
零基础学AI大模型之Stream流式输出实战


前情摘要:
8、零基础学AI大模型之LangChain六大核心模块与大模型IO交互链
10、零基础学AI大模型之LangChain-PromptTemplate
11、零基础学AI大模型之ChatModel聊天模型与ChatPromptTemplate实战
12、零基础学AI大模型之LangChain聊天模型多案例实战
零基础学AI大模型之Stream流式输出实战
在之前的LangChain实战中,我们调用大模型时都是「一次性获取完整结果」——比如生成一篇文案、回答一个问题,需要等模型把所有内容生成完才返回。但在实际场景中(如ChatGPT聊天界面、长文本生成),这种方式会让用户面对“空白加载页”等待几秒甚至更久,体验大打折扣。
本文将聚焦LLM的Stream流式输出,从核心原理讲起,通过“故事小助手”“科普助手”两个实战案例,带你掌握从基础调用到LCEL表达式的流式落地,最后分析流式输出的优劣势与实战注意事项。
1. 为什么需要流式输出?先搞懂“一次性输出”的痛点
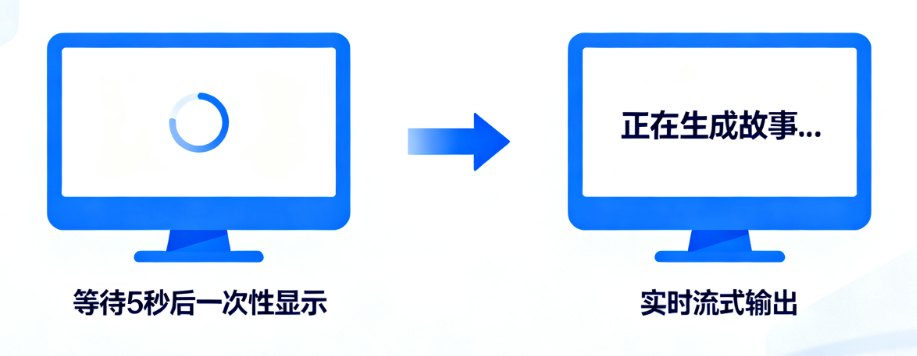
在学习流式输出前,我们先明确:流式输出不是“让模型生成更快”,而是“让用户感知更快”。
先看“一次性输出”的典型问题:
- 体验割裂:生成1000字的文章需要5秒,这5秒内用户看不到任何内容,容易误以为“程序卡住了”;
- 内存压力大:如果生成超长文本(如万字报告),一次性加载完整结果会占用更多内存,甚至导致前端页面卡顿;
- 无法中断:一旦触发生成,必须等完整结果返回才能停止,若用户不想看了也无法中途取消。
而流式输出的解决思路很简单:模型生成一个字/一个短句,就立刻返回一个“片段(Chunk)”,前端实时拼接展示——就像与人对话时“边说边听”,而非“等对方说完一长段再回应”。
2. 流式输出核心原理:什么是Stream?
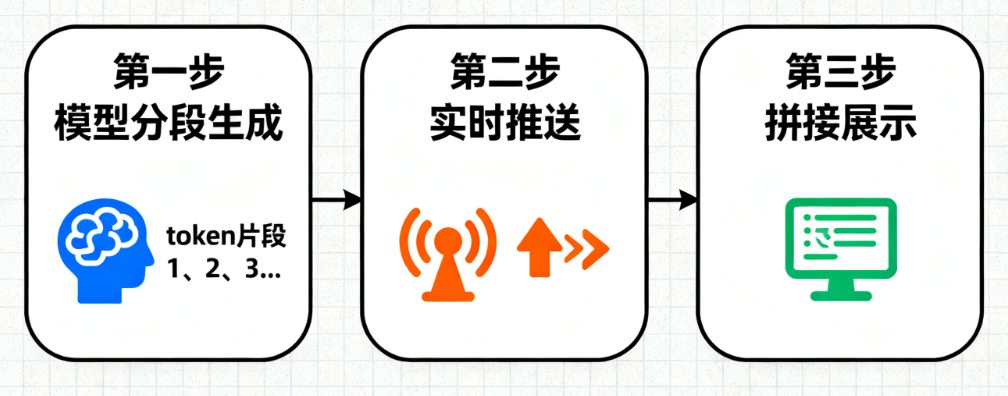
LLM的流式输出本质是基于HTTP流式传输(或WebSocket)实现的“增量返回”机制,核心逻辑可拆解为3步:
- 模型端“分段生成”:大模型生成文本时,并非一次性计算所有内容,而是按“token片段”(可理解为“词语/短句单元”)逐步生成——比如生成“讲一个翠花的故事”,模型会先算“翠花是山村里的”,再算“一个小姑娘,每天帮妈妈”,以此类推;
- 实时推送片段:每生成一个token片段,模型就通过“流式接口”将片段推送给调用方(如我们的Python代码),而非等待全部生成;
- 调用方“实时拼接”:我们的代码接收到每个片段后,立即打印、展示或存储,最终拼接成完整结果。
类比生活场景:就像外卖小哥送10份餐,“一次性输出”是等10份餐全做好再一起送;“流式输出”是做好1份送1份,你收到后可以先吃,不用等全部到齐。
3. 基础实战:用ChatOpenAI实现“故事小助手”流式输出
首先从最基础的「直接调用大模型流式接口」入手,实现一个“输入关键词,流式生成故事”的小工具。我们依然用DeepSeek 作为示例模型,你也可以替换为GPT-4、Llama 3等支持流式的模型。
3.1 环境准备
确保已安装最新版langchain-openai(流式功能依赖较新的API封装):
3.2 完整代码:故事小助手(逐字生成故事)
3.3 运行效果说明
代码执行后,你会看到控制台逐字/逐词输出故事,而非等待几秒后一次性显示:

关键注意点:streaming=True是开启流式的核心参数,若未设置,model.stream()会报错;flush=True必须加,否则Python会将片段缓存起来,导致“看似流式实则一次性输出”。
4. 进阶实战:用LCEL实现“科普助手”流式输出
在LangChain 0.3+中,推荐用LCEL表达式(|管道符)串联组件——流式输出也不例外。相比直接调用model.stream(),LCEL能更灵活地结合“提示模板、输出解析器”,适配复杂场景(如带格式的科普内容生成)。
