计的精妙之处在于它巧妙地结合了两种AI能力:
- 检索能力:从大规模知识库中快速定位相关信息
- 生成能力:基于检索到的信息生成连贯、准确的回答
传统的大语言模型面临三大核心挑战:
- 知识的局限性:模型知识完全源于训练数据,无法获取实时性、非公开或私域数据
- 幻觉问题:基于概率的生成机制导致模型可能产生看似合理但实际错误的内容
- 数据安全性:企业不愿将私域数据上传到第三方平台进行训练
1.2 RAG的工作流程:从查询到生成的完整链路
RAG系统的工作流程可以分为两个主要阶段:
数据准备阶段(离线处理)
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
loader = PyPDFLoader("enterprise_knowledge.pdf")
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
separators=["\n\n", "\n", "。", "!", "?"]
)
texts = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(
documents=texts,
embedding=embeddings,
persist_directory="./chroma_db"
)
应用阶段(实时处理)
from langchain.llms import OpenAI
from langchain.chains import RetrievalQA
query = "什么是深度学习的反向传播算法?"
query_embedding = embeddings.embed_query(query)
relevant_docs = vectorstore.similarity_search(
query, k=5, score_threshold=0.7
)
context = "\n".join([doc.page_content for doc in relevant_docs])
prompt = f"""
基于以下上下文信息回答问题:
上下文:{context}
问题:{query}
请基于上下文提供准确、详细的回答:
"""
llm = OpenAI(temperature=0.1)
response = llm(prompt)
1.3 核心组件深度解析
向量数据库:语义搜索的基石
向量数据库是RAG系统的核心基础设施,它将文本转换为高维向量空间中的点,使得语义相似的内容在空间中距离更近。
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
def calculate_similarity(query_vector, doc_vectors):
"""
计算查询向量与文档向量的余弦相似度
"""
similarities = cosine_similarity(
query_vector.reshape(1, -1),
doc_vectors
)
return similarities[0]
query_vec = np.array([0.1, 0.2, 0.3, 0.4])
doc_vecs = np.array([
[0.15, 0.25, 0.35, 0.45],
[0.8, 0.1, 0.05, 0.05],
[0.12, 0.18, 0.32, 0.38]
])
similarities = calculate_similarity(query_vec, doc_vecs)
ranked_docs = np.argsort(similarities)[::-1]
Embedding模型:语义理解的关键
Embedding模型负责将文本转换为向量表示,其质量直接影响检索效果:
from sentence_transformers import SentenceTransformer
from openai import OpenAI
class EmbeddingComparison:
def __init__(self):
self.sentence_model = SentenceTransformer(
'paraphrase-multilingual-MiniLM-L12-v2'
)
self.openai_client = OpenAI()
def get_sentence_embedding(self, text):
"""使用SentenceTransformer获取向量"""
return self.sentence_model.encode(text)
def get_openai_embedding(self, text):
"""使用OpenAI获取向量"""
response = self.openai_client.embeddings.create(
model="text-embedding-ada-002",
input=text
)
return response.data[0].embedding
def compare_embeddings(self, text1, text2):
"""比较不同模型的向量相似度"""
sent_emb1 = self.get_sentence_embedding(text1)
sent_emb2 = self.get_sentence_embedding(text2)
sent_sim = cosine_similarity([sent_emb1], [sent_emb2])[0][0]
openai_emb1 = self.get_openai_embedding(text1)
openai_emb2 = self.get_openai_embedding(text2)
openai_sim = cosine_similarity([openai_emb1], [openai_emb2])[0][0]
return {
'sentence_transformer': sent_sim,
'openai': openai_sim
}
第二章:应用场景深度剖析 - RAG技术的实战价值
2.1 企业知识管理:构建智能知识库
在企业环境中,RAG技术能够将分散的文档、手册、报告等知识资源整合成统一的智能问答系统:
class EnterpriseKnowledgeRAG:
def __init__(self):
self.document_types = {
'policy': '政策文件',
'manual': '操作手册',
'report': '分析报告',
'faq': '常见问题'
}
self.vectorstore = None
self.llm = None
def ingest_documents(self, file_paths, doc_type):
"""批量导入企业文档"""
documents = []
for file_path in file_paths:
loader = self._get_loader(file_path)
docs = loader.load()
for doc in docs:
doc.metadata.update({
'doc_type': doc_type,
'source': file_path,
'ingestion_time': datetime.now().isoformat()
})
documents.extend(docs)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=800,
chunk_overlap=100
)
splits = text_splitter.split_documents(documents)
self.vectorstore = Chroma.from_documents(
documents=splits,
embedding=OpenAIEmbeddings(),
persist_directory="./enterprise_kb"
)
def query_knowledge(self, question, doc_type_filter=None):
"""智能知识查询"""
filter_dict = {}
if doc_type_filter:
filter_dict['doc_type'] = doc_type_filter
relevant_docs = self.vectorstore.similarity_search(
question,
k=5,
filter=filter_dict
)
context = self._build_context(relevant_docs)
prompt = f"""
