
当AI遇上食品安全,我们忽略了什么?


在人工智能为食品安全描绘出一幅主动防控、精准高效的宏伟蓝图时,一场静默的危机正在上演。数据无法流通,算法存在偏见,新型生物制剂的风险未知……这些隐藏在技术光环下的"暗流",可能正决定着这场变革的最终走向。当我们沉醉于AI能够实现84.1%预测精度的真菌毒素预警模型,或是99.09%识别率的农残检测系统时,更需要冷静思考:这些光鲜数字的背后,究竟隐藏着怎样的挑战与风险。
一、AI盛宴下的"数字巴别塔"
在食品安全领域,数据正被困在无数个孤立的"岛屿"上,形成了一座座难以逾越的"数字巴别塔"。从农田的种植数据、工厂的加工数据,到实验室的检测数据和物流的运输数据,它们分属不同主体,标准不一,利益交织,难以汇聚成一条有价值的数据河流。更严重的是,政府监管数据、第三方检测机构数据和企业自查数据之间存在着天然的隔阂,出于隐私、商业机密和合规风险的考量,各方的数据共享意愿极低。
这种数据割裂的直接后果,就是让AI模型陷入"营养不良"的困境。《人工智能辅助食品安全主动防控研究进展》明确指出,许多农业原材料来自数据意识薄弱的发展中或欠发达地区,若无法将这些地区纳入AI系统,算法的性能表现将大打折扣。当基于局部数据训练的AI模型被用于全局决策时,其准确性和可靠性都将受到严峻考验。这种数据孤岛现象不仅限制了AI能力的发挥,更可能让整个食品安全体系出现系统性盲区。
二、技术光环下的责任困境
当AI的决策开始影响从田间到餐桌的每一个环节时,其背后的伦理问题便无法回避。首当其冲的是算法偏见与公平性质疑。如果一个基于特定地区数据训练的AI模型被用于指导全国范围的食品抽检,它是否会系统性地忽略其他地区的特有风险?这种偏见可能导致监管资源分配不公,形成新的"安全盲区",让某些区域的消费者暴露在更高的食品安全风险之下。
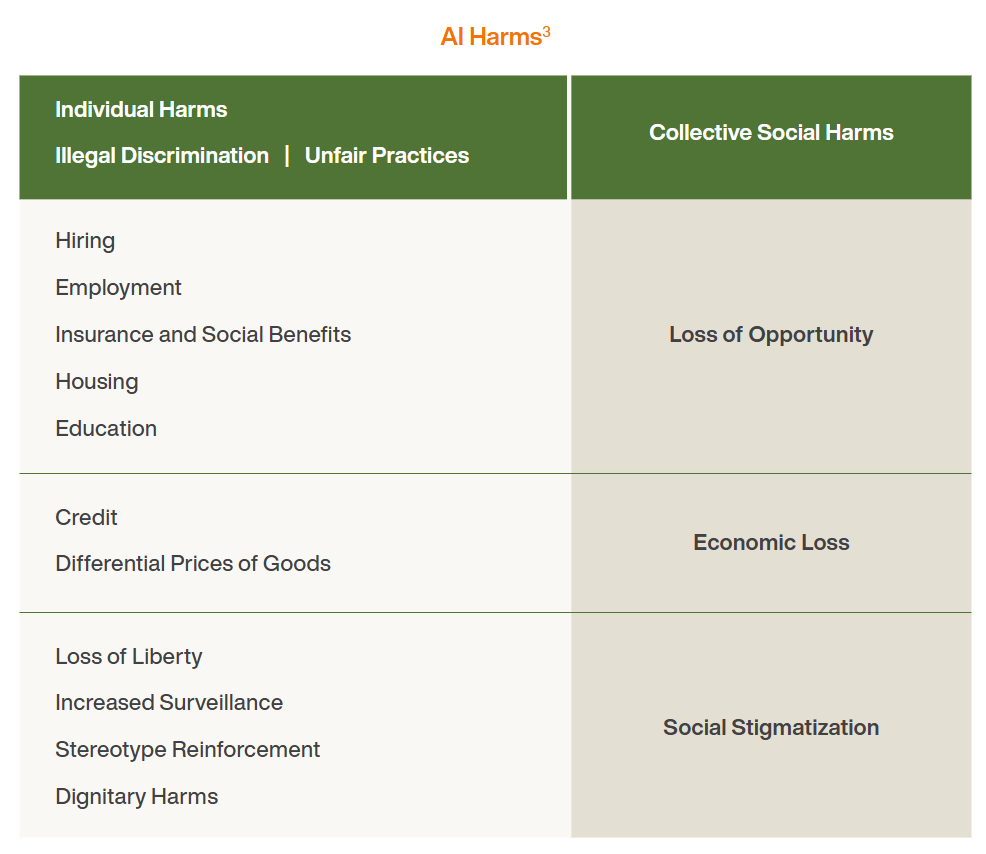 算法偏见危害
算法偏见危害
来源:《ALGORITHMIC BIAS》报告
更复杂的是责任界定的困境。如果一项由AI预测为"安全"的食品最终引发了安全问题,责任应该由谁承担?是数据的提供者、算法的开发者、模型的使用者,还是AI本身?这是一个法律与伦理的灰色地带。与此同时,"数字鸿沟"的加剧同样值得警惕。大型企业有足够财力部署先进的AI系统,而小农户、小作坊则被远远甩在身后。这种技术能力的落差可能导致市场垄断,破坏食品产业生态的多样性。
