想象你在训练一个天气预报模型,它预测明天下雨概率80%,结果真实概率是20%。
模型预测与真实世界的结果不一致,但如何量化这种错误?KL散度(Kullback-Leibler Divergence)正是解决这一难题的利器。
它不仅能告诉我们预测与真实之间有多大偏差,还能帮助我们优化模型、提高效率。
本文将从直觉、公式到实际应用,全方位解析KL散度,带你深入理解这一重要概念,掌握其在机器学习中的实际运用。
一、什么是KL散度?
KL散是用来衡量两个概率分布之间差异的统计量。
简单来说,它量化了模型预测分布(Q)与真实分布(P)之间“额外惊讶”,让我们知道模型错得多离谱。
举一个简单例子,假设你是天气预报员
你的预测(预测分布Q)
晴天概率:50%
雨天概率:50%
真实情况(真实分布P)
晴天概率:70%
雨天概率:30%
你的预测错了多少?
错误方法:直接相减,70%-50%=20%
正确方法:计算KL散度 = 0.0853 nats(稍后会计算)
为什么不能简单相减?
因为概率预测的错误不是线性的,比如把80%预测成20%,看似只误差60%,实则是两个完全相反的预测,灾难性错误。
KL散度考虑了这种非线性关系,它会根据真实概率给预测误差“加权”。
在机器学习中,KL散度的核心作用是:通过计算预测分布与真实分布的差异,帮助我们判断模型的有效性。
KL散度被广泛应用于模型评估、神经网络正则化、贝叶斯更新、数据压缩等多个领域。
KL散度的数学定义如下
离散情况:
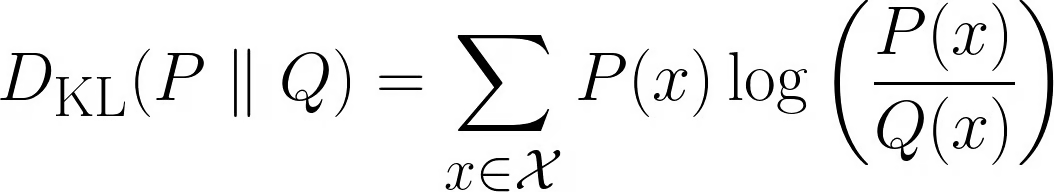
连续情况:
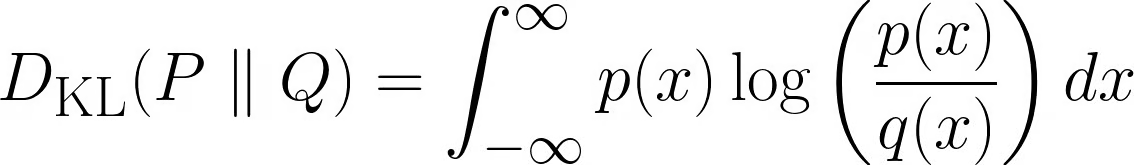
KL散度衡量了我们使用Q来代替P所造成的额外“惊讶”量。
二、KL散度的直觉理解
要理解KL散度,我们首先需要理解“惊讶”这一概念。
当我们预测某个事件时,实际的“惊讶”量与该事件发生的概率密切相关。
如果你猜中了硬币的正反面,你会感到惊讶吗? 答案是会,但并不会过于惊讶,因为硬币的正反面各占50%概率。
如果你猜中了骰子的点数呢?由于骰子有六个面,猜中点数的概率较低,所以你的惊讶程度会更高。
如果你猜中了彩票的中奖号码呢?这是最难的,概率极低,因此你的惊讶会更大。
在这些场景中,我们可以看到:事件的概率和“惊讶”成反比关系,事件的概率越低,惊讶程度越高。
惊讶度(Surprise) = -log(概率)
例如掷骰子
单次掷骰子概率:1/6
惊讶度 = -log(1/6) = log(6) ≈ 1.79 bits
连续3次掷骰子概率(相乘):1/6 × 1/6 × 1/6 = 1/216
惊讶度 = -log(1/216) = log(216) = log(6³) = 3×log(6) ≈ 5.37 bits
三、信息熵与KL散度
在机器学习中,除了单个事件的惊讶,我们更关心平均惊讶,即所有可能事件的预期惊讶值。
这就是信息熵(Entropy)的概念,信息熵定义了一个概率分布中,所有可能事件的平均惊讶。
信息熵的公式
H(P) = -∑ P(x) log P(x)
而KL散度实际上是通过比较真实分布P和预测分布Q的交叉熵来计算的。
交叉熵:用预测分布Q计算的惊讶
H(P,Q) = -∑ P(x) log Q(x)
KL散度:真实惊讶与预测惊讶的差异
D_KL(P‖Q) = H(P,Q) - H(P)
= ∑ P(x) log[P(x)/Q(x)]
假设你要传输英文字母,需要设计编码方案
真实频率P:
- 'e' 出现13% → 应该用短编码(如 '01')
- 'z' 出现0.1% → 可以用长编码(如 '11010110')
错误频率Q(你错误地认为所有字母等概率):
- 所有字母用相同长度编码(如5位)
用P设计编码:平均每字母4.2 bits(最优)
用Q设计编码:平均每字母5.0 bits(浪费)
KL散度 = 5.0 - 4.2 = 0.8 bits,每个字母多浪费0.8位
