0深度学习的成功,很大程度上依赖于激活函数。
ReLU 虽然统治了十年,但它从来不是完美解,它的“死亡神经元”问题依然频繁出现在复杂训练任务中。
ReLU在零点处不可微分,导致基于梯度的优化算法在关键时刻失灵。
Softplus,这个常被误解为小众替代品的函数,却在许多高要求场景中展示出远超想象的数学力量与优化优势。
它保留了ReLU的核心优势(非线性、避免梯度消失),同时用一条无限平滑的曲线解决了可微性难题。
更神奇的是,它的数学本质竟然是对数求和指数(LogSumExp)函数的特例,这让它在概率建模、强化学习等领域拥有天然优势。
假如你正在构建更稳定、更可解释、对梯度质量要求更高的模型,Softplus 将彻底改变你对激活函数的认知。
一、Softplus是什么?
Softplus是ReLU(线性整流函数)的平滑、可微版本。
它保留了ReLU在正区间的线性特性,但通过一条光滑曲线避免了ReLU在零点的硬拐角。
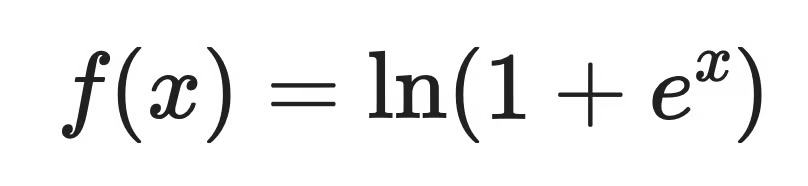
这条公式意味着三个特点
输出永远为正:非负输出在各种概率模型、计数模型中极其重要
每一点可导且导数连续:这对优化器来说是巨大加分项
负区间梯度永不为零:不存在死亡神经元
与ReLU的区别
二、为什么Softplus的导数是sigmoid?
对Softplus求导,会得到一个你非常熟悉的函数,Sigmoid函数。
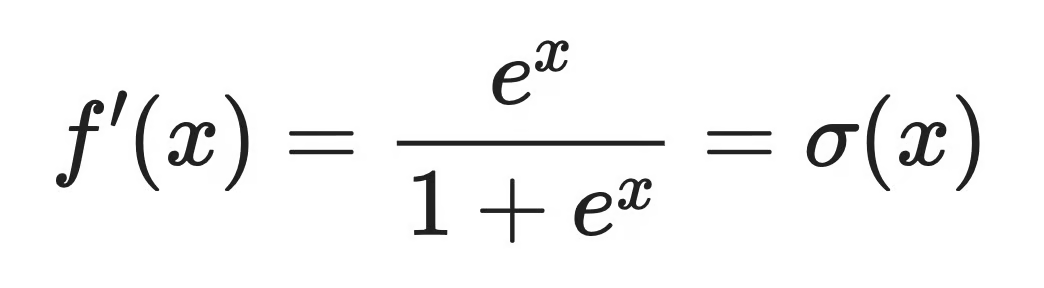
这意味着
- Softplus 的梯度在所有点都存在,而且从不为零
- 梯度在负区间仍有强度,可避免ReLU中的梯度冻结
- Softplus 是 sigmoid 的积分,因此其曲线形态稳定且具有良好的数学结构
对于强调梯度连续性、需要分析梯度方向的任务(比如物理模拟、概率建模),这一点尤其关键。
三、Softplus的数学结构:稳定优化的天然盟友
Softplus 的三个核心数学属性,让它比ReLU更适用于某些训练场景。
1. 无限可微性
Softplus 在所有点都是光滑的(无限阶可导)。这意味着
- 适合二阶优化(如 L-BFGS)
- 有利于构建光滑损失景观
- 更稳定的梯度下降路径
而 ReLU 在零点不可导,梯度骤变会影响优化器判断。
2. 数值稳定性:LogSumExp技术的天然产物
Softplus是两项LogSumExp的特例:
Softplus(x)=LogSumExp(0,x)
LogSumExp 是机器学习中著名的数值稳定技巧,被用在 Softmax、CRF、能量模型等结构。
换句话说,Softplus诞生于数值稳定性的核心数学结构中,这本身就使它在复杂概率模型中更自然。
3. 与熵(Entropy)的深层联系
Softplus的凸共轭是负二元熵,这链接到了统计学中的最大熵原理。
这让Softplus在以下任务中格外契合:
- Bayesian 模型
- 概率推断
- 能量模型(EBM)
- 强调不确定性估计的任务
ReLU 在这些领域完全不具备这种结构优势。
四、Softplus的核心优势:ReLU做不到,它能做
1. 再也不会“神经元死亡”
ReLU 的最大弱点是一旦输出被压到负区间,就有可能永远输出 0,梯度彻底断掉。
二Softplus永远不会输出0也不会产生零梯度,神经元不会死亡。
在浅层网络中,这能显著提升训练成功率。
量化对比:
x = -5时:
ReLU梯度 = 0
Softplus梯度 = Sigmoid(-5) ≈ 0.0067 (小但不为0)
2. 输出天然非负,适合正值约束任务
包括:
- Poisson 回归(统计计数)
- 光流/亮度估计(强度值不能为负)
- 概率模型中的 scale 参数
- 能量模型的正能量约束
不用再额外加 clip、ReLU、平方等操作。
3. 梯度连续,优化轨迹更稳定
如果你的任务对梯度质量敏感,Softplus会比ReLU更稳定:
- 潜变量模型(VAE)
- 测度学习、能量函数拟合
- 需要深度可解释性的敏感任务
- 连续控制
在这些场景中,Softplus 通常带来更快、更稳定的收敛。
五、为什么主流深度学习仍然偏爱ReLU?
