
2025年值得关注的9款开源大模型


生成式AI的浪潮离不开底层的大语言模型,以ChatGPT 和Gemini为代表的专有模型,其底层技术被少数科技巨头掌控。
敏感数据存在泄露风险、长期使用成本过高,还受制于厂商更新节奏。
开源模型应运而生,并以惊人的速度崛起。开源模型更加自由(包括查看代码、调整模型),允许你修改训练、微调、参数、上下文窗口等,以适配你特定领域(如法律、医药、技术文档)或特定任务(如生成报告、做交互式助手)。
虽然运行LLM仍需基础设施(如云服务或高性能硬件)的投入,但长期来看,能显著降低软件授权成本,对中小型企业极具新引力。
下面我给出9款模型,每款包含技术亮点和应用场景解释。由于资料多为早期公开、可能存在版本迭代,以下为目前可查的方向性特征,不是绝对最终。
一、GLM‑4.6
GLM 4.6 作为新一代大模型,专为强化 Agentic 工作流、强大的编码辅助和高级推理而设计。
它将上下文窗口从 128K 扩展至 200K,在 Agentic 任务和编码性能上均有显著提升,在八大公共基准测试中,表现全面超越 GLM-4.5 和 DeepSeek-V3.1。
应用场景:适合需要处理长文档或多轮交互的系统,比如法律合规审查、客户支持多轮对话、代码生成+调试流程。
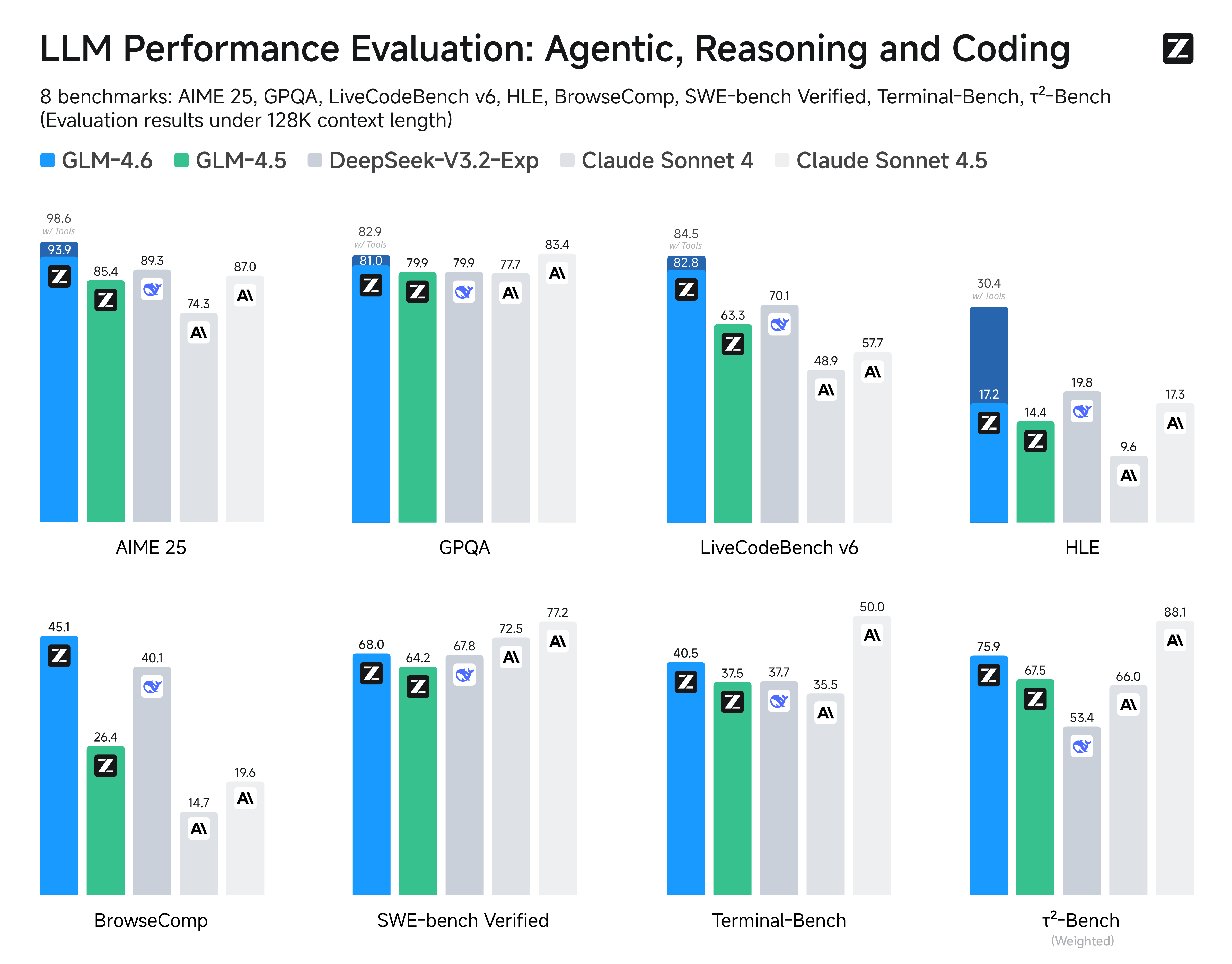
图片来源:https://huggingface.co/zai-org/GLM-4.6
二、gpt‑oss‑120B
这是OpenAI gpt-oss系列的巅峰之作,专为需要高水平推理能力的生产级通用用例而设计。它
实现了MoE权重MXFP4量化,使得这款1170亿参数的模型(51 亿激活参数)能在单张 80GB GPU 上运行,极大地降低了部署门槛。
它还提供可配置的推理深度和完整的思维链访问权限,内置函数调用、网页浏览等Agentic能力。
应用场景:适合企业内部部署、对推理能力要求高、且希望自主控制的场景,例如内部知识问答、自动化助手、调试环境。
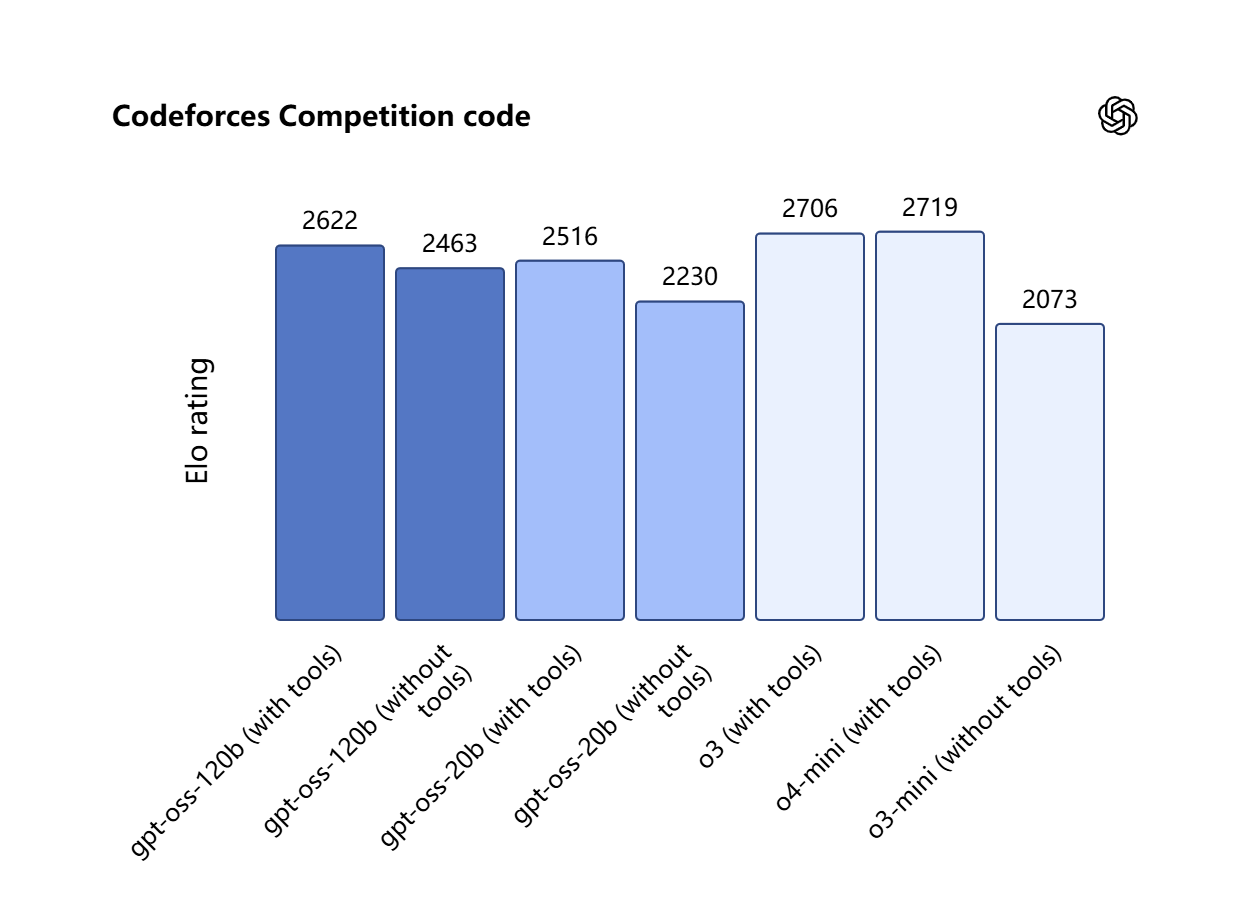
图片来源:https://openai.com/zh-Hans-CN/index/introducing-gpt-oss/
三、Qwen3‑235B‑Instruct‑2507
