
模型自主发现算法:AlphaResearch在2/8开放问题上击败人类研究者


在算法设计这种高度依赖经验、洞察与启发式思维的任务上,传统观点认为 AI 只能做优化器。
但 AlphaResearch的出现,让这一假设出现松动。
它不仅能够在特定数学任务上超越人类专家,独立发现未知知识,这意味着语言模型可以作为科研主体。
字节跳动+耶鲁大学+纽约大学+清华大学联合发布的论文表示,AlphaResearch通过构建双研究环境,首次实现了LLM在开放算法问题上的自主发现,并在部分任务中超越人类最佳记录。
论文链接:https://arxiv.org/pdf/2511.08522
项目链接:https://github.com/answers111/alpha-research
双轨环境破解LLM的创新性死循环
传统方法存在根本矛盾:执行验证系统能确保代码运行,但可能收敛于无科学意义的解;纯创意生成系统则易产出不可行的想法。
AlphaResearch的突破在于融合两种路径
- 执行验证环境:语言模型提出算法后立即进入代码执行、性能检测、自动调参等流程,通过代码解释器实时检验生成程序的符合性与性能
- 评审奖励环境:AlphaResearch-RM-7B用2.4万条ICLR评审意见训练,形成一个科研价值判断器,对生成思路进行新颖性和文献对齐度评分
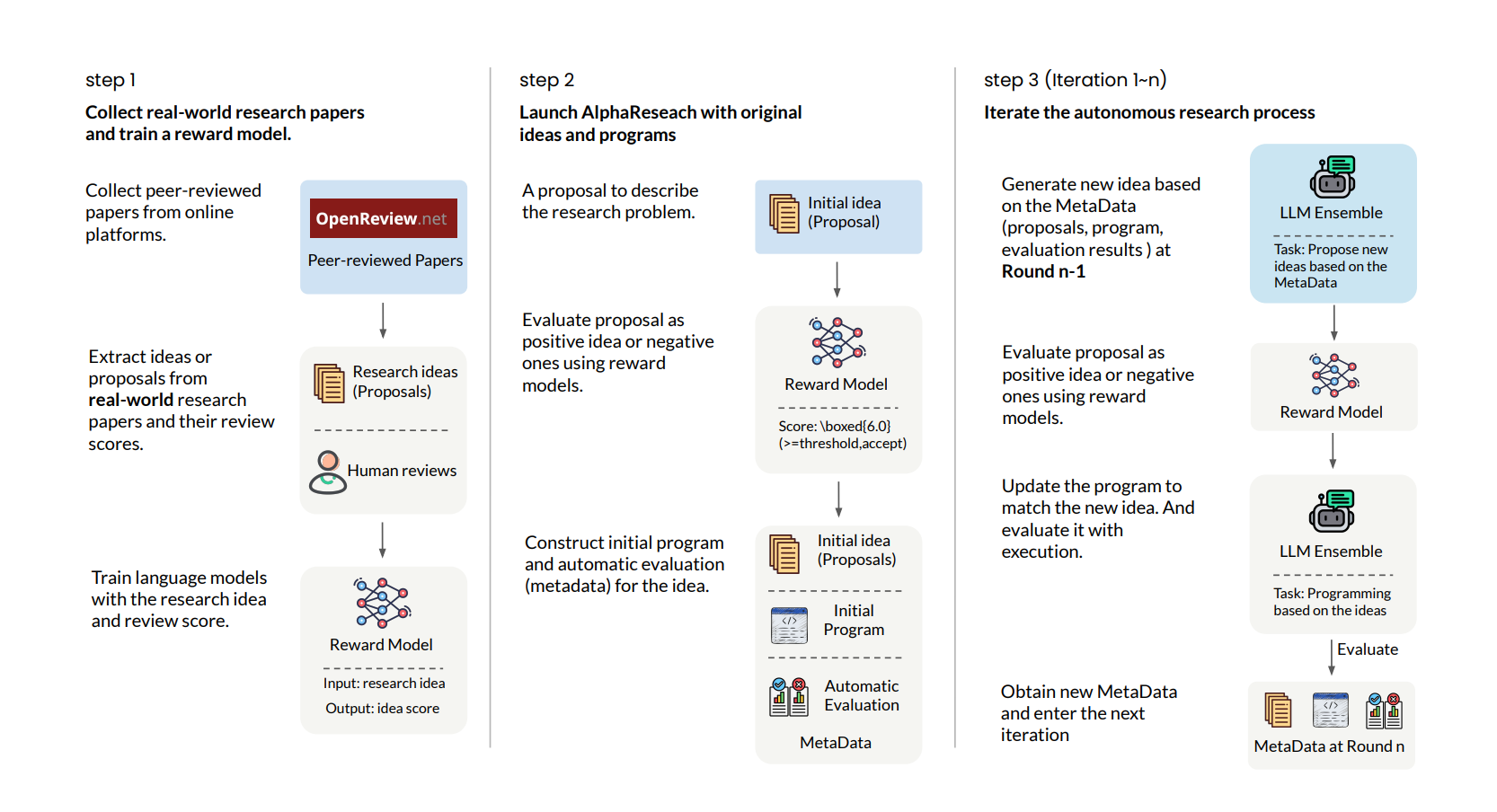
AlphaResearch通过迭代生成想法 → 验证 → 优化的闭环,使LLM具备持续进化能力
圆packing算法实现“超人类”突破
在AlphaResearchComp基准的8个问题中,AlphaResearch以2/8的胜率击败人类研究者。
其最显著成就是圆packing问题(目标:在单位正方形内放置n个不重叠圆,最大化半径和)
