
如何评价Rich Sutton关于「LLM是死路」的观点?


不仅仅是Rich Sutton,是大佬们都转向了。
AI圈的"信仰"崩塌,是因为Scaling不是万能药……
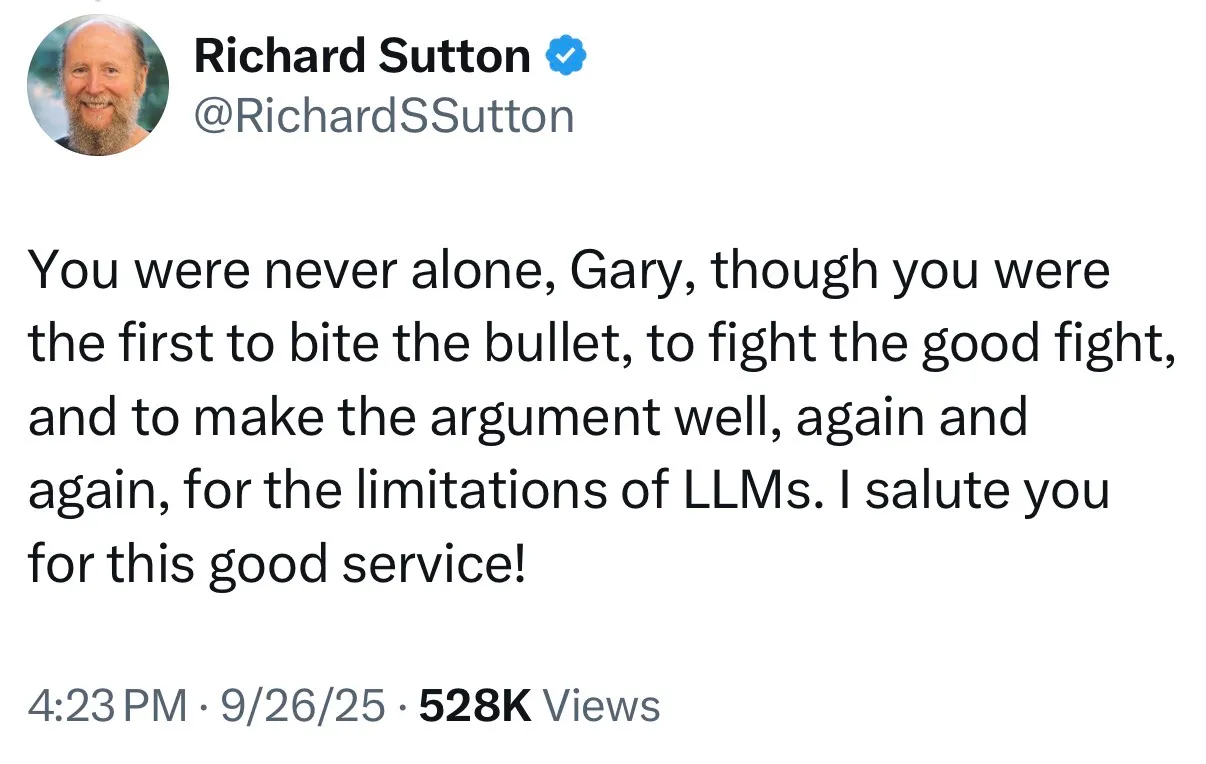
说实话,当我看到Rich Sutton——对,就是那个写了《苦涩的教训》、被LLM圈奉为"理论教父"的图灵奖得主,在2025年公开说"LLM到不了AGI,必须要世界模型"的时候,我人都傻了。
但又并不是这样!
