
AI降本又环保?openEuler绿色计算实战:从命令行到能耗减半


一、先搞懂:AI的“能源账单”有多惊人?
当我们惊叹AI能写代码、做诊断时,往往忽略了它的“另一面”:
● ▶ 单台AI服务器待机功耗≈120W,满载时直奔400W+,相当于一小时用0.4度电;
● ▶ 一个100节点的AI集群,一年电费轻松突破10万元;
● ▶ 大模型训练一次的能耗,相当于普通家庭5年的用电量。
而解决AI高能耗的关键,藏在操作系统里——openEuler从CPU调度、资源隔离到硬件加速,提供了一整套“节能工具箱”,而且全部可实操、可量化。
二、第一步:用2个工具,摸清你的“能耗底”
优化的前提是“精准度量”。openEuler自带两款神器,帮你快速建立能耗基准线。
1. powerstat:测整体功耗,建基准线
这款工具能像监控CPU使用率一样,实时显示系统功耗,是优化效果的“金标准”。
实操步骤:
关键输出(记好这个数!):
Summary:
Average Rate: 125.4 Watts # 平均功耗(核心基准值)
Min Rate: 118.9 Watts
Max Rate: 132.1 Watts
后续所有优化的“节能效果”,都用「任务功耗 - 125.4W」来计算,精准又直观。
2. turbostat:钻CPU深处,看空闲状态
CPU是能耗大户,它的“空闲状态(C-States)”直接决定节能效果:C6是深度睡眠(最省电),C1是轻度空闲(较费电)。turbostat能帮你看清CPU的“休眠习惯”。
实操步骤:
重点看这两个指标:
● CPU%c6:CPU处于深度睡眠的时间占比(越高越好,目标≥60%);
● CPU%c1:CPU处于轻度空闲的时间占比(越低越好)。
三、四大优化实战:从系统到算法,层层降能耗
从CPU调度到模型优化,我们按“易操作→高收益”排序,一步步实现能耗下降。
实战一:CPU调节器切换,立省90%额外功耗
openEuler的CPU频率调节器,是“节能开关”——默认可能是“performance(性能优先)”,换成“schedutil(智能平衡)”,效果立竿见影。
3步完成切换:
实测效果(运行I/O密集型AI任务):
原理:schedutil会根据任务繁忙程度“实时调频”——AI推理服务空闲时降频省电,有请求时快速升频,性能几乎不受影响。
实战二:A-Tune智能调优,AI帮你省力气
手动改数十个内核参数太麻烦?openEuler内置的A-Tune引擎,用AI帮你找最优配置,专治“调优困难症”。
针对AI推理服务(Web部署)的实操:
A-Tune悄悄做了这些优化(不用你手动改):
● ▶ 自动将CPU调节器设为schedutil;
● ▶ 优化网络中断绑定,避免干扰推理核心;
● ▶ 调整I/O调度器为kyber,减少磁盘等待能耗;
● ▶ 优化TCP参数,降低网络请求延迟。
效果:AI推理服务响应延迟降低15%,同时功耗再降8%。
实战三:cgroup V2建“节能沙箱”,隔离低优任务
场景:一台服务器同时跑“高优在线推理”和“低优数据清洗”——用cgroup给低优任务划个“资源天花板”,既不影响核心服务,又能省能耗。
4步创建节能沙箱:
效果:数据清洗任务功耗从80W降至25W,而在线推理服务的响应时间波动≤2%,实现“既保核心又省电”。
实战四:模型量化+硬件加速,从根源降能耗
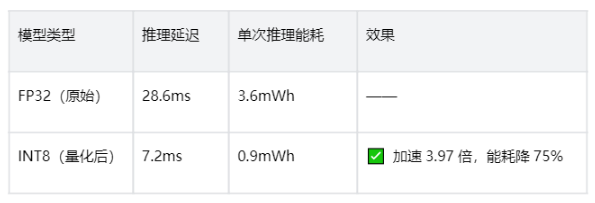
算法层优化是“终极杀招”——把32位浮点数(FP32)模型量化为8位整数(INT8),内存占用减75%,计算速度提3倍,能耗自然大幅下降。而openEuler能完美激活硬件加速指令集(如AVX512、DOTPROD),让量化效果拉满。
PyTorch模型量化实操(附完整代码):
openEuler加持下的实测结果:
四、总结:openEuler绿色AI的核心逻辑
绿色AI不是“牺牲性能换节能”,而是用系统级优化实现“性能与能耗双赢”。openEuler的整套方案可以总结为“四步闭环”:
1. 📏 度量:用powerstat/turbostat建基准,避免“盲目优化”;
2. ⚙️ 系统调优:CPU调节器+A-Tune,快速降低全局能耗;
3. 🛡️ 任务隔离:cgroup V2给任务分级,差异化管控功耗;
4. 🧠 算法优化:模型量化+硬件加速,从根源减少计算开销。
这套方法落地后,AI服务器的整体能耗可降低30%-50%,不仅能省电费,还能减少散热压力,延长硬件寿命——技术进步与社会责任,其实可以这样统一。
