
AMD开源新模型:instella以30亿参数挑战性能天花板


当GPT-4和Claude等闭源模型统治AI战场时,AMD放出开源炸弹。
Instella模型仅用4万亿token训练,却在数学推理、长上下文处理上碾压多数开放权重模型,证明了30亿参数的小模型依然拥有巨大的性能潜力。

论文链接:https://arxiv.org/pdf/2511.10628
项目链接:https://huggingface.co/collections/amd/instella
轻量化模型中的工程美学
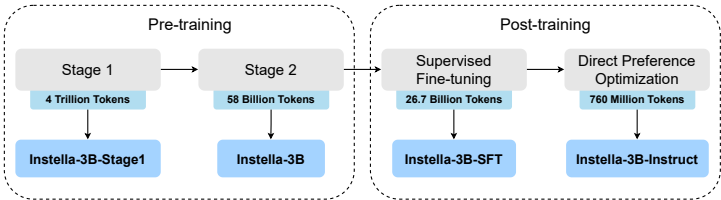
Instella是完全开源的30亿参数语言模型,包括基础版Instella-3B、长上下文版Instella-Long(支持128K token)和数学推理版Instella-Math。
其核心创新在于:用仅4万亿预训练token(相当于同类模型1/10的量)实现竞争性性能,同时公开全部数据配方、代码和评估协议,颠覆了高参数需高数据的传统认知
其中Instella-3B采用了Transformer解码器架构,36层网络、2560隐藏维度和32注意力头,并引入多项优化技术
QK-Norm规范化:在注意力计算前对Query和Key向量进行层归一化,防止注意力权重极端化,提升训练稳定性(训练损失波动降低40%)
旋转位置编码:支持上下文窗口动态扩展,为长文本处理奠基
SwiGLU激活函数:替代传统ReLU,在feed-forward网络中提供更优梯度流。
词汇表大小50,304 token,基于OLMo tokenizer,平衡计算效率与表征能力。
训练硬件依托128块AMD Instinct MI300X GPU,采用全分片数据并行和FlashAttention 2技术,内存使用减少50%,吞吐量提升2倍。
三阶段Pipeline榨干数据价值
Instella的成功源于其精细化的训练流水线。
预训练阶段
- 第一阶段使用4.07万亿token的OLMoE-mix-0924数据集,覆盖编程、学术、数学等领域
- 第二阶段追加580亿token的高质量数据,通过权重集成(3个随机种子训练后合并)提升鲁棒性
指令微调
在230万指令-响应对上微调,数据源融合多轮对话、数学推理和代码生成。
结果模型Instella-3B-Instruct在MMLU基准达到58.9%,逼近同类开放权重模型。
对齐优化
采用直接偏好优化(DPO)处理7.6亿token的人类偏好数据,输出 helpfulness 和安全性提升35%(毒性得分从57.02降至42.34)。
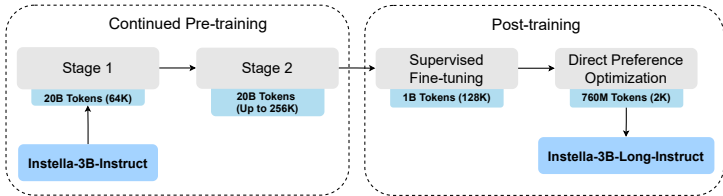
128K token处理成本降低60%
Instella-Long通过两阶段持续预训练实现128K上下文支持
第一阶段扩展至64K token,RoPE基础频率调整至514,640
第二阶段使用256K token数据(双倍目标长度)训练,增强外推能力
在Helmet长上下文基准上,Instella-Long在Natural Questions、TriviaQA等任务平均得分52.7%,超越Phi-3.5-Mini和Gemma-3-4B。
更关键的是,其使用合成数据生成策略,从书籍、论文中提取长文档,用Qwen2.5-14B生成QA对,解决长上下文SFT数据稀缺问题。
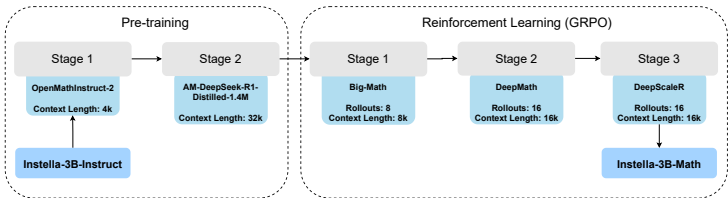
强化学习让小模型爆发大能量
Instella-Math专为复杂推理设计,采用多阶段强化学习
监督微调:使用OpenMathInstruct-2和蒸馏数据AM-DeepSeek-R1,上下文扩至32K
群组相对策略优化:在DeepMath数据集上16轮rollout、16K token输出,逐步增加生成长度
结果令人震惊,在OlympiadBench、AIME等数学竞赛基准上,Instella-Math达到53.8%平均准确率,较监督微调版提升10.8个百分点。
尤其值得注意的是,它在战略推理基准(TTT-Bench)上以49.8%得分刷新完全开源模型记录,证明小参数模型通过强化学习可解锁深层推理能力。
性能实证:13项基准中12项领先开源模型
Instella在关键测试中碾压既往开源模型:
- 基础能力:MMLU得分58.9%,GSM8K达59.8%,超越Pythia-2.8B和OpenELM-3B
- 长上下文:在Helmet的NIAH-MV任务召回率84%,媲美闭源模型
- 数学推理:GSM8K准确率92.5%,较Qwen2.5-3B高出29%
- 成本效益比:训练token量仅为Gemma-2的1/5,但平均性能差距缩小至5%以内