作为Qwen3-MoE家族的旗舰非思考模型,它拥有 2350 亿总参数和 220 亿激活参数,其原生上下文窗口达 262,000 token,可扩展至约 1.01M token。
最新的Instruct-2507更新,使其在高精度指令遵循、逻辑推理、多语言理解以及超过 256K 的长上下文理解方面表现卓越,在基准测试中超越 DeepSeek-V3、GPT-4o 和 Claude Opus 4 等顶级竞争者。
应用场景:适合跨语言支持、长上下文理解、国际化产品、写作助手、技术文档生成、翻译+理解任务。
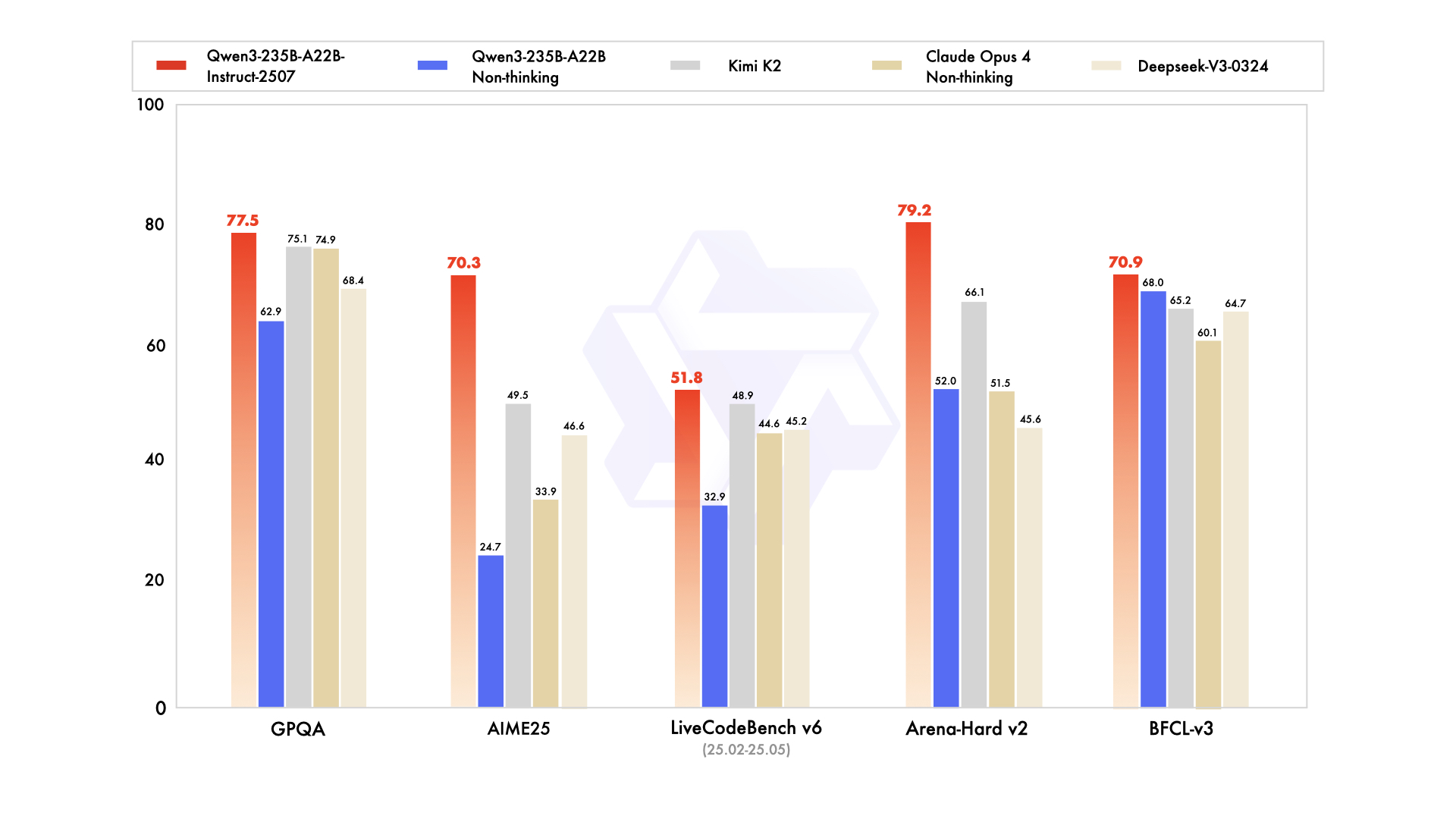
图片来源:https://huggingface.co/Qwen/Qwen3-235B-A22B-Instruct-2507
四、DeepSeek‑V3.2‑Exp
这是一个实验性的中间版本,引入了DeepSeek稀疏注意力机制,旨在提高训练和推理效率,特别是在长上下文场景中。
它在保持V3.1性能水准的同时,显著降低了计算成本,证明了稀疏注意力在不牺牲质量的前提下提升效率的可能性。