你是一个企业知识助手,请基于以下企业内部资料回答问题。
企业资料:
{context}
问题:{question}
请提供准确、专业的回答,并注明信息来源:
"""
response = self.llm(prompt)
return {
'answer': response,
'sources': [doc.metadata['source'] for doc in relevant_docs],
'doc_types': list(set([doc.metadata['doc_type'] for doc in relevant_docs]))
}
2.2 智能客服系统:提升服务质量与效率
RAG技术在客服领域的应用能够显著提升响应准确性和用户满意度:
class CustomerServiceRAG:
def __init__(self):
self.knowledge_base = {
'product_info': '产品信息库',
'troubleshooting': '故障排除指南',
'policy': '服务政策',
'history': '历史对话记录'
}
def handle_customer_query(self, query, customer_id=None):
"""处理客户查询"""
intent = self._classify_intent(query)
relevant_docs = self._retrieve_knowledge(query, intent)
if customer_id:
customer_context = self._get_customer_context(customer_id)
relevant_docs.extend(customer_context)
response = self._generate_response(query, relevant_docs, intent)
self._log_interaction(customer_id, query, response)
return response
def _classify_intent(self, query):
"""查询意图分类"""
intent_prompts = {
'product_inquiry': '产品咨询',
'technical_support': '技术支持',
'billing_question': '账单问题',
'complaint': '投诉建议'
}
classification_prompt = f"""
请将以下客户查询分类到合适的意图类别:
查询:{query}
可选类别:{list(intent_prompts.keys())}
只返回类别名称:
"""
intent = self.llm(classification_prompt).strip()
return intent if intent in intent_prompts else 'general'
2.3 教育培训领域:个性化学习助手
在教育场景中,RAG技术能够构建智能化的学习辅导系统:
class EducationalRAG:
def __init__(self):
self.subject_areas = {
'mathematics': '数学',
'physics': '物理',
'chemistry': '化学',
'computer_science': '计算机科学'
}
def create_personalized_explanation(self, concept, student_level, learning_style):
"""创建个性化概念解释"""
relevant_materials = self.vectorstore.similarity_search(
f"{concept} {student_level} level explanation",
k=3
)
style_prompts = {
'visual': '请用图表、图像和视觉化方式解释',
'auditory': '请用对话和声音相关的比喻解释',
'kinesthetic': '请用动手实践和身体感知的方式解释',
'reading': '请用详细的文字描述和阅读材料解释'
}
context = "\n".join([doc.page_content for doc in relevant_materials])
prompt = f"""
你是一位经验丰富的教师,请为{student_level}水平的学生解释以下概念:
概念:{concept}
学生水平:{student_level}
学习风格:{learning_style}
参考教学材料:
{context}
解释要求:{style_prompts.get(learning_style, '请用清晰易懂的方式解释')}
请提供:
1. 概念的核心定义
2. 具体例子和应用
3. 常见误区和注意事项
4. 进一步学习建议
"""
explanation = self.llm(prompt)
return explanation
第三章:技术优势与价值分析 - RAG的核心竞争力
3.1 实时性优势:动态知识更新能力
RAG技术最显著的优势之一是其实时性。与传统需要重新训练的模型不同,RAG系统可以通过更新知识库来获取最新信息:
class RealTimeKnowledgeUpdater:
def __init__(self, vectorstore):
self.vectorstore = vectorstore
self.update_queue = []
def add_new_document(self, document, metadata=None):
"""添加新文档到知识库"""
processed_doc = self._preprocess_document(document)
if metadata is None:
metadata = {}
metadata.update({
'added_time': datetime.now().isoformat(),
'version': self._get_next_version(),
'status': 'active'
})
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200
)
chunks = text_splitter.split_text(processed_doc)
for chunk in chunks:
doc_obj = Document(
page_content=chunk,
metadata=metadata
)
self.vectorstore.add_documents([doc_obj])
print(f"成功添加文档,共{len(chunks)}个片段")
def update_document(self, doc_id, new_content):
"""更新现有文档"""
self._deactivate_document(doc_id)
metadata = {
'original_doc_id': doc_id,
'update_type': 'content_revision'
}
self.add_new_document(new_content, metadata)
def remove_outdated_info(self, keywords, cutoff_date):
"""移除过时信息"""
docs = self.vectorstore.similarity_search(
" ".join(keywords),
k=100
)
outdated_docs = []
for doc in docs:
doc_date = datetime.fromisoformat(doc.metadata.get('added_time', '1970-01-01'))
if doc_date < cutoff_date:
outdated_docs.append(doc)
for doc in outdated_docs:
doc.metadata['status'] = 'inactive'
doc.metadata['deactivated_time'] = datetime.now().isoformat()
print(f"标记{len(outdated_docs)}个过时文档为非活跃状态")
3.2 可解释性优势:透明的推理过程
RAG系统的另一个重要优势是其可解释性。系统可以明确显示回答的信息来源,增强用户信任:
class ExplainableRAG:
def __init__(self, vectorstore, llm):
