
K8s部署AI推理太乱?NVIDIA Grove一键搞定多组件编排



一、先搞懂:AI推理部署,为啥越来越“乱”?
几年前,AI推理还是“一个模型一个Pod”的简单模式;现在不一样了——一个完整的推理管道,可能包含预填充、解码、视觉编码器、KV路由器等N个组件,甚至多个模型协同工作。
这就给K8s运维挖了4个大坑:
1. 组件协调乱
预填充节点要等主节点启动,解码节点要跟预填充匹配,启动顺序错一步就全崩,全靠脚本硬凑太容易出问题。
2. 扩缩容踩坑
流量高峰时加了预填充工作节点,却忘了同步扩解码节点;新服务副本起来,组件比例全乱,性能直接打折。
3. 拓扑调度难
预填充和解码节点跨NVLink域部署,KV缓存传输延迟飙升;想分散副本提可用性,又不知道怎么贴近网络拓扑。
4. 生命周期难管
单个Pod故障重启后,连不上对应的主节点;滚动更新时拓扑被打乱,服务中断风险翻倍。
简单说:传统“单Pod管理”的思路,已经跟不上“多组件协同”的AI推理需求了。而Grove的核心价值,就是把“一堆零散组件”变成“一个可管可控的逻辑系统”。
二、Grove到底牛在哪?5大核心能力解决编排痛点
Grove本质是K8s的自定义API,专门为AI推理而生。它把多组件推理系统描述成一个自定义资源(CR),剩下的调度、扩缩容、启动顺序,全由平台自动搞定。核心能力看这5点:
1. 多级自动扩缩容:组件协同不用“手动牵线”
传统扩缩容是“管头不管尾”——加了预填充工作节点,解码节点没跟上,推理直接堵死。Grove支持三级扩缩容:
● 单组件级:流量高峰时自动加预填充工作节点;
● 组件组级:预填充主节点扩缩时,自动匹配对应的工作节点数量;
● 全服务级:整体容量不够时,复制整个推理系统的完整副本。
举个例子:当用户请求暴涨,Grove会先加3个预填充工作节点,同时自动扩2个解码节点配套,不用运维手动计算比例。
2. 拓扑感知调度:性能直接提30%
AI推理的延迟,很大程度取决于组件部署的“物理位置”。Grove能读懂GPU集群的拓扑结构:
● 把预填充和解码节点调度到同一NVLink域,KV缓存传输延迟降低50%;
● 服务副本分散部署在不同节点,避免单点故障,可用性拉满。
3. 系统级生命周期管理:故障恢复“全自动”
以前单个Pod故障,要手动重新关联主节点;滚动更新时,拓扑乱了延迟飙升。Grove把整个系统当“一个单元”管理:
● 预填充工作节点重启后,自动重连对应的主节点;
● 滚动更新时保持网络拓扑不变,服务不中断、延迟不波动。
4. 灵活组调度:组件扩展“不绑死”
传统组调度把所有组件“绑成一团”,预填充和解码必须同步扩缩,不符合实际负载。Grove能:
● 保证核心组合(比如1个预填充+1个解码节点)必存在;
● 允许预填充和解码节点按不同比例独立扩展(比如预填充:解码=1:3)。
5. 声明式配置:一个文件定义全系统
不用再拼接N个YAML和脚本,一个Grove配置文件就能定义:
● 所有组件(前端、预填充、解码)的配置和资源需求;
● 启动顺序(主节点先启,工作节点后启);
● 扩缩容策略和拓扑约束。
三、核心原理解析:Grove的“三级作战单元”
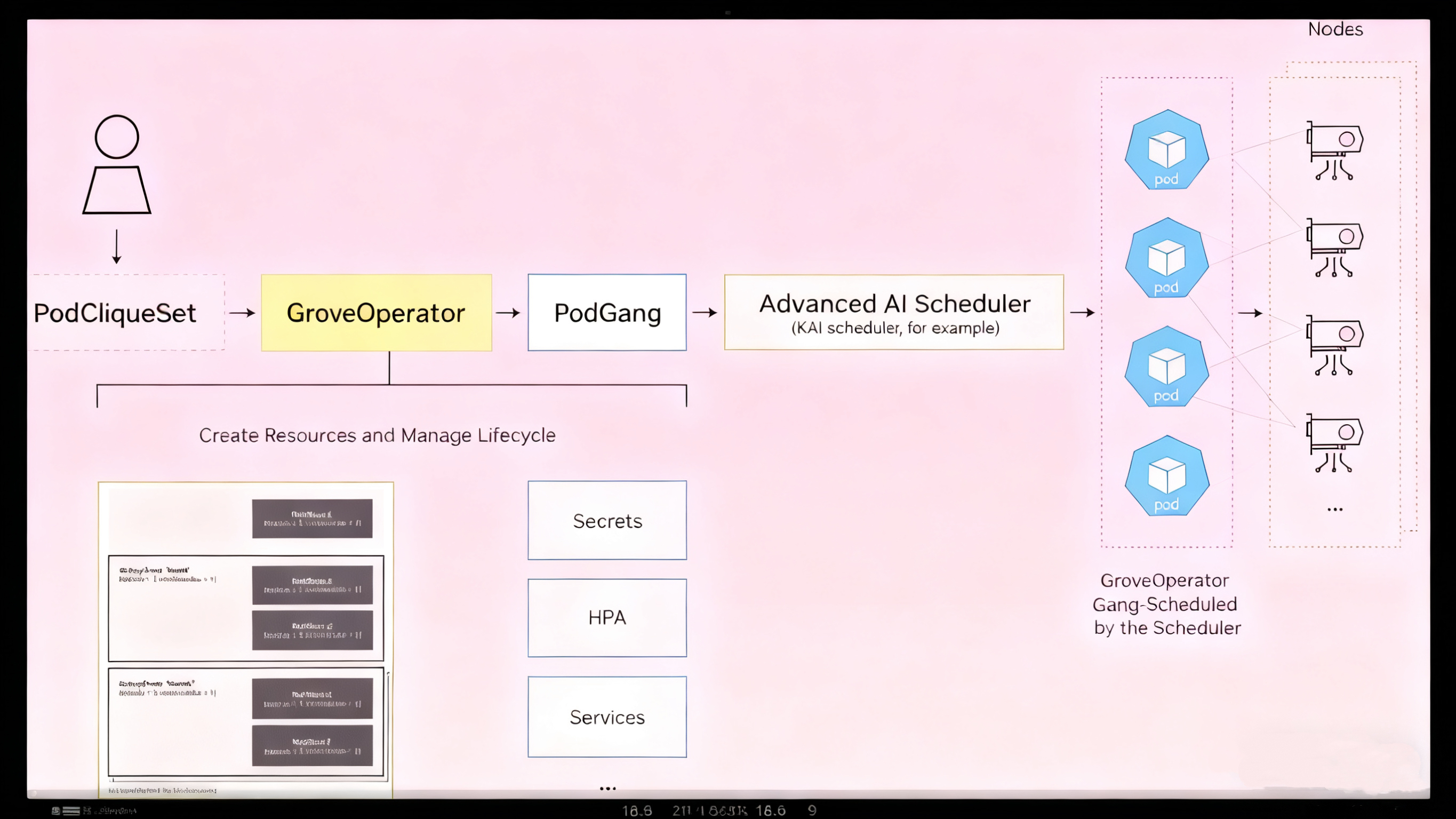
Grove靠3个核心自定义资源(CR)实现层级化编排,把复杂系统拆成“可管理的小分队”,看这张逻辑图(对应原文图1):