 …
…
这就好比乔布斯突然说iPhone不行,或者马斯克说电动车是死路。你们能想象那种感觉吗
更离谱的是,Sutton现在的观点,和Gary Marcus这个从2019年就一直被LLM派喷的"老顽固"一模一样,以至于Marcus自己都说"可以直接搜索替换我俩的名字,观点完全重合"。
我看到这段的时候,下巴真的快掉下来了。
这不是一个人的转向,这是整个AI理论基础的地震。
让我慢慢给你们捋一捋这事儿有多炸裂。
大佬集体"叛逃":从LeCun到Sutton的思想转向
先上个时间表,你们感受一下这个"倒戈"的节奏:
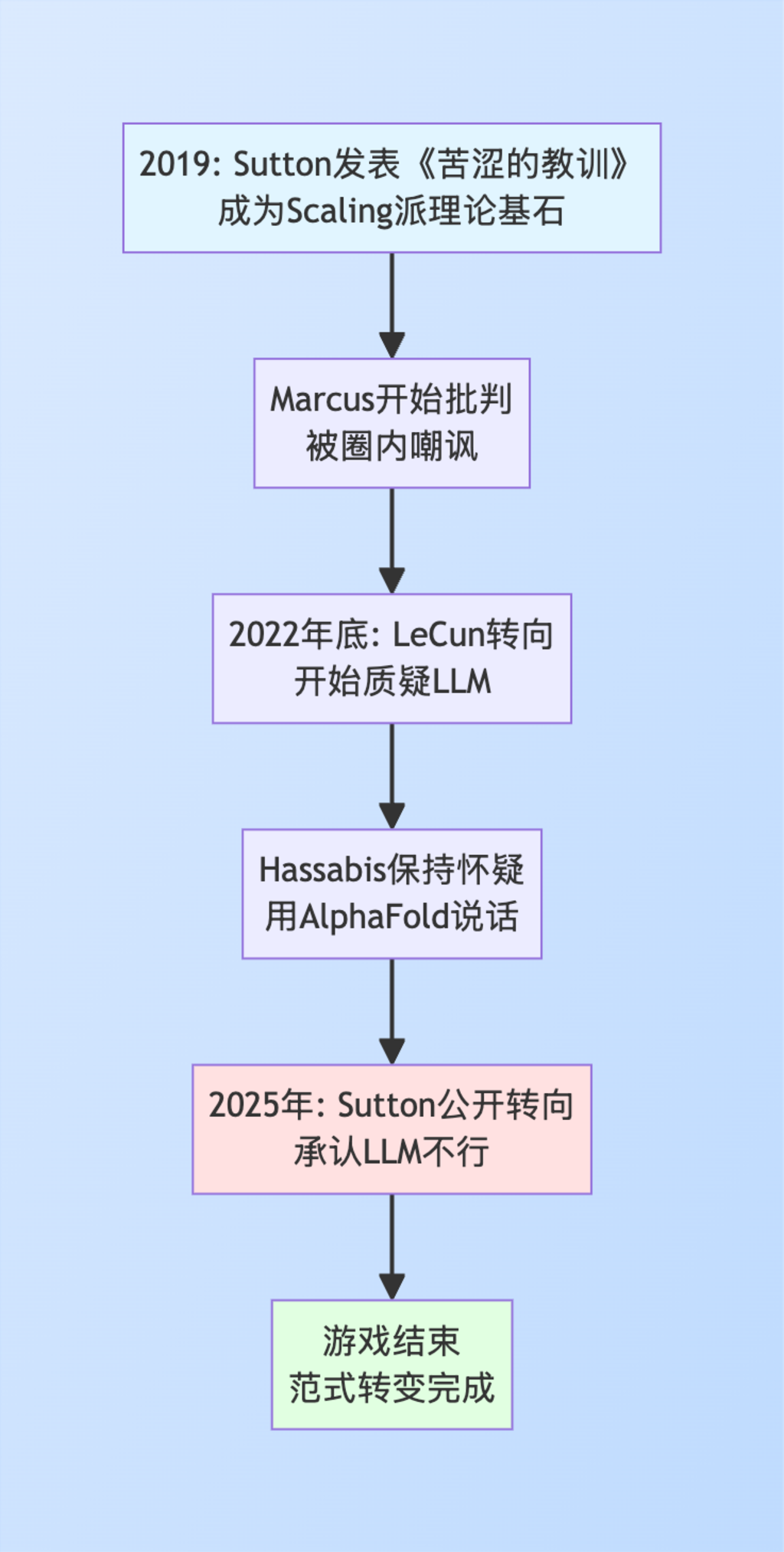
这个表格更直观:
大佬 | 转向时间 | 核心观点变化 | 江湖地位 |
|---|---|---|---|
Yann LeCun | 2022年底 | 从深度学习先驱→LLM怀疑者,搞能量基模型 | 深度学习三巨头之一 |
Demis Hassabis | 一直保持 | 用AlphaFold的混合架构"打脸"纯LLM | 诺贝尔奖+DeepMind CEO |
Rich Sutton | 2025年 | 从"Scaling万能"→"需要世界模型" | 图灵奖+强化学习教父 |
看到没?