self.vectorstore = vectorstore
self.llm = llm
def query_with_explanation(self, question):
"""带解释的查询"""
relevant_docs = self.vectorstore.similarity_search_with_score(
question, k=5
)
retrieval_analysis = self._analyze_retrieval_results(relevant_docs)
context = "\n".join([doc.page_content for doc, score in relevant_docs])
prompt = f"""
基于以下信息回答问题,并说明你的推理过程:
上下文信息:
{context}
问题:{question}
请提供:
1. 直接回答
2. 推理过程
3. 信心度评估(1-10分)
"""
response = self.llm(prompt)
explanation = {
'answer': response,
'sources': self._format_sources(relevant_docs),
'retrieval_analysis': retrieval_analysis,
'confidence_factors': self._calculate_confidence_factors(relevant_docs)
}
return explanation
def _analyze_retrieval_results(self, docs_with_scores):
"""分析检索结果质量"""
analysis = {
'total_docs': len(docs_with_scores),
'avg_similarity': np.mean([score for _, score in docs_with_scores]),
'source_diversity': len(set([doc.metadata.get('source', 'unknown')
for doc, _ in docs_with_scores])),
'recency': self._analyze_document_recency(docs_with_scores)
}
return analysis
def _format_sources(self, docs_with_scores):
"""格式化信息源"""
sources = []
for doc, score in docs_with_scores:
source_info = {
'content_preview': doc.page_content[:200] + "...",
'similarity_score': round(score, 3),
'source': doc.metadata.get('source', '未知来源'),
'timestamp': doc.metadata.get('added_time', '未知时间')
}
sources.append(source_info)
return sources
3.3 成本效益优势:高性价比的解决方案
RAG技术相比于模型微调具有显著的成本优势:
class RAGCostAnalyzer:
def __init__(self):
self.cost_factors = {
'embedding_cost': 0.0001,
'storage_cost': 0.001,
'query_cost': 0.002,
'llm_generation_cost': 0.02
}
def calculate_setup_cost(self, document_count, avg_doc_size_kb):
"""计算初始设置成本"""
total_tokens = document_count * avg_doc_size_kb * 0.75
costs = {
'embedding_processing': total_tokens * self.cost_factors['embedding_cost'] / 1000,
'initial_storage': (total_tokens * 1536 * 4) / (1024**3) * self.cost_factors['storage_cost'],
'setup_time': document_count * 0.1
}
return costs
def calculate_operational_cost(self, monthly_queries, avg_response_tokens):
"""计算运营成本"""
monthly_costs = {
'query_processing': monthly_queries * self.cost_factors['query_cost'],
'llm_generation': monthly_queries * avg_response_tokens * self.cost_factors['llm_generation_cost'] / 1000,
'storage_maintenance': 10
}
return monthly_costs
def compare_with_fine_tuning(self, model_size_gb, training_hours):
"""与微调成本对比"""
fine_tuning_costs = {
'compute_cost': training_hours * 50,
'data_preparation': training_hours * 0.5 * 100,
'model_storage': model_size_gb * 0.1,
'deployment_cost': 200
}
return fine_tuning_costs
第四章:挑战与局限性分析 - RAG技术的现实考量
4.1 检索质量挑战:精准度与召回率的平衡
检索质量是RAG系统成功的关键,但在实际应用中面临多重挑战:
class RetrievalQualityOptimizer:
def __init__(self, vectorstore):
self.vectorstore = vectorstore
self.retrieval_metrics = {
'precision': [],
'recall': [],
'f1_score': [],
'mrr': []
}
def hybrid_search(self, query, alpha=0.7):
"""混合检索:语义搜索 + 关键词搜索"""
semantic_results = self.vectorstore.similarity_search_with_score(
query, k=10
)
keyword_results = self._bm25_search(query, k=10)
fused_results = self._fuse_results(
semantic_results,
keyword_results,
alpha
)
return fused_results[:5]
def _bm25_search(self, query, k=10):
"""BM25关键词搜索实现"""
from rank_bm25 import BM25Okapi
all_docs = self._get_all_documents()
tokenized_docs = [doc.split() for doc in all_docs]
bm25 = BM25Okapi(tokenized_docs)
query_tokens = query.split()
scores = bm25.get_scores(query_tokens)
top_indices = np.argsort(scores)[::-1][:k]
results = []
for idx in top_indices:
results.append((all_docs[idx], scores[idx]))
return results
def _fuse_results(self, semantic_results, keyword_results, alpha):
"""结果融合算法"""
semantic_scores = self._normalize_scores([score for _, score in semantic_results])
keyword_scores = self._normalize_scores([score for _, score in keyword_results])
