
AI眼科进化时:多模态智能体用53个工具实现人机协同


长久以来的医学AI,尤其在眼科领域,一直停留在单任务工具的阶段。
例如,一个模型专门用于识别糖尿病视网膜病变,另一个模型专门用于黄斑水肿的量化分析。它们只能被动的接收单一模态的输入(如一张眼底照片),给出孤立的判断。
这种碎片化的AI无法理解病人的全局信息:糖化血红蛋白、用药史、眼压、甚至合并症风险。
一款名为EyeAgent的AI系统提供了多模态思路,通过动态调度53个专用工具,让该系统在眼科诊断中准确率突破80%。

论文链接:https://arxiv.org/pdf/2511.09394
多模态推理不是简单叠加
医疗AI领域,眼科因其多模态成像的复杂性,一直是AI落地的硬骨头。近期,一项发表于国际顶刊的研究推出了EyeAgent,首个多模态代理式AI框架,通过工具集成和逻辑推理,实现了眼科临床决策的突破。
三个核心支柱
视觉编码器):解析视网膜、OCT(光学相干断层扫描)和裂隙灯图像
语言-知识融合层:整合病历、实验室数据和医生记录。
医学语言模型:基于大型语言模型(DeepSeek-V3)架构,通过上下文学习生成诊断建议与风险解释。
这一架构的关键并非数据堆叠,而是模态间的语义映射。
例如,系统能在看到OCT中的黄斑厚度异常时,主动检索患者的糖尿病史,从而判定病灶性质,这种跨模态推理正是传统影像AI所缺失的能力。
EyeAgent动态协调了53个已验证的眼科专用工具,覆盖了23种成像模态和260种眼病。
这些工具按临床需求分为四类:全科医生工具(如基础筛查)、视网膜专家工具(如病灶分割)、医学教育工具(如报告生成)和跨专科分析工具(如心血管风险预测)。
系统通过检索增强生成(RAG)整合14本眼科教科书知识,确保输出有据可循。
性能超越影像AI
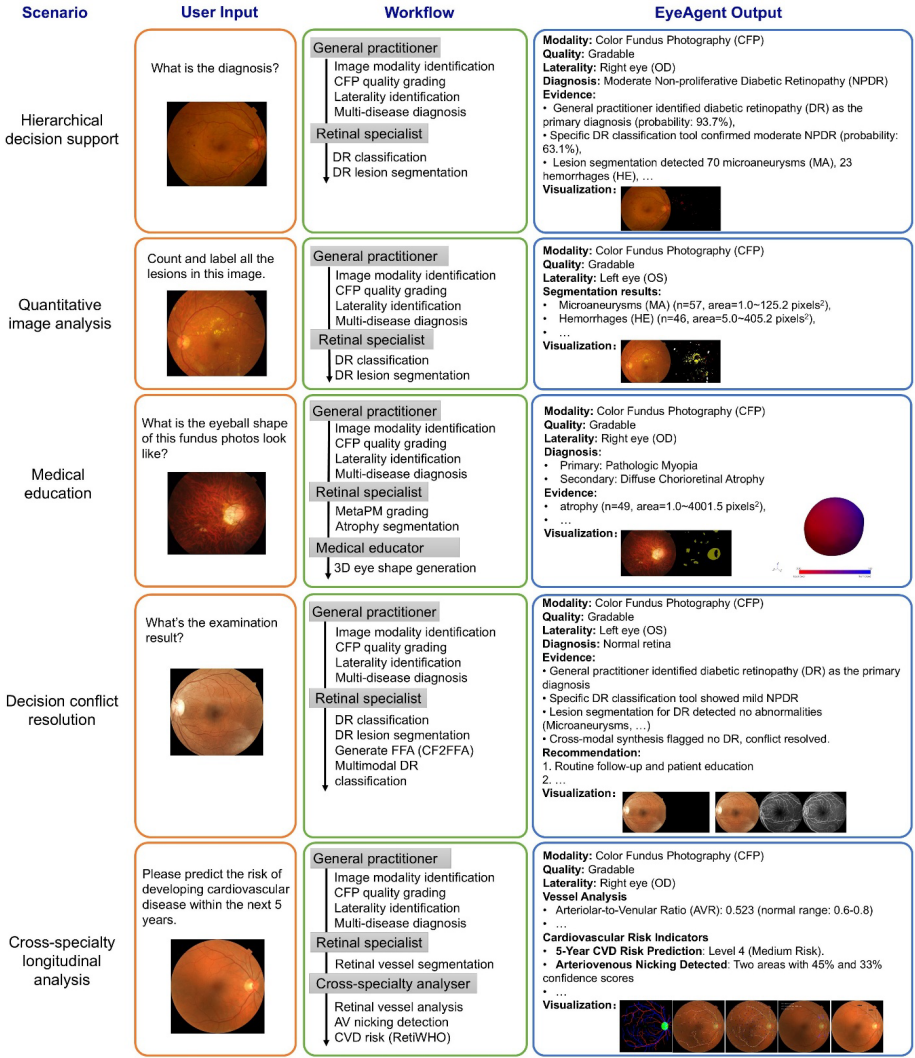
在五类临床工作流模拟中,EyeAgent展现出类人推理能力。
例如,在分层决策支持中,它可模拟从初筛到专科分诊的完整链条;在定量分析中,自动生成病灶地图和生物标志物数据;甚至能通过多工具验证解决诊断冲突。