- n=26时,AlphaResearch将半径和提升至2.636,超越人类记录的2.634(David Cantrell, 2011)和AlphaEvolve的2.635
- n=32时,进一步达到2.939,优于人类的2.936和AlphaEvolve的2.937
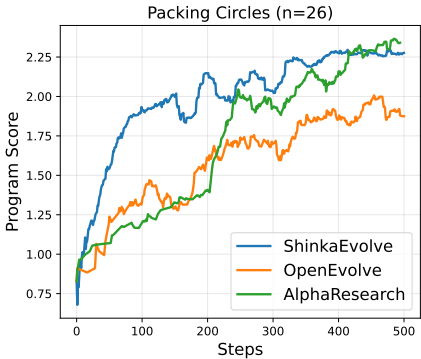
引入评审奖励后,AlphaResearch的优化曲线更平滑,收敛速度更快
这一结果的意义远超数值提升,它证明LLM能产出当前人类知识库中不存在的解法。
例如,其生成的圆排布策略结合了六边形密铺和动态扰动技术,突破了传统对称布局的局限。
自主发现的六大挑战
尽管取得突破,AlphaResearch在其余6个问题中未能超越人类。
分析显示三大瓶颈
- 奖励泛化局限:对高度抽象问题(如数论猜想),基于论文摘要训练的RM难以准确评估创新性
- 代码执行效率:复杂约束问题(如自相关不等式)需大量采样,LLM生成的代码常因计算资源不足而失败
- 初始状态依赖性强:若直接沿用人类最优解初始化,LLM难以跳出局部最优(如MSTD问题中评分无提升)
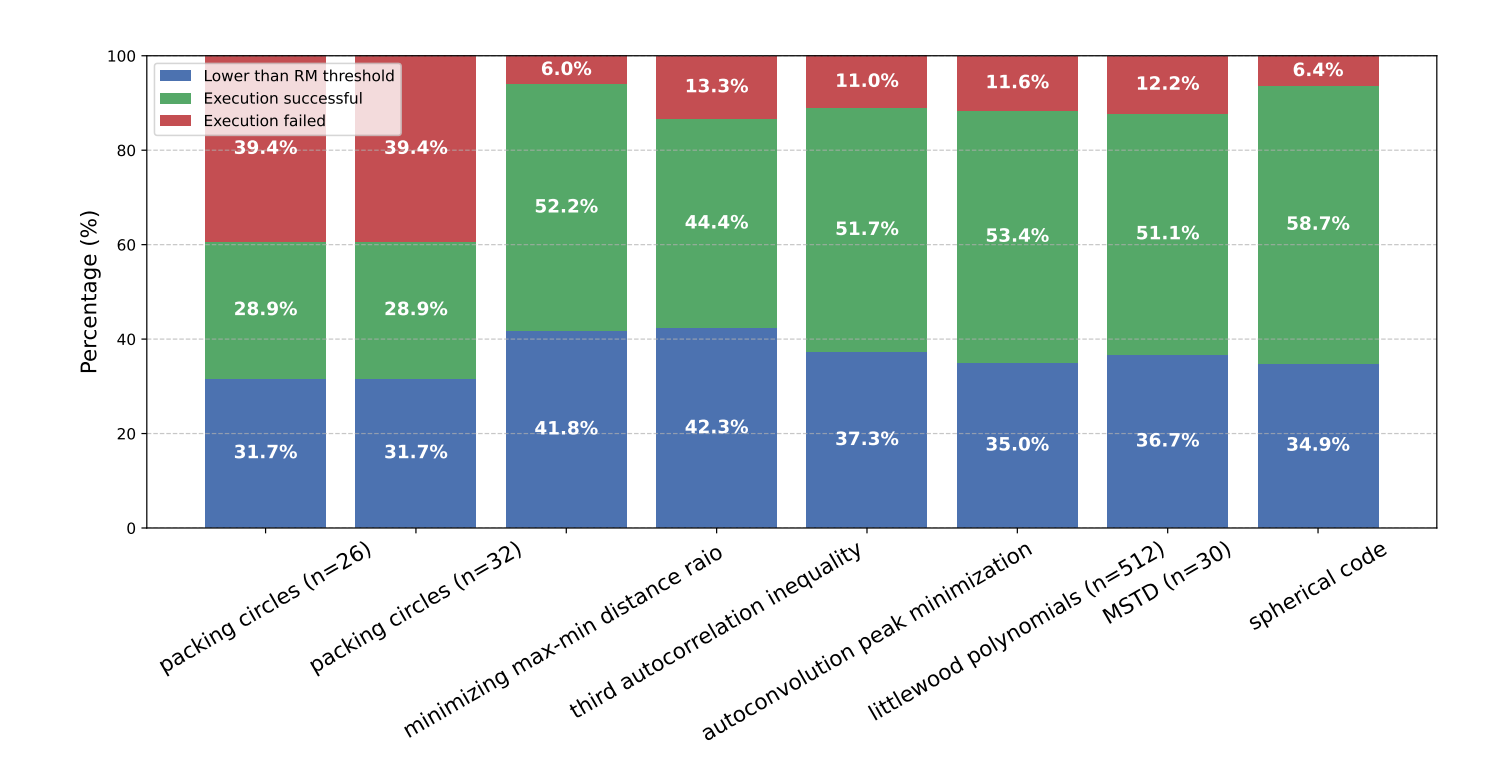
想法筛选机制虽提升效率,但也可能误杀潜在创新方案

科研范式的转变
AlphaResearch带来的并不是单一工具突破,而是一种科研范式的改变。
人类研究员负责方向判断、任务定义、约束设定,模型负责执行、试验、微创新、空间搜索,奖励模型负责科研价值判断,搜索系统负责迭代与路线优化。
未来的科研团队很可能演化成“人类 + LLM + RM + 执行集群”的混合科研结构,这比一个人 + 一个模型强得多,也比传统实验室高效得多。