一个接一个,圈内大佬都开始"叛逃"了。
现在还在死守"Scaling就完事儿了"的,基本都是有利益相关的。
要么是拿了投资的,要么就是Marcus说的"grifters"(骗子)。
Sutton的《苦涩的教训》到底说了啥?
这篇2019年的论文,但简直是LLM圈的"圣经"。
核心就一句话:
“AI进步总是来自Scaling(扩大计算规模),而不是手工工程。通用方法的巨大力量,能够随着计算增加而持续扩展。”
当时这论文一出,整个圈子都high起来。
什么算法优化、什么知识工程,统统靠边站,只管堆算力、堆数据就完事儿了。
但现在呢?
Sutton自己都说:“LLM到不了AGI,必须要世界模型。”
Marcus当时准备的皇家学会演讲PPT,早就把Sutton的例子怼得明明白白:
- Deep Blue:说是纯学习?人家用了一堆手工知识好吧!
- AlphaGo:强化学习+搜索+手工特征,哪里纯了?
Sutton的"纯Scaling"理论,本质上就是选择性失忆。
这些成功案例,哪个不是混合架构?
Gary Marcus这人,从2019年就开始批判LLM,结果被喷成啥样你们知道吗?
圈内人说他"不懂技术"、“跟不上时代”、“老古董思维”。
但现在呢?
Sutton的观点,和Marcus"可以逐字搜索替换名字"。
Marcus自己都说:“当LLM阵营失去了Sutton,游戏就结束了。”
我现在回头看Marcus这几年的文章,真的是字字戳心啊!
人家早就看穿了LLM的本质问题:
- 统计相关性≠因果理解
- 缺乏世界模型
- 需要embodiment(具身交互)
- 纯Scaling已经触顶
结果呢?
被嘲讽了6年,最后被证明是对的。 这何止是打脸,简直是把整个LLM圈按在地上摩擦。
LLM的"原罪":统计相关性永远跨不过因果理解的鸿沟
什么叫"范畴错误"(Category Mistake)?
这是Marcus和Sutton现在都认同的核心论点:LLM的问题不是工程问题,是因果问题。
打个比方:
- 用地图导航 vs 真正理解地理
- 背诵食谱 vs 真的会做菜
- 模仿人说话 vs 理解语言含义
LLM干的就是第一种事儿。
它再怎么Scale,也只是在"统计相关性"的圈子里打转,永远跨不进"因果理解"的门槛。
可以用一首打油诗总结(英文诗和油诗也押上韵了):
The world of bot / Is correlation But causal? NOT! / It’s mathsturbation 机器人世界,仅仅是交汇 而因果却非,乃数学自慰
这就是范畴错误——你拿着锤子,却想当螺丝刀使。
再大的锤子,也不可能拧螺丝。
可以看看两个经典失败案例:Hanoi塔和国际象棋
有人可能会说:“不对啊,LLM不是很强吗?”
强是强,但是你试试让它干这两件事:
案例1:Hanoi塔问题
- 这个经典递归问题,需要理解规则并执行
- LLM怎么做?只会模仿训练数据里的解法
- 结果:稍微变个形式,立马歇菜
案例2:国际象棋
- LLM会产生非法走法
- 为啥?因为它不是"理解规则",而是"记忆模式"
- 训练数据里没见过的局面,立马露馅
LLM不思维也不模拟思维。
它们充其量是模仿思维,就像那些模仿树叶的昆虫——能骗鸟,但没鸟用,永远不能光合作用。
你可以骗过人类评委,但你骗不过物理规律。
所以世界模型≠潜在空间。
有些人会反驳:“LLM有潜在空间啊,那不就是世界模型吗?”
兄弟,这是严重的误解。
潜在空间只是统计嵌入,不是因果理解。
就好比:
- 你背了1万道数学题的答案
- 但你不理解数学原理
- 遇到新题型,你就傻眼了
"世界模型"这个词本身可能就是矛盾的。
为啥?因为:
- 所有训练数据都是人类捕获的(文本、图像、视频)
- 观察视频≠理解物理(不然要实验室干嘛?YouTube不就够了?)
- 真正的基础知识不需要符号(婴儿、猫、蝴蝶都没语言,照样活得好好的)
说白了,LLM永远只能是"二手知识",没有"一手体验"。
这就是为什么LLM永远没法原创,也没法当马前卒!
因为本身就是中介,而非前亦非后。
只能:以色事他人,能得几回好。
Embodiment(具身性):为什么"无身体的大脑"到不了AGI?
真实的世界模型需要embodied知识吗?