不是因为Softplus不够好,而是ReLU足够划算。
1. 计算成本更高
ReLU只需要
max(0, x)
Softplus 需要:
- 指数
- 对数
- 防溢出处理
在大型模型中,可造成10%~25%的训练速度损失。
2. 没有稀疏性
ReLU的零输出产生了稀疏性,这提升了
- 模型训练速度
- 内存利用率
- 泛化能力
Softplus不会产生稀疏激活,全部神经元都在工作。
x = [-5, -10, -20]
ReLU输出: [0, 0, 0] → 稀疏度100%
Softplus输出: [0.0067, 0.000045, 2e-9] → 稀疏度0%
3. 社区惯性,90%的架构围绕ReLU设计
这意味着
- ReLU 的调参经验更丰富
- ReLU 的工程优化更强
- 大规模硬件对ReLU做过深度加速
Softplus生态远远不如ReLU胜任主流大规模任务。
六、PyTorch中的Softplus
- 1.基础用法
方式1 函数式API(推荐)
import torch
import torch.nn.functional as F
x = torch.tensor([-2.0, -1.0, 0.0, 1.0, 2.0])
y = F.softplus(x)
print(y)
y_beta2 = F.softplus(x, beta=2)
print(y_beta2)
方式2 模块类(用于nn.Sequential
import torch.nn as nn
model = nn.Sequential(
nn.Linear(10, 20),
nn.Softplus(),
nn.Linear(20, 1)
)
x = torch.randn(32, 10)
output = model(x)
print(output.shape)
2.核心参数:beta
数学定义
Softplus(x, β) = (1/β) * log(1 + e^(β*x))
参数作用
- β = 1:标准Softplus
- β > 1:曲线更陡峭,逼近ReLU
- β < 1:曲线更平缓,更平滑
实战案例
import matplotlib.pyplot as plt
import numpy as np
x = torch.linspace(-3, 3, 200)
plt.figure(figsize=(10, 6))
for beta in [0.5, 1, 2, 5]:
y = F.softplus(x, beta=beta)
plt.plot(x.numpy(), y.numpy(), label=f'β={beta}', linewidth=2)
plt.plot(x.numpy(), F.relu(x).numpy(), 'k--',
label='ReLU(参考)', linewidth=2)
plt.xlabel('x', fontsize=12)
plt.ylabel('Softplus(x, β)', fontsize=12)
plt.title('不同β值对Softplus的影响', fontsize=14)
plt.legend(fontsize=11)
plt.grid(True, alpha=0.3)
plt.show()
选择建议
生成模型(VAE/GAN):β=1,保持最大平滑性
速度敏感场景:β=2~5,接近ReLU但保留可微性
极端平滑需求:β=0.5,牺牲速度换平滑
3.常见应用模式
模式1 VAE方差参数化
class VAEEncoder(nn.Module):
def __init__(self, input_dim=784, latent_dim=20):
super().__init__()
self.fc = nn.Linear(input_dim, 256)
self.fc_mu = nn.Linear(256, latent_dim)
self.fc_logvar = nn.Linear(256, latent_dim)
def forward(self, x):
h = F.relu(self.fc(x))
mu = self.fc_mu(h)
logvar = F.softplus(self.fc_logvar(h))
return mu, logvar
encoder = VAEEncoder()
x = torch.randn(32, 784)
mu, logvar = encoder(x)
print(f"μ范围: [{mu.min():.2f}, {mu.max():.2f}]")
print(f"logvar范围: [{logvar.min():.2f}, {logvar.max():.2f}]")
模式2 强化学习策略网络
class PolicyNetwork(nn.Module):
def __init__(self, state_dim, action_dim):
super().__init__()
self.net = nn.Sequential(
nn.Linear(state_dim, 128),
nn.Softplus(),
nn.Linear(128, 64),
nn.Softplus(),
nn.Linear(64, action_dim * 2)
)
def forward(self, state):
output = self.net(state)
mu, log_std = output.chunk(2, dim=-1)
log_std = F.softplus(log_std)
return mu, log_std.exp()
policy = PolicyNetwork(state_dim=4, action_dim=2)
state = torch.randn(1, 4)
mu, std = policy(state)
action = torch.normal(mu, std)
print(f"动作: {action}")
模式3 概率层(正性约束
class ProbabilisticLinear(nn.Module):
"""输出必须为正数的线性层"""
