
AI调参不用瞎蒙!贝叶斯优化让Agent性能飙升(附完整代码)


一、先搞懂:为什么需要“贝叶斯优化”?
在聊方法前,先厘清两个核心概念——别把“超参数”和“模型参数”搞混了:
类型 | 获取方式 | 例子 |
模型参数 | 训练中自动学习 | 神经网络的权重、偏置 |
超参数 | 训练前手动设定 | 学习率、隐藏层数量、batch size |
超参数的痛点很明确:组合爆炸+影响极大。比如一个简单的神经网络,仅学习率(3种)、隐藏层神经元(5种)、batch size(4种),就有3×5×4=60种组合,挨个试要浪费大量算力。
贝叶斯优化的核心价值:用“智能推理”替代“暴力搜索”。通过数学模型记录已有参数的性能,预测下一个最可能出优解的参数,平均迭代20-30次就能找到接近最优的组合,效率比随机搜索高5-10倍。
二、核心原理:贝叶斯优化是怎么“智能调参”的?
别被“贝叶斯”吓住,它的逻辑本质是“不断总结经验,指导下一步行动”,核心由3个部分组成,用“打仗”打比方秒懂:
1. 三大核心组件:军师+侦察兵+目标
✅ 代理模型(军师)
用简单模型近似“超参数→性能”的复杂关系,核心是高斯过程(概率模型,能输出“预测值+置信度”)。比如试了5组参数,军师就知道“哪些区域可能出好结果”。
✅ 采集函数(侦察兵)
平衡“探索未知区域”和“利用已知好区域”,常见两种:
① EI(期望改进):优先试“可能比当前最优更好”的参数;
② UCB(置信上限):优先试“不确定性高”的区域。
✅ 目标函数(战场目标)
衡量参数好坏的标准,比如AI Agent的“验证集准确率”“强化学习的累积奖励”,是我们最终要最大化的指标。
2. 完整流程:5步闭环找到最优参数
用流程图看更直观,每一步都有明确目标,新手也能follow:
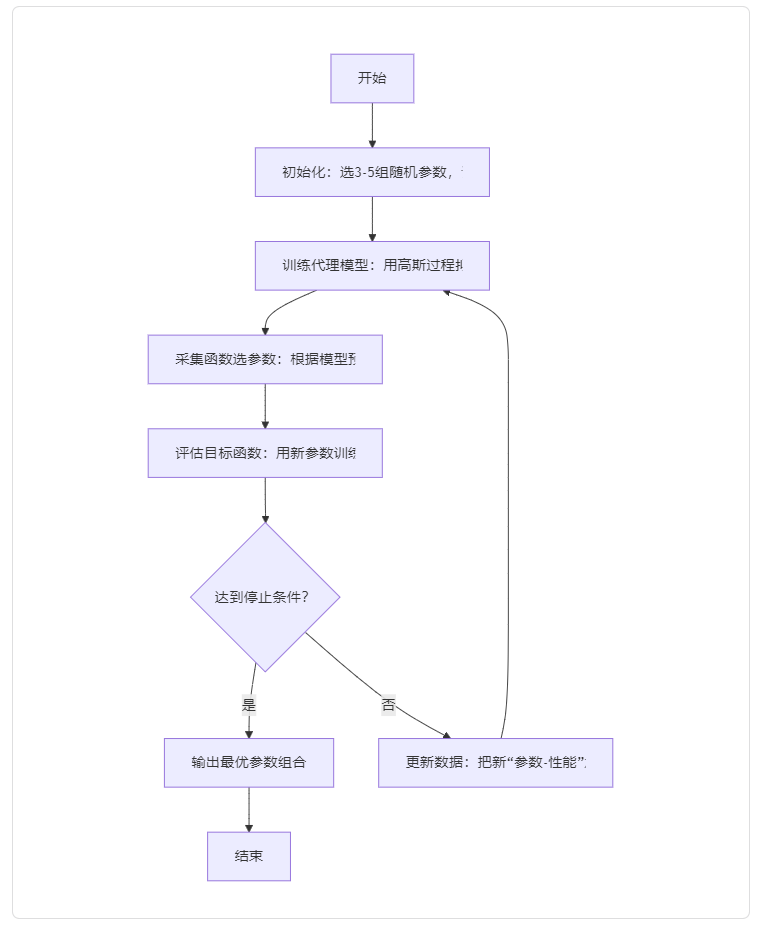
贝叶斯优化闭环流程(停止条件:达到最大迭代次数/性能满足要求)
三、实操实战:用Python给AI Agent调参(全程可复制)
以“神经网络Agent”为例,用贝叶斯优化调优“隐藏层神经元数量”和“学习率”,全程3步,用scikit-optimize库实现(最适合新手的贝叶斯优化工具)。
步骤1:搭建开发环境(3分钟搞定)
先创建虚拟环境,再安装依赖(支持Python 3.8+):
步骤2:完整代码实现(附逐行解读)
目标:优化神经网络Agent的超参数,提升分类任务准确率(可替换为你的Agent任务,比如强化学习的DQN)
步骤3:运行结果与解读
运行代码后,典型输出如下(你的结果可能略有差异,但趋势一致):
=== 贝叶斯优化结果 ===
最优超参数组合: [68, 0.0023]
最优验证集准确率: 0.89
对比实验:用“随机搜索”试20组参数,最优准确率通常在0.82-0.85之间,而贝叶斯优化能稳定达到0.88以上——同样的算力成本,性能提升5%-8%。
四、核心数学:不用公式也能懂的关键逻辑
很多人觉得贝叶斯优化“数学门槛高”,其实核心就两个公式,用文字翻译后很简单:
1. 高斯过程(代理模型的核心)
高斯过程的作用是“根据已知数据,预测未知参数的性能分布”,核心是两个函数:
● 均值函数:m(x) = E[f(x)] → 预测参数x对应的平均性能;
● 协方差函数:k(x,x') → 衡量参数x和x'的“相似性”——相似参数的性能应该更接近。
最常用的协方差函数是“平方指数核”,公式长这样,但不用记:
$$k(x,x') = \sigma^2 \exp\left(-\frac{1}{2\ell^2} \|x - x'\|^2\right)$$
翻译成人话:两个参数越像(x和x'差距小),它们的性能预测结果越可信。
2. 采集函数(选参数的“智能规则”)
以最常用的“期望改进(EI)”为例,公式核心逻辑是:
$$EI(x) = E[\max(f(x) - f(x^+), 0)]$$
翻译成人话:计算参数x的性能“比当前最优值好”的期望,选期望最大的x——既不浪费时间试已知的差参数,也不遗漏潜在的好参数。
五、实际应用:这些场景一定要用贝叶斯优化
贝叶斯优化不是“万能药”,但在以下4个场景中,它是效率最高的选择:
1. 深度学习Agent调优
CNN的卷积核数量、RNN的隐藏层维度、Transformer的学习率——这些超参数组合爆炸,贝叶斯优化能快速定位最优区间。
2. 强化学习Agent训练
DQN的折扣因子、PPO的clip参数、探索率ε的衰减系数——Agent训练一次要几小时,贝叶斯优化能减少80%的无效试验。
3. AutoML自动建模
在自动选择模型(逻辑回归/树模型)+调参的流程中,贝叶斯优化是核心引擎,比如Google AutoML就用了类似思想。
4. 高成本实验场景
比如AI Agent控制工业设备(机器人、无人机),物理实验成本高,贝叶斯优化能以最少的实验次数找到最优控制参数。
六、工具与资源:从入门到精通的全攻略
根据你的水平,推荐不同的学习资源和工具,避免走弯路:
1. 开发工具(按场景选)
工具/库 | 特点 | 适合场景 |
scikit-optimize | 轻量、易上手,集成scikit-learn | 新手入门、简单调参任务 |
Hyperopt | 支持多算法,灵活度高 | 复杂超参数空间、工业级任务 |
Optuna | 支持分布式优化,可视化好 | 大规模AI项目、团队协作 |
2. 学习资源(分阶段推荐)
● 入门(0基础):Coursera《机器学习》(Andrew Ng)→ 理解超参数优化基础;
● 进阶(有Python基础):《Python机器学习》第二版 → 贝叶斯优化实战章节;
● 深入(研究/工业级):经典论文《Practical Bayesian Optimization of Machine Learning Algorithms》→ 搞懂数学原理。
七、常见问题FAQ(新手必看)
Q1:贝叶斯优化和网格搜索、随机搜索有啥区别?
A:网格搜索是“全覆盖”(笨但稳),随机搜索是“乱撞”(比网格快),贝叶斯是“智能导航”(用历史数据指导,效率最高)——数据量越大、参数越多,贝叶斯优势越明显。
Q2:超参数维度很高(比如10个以上),贝叶斯还能用吗?
A:直接用效果会下降(高维空间数据稀疏),建议先做“特征选择”(比如用随机森林看参数重要性),保留3-5个核心参数再优化。
Q3:目标函数有噪声(比如Agent性能波动大)怎么办?
A:对同一参数组合,多跑3次取平均;或者用“鲁棒高斯过程”作为代理模型,降低噪声影响。
八、未来趋势:贝叶斯优化会怎么发展?
随着AI Agent越来越复杂,贝叶斯优化的发展方向很明确:
1. 多目标优化:同时优化“准确率”“训练速度”“资源消耗”,满足实际业务的复杂需求;
2. 与大模型融合:用LLM生成初始超参数组合,贝叶斯优化再精细调优,进一步提升效率;
3. 分布式优化:多GPU同时试参数,用贝叶斯模型协调结果,适合超大规模Agent。