如果P和Q完全相同,那么交叉熵与信息熵相等,此时KL散度为0,表示模型的预测完美符合真实分布。
四、KL散度公式的推导与直觉
KL散度公式可以理解为:使用错误的分布Q来代替正确的分布P时,我们所付出的额外惊讶。
通过计算交叉熵与信息熵之差,KL散度量化了这种额外的代价。
假设我们有一个电影类型预测模型,真实分布P(x)和预测分布Q(x)如下:
KL散度可以通过公式计算
D_KL(P‖Q) = ∑ P(x) log[P(x)/Q(x)]
动作片
P(动作)=0.4, Q(动作)=0.3
贡献 = 0.4 × log(0.4/0.3)
= 0.4 × log(1.333)
= 0.4 × 0.288
= 0.115
喜剧片
P(喜剧)=0.3, Q(喜剧)=0.4
贡献 = 0.3 × log(0.3/0.4)
= 0.3 × log(0.75)
= 0.3 × (-0.288)
= -0.086
剧情片和恐怖片为0,总和:
D_KL(P‖Q) = 0.115 + (-0.086) + 0 + 0
= 0.029 nats (自然对数)
或
= 0.042 bits (对数底为2)
解释:
KL散度=0.029 nats
意思:用Q代替P,每次预测多付出0.029 nats的信息代价
如果预测100万次,累计损失= 29,000 nats
五、KL散度的Python实现
在Python中,我们可以使用scipy.stats.entropy来直接计算KL散度。以下是代码实现:
import numpy as np
from scipy.stats import entropy
P = np.array([0.4, 0.3, 0.2, 0.1])
Q = np.array([0.3, 0.4, 0.2, 0.1])
kl_nats = entropy(P, Q)
kl_bits = entropy(P, Q, base=2)
print(f"KL(P‖Q) = {kl_nats} nats")
print(f"KL(P‖Q) = {kl_bits} bits")
手动实现(理解原理
import numpy as np
def kl_divergence(p, q, epsilon=1e-10):
"""
手动计算KL散度
参数:
p: 真实分布(numpy数组)
q: 预测分布(numpy数组)
epsilon: 平滑系数,防止log(0)
返回:
KL散度(nats)
"""
p = np.asarray(p) + epsilon
q = np.asarray(q) + epsilon
p = p / p.sum()
q = q / q.sum()
kl = np.sum(p * np.log(p / q))
return kl
P = np.array([0.4, 0.3, 0.2, 0.1])
Q = np.array([0.3, 0.4, 0.2, 0.1])
kl = kl_divergence(P, Q)
print(f"手动计算 KL(P‖Q) = {kl:.6f} nats")
print("\n逐项贡献:")
for i, (p_i, q_i) in enumerate(zip(P, Q)):
contribution = p_i * np.log(p_i / q_i)
print(f"项{i+1}: P={p_i}, Q={q_i}, 贡献={contribution:.6f}")
```
**输出:**
```
手动计算 KL(P‖Q) = 0.029056 nats
逐项贡献:
项1: P=0.4, Q=0.3, 贡献=0.115173
项2: P=0.3, Q=0.4, 贡献=-0.086304
项3: P=0.2, Q=0.2, 贡献=0.000000
项4: P=0.1, Q=0.1, 贡献=0.000000
完整实战:模型评估