doc_scores = {}
for i, (doc, _) in enumerate(semantic_results):
doc_id = self._get_doc_id(doc)
doc_scores[doc_id] = alpha * semantic_scores[i]
for i, (doc, _) in enumerate(keyword_results):
doc_id = self._get_doc_id(doc)
if doc_id in doc_scores:
doc_scores[doc_id] += (1 - alpha) * keyword_scores[i]
else:
doc_scores[doc_id] = (1 - alpha) * keyword_scores[i]
sorted_docs = sorted(doc_scores.items(), key=lambda x: x[1], reverse=True)
return [(self._get_doc_by_id(doc_id), score) for doc_id, score in sorted_docs]
def evaluate_retrieval_quality(self, test_queries, ground_truth):
"""评估检索质量"""
total_precision = 0
total_recall = 0
total_f1 = 0
reciprocal_ranks = []
for query, relevant_docs in zip(test_queries, ground_truth):
retrieved_docs = self.hybrid_search(query)
retrieved_ids = [self._get_doc_id(doc) for doc, _ in retrieved_docs]
relevant_ids = set(relevant_docs)
retrieved_set = set(retrieved_ids)
if len(retrieved_set) > 0:
precision = len(relevant_ids & retrieved_set) / len(retrieved_set)
else:
precision = 0
if len(relevant_ids) > 0:
recall = len(relevant_ids & retrieved_set) / len(relevant_ids)
else:
recall = 0
if precision + recall > 0:
f1 = 2 * (precision * recall) / (precision + recall)
else:
f1 = 0
for i, doc_id in enumerate(retrieved_ids):
if doc_id in relevant_ids:
reciprocal_ranks.append(1 / (i + 1))
break
else:
reciprocal_ranks.append(0)
total_precision += precision
total_recall += recall
total_f1 += f1
num_queries = len(test_queries)
avg_metrics = {
'precision': total_precision / num_queries,
'recall': total_recall / num_queries,
'f1_score': total_f1 / num_queries,
'mrr': np.mean(reciprocal_ranks)
}
return avg_metrics
4.2 上下文长度限制:信息容量的技术瓶颈
大多数LLM都有上下文长度限制,这对RAG系统的信息整合能力构成挑战:
class ContextManager:
def __init__(self, max_context_length=4000):
self.max_context_length = max_context_length
self.tokenizer = tiktoken.get_encoding("cl100k_base")
def optimize_context(self, query, retrieved_docs):
"""优化上下文以适应长度限制"""
base_prompt_tokens = self._count_tokens(
f"基于以下信息回答问题:\n\n问题:{query}\n\n请提供详细回答:"
)
available_tokens = self.max_context_length - base_prompt_tokens - 500
scored_docs = self._score_document_importance(query, retrieved_docs)
selected_docs = []
current_tokens = 0
for doc, score in scored_docs:
doc_tokens = self._count_tokens(doc.page_content)
if current_tokens + doc_tokens <= available_tokens:
selected_docs.append(doc)
current_tokens += doc_tokens
else:
remaining_tokens = available_tokens - current_tokens
if remaining_tokens > 100:
truncated_content = self._truncate_document(
doc.page_content, remaining_tokens
)
truncated_doc = Document(
page_content=truncated_content,
metadata=doc.metadata
)
selected_docs.append(truncated_doc)
break
return selected_docs
def _score_document_importance(self, query, docs):
"""文档重要性评分"""
scored_docs = []
for doc in docs:
similarity_score = self._calculate_similarity(query, doc.page_content)
recency_score = self._calculate_recency_score(doc.metadata)
authority_score = self._calculate_authority_score(doc.metadata)
total_score = (
0.5 * similarity_score +
0.3 * recency_score +
0.2 * authority_score
)
scored_docs.append((doc, total_score))
return sorted(scored_docs, key=lambda x: x[1], reverse=True)
def _truncate_document(self, content, max_tokens):
"""智能文档截断"""
tokens = self.tokenizer.encode(content)
if len(tokens) <= max_tokens:
return content
sentences = content.split('。')
truncated_content = ""
current_tokens = 0
for sentence in sentences:
sentence_tokens = len(self.tokenizer.encode(sentence + '。'))
if current_tokens + sentence_tokens <= max_tokens:
truncated_content += sentence + '。'
current_tokens += sentence_tokens
else:
break
if not truncated_content:
truncated_tokens = tokens[:max_tokens-10]
truncated_content = self.tokenizer.decode(truncated_tokens) + "..."