「PodClique(角色小分队)」→「PodCliqueScalingGroup(协同小组)」→「PodCliqueSet(完整作战部队)」
● 1. PodClique:按角色分组的“小分队”每个PodClique对应一类组件,比如“预填充主节点”“解码工作节点”,有独立的配置(镜像、资源限制)和扩展逻辑。比如原文图1中,A是前端PodClique,B是预填充主节点PodClique,C是预填充工作节点PodClique。
● 2. PodCliqueScalingGroup:必须协同的“小组”把紧密耦合的PodClique打包,比如“预填充主节点+预填充工作节点”,它们会同步扩缩,避免“主节点在、工作节点不够”的问题。
● 3. PodCliqueSet:完整的“作战部队”定义整个推理系统,包含所有PodCliqueScalingGroup,指定启动顺序、拓扑约束和扩缩容策略。当需要扩容时,Grove会复制整个PodCliqueSet的副本,分散部署在集群中。
工作流(对应原文图2):创建PodCliqueSet → Grove Operator生成底层Pod/Service → 调度器(如KAI Scheduler)按拓扑部署 → 系统全自动运行与自愈。
四、实操教程:用Grove部署PD分离推理服务(附完整命令)
以Qwen3-0.6B模型为例,教你用Grove在K8s上部署“前端+预填充+解码”的完整推理系统,全程10分钟搞定。
先决条件(必看)
● ✅ 支持GPU的K8s集群(推荐16G显存及以上GPU);
● ✅ kubectl已配置集群访问权限;
● ✅ 安装Helm CLI(3.0+版本);
● ✅ Hugging Face Token(用于拉取模型,点此获取)。
步骤1:创建Hugging Face密钥
替换<insert_huggingface_token>为你的实际Token,执行命令:
注意:Token不要提交到代码仓库,生产环境建议用密钥管理工具存储。
步骤2:创建独立命名空间
步骤4:验证Grove安装成功
✅ 预期输出(出现以下CRD说明安装成功):
podcliques.grove.io
podcliquescalinggroups.grove.io
podcliquesets.grove.io
podgangs.scheduler.grove.io
podgangsets.grove.io
步骤5:编写Grove部署配置文件
创建名为dynamo-grove.yaml的文件,定义前端、1个预填充节点、2个解码节点的完整架构:
步骤6:部署并验证服务
✅ 预期输出(所有Pod READY为1/1或2/2):
NAME READY STATUS AGE
dynamo-grove-0-frontend-w2xxl 1/1 Running 10m
dynamo-grove-0-vllmdecodeworker-57ghl 1/1 Running 10m
dynamo-grove-0-vllmdecodeworker-drgv4 1/1 Running 10m
dynamo-grove-0-vllmprefillworker-27hhn 1/1 Running 10m
dynamo-platform-dynamo-operator-controller-manager-7774744kckrr 2/2 Running 10m