应用场景:适合资源受限但希望处理长文本的环境,如研究分析、长报告生成、档案文本梳理。
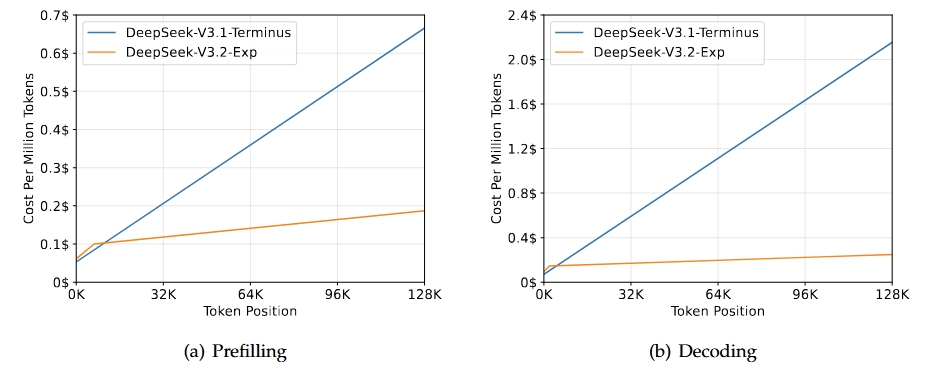
图片来源:https://huggingface.co/deepseek-ai/DeepSeek-V3.2-Exp
五、DeepSeek‑R1‑0528
DeepSeek-R1的这次升级通过算法优化和计算增强,在推理和推断能力上实现了重大突破。
尤其在复杂推理方面提升显著,例如在AIME 2025考试中的准确率从70%提升至87.5%,分析深度翻倍。
它在数学、编程(LiveCodeBench, Codeforces)和逻辑推理等领域,表现更接近O3和Gemini 2.5 Pro等领先系统。
应用场景:适合需要“思考”的AI应用,例如科学研究助手、高难度问题解答、代码生成与验证。
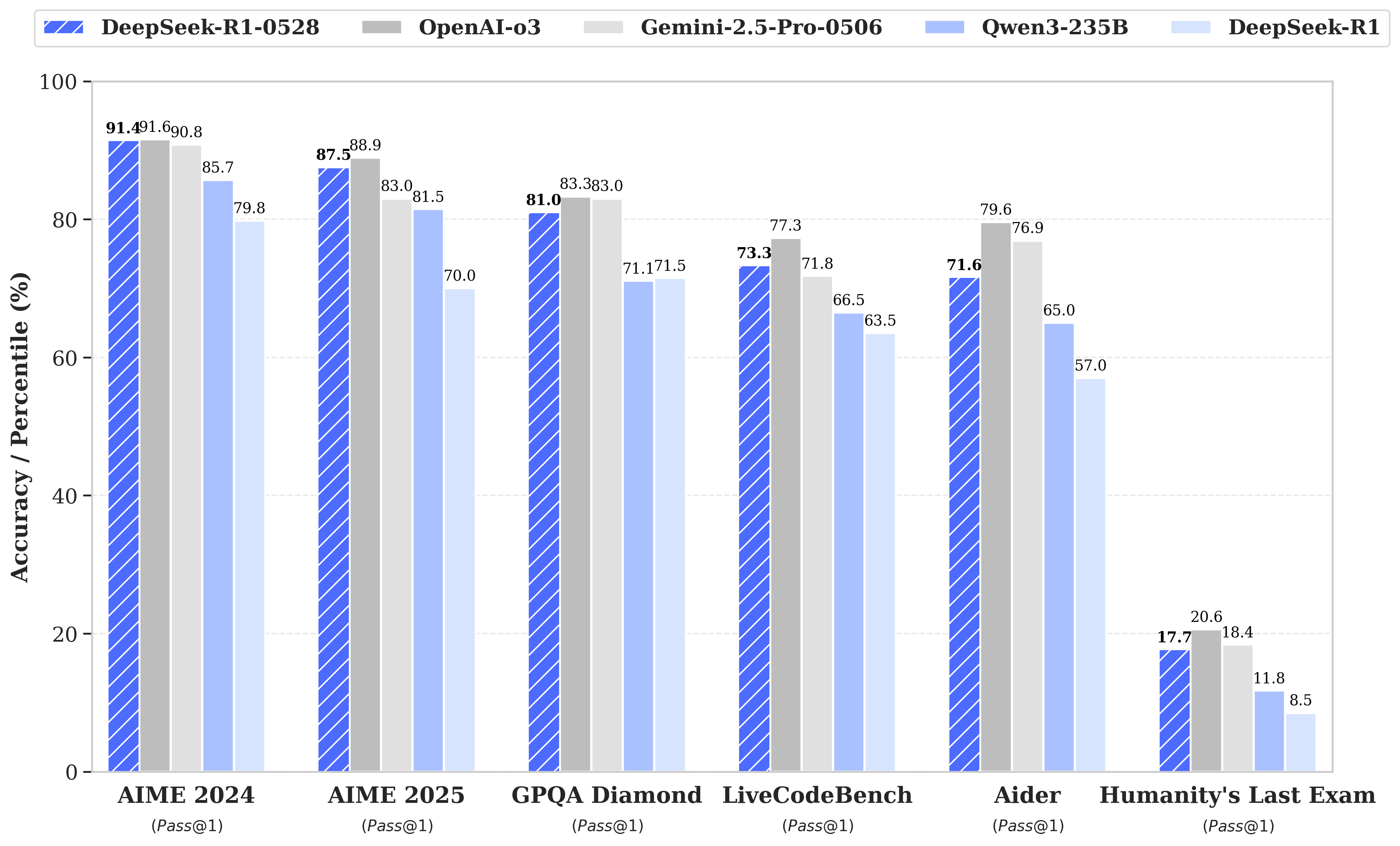
图片来源:https://huggingface.co/deepseek-ai/DeepSeek-R1-0528
六、Apriel‑1.5‑15B‑Thinker