def __init__(self, in_features, out_features):
super().__init__()
self.linear = nn.Linear(in_features, out_features)
def forward(self, x):
return F.softplus(self.linear(x))
prob_layer = ProbabilisticLinear(10, 5)
x = torch.randn(3, 10)
positive_output = prob_layer(x)
print(f"所有输出是否>0: {(positive_output > 0).all()}")
4. 性能优化技巧
技巧1 避免重复计算
def inefficient_forward(x):
y = F.softplus(x)
grad = torch.sigmoid(x)
return y, grad
def efficient_forward(x):
exp_x = torch.exp(x)
y = torch.log(1 + exp_x)
grad = exp_x / (1 + exp_x)
return y, grad
技巧2 混合使用
class HybridNetwork(nn.Module):
"""前面层用ReLU,关键层用Softplus"""
def __init__(self):
super().__init__()
self.features = nn.Sequential(
nn.Linear(784, 512),
nn.ReLU(),
nn.Linear(512, 256),
nn.ReLU(),
)
self.mu = nn.Linear(256, 20)
self.logvar = nn.Linear(256, 20)
def forward(self, x):
h = self.features(x)
mu = self.mu(h)
logvar = F.softplus(self.logvar(h))
return mu, logvar
技巧3 数值稳定版本
def stable_softplus(x, threshold=20):
"""手动实现数值稳定的Softplus"""
return torch.where(
x > threshold,
x,
torch.log1p(torch.exp(x))
)
x = torch.tensor([100.0, 1.0, -10.0])
print(f"PyTorch版本: {F.softplus(x)}")
print(f"稳定版本: {stable_softplus(x)}")
调试技巧
检查梯度流动
x = torch.tensor([-5.0, 0.0, 5.0], requires_grad=True)
y = F.softplus(x)
loss = y.sum()
loss.backward()
print("输入值:", x)
print("Softplus输出:", y)
print("梯度:", x.grad)
可视化激活分布
x = torch.randn(10000)
y_relu = F.relu(x)
y_softplus = F.softplus(x)
plt.figure(figsize=(12, 4))
plt.subplot(1, 3, 1)
plt.hist(x.numpy(), bins=50, alpha=0.7, label='输入')
plt.title('原始分布')
plt.subplot(1, 3, 2)
plt.hist(y_relu.numpy(), bins=50, alpha=0.7, label='ReLU', color='orange')
plt.title('ReLU输出(50%为0)')
plt.subplot(1, 3, 3)
plt.hist(y_softplus.numpy(), bins=50, alpha=0.7, label='Softplus', color='green')
plt.title('Softplus输出(无真零值)')
plt.tight_layout()
plt.show()
七、何时使用Softplus
推荐场景
1. 生成模型中的正性约束
VAE:方差/标准差参数化
GAN:判别器需要梯度惩罚时
Normalizing Flows:尺度参数必须>0
代码标志
logvar = self.fc_logvar(h)
sigma = torch.exp(0.5 * logvar)
2. 强化学习策略梯度
动作分布的标准差建模
连续控制任务的输出层
Actor-Critic架构的value函数
3. 贝叶斯深度学习
权重不确定性建模
变分推断中的参数化
预测置信区间估计
4. 需要二阶导数的优化
WGAN-GP的梯度惩罚
自然梯度方法
牛顿法、拟牛顿法
慎用场景
1. 超大规模网络(>1B参数)
计算开销累积显著
推荐:仅在关键层使用
2. 实时推理系统
对延迟极度敏感(如自动驾驶)
推荐训练用Softplus,推理换ReLU
3. 稀疏激活需求
需要大量零值优化内存
推荐使用ReLU或Leaky ReLU
4. 嵌入式/移动端部署
硬件对指数运算支持差
推荐量化后的ReLU
不推荐场景
1. 图像分类的卷积层
ReLU已足够好,无需额外平滑性
性能损失无对应收益
2. 文本处理的全连接层
Transformer架构通常不需要
GELU是更好的选择
3. 简单的回归任务
线性关系为主时,激活函数影响小
用ReLU即可
决策流程图
需要参数>0约束?
├─ 是 → 需要对该参数求导?
│ ├─ 是 → ✅ 使用Softplus
│ └─ 否 → 考虑exp()或ReLU
│
└─ 否 → 需要二阶导数?
├─ 是 → ✅ 使用Softplus
└─ 否 → 追求极致速度?
├─ 是 → 使用ReLU
└─ 否 → 两者皆可,ReLU更常见
一句话记忆
需要平滑就Softplus,追求速度用ReLU,生成模型和概率网络,Softplus是第一选择。