return truncated_content
4.3 多模态处理挑战:超越文本的信息整合
现代RAG系统需要处理图像、音频、视频等多模态数据,这带来了新的技术挑战:
class MultiModalRAG:
def __init__(self):
self.text_embedder = OpenAIEmbeddings()
self.image_embedder = self._init_image_embedder()
self.audio_embedder = self._init_audio_embedder()
self.multimodal_vectorstore = None
def _init_image_embedder(self):
"""初始化图像编码器"""
from transformers import CLIPProcessor, CLIPModel
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
return {'model': model, 'processor': processor}
def _init_audio_embedder(self):
"""初始化音频编码器"""
from transformers import Wav2Vec2Processor, Wav2Vec2Model
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-base-960h")
model = Wav2Vec2Model.from_pretrained("facebook/wav2vec2-base-960h")
return {'model': model, 'processor': processor}
def process_multimodal_document(self, file_path, doc_type):
"""处理多模态文档"""
if doc_type == 'image':
return self._process_image_document(file_path)
elif doc_type == 'audio':
return self._process_audio_document(file_path)
elif doc_type == 'video':
return self._process_video_document(file_path)
else:
return self._process_text_document(file_path)
def _process_image_document(self, image_path):
"""处理图像文档"""
from PIL import Image
import torch
image = Image.open(image_path)
description = self._generate_image_description(image)
inputs = self.image_embedder['processor'](images=image, return_tensors="pt")
with torch.no_grad():
image_features = self.image_embedder['model'].get_image_features(**inputs)
multimodal_doc = {
'content_type': 'image',
'file_path': image_path,
'description': description,
'text_embedding': self.text_embedder.embed_query(description),
'image_embedding': image_features.numpy().flatten(),
'metadata': {
'source': image_path,
'type': 'image',
'processed_time': datetime.now().isoformat()
}
}
return multimodal_doc
def _process_audio_document(self, audio_path):
"""处理音频文档"""
import librosa
import torch
audio, sr = librosa.load(audio_path, sr=16000)
transcript = self._speech_to_text(audio, sr)
inputs = self.audio_embedder['processor'](
audio, sampling_rate=sr, return_tensors="pt"
)
with torch.no_grad():
audio_features = self.audio_embedder['model'](**inputs).last_hidden_state
audio_embedding = torch.mean(audio_features, dim=1).numpy().flatten()
multimodal_doc = {
'content_type': 'audio',
'file_path': audio_path,
'transcript': transcript,
'text_embedding': self.text_embedder.embed_query(transcript),
'audio_embedding': audio_embedding,
'metadata': {
'source': audio_path,
'type': 'audio',
'duration': len(audio) / sr,
'processed_time': datetime.now().isoformat()
}
}
return multimodal_doc
def multimodal_search(self, query, query_type='text', k=5):
"""多模态搜索"""
if query_type == 'text':
query_embedding = self.text_embedder.embed_query(query)
results = self._search_in_embedding_space(
query_embedding, 'text_embedding', k
)
elif query_type == 'image':
query_embedding = self._encode_image_query(query)
results = self._search_in_embedding_space(
query_embedding, 'image_embedding', k
)
elif query_type == 'audio':
query_embedding = self._encode_audio_query(query)
results = self._search_in_embedding_space(
query_embedding, 'audio_embedding', k
)
return results
def _generate_image_description(self, image):
"""生成图像描述"""
return "这是一张包含多个对象的图像"
def _speech_to_text(self, audio, sr):
"""语音转文本"""
return "这是音频的转录文本"
第五章:未来发展展望 - RAG技术的演进方向
5.1 自适应RAG:智能化的检索策略
未来的RAG系统将具备自适应能力,能够根据查询类型和上下文动态调整检索策略:
class AdaptiveRAG:
def __init__(self):
self.query_classifier = self._init_query_classifier()
self.retrieval_strategies = {
'factual': self._factual_retrieval,
'analytical': self._analytical_retrieval,
'creative': self._creative_retrieval,
'comparative': self._comparative_retrieval
}
self.performance_tracker = {}
def adaptive_query(self, query, user_context=None):
"""自适应查询处理"""
query_type = self._classify_query(query)
user_profile = self._analyze_user_profile(user_context)
strategy = self._select_optimal_strategy(query_type, user_profile)
retrieved_docs = strategy(query, user_profile)