4.1 需求定义:科普助手
实现功能:接收用户输入的“科普主题”,按“【核心概念】→【生活案例】→【一句话总结】”的格式,流式生成科普内容。
4.2 完整代码:LCEL流式串联
4.3 运行效果示例(输入“人工智能”)
4.4 LCEL流式的优势
相比直接调用model.stream(),LCEL的核心优势在于组件解耦与复用:
- 若想修改科普格式,只需改
prompt,无需动模型和解析器; - 若想切换模型(如从通义千问换成GPT-3.5),只需替换
model实例,流式逻辑不变; - 后续可轻松添加“输入验证”“结果存储”等组件(如
输入验证 → prompt → model → parser → 数据库存储),流式特性不受影响。
5. 流式输出的优势与限制:实战前必看
流式输出虽能提升体验,但并非适用于所有场景。我们需要客观看待其优劣势,避免盲目使用。
5.1 核心优势
优势点 | 具体场景说明 |
|---|---|
提升用户感知体验 | 聊天机器人、实时问答场景中,用户看到“逐字输出”,会觉得“响应很快”,减少等待焦虑; |
降低内存占用 | 生成万字报告、小说章节时,无需一次性加载完整文本(可能占几十MB内存),而是逐段处理; |
支持中途中断 | 若用户看到部分内容后不想继续(如生成的故事不符合预期),可随时停止流式接收,节省资源; |
适配长文本生成 | 一次性输出长文本可能触发“超时错误”(如API限制单次返回时长),流式分段返回可规避此问题; |
5.2 关键限制
限制点 | 实际影响与应对方案 |
|---|---|
完整结果总耗时未减少 | 流式只是“分段返回”,模型生成完整内容的总时间基本不变(甚至略增,因多了分段传输开销);→ 应对:仅在“用户需要实时感知”的场景用(如聊天),后台批量生成(如报表)仍用一次性输出; |
代码复杂度提升 | 需处理“片段拼接”“中断逻辑”“错误重试”(如某片段传输失败,需重新请求后续内容);→ 应对:用LangChain LCEL封装,减少重复代码; |
部分模型/API不支持 | 并非所有LLM都支持流式输出(如部分轻量开源模型、旧版API);→ 应对:调用前查看模型文档(如通义千问、GPT系列、Llama 3均明确支持流式); |
输出解析难度增加 | 一次性输出可直接用JSON解析器提取结构化数据(如“{“核心概念”: “xxx”, “案例”: “xxx”}”),流式需逐段判断“是否解析完整”;→ 应对:用LangChain的 |
6. 实战注意事项:避坑指南
- API密钥安全:代码中的
api_key不要硬编码到项目中,建议用环境变量(如os.getenv("QWEN_API_KEY"))或配置文件存储,避免泄露; - 流式中断处理:在用户主动取消(如关闭页面)或网络异常时,需调用
stream.close()停止流式传输,避免模型继续生成浪费资源; - 不同模型的流式差异:
- 通义千问、GPT系列的
stream()返回的是“包含content字段的Chunk对象”; - 部分开源模型(如本地部署的Llama 3)需通过
transformers库的pipeline("text-generation", streaming=True)实现流式,接口略有不同; - 前端流式展示:若需在Web端实现流式(如类似ChatGPT的界面),后端需用SSE(Server-Sent Events)或WebSocket传递流式片段,前端用
EventSource接收并实时更新DOM;
7. 总结
7.1 核心总结
- 流式输出的核心价值:不是“加速生成”,而是“提升用户实时感知体验”,适合聊天、长文本实时生成等场景;
- 落地路径:基础场景用
ChatOpenAI.stream(),复杂场景用LCEL串联“模板+模型+解析器”,减少代码复杂度; - 适用边界:优先在“用户可见”的交互场景用,后台批量任务用一次性输出,平衡体验与效率。
如果本文对你有帮助,欢迎点赞+评论,说说你在流式输出中遇到的问题或想实现的场景,一起交流进步!