作为ServiceNow Apriel SLM系列中的多模态推理模型,它以仅150亿参数的紧凑尺寸,致力于在单GPU预算下实现前沿级别的文本和图像推理结果。
它通过跨文本和图像域的广泛持续预训练,在保持小模型足迹的同时,展示出强大的企业级应用潜力。
应用场景:适合中型企业或项目,需要支持图像理解+文本生成场景,如视觉客服、图文说明自动生成、社交媒体内容生产。
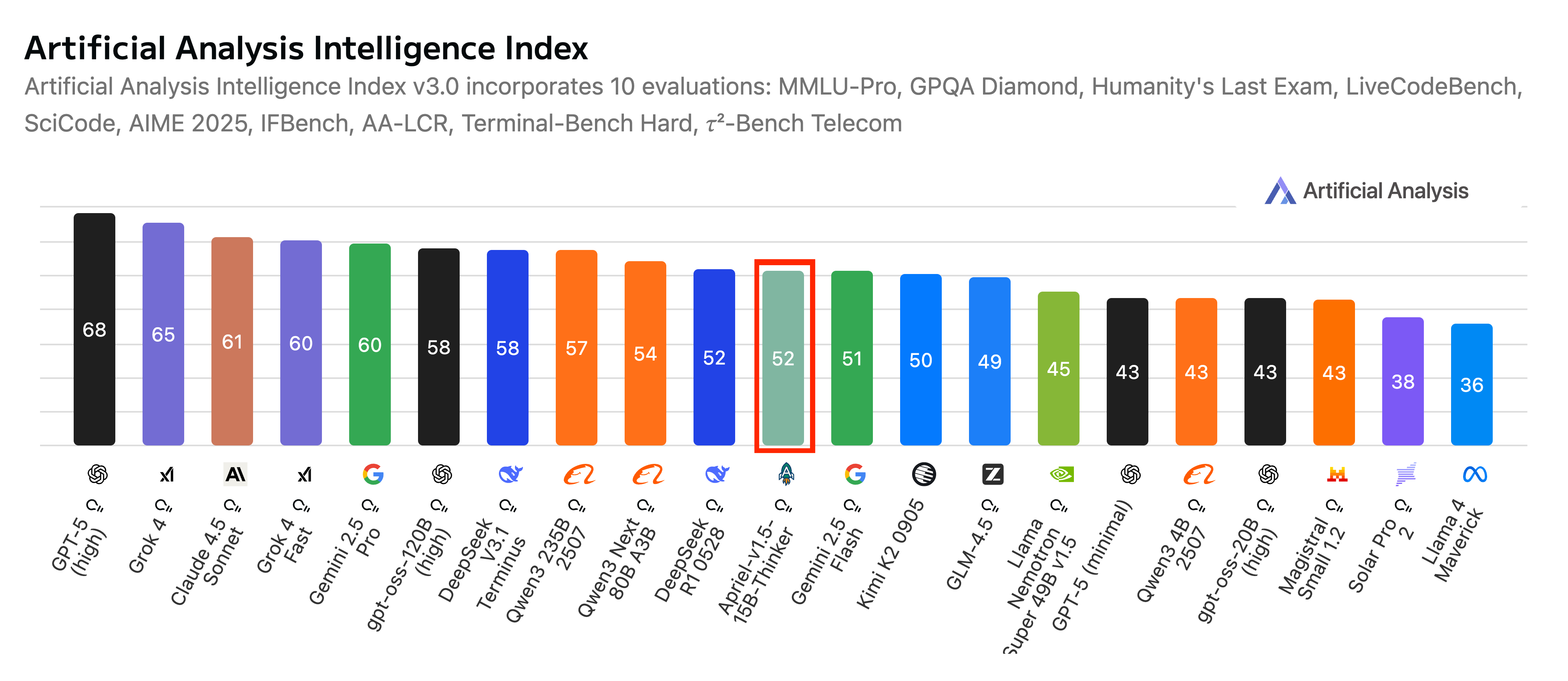
图片来源:https://huggingface.co/ServiceNow-AI/Apriel-1.5-15b-Thinker
七、Kimi‑K2‑Instruct‑0905
Kimi-K2-Instruct-0905是一款先进的MoE模型,拥有1万亿总参数和320亿激活参数。
它专为高端推理和编码工作流设计,上下文窗口扩展至惊人的256,000token,是支持工具增强型聊天和长期Agentic任务的旗舰级模型。
应用场景:高度复杂的产品:比如自动化编程助手、持续多轮任务交互、软件开发中“从需求到生成再调试”的全过程。
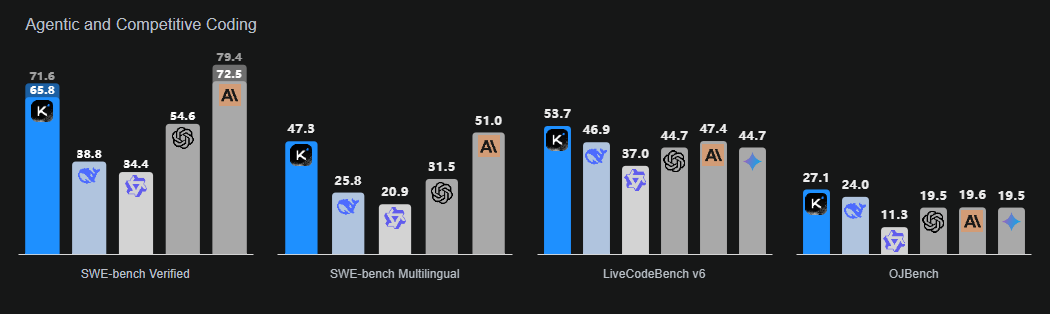