这种灵活性使其能适应从慢病管理到罕见病诊断的多元场景。
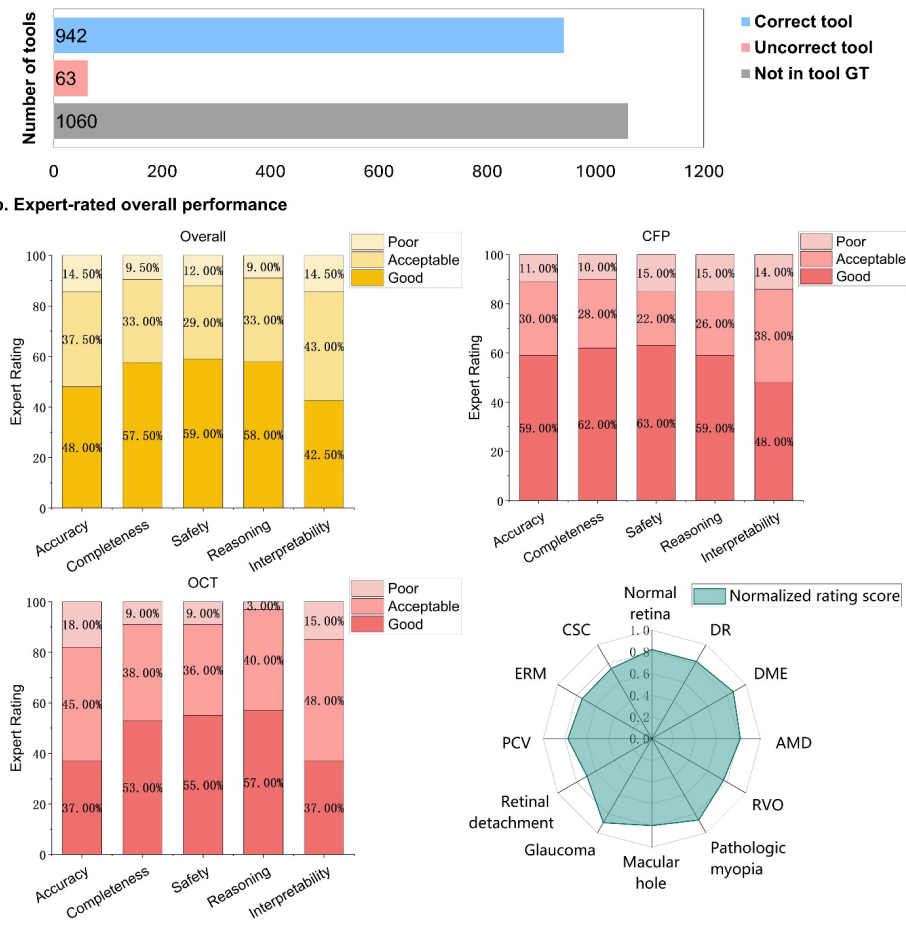
性能层面,逐步消融实验揭示工具集成的关键价值,仅用5个通用工具时,诊断准确率为69.71%;加入疾病专用分类器后提升9.11%;进一步整合分割工具再增1.68%。
最终,53工具全开时准确率达80.79%,82%的性能增益源于专用分类与分割工具,印证了工具质量优于模型规模。
与GPT-4o的对比更凸显其可靠性。
在9个案例中,GPT-4o因缺乏工具支撑,误判影像模态或虚构细节;而EyeAgent通过工具调用生成量化结果(如血管参数CRAE/CRVE),误差率显著降低。
在对抗性测试中,它甚至能识别图像伪影,通过多工具交叉验证规避误诊。
系统部署的可行性
研究团队在三家医院部署系统时采取了人机协同模式。
这项涉及27名眼科医生的多中心研究显示,EyeAgent独立诊断准确率(93.33%)媲美资深医生(84.4%),远超初级医生(71.1%)。
作为助手时,它将整体诊断准确性提升18.51%,其中初级医生改善达23.3%。报告完整性评分从0.57跃至0.76,且任务耗时减半。
88.9%的医生认可其输出可解释性,并愿用于临床。
虽然系统仍有局限,其性能在眼底彩照(CFP)模态最强,OCT工具尚待丰富,LLM推理逻辑也未必完全契合眼科专科思维。
但模块化设计允许未来即插即用的新工具,而视网膜作为全身健康窗口的定位,更预示其在跨专科协同中的潜力。
该AI模型的训练涉及超20万例影像及匿名病历,在未见数据集上性能下降不足5%。
这意味着它具备在不同设备、不同医院环境下稳定运行的潜力。

初筛场景是AI眼科的黄金落地口
AI先行生成诊断摘要,医生再做验证。其结果是平均阅片时间缩短32%,医生的误诊率下降约 17%。
而在糖尿病、眼病筛查门诊中,把AI被用于初筛阶段,自动分流低风险患者,让医生将精力集复杂病例,是目前医疗AI从实验室走向医院的有效途径。