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import entropy
def evaluate_weather_models():
"""
比较三个天气预报模型的性能
"""
P_true = np.array([0.6, 0.25, 0.15])
models = {
"模型A(保守)": np.array([0.5, 0.3, 0.2]),
"模型B(激进)": np.array([0.7, 0.2, 0.1]),
"模型C(错误)": np.array([0.3, 0.3, 0.4])
}
results = {}
for name, Q in models.items():
kl = entropy(P_true, Q)
results[name] = kl
print(f"{name}: KL散度 = {kl:.4f} nats")
plt.figure(figsize=(10, 6))
plt.bar(results.keys(), results.values(), color=['green', 'yellow', 'red'])
plt.ylabel('KL散度 (nats)', fontsize=12)
plt.title('天气预报模型性能对比(越低越好)', fontsize=14)
plt.axhline(0, color='black', linewidth=0.5)
for i, (name, kl) in enumerate(results.items()):
plt.text(i, kl + 0.01, f'{kl:.4f}', ha='center', fontsize=10)
plt.tight_layout()
plt.show()
return results
results = evaluate_weather_models()
```
---
**数学证明(Gibb's不等式):**
```
D_KL(P‖Q) ≥ 0
等号成立当且仅当 P(x) = Q(x) 对所有x成立
```
**直观理解:**
```
"用错误分布"的代价 ≥ "用正确分布"的代价
当Q完美匹配P时,额外代价=0
六、KL散度的性质
KL散度具有以下几个重要性质
非负性:KL散度的值永远是非负的,只有当预测分布与真实分布完全一致时,KL散度为0。
单位问题:KL散度的单位取决于对数的底数。如果使用自然对数,单位是nats;如果使用以2为底的对数,单位是bits。
不对称性:KL散度不是对称的,即KL(P‖Q) ≠ KL(Q‖P),这意味着用P来逼近Q与用Q来逼近P所得到的散度值不同。
七、KL散度在机器学习中的应用
KL散度在机器学习中有广泛的应用,尤其在以下几个领域
模型评估:衡量预测与真实标签之间的差异。
变分推断:在变分自编码器中,最小化KL散度用于逼近后验分布。
强化学习:信任区域策略优化(TRPO)使用KL约束来保持策略更新的稳定性。
语言建模:比较生成的token与真实标签之间的差异。
八、KL散度的局限性与解决方案
KL散度虽然强大,但也有其局限性,尤其在以下几种情况
支持不匹配:当预测分布Q中某些值为0而真实分布P中对应值非0时,KL散度会趋向无穷大。为避免这种情况,我们可以使用平滑技术(如ε平滑)或改用Jensen-Shannon散度。
高维类别特征:当类别特征维度过高时,KL散度可能会受到稀疏数据的影响,导致估计误差。此时,可以通过合并稀有类别或使用贝叶斯平滑来解决。
非对称性:由于KL散度本身不具备对称性,有时可以考虑使用Jensen-Shannon散度来代替。
结论
KL散度是机器学习中的一个核心工具,它通过量化模型预测与真实分布之间的差异,帮助我们评估模型的表现并进行优化。
虽然它有一些局限性,但通过适当的技术和方法,KL散度仍然是处理许多问题的利器。