图片来源:https://moonshotai.github.io/Kimi-K2/
八、Llama‑3.3‑Nemotron‑Super‑49B‑v1.5
这是NVIDIA 基于Meta Llama-3.3-70B-Instruct 衍生出的 490 亿参数模型。
它经过专门调优,强化了推理能力、偏好对齐和工具使用,支持高达128,000 token 的长上下文工作流,是开发者进行RAG(检索增强生成)和复杂多步应用开发的平衡且高效的解决方案。
应用场景:适合需要平衡成与性能的团队,如果你想部署强推理能力但又不想用200 B以上的重量级模型,这款是不错选择,用于检索增强生成 (RAG)、智能客服、知识库问答等。
比喻:像是“中型旗舰”模式:比入门款强很多,但比超大型模型轻很多,适合多数企业用。
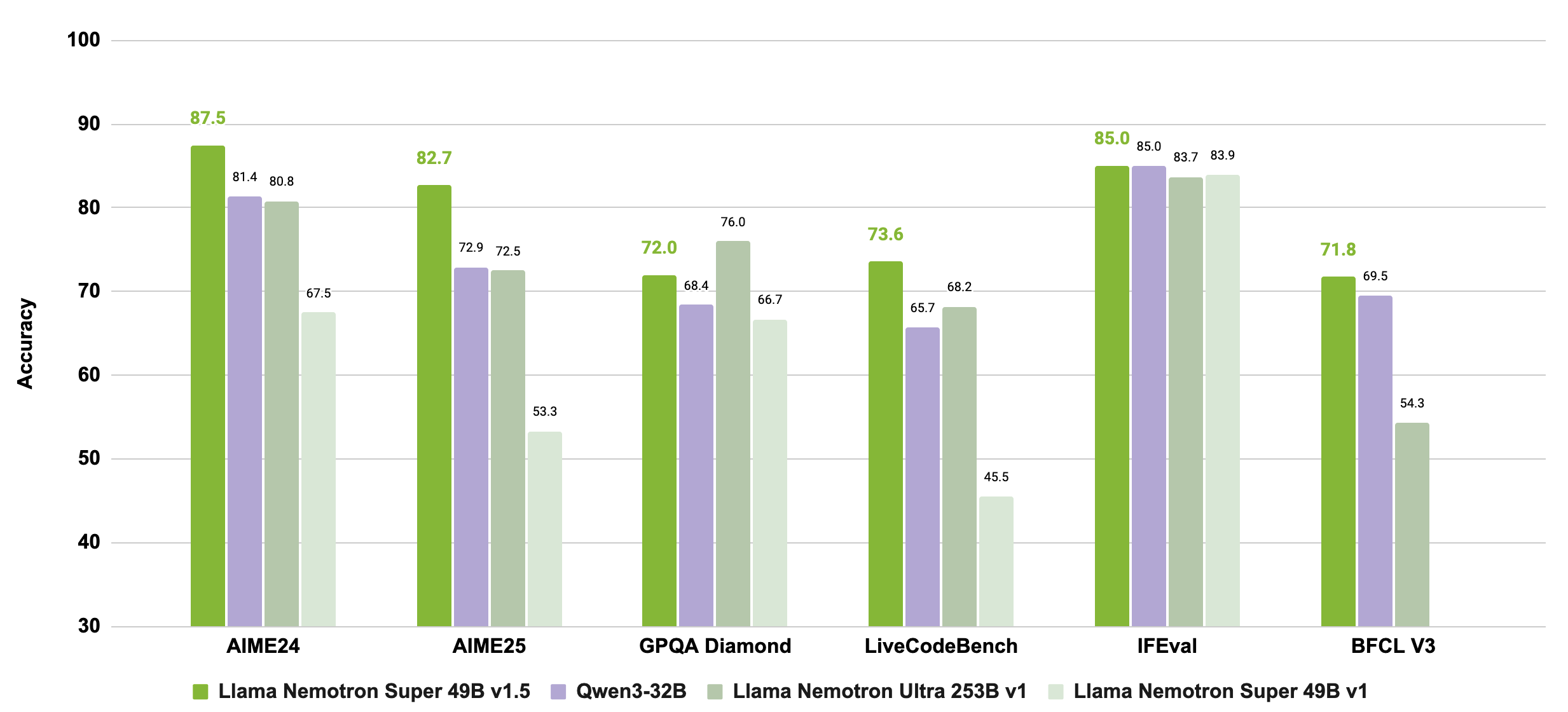
图片链接:https://huggingface.co/nvidia/Llama-3_3-Nemotron-Super-49B-v1_5
九、Mistral‑Small‑3.2‑24B‑Instruct‑2506
