想象这样的场景,某医院部署了一套AI癌症筛查系统,在10万名体检者中准确率高达95%。管理层拍手称赞,直到有一天发现,系统只是把所有人都判定为健康,而那5000名真正的癌症患者被漏诊了!
这是机器学习上的隐形陷阱,准确率会说谎,尤其在数据不平衡时,而F1分数(F1 Score),正是揭穿这个谎言的“测谎仪”。
一、什么是 F1分数?
F1 分数是机器学习中用于综合评估分类模型性能的核心指标之一。它结合了两个关键概念精准率和召回率,通过调和平均数将二者融合
精准率:在模型预测为正类的样本中,实际为正的比例,它反映模型能否抓得准。
召回率:在所有正类样本中,被模型正确识别出的比例,它反映模型能否抓得全。
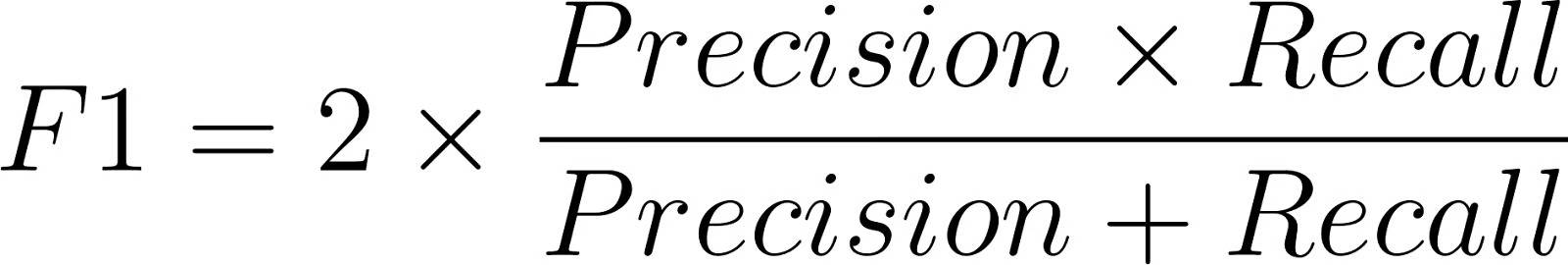
调和平均数的妙处在于,无论精准率多高,只要召回率很低,F1都会被拉低,不允许模型偏科。
案例
假设你开发了一个电商反欺诈系统,数据分布如下
正常订单:9500笔,占比95%
欺诈订单:500笔,占比5%
方案A:懒惰模型
def lazy_model(order):
return "正常"
```
这个模型的准确率是多少?95%! 但它对欺诈订单的识别能力是0%。
方案B:F1优化模型
- 准确率:88%
- F1分数:0.75
- 成功拦截400笔欺诈
哪个模型更有价值?显然是方案B。这就是F1分数存在的意义:它拒绝让模型蒙混过关。
F1分数的数学本质是:
F1 = 2 × (精确率 × 召回率) / (精确率 + 召回率)
二、为什么 F1 比准确率更可靠?
准确率只是统计预测正确的样本占比,计算简单,极易被类别不平衡误导。
假设在一个包含 1000个样本的医疗数据集中,只有5%的患者患病。若模型始终预测无病,它的准确率高达 95%,但从诊断角度看,这个模型完全失效。
而F1分数能揭示真相。
准确率: 99.5% ← 看起来完美!
精确率: 未定义(因为TP=0, FP=0)
召回率: 0% ← 揭露真相:一个欺诈都没抓到
F1分数: 0 ← 模型不可用
F1分数将错误显性化,尤其在欺诈检测、疾病识别、异常监测等任务中,F1能有效揭露那些被高准确率掩盖的盲区。
三、F1 的不同形态:从二分类到多分类
真实的分类任务往往不止两个类别。为适应复杂场景,F1 提供了多种平均策略:
二分类:癌症筛查系统
from sklearn.metrics import f1_score, precision_score, recall_score, confusion_matrix
import numpy as np
np.random.seed(42)
y_true = np.array([1]*20 + [0]*80)
y_pred = np.array([1]*18 + [0]*2 + [1]*5 + [0]*75)
precision = precision_score(y_true, y_pred)
recall = recall_score(y_true, y_pred)
f1 = f1_score(y_true, y_pred)
print(f"精确率: {precision:.2f} (预测有病的人中,真有病占{precision*100:.0f}%)")
print(f"召回率: {recall:.2f} (真有病的人中,找出了{recall*100:.0f}%)")
print(f"F1分数: {f1:.2f}")
cm = confusion_matrix(y_true, y_pred)
print("\n混淆矩阵:")
print(f"真阴性(TN): {cm[0,0]} | 假阳性(FP): {cm[0,1]}")
print(f"假阴性(FN): {cm[1,0]} | 真阳性(TP): {cm[1,1]}")
示例里可以看出
精确率78%,每预测5个患病,有1个是误报
召回率90%,20名真实患者中,找到了18名(漏了2名)
F1分数0.84:表现良好,但还有提升空间
多分类:疾病类型识别
from sklearn.metrics import f1_score, classification_report
y_true = [0, 1, 2, 2, 0, 1, 2, 1, 2]
y_pred = [0, 2, 1, 2, 0, 0, 2, 1, 2]
print("Macro F1:", f1_score(y_true, y_pred, average='macro'))
print("Micro F1:", f1_score(y_true, y_pred, average='micro'))
print("Weighted F1:", f1_score(y_true, y_pred, average='weighted'))
print("\n" + classification_report(y_true, y_pred,
target_names=['疾病A', '疾病B', '疾病C']))
这种灵活性让 F1 几乎能覆盖从二分类到多标签检测的所有常见应用。
四、Python实战:一分钟算出 F1
在Python的scikit-learn库中,计算分数几乎是一行命令的事。
二分类示例:
from sklearn.metrics import f1_score
y_true = [0, 1, 1, 1, 0, 1, 0, 1]
y_pred = [0, 1, 0, 1, 0, 1, 1, 1]
print("F1 Score:", round(f1_score(y_true, y_pred), 2))
多分类示例:
from sklearn.metrics import f1_score
y_true = [0, 1, 2, 2, 0, 1, 2, 1, 2]
y_pred = [0, 2, 1, 2, 0, 0, 2, 1, 2]
print("Macro F1:", round(f1_score(y_true, y_pred, average='macro'),2))
print("Weighted F1:", round(f1_score(y_true, y_pred, average='weighted'),2))
五、进阶:Fβ 分数的权衡
F1 只是 Fβ 家族的一个特例。当你需要偏重精准率或召回率时,可调整 β 值:
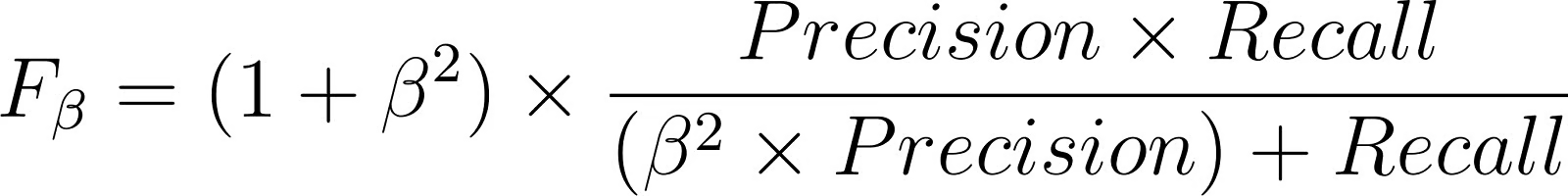
F1分数默认"精确率和召回率同等重要",但现实往往不是这样:
场景A:癌症早筛
- 漏诊(假阴性)可能致命 → 召回率更重要
- 需要提高β值,如F2分数
场景B:垃圾邮件过滤
- 误杀正常邮件(假阳性)损失更大 → 精确率更重要
- 需要降低β值,如F0.5分数
```
Fβ = (1 + β²) × (精确率 × 召回率) / (β² × 精确率 + 召回率)
β > 1更关注召回率(如医疗诊断中宁可多报也不能漏报)
β < 1:更关注精准率(如垃圾邮件过滤中宁可漏掉一些也不误伤正常邮件)
例如:
F2 Score 适合医学诊断任务
F0.5 Score 常用于邮件分类、内容审核系统
六、案例:糖尿病检测模型
假设某模型预测糖尿病患者的准确率达 88%。听起来不错?但仔细看数据:
from sklearn.metrics import f1_score, fbeta_score
y_true = [0,0,0,1,0,1,0,1,0,0,1,0,0,0,1,1]
y_pred = [0,0,0,1,0,0,0,1,0,0,1,0,0,0,0,1]
print("Accuracy:", 0.88)
print("F1 Score:", round(f1_score(y_true, y_pred),2))
print("F2 Score:", round(fbeta_score(y_true, y_pred, beta=2),2))
输出结果:
Accuracy: 0.88
F1 Score: 0.80
F2 Score: 0.71
模型表面准确,但在召回层面仍有明显不足。
错过了真实病患,即便准确率高也毫无意义,F1和F2让我们看清了模型是否真正可靠。
七、高级技巧:阈值调优与ROC曲线联
from sklearn.metrics import precision_recall_curve, roc_auc_score
import matplotlib.pyplot as plt
y_scores = np.random.rand(1000)
y_true = (y_scores + np.random.normal(0, 0.3, 1000) > 0.7).astype(int)
precisions, recalls, thresholds = precision_recall_curve(y_true, y_scores)
f1_scores = 2 * (precisions * recalls) / (precisions + recalls + 1e-10)
best_idx = np.argmax(f1_scores)
best_threshold = thresholds[best_idx]
best_f1 = f1_scores[best_idx]
print(f"最佳阈值: {best_threshold:.3f}")
print(f"最佳F1分数: {best_f1:.3f}")
print(f"对应精确率: {precisions[best_idx]:.3f}")
print(f"对应召回率: {recalls[best_idx]:.3f}")
plt.figure(figsize=(10, 6))
plt.plot(thresholds, f1_scores[:-1], label='F1 Score')
plt.axvline(best_threshold, color='r', linestyle='--', label=f'最佳阈值={best_threshold:.2f}')
plt.xlabel('阈值')
plt.ylabel('F1分数')
plt.title('阈值 vs F1分数曲线')
plt.legend()
plt.grid(True)
plt.show()
写在最后
衡量模型表现,绝不是数字游戏,而是风险管理的艺术。准确率告诉你模型“看起来有多聪明”,F1 分数告诉你模型“是否真的可靠”。
在任何关乎生命、安全、信任的应用场景中,选择 F1,就是选择责任感。