人类学习大部分来自交互和反馈,而不仅仅是观察。
AI作为’无身体的大脑’,能否以有意义的方式理解世界?”
这问题直击要害。
想想人类是怎么学的:
- 小孩学"热":手摸火,烫!
- 学"重":提东西,累!
- 学"疼":摔跤,哭!
这些都是"一手体验",不是"看视频"能学会的。
真相则是我们的大脑不计算,不编码,而是让物理自然工作,产生我们可以检测的「信号」。
这就是embodiment,这就是为什么它如此强大。”
不知道有没有人听过,我之前忘记在看的,巨精辟:
Bots are “embottied” but not “embodied”(机器人是"瓶装化"的,而非"具身化"的)

有人会反驳:“那海伦呢?她又盲又聋,不也有世界模型吗?”
好问题!
但这恰恰证明了embodiment的重要性:
Helen Keller虽然缺视觉听觉,但她有:
- 触觉:通过手摸索世界
- 嗅觉、味觉、加速度感:其他感官补偿
在《奇迹创造者》电影里,她把水的感觉和ASL手势联系起来的那一刻,理解之门才打开“世界模型构建是个连续体,不是非黑即白。
部分embodiment可以建模,只是颗粒度低一些、校准慢一些。但完全没有embodiment?那不可能建模。
LLM连"部分embodiment"都没有,它就是个纯文本统计机器。
其实我们不是通过感知来理解,而是通过智能功能,包括伴随感知的想象力。
形式本身是不可感知的,就像我们的内在对话是不可感知的。你现在的思考不是可感知的,尽管你在思考。
也就是感知是必要条件,但不是充分条件。
但LLM呢?连必要条件都不满足! 它没有感知,只有统计。
语言的局限:巧克力的味道无法用文字模拟。
想象一下:
- 小猫呼噜声的感受
- 医院氧气管的冷空气
- 从未尝过巧克力的人,你怎么描述?
“Words fail me”(语言无法形容)——这不是夸张,是事实。
没有世界感觉,LLM可以预测文字,但会严重偏离,变成无意义的胡言乱语。因为词语不与感官连接。
可以让LLM生成音乐和弦,创造"童年恐怖电影的欢乐惊恐"感觉。
结果呢?
因为LLM没有感觉"库",它是不知道什么叫"恐怖但欢乐"。
对比一下:
人类理解 | LLM处理 |
|---|---|
直接感官体验 | 语言统计模式 |
想象力和智能功能 | 像素/数据表示 |
可理解的形式和关系 | 数学相关性 |
两条平行线,永远不相交。
有人会说:“那Stephen Hawking呢?他几乎不能动,不也是伟大物理学家吗?”
好问题!
但这恰恰证明:问题不在于身体,而在于世界模型。
Hawking能做物理,因为:
- 他有数学推理能力(这是符号逻辑)
- 他有因果思考能力(这是世界模型)
- 他能访问物理教科书(这是知识传承)
LLM缺的不是身体,是因果推理和世界模型。
Scaling神话的终结:为什么"堆算力"不灵了?
自去年的’reasoning at scale’以来,一切都只是脚手架。现在没有传闻任何关键突破。
什么意思?
就是LLM已经到天花板了,现在只能靠"外挂"凑合。
连LLM的辩护者Oleg Alexandrov都承认:
“一旦数据覆盖了问题空间,神经网络被拟合,它就不能为你做更多。需要大量增强机械装置——验证管道、工具集成、知识处理引擎、形式化验证器。”
LLM本身不行了,得靠一堆"外挂"救场。
功耗数据更吓人。看看这个对比:
LLM能耗 >> 比特币挖矿能耗
比特币挖矿,都已经是肉鸡加成,「全民」挖「坑」。
AI功耗也是相形见绌。
更讽刺的是,这些公司现在居然开始投资核聚变了。
为啥?因为他们知道电不够用了。
在美国,这些可怕的数据中心会榨干美国电网,破坏环境。
当算法突破出现,这些基础设施全成废铁。而这100%会发生,因为任何懂技术的人都知道当前问题有算法解决方案。
相当于是:
- 人类大脑:24瓦
- LLM:兆瓦级+
谁更高效?