作为对Mistral-Small-3.1-24B-Instruct-2503的重大升级,这款 240 亿参数模型在保持核心能力的同时,显著提升了指令遵循能力(Wildbench v2 和 Arena Hard v2 上大幅增益),并将最具挑战性提示下的重复失败率减少了一半,提供了更可靠的函数调用模板和更一致的助理质量。
应用场景:适合中小型团队、产品较为标准化、对生成稳定性要求较高的场景,如客服机器人、内容生成、自动化报告等。
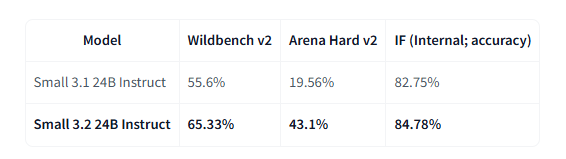
图片来源:https://huggingface.co/mistralai/Mistral-Small-3.2-24B-Instruct-2506
这些模型如何选择
既然有这么多选项,究竟哪个适合自己团队/项目呢?
看你想做什么任务,是内容生成、翻译、客服、编码辅助、知识库问答还是图文生成。每个任务对模型「能力」「上下文窗口」「多模态支持」「语言支持」的要求不同。
模型越大、越能力强,但部署成本(GPU 内存、推理延迟、能源)也越高。
对于内容生产型团队,可能用24 B或49 B模型就够了;如果是高级研究或编码辅助,可能要100 B+模型。
如果你的工作涉及长文档理解、多轮对话、电子档案阅读,那需要模型支持较长上下文(如 128K、200K token),例如GLM-4.6、Kimi-K2。
如果你面向中文、英文以外多语言用户,或者希望图像+文本混合,那要选支持这些特性的模型(如 Apriel 支持图像、Qwen3 多语言)。
如果资源有限,可以优先考虑轻量级但性能不错的模型,比如 Mistral-Small,或者考虑模型量化、稀疏注意力版本。
虽然叫开源,但部分模型在商业使用上有附加条款。
务必检查许可证(Apache 2.0、MIT、OpenRAIL 等),是否允许你当前的用途,确认是否可以微调、是否需要署名、是否限制某些用途。
总结
2025年的开源大语言模型生态已经非常丰富,从巨规模(数百B参数、长期上下文)到轻量模型,从文字专精到图文混合,从通用助手到编码专家,选择多样。
关键在于理解自己的需求、理解模型特性、搭配好基础设施、训练好团队能力。
选对模型,不只是最新最大那么简单,而是和你团队、任务模式、资源环境最匹配的那个。