最具潜在风险的,或许是AI设计生物制剂带来的新型生物安全挑战。研究表明,AI正在用于从头设计抗菌肽、降解酶甚至噬菌体。这些由AI设计的"生防制剂"在环境中的释放,其长期生态影响和潜在风险目前仍是未知数。当我们欣喜于AI能够从海量微生物基因数据中预测出近百万种新的抗菌肽时,也必须思考这些新型生物制剂可能对生态平衡造成的不可逆影响。
三、如何构建可信赖的AI治理生态?
面对这些挑战,我们不能因噎废食,而应主动构建一个让技术健康发展、值得信赖的生态环境。在技术层面,隐私计算技术如联邦学习可以实现"数据不动模型动",在不交换原始数据的前提下共同训练AI模型,这能有效满足各方对数据隐私和安全的核心诉求。区块链技术的引入,则能通过其不可篡改、可追溯的特性,构建可信的数据交换与溯源链条。
在制度与标准建设方面,迫切需要建立数据标准与分级分类体系。由政府、行业协会牵头,制定非敏感数据的共享标准,并对核心数据进行分级分类管理,明确共享边界。同时,应当设立伦理审查委员会,在企业和科研机构内部推动建立针对AI应用,特别是涉及生物设计项目的伦理审查机制,将伦理考量前置。"监管沙盒"的探索也尤为重要,它能为创新的AI食品安全应用提供风险可控的"试验区",在严密监控下验证其有效性与安全性。
人才培养与共识构建是解决这些挑战的基石。我们亟需培养既懂食品科学、毒理学,又精通数据科学和AI伦理的跨界人才。同时,应该推动跨领域对话,组织技术专家、伦理学者、法律专家、监管官员和产业代表进行持续沟通,共同制定"负责任创新"的行业准则。《2025年食品安全检测行业发展现状研究》指出,建立严格的质量控制体系,避免因数据造假、检测失误等风险事件损害声誉,这需要所有参与者的共同努力。
人工智能在食品安全领域的征程,不应是一场蒙眼的赛跑。数据孤岛与伦理挑战,是我们必须穿越的险滩。在追求技术创新的同时,更需要建立相应的治理框架和伦理标准。唯有通过技术、制度与共识的三轮驱动,为这匹强大的"技术骏马"套上缰绳,我们才能真正驾驭其力量,确保这场变革的航船不会偏航,最终安全地抵达保障全球公共健康的彼岸。在这个充满希望又暗藏危机的时代,保持技术的锐意进取与人文的审慎反思,或许是我们最明智的选择。