一目了然。
相当于是花了一个国家的钱养了一个残疾的昏君。
现在已经到了强化学习也救不了LLM……
Sutton转向后,提出了新方案:OaK(options-based learning from experience)框架,强调强化学习。
这是用一个童话替换另一个童话。
强化学习有充分记录的根本缺陷:深度样本低效、奖励黑客、分布转移下的灾难性脆弱。
OpenAI的o1就是典型例子:
- 把RL层叠在LLM上
- 产生所谓的"思维链"推理
- 但本质是什么?有界优化的幻象,不是真正因果推理
这是叙事工程的杰作,而非科学突破。
o1就是个"套壳",换汤不换药。
毕竟现在AI悲剧已经发生了!
聊天机器人导致孩子自杀,然后呢?
就没有然后了……
还有Altman说:
“如果GPT-8解决了量子引力,我们就知道它是AGI了。”
这都是走上不归路了。
还有个经典案例,就是LLM"超越"医生诊断罕见病的新闻。
医生只能靠个人经验。
但LLM很可能可以访问题库数据库——这是不公平优势。
很多媒体根本没提这个关键问题。
这是"开卷考试vs闭卷考试"的对比。
其实没啥好吹的?
所有这些钱本可以投入医疗保健、高速铁路、超音速飞行、核电、海水淡化——所有改善生活的有形东西。
但他们都不会这样做,10年后也不会。
因为AI既有造福的一面,也有高强融资的一面。
当所有投资贬值并拖垮股市时,代价会是什么?
我们可能正处于AI泡沫破裂的时刻,后果远超少数公司失败。
历史类比很清楚:收费公路、运河、铁路、互联网——所有这些都经历了炒作、繁荣、破产,然后真正价值才出现。
AI泡沫,可能比你想象的更快破裂。
正确的路:混合架构才是王道
DeepMind的AlphaFold为啥成功?因为它不是纯LLM。
每当DeepMind搞出新能力,它都是符号+程序+神经网络的混合系统。
换句话说,就是[计算]。我们过去60年一直在做的事。不是第二次降临。
AlphaFold的架构:
组件 | 作用 | 为什么重要 |
|---|---|---|
符号推理 | 处理蛋白质结构规则 | 保证逻辑正确 |
程序化逻辑 | 编码生物化学约束 | 符合物理定律 |
神经网络 | 模式识别和优化 | 处理复杂数据 |
验证机制 | 确保输出合规 | 质量保证 |
纯LLM有这些吗?没有。
最后,Marcus vs Sutton:分歧与共识
现在Marcus和Sutton在问题诊断上完全一致:
- 需要世界模型
- 纯预测不够
- LLM到不了AGI
但在解决方案上有分歧:
Sutton的路线: 强化学习为主
- 优势:可以在交互中学习
- 劣势:样本低效、奖励黑客、容易崩
Marcus的路线: Neurosymbolic(神经符号混合)
- 优势:可验证、可解释、有先天约束
- 劣势:需要手工设计一些结构
Marcus总结得特别务实:
“也许他对,也许我对。很可能两者都需要一些。 只需当前LLM投资的一小部分,我们就可以验证。”
这才是科学态度——实事求是,不吹牛逼。
最后的最后《苦涩的教训》被误解了?重读Sutton的真实意思
这得聊聊元方法vs具体方法了。
Sutton不是倡导盲目Scaling。他倡导的是元方法——能够发现和捕获任意复杂性的方法。
Sutton原话:
“心智的实际内容是巨大的、不可救药地复杂的。我们应该停止试图找到关于心智内容的简单思考方式。应该内置的是元方法,而不是具体发现。 我们想要能像我们一样发现的AI,而不是包含我们已发现内容的AI。”
这话啥意思?
别把具体知识硬编码进去,而是给AI"学习能力"。
但问题是:"学习能力"本身,也需要先天结构。
这就是Marcus说的"先天约束"。
Doug Lenat的《自动数学家》是最伟大的AI博士论文之一。
但他从困难问题逃跑了,转向简单无用的手工知识编码,浪费了40年。
Cyc项目想干啥?把所有常识都编码成规则。 结果呢?
彻底失败。 因为常识太复杂了,根本编不完。
但LLM走了另一个极端:什么都不编码,全靠统计。
结果也不行。
正确答案可能在中间:一些先天结构+自主学习能力。
对于纯LLM作为AGI之路,是的,游戏结束了。
当理论奠基人集体转向,当大佬们都承认问题时,死守"Scaling万能"的,要么是利益相关,要么就是骗子。
真正的问题在前面:
- 构建具有世界模型的系统
- 实现因果推理能力
- 解决embodiment问题
- 找到人机协作的正确方式