optimized_context = self._optimize_context_dynamically(
query, retrieved_docs, query_type
)
response = self._generate_adaptive_response(
query, optimized_context, query_type, user_profile
)
self._track_performance(query_type, strategy.__name__, response)
return response
def _classify_query(self, query):
"""查询类型分类"""
classification_prompt = f"""
请将以下查询分类到最合适的类型:
查询:{query}
类型选项:
- factual: 事实性查询,需要准确的信息
- analytical: 分析性查询,需要深度思考
- creative: 创造性查询,需要灵感和想象
- comparative: 比较性查询,需要对比分析
只返回类型名称:
"""
query_type = self.query_classifier(classification_prompt).strip().lower()
return query_type if query_type in self.retrieval_strategies else 'factual'
def _factual_retrieval(self, query, user_profile):
"""事实性检索策略"""
return self.vectorstore.similarity_search(
query,
k=3,
filter={'authority_score': {'$gte': 0.8}}
)
def _analytical_retrieval(self, query, user_profile):
"""分析性检索策略"""
diverse_results = []
main_results = self.vectorstore.similarity_search(query, k=3)
diverse_results.extend(main_results)
counter_query = f"反对 {query} 的观点"
counter_results = self.vectorstore.similarity_search(counter_query, k=2)
diverse_results.extend(counter_results)
return diverse_results
def _creative_retrieval(self, query, user_profile):
"""创造性检索策略"""
expanded_queries = self._generate_creative_queries(query)
all_results = []
for expanded_query in expanded_queries:
results = self.vectorstore.similarity_search(expanded_query, k=2)
all_results.extend(results)
return all_results[:5]
def _select_optimal_strategy(self, query_type, user_profile):
"""选择最优检索策略"""
if query_type in self.performance_tracker:
best_strategy = max(
self.performance_tracker[query_type].items(),
key=lambda x: x[1]['avg_satisfaction']
)[0]
return self.retrieval_strategies[best_strategy]
return self.retrieval_strategies[query_type]
5.2 RAG + Agent架构:智能化的任务执行
结合Agent技术的RAG系统将具备更强的任务执行能力:
class RAGAgent:
def __init__(self):
self.tools = {
'search': self._search_tool,
'calculate': self._calculate_tool,
'visualize': self._visualize_tool,
'summarize': self._summarize_tool
}
self.memory = []
self.vectorstore = None
self.llm = None
def execute_complex_task(self, task_description):
"""执行复杂任务"""
subtasks = self._decompose_task(task_description)
execution_plan = self._generate_execution_plan(subtasks)
results = []
for step in execution_plan:
step_result = self._execute_step(step)
results.append(step_result)
self.memory.append({
'step': step,
'result': step_result,
'timestamp': datetime.now().isoformat()
})
final_result = self._integrate_results(results, task_description)
return final_result
def _decompose_task(self, task):
"""任务分解"""
decomposition_prompt = f"""
请将以下复杂任务分解为具体的子任务:
任务:{task}
请按照逻辑顺序列出子任务,每个子任务应该是具体可执行的:
"""
response = self.llm(decomposition_prompt)
subtasks = [line.strip() for line in response.split('\n') if line.strip()]
return subtasks
def _execute_step(self, step):
"""执行单个步骤"""
required_tools = self._identify_required_tools(step)
relevant_info = self._retrieve_step_info(step)
tool_results = {}
for tool_name in required_tools:
if tool_name in self.tools:
tool_result = self.tools[tool_name](step, relevant_info)
tool_results[tool_name] = tool_result
step_result = self._generate_step_result(step, relevant_info, tool_results)
return step_result
def _search_tool(self, query, context):
"""搜索工具"""
enhanced_query = f"{query} {' '.join([mem['result'][:100] for mem in self.memory[-3:]])}"
results = self.vectorstore.similarity_search(enhanced_query, k=5)
return [doc.page_content for doc in results]
def _calculate_tool(self, expression, context):
"""计算工具"""
try:
math_expr = self._extract_math_expression(expression)
result = eval(math_expr)
return f"计算结果:{result}"
except Exception as e:
return f"计算错误:{str(e)}"
def _visualize_tool(self, data_description, context):
"""可视化工具"""
viz_code = self._generate_visualization_code(data_description, context)
return f"可视化代码:\n{viz_code}"
def _summarize_tool(self, content, context):
"""摘要工具"""
summary_prompt = f"""
请对以下内容进行摘要:
内容:{content}
上下文:{context}
请提供简洁而全面的摘要:
"""
summary = self.llm(summary_prompt)
return summary
第六章:实践指南 - 构建生产级RAG系统
6.1 系统架构设计:可扩展的技术方案
构建生产级RAG系统需要考虑可扩展性、可靠性和性能等多个维度:
class ProductionRAGSystem:
def __init__(self, config):
self.config = config
self.document_processor = DocumentProcessor()
self.vector_store = self._init_vector_store()
self.llm_client = self._init_llm_client()
self.cache = self._init_cache()
self.monitoring = self._init_monitoring()
def _init_vector_store(self):
"""初始化向量数据库"""
if self.config['vector_store']['type'] == 'pinecone':
import pinecone
pinecone.init(
api_key=self.config['vector_store']['api_key'],
environment=self.config['vector_store']['environment']
)
return pinecone.Index(self.config['vector_store']['index_name'])
elif self.config['vector_store']['type'] == 'weaviate':
import weaviate
return weaviate.Client(
url=self.config['vector_store']['url'],
auth_client_secret=weaviate.AuthApiKey(
api_key=self.config['vector_store']['api_key']
)
)
else:
return Chroma(
persist_directory=self.config['vector_store']['persist_directory']
)
def _init_cache(self):
"""初始化缓存系统"""
import redis
return redis.Redis(
host=self.config['cache']['host'],
port=self.config['cache']['port'],
db=self.config['cache']['db']
)
def _init_monitoring(self):
"""初始化监控系统"""
from prometheus_client import Counter, Histogram, Gauge
return {
'query_counter': Counter('rag_queries_total', 'Total RAG queries'),
'response_time': Histogram('rag_response_time_seconds', 'RAG response time'),
'cache_hit_rate': Gauge('rag_cache_hit_rate', 'Cache hit rate'),
'error_counter': Counter('rag_errors_total', 'Total RAG errors', ['error_type'])
}
async def process_query(self, query, user_id=None):
"""异步查询处理"""
start_time = time.time()
try:
processed_query = await self._preprocess_query(query)
cache_key = self._generate_cache_key(processed_query, user_id)
cached_result = await self._check_cache(cache_key)
if cached_result:
self.monitoring['cache_hit_rate'].inc()
return cached_result
relevant_docs = await self._retrieve_documents(processed_query)
optimized_context = await self._optimize_context(
processed_query, relevant_docs
)
response = await self._generate_response(
processed_query, optimized_context
)
final_response = await self._postprocess_response(response)
await self._cache_result(cache_key, final_response)
response_time = time.time() - start_time
self.monitoring['query_counter'].inc()
self.monitoring['response_time'].observe(response_time)
return final_response
except Exception as e:
self.monitoring['error_counter'].labels(error_type=type(e).__name__).inc()
raise
async def _retrieve_documents(self, query):
"""异步文档检索"""
tasks = [
self._semantic_search(query),
self._keyword_search(query),
self._hybrid_search(query)
]
results = await asyncio.gather(*tasks)
all_docs = []
for result_set in results:
all_docs.extend(result_set)
unique_docs = self._deduplicate_documents(all_docs)
ranked_docs = self._rank_documents(query, unique_docs)
return ranked_docs[:self.config['retrieval']['max_docs']]
def _deduplicate_documents(self, documents):
"""文档去重"""
seen_content = set()
unique_docs = []
for doc in documents:
content_hash = hashlib.md5(doc.page_content.encode()).hexdigest()
if content_hash not in seen_content:
seen_content.add(content_hash)
unique_docs.append(doc)
return unique_docs
生产环境中的RAG系统需要在保证准确性的同时优化响应速度:
```python
class RAGPerformanceOptimizer:
def __init__(self):
self.query_cache = LRUCache(maxsize=1000)
self.embedding_cache = LRUCache(maxsize=5000)
self.connection_pool = self._init_connection_pool()
def _init_connection_pool(self):
"""初始化连接池"""
import aiohttp
connector = aiohttp.TCPConnector(
limit=100,
limit_per_host=30,
ttl_dns_cache=300,
use_dns_cache=True
)
return aiohttp.ClientSession(connector=connector)
async def batch_embedding_generation(self, texts):
"""批量生成嵌入向量"""
cached_embeddings = {}
uncached_texts = []
for text in texts:
text_hash = hashlib.md5(text.encode()).hexdigest()
if text_hash in self.embedding_cache:
cached_embeddings[text] = self.embedding_cache[text_hash]
else:
uncached_texts.append(text)
if uncached_texts:
batch_embeddings = await self._generate_embeddings_batch(uncached_texts)
for text, embedding in zip(uncached_texts, batch_embeddings):
text_hash = hashlib.md5(text.encode()).hexdigest()
self.embedding_cache[text_hash] = embedding
cached_embeddings[text] = embedding
return [cached_embeddings[text] for text in texts]
async def parallel_document_processing(self, documents):
"""并行文档处理"""
batch_size = 50
batches = [documents[i:i+batch_size] for i in range(0, len(documents), batch_size)]
tasks = [self._process_document_batch(batch) for batch in batches]
results = await asyncio.gather(*tasks)
processed_docs = []
for batch_result in results:
processed_docs.extend(batch_result)
return processed_docs
def implement_query_optimization(self, query):
"""查询优化"""
optimizations = {
'query_expansion': self._expand_query(query),
'query_rewriting': self._rewrite_query(query),
'intent_detection': self._detect_intent(query)
}
return optimizations
def _expand_query(self, query):
"""查询扩展"""
expansion_prompt = f"""
为以下查询生成3-5个相关的同义词或相关词:
查询:{query}
请只返回词汇,用逗号分隔:
"""
expanded_terms = self.llm(expansion_prompt).strip().split(',')
return [term.strip() for term in expanded_terms]
6.2 质量保证与监控:确保系统稳定性
class RAGQualityMonitor:
def __init__(self):
self.metrics_collector = MetricsCollector()
self.alert_manager = AlertManager()
self.quality_thresholds = {
'response_time': 2.0,
'accuracy_score': 0.85,
'user_satisfaction': 0.8,
'cache_hit_rate': 0.6
}
def monitor_system_health(self):
"""系统健康监控"""
health_metrics = {
'vector_store_status': self._check_vector_store_health(),
'llm_service_status': self._check_llm_service_health(),
'cache_status': self._check_cache_health(),
'memory_usage': self._get_memory_usage(),
'cpu_usage': self._get_cpu_usage()
}
for metric, value in health_metrics.items():
if self._should_alert(metric, value):
self.alert_manager.send_alert(metric, value)
return health_metrics
def evaluate_response_quality(self, query, response, retrieved_docs):
"""评估响应质量"""
quality_scores = {
'relevance': self._calculate_relevance_score(query, response),
'completeness': self._calculate_completeness_score(query, response),
'accuracy': self._calculate_accuracy_score(response, retrieved_docs),
'coherence': self._calculate_coherence_score(response)
}
overall_score = np.mean(list(quality_scores.values()))
self.metrics_collector.record_quality_metrics(quality_scores)
return overall_score, quality_scores
结语:RAG技术的价值与未来
通过本文的深度解析,我们全面探讨了RAG技术从基础原理到实际应用的各个层面。作为连接传统信息检索与现代生成式AI的桥梁,RAG技术正在重新定义人工智能与知识的交互方式。
技术价值总结
RAG技术的核心价值体现在四个方面:
- 知识时效性:通过动态检索机制,RAG系统能够获取最新信息,解决了传统模型知识滞后的问题
- 准确性提升:基于事实的生成过程显著减少了AI幻觉现象,提高了回答的可信度
- 成本效益:相比模型微调,RAG提供了更经济的知识更新方案
- 透明可控:清晰的检索-生成流程使得系统行为更加可解释和可控制
未来发展展望
展望未来,RAG技术将在以下几个方向持续演进:
技术融合趋势:RAG将与多模态AI、强化学习、知识图谱等技术深度融合,形成更加智能化的知识处理系统。5
应用场景扩展:从当前的问答系统扩展到创意写作、科学研究、决策支持等更广泛的领域。
性能优化突破:随着硬件技术和算法优化的发展,RAG系统的响应速度和处理能力将得到显著提升。
思考与讨论
在RAG技术快速发展的同时,我们也需要思考一些深层次的问题:
- 数据质量与偏见:如何确保检索到的信息质量,避免偏见信息的传播?
- 隐私与安全:在处理敏感信息时,如何平衡功能性与隐私保护?
- 人机协作:RAG系统应该如何与人类专家协作,而不是简单替代?
这些问题的解答将直接影响RAG技术的健康发展和广泛应用。
互动环节
作为读者,您可以思考以下问题:
- 在您的工作或学习领域,RAG技术可能带来哪些具体的改进?
- 您认为RAG技术面临的最大挑战是什么?
- 如何评估一个RAG系统的成功程度?
欢迎在评论区分享您的见解和经验,让我们共同探讨RAG技术的无限可能。
推荐阅读
核心论文文献:
- Lewis, P., et al. (2020). "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks." arXiv preprint arXiv:2005.11401.
- Karpukhin, V., et al. (2020). "Dense Passage Retrieval for Open-Domain Question Answering." EMNLP 2020.
- Izacard, G., & Grave, E. (2021). "Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering." EACL 2021.
开源项目推荐:
- LangChain (https://github.com/langchain-ai/langchain) - 构建RAG应用的综合框架
- LlamaIndex (https://github.com/run-llama/llama_index) - 专注于数据连接的RAG框架
- Haystack (https://github.com/deepset-ai/haystack) - 端到端的NLP框架,支持RAG
- ChromaDB (https://github.com/chroma-core/chroma) - 开源向量数据库
- FAISS (https://github.com/facebookresearch/faiss) - Facebook开源的相似性搜索库
技术博客与资源:
- Pinecone Learning Center - RAG技术深度教程
- Weaviate Blog - 向量数据库与RAG实践
- OpenAI Cookbook - RAG应用开发指南


