
Andrej Karpathy 的新项目nanochat有多牛?


一个让人破防的真相,就是人家全程手写了一个AI。
Claude code和Codex agents压根too yung too simple。
这项目实在是too far off the data distribution。
感觉就像是:一个大佬用蘑菇打败了人家蘑菇云……
大佬Karpathy花了$100训练AI才发现,其实最需要AI帮忙的时候,它反而最没用。
$100和4小时就能训练出ChatGPT级别的对话模型,全球各大社区直接炸了。
有两个关键点:大佬透了一波代码,而AI工具在最需要它的地方,反而最拉胯。
这揭示了一个让所有AI炒作者都不想承认的悖论:
工具效能数据分布匹配度任务复杂度理解深度AI工具效能=f(数据分布匹配度,任务复杂度)×理解深度
这又回归到一个历史难题。
外行人看到程序员,都不禁暗笑以及大笑的话:你怎么不去送外卖?你这迟早被淘汰的玩意……
(真有这样的人讲过这样的话,然后他上班时,只要有一个Coder,是绝对联网都连不上并且经常蓝屏,且找不到IT部同事解决的)
其实大佬Karpathy这一手活,正好讲明白了编程思维以及代码原理的第一性,大模型不过是工具。
也正好给那些老以为Coder被替代的自媒体以及SD一个大13兜,最晚淘汰的永远是Coder……
因为你在用的AI是Coder写的。
为什么要花$100训练一个"幼儿园
明明已经有GPT/Claude这样强大的模型!
这不是浪费时间和金钱吗?
这是为了让人更了解AI,因为训练(Training)和推理(Inference)是两个完全不同的过程:
训练阶段是需要大量GPU算力 、时间长(几小时到几个月)、成本高(几千到几百万美元)、一次性投入,而结果是模型权重。
推理阶段是相对少的算力,且时间短(毫秒到秒级)、成本低(每次几美分到几美元),是按使用付费,最终结果是文本输出。
通过$100的训练项目,你会真正理解:
- 为什么API调用这么便宜
- 为什么训练自己的模型这么贵
- 何时应该自己训练,何时应该调用API
- 云服务商的定价策略
也就是从0到1 理解数据分布和能力边界。
NanoChat训练4小时后,问它:“天空为什么是蓝色?”
模型的回答(原话):
The blue color of the sky is an optical illusion caused by the scattering of sunlight by tiny blue and violet particles in the atmosphere
(天空的蓝色是一种视错觉,由大气中微小的蓝色和紫色粒子散射阳光引起的)
分析:
错误点 | 正确答案 | 模型的误解 |
|---|---|---|
optical illusion | Rayleigh scattering是效应,不是幻觉 | 混淆了概念 |
tiny blue and violet particles | 空气分子散射蓝光,不是有蓝色粒子 | 完全错误的物理理解 |
整体 | 瑞利散射:短波长光(蓝紫)散射更强 | 训练数据不足导致知识不可靠 |
当然nanoGPT只是为了展示训练4小时的模型可以模仿对话形式,但实际上离真正有用还差得远)。
这正是教育的目的,清醒认识现实,而不是沉浸在炒作中。
这就是$100买不到的教育价值:
直接使用GPT | 从零构建LLM($100) |
|---|---|
快速获得结果 | 深入理解原理 |
黑盒思维 | 第一原理思维 |
依赖工具 | 掌握方法论 |
工具变了需重学 | 原理不变可迁移 |
被炒作影响 | 清醒认识现实 |
短期效率 | 长期竞争力 |
在AI时代,理解构建原理比盲目使用更重要,因为:
- 理解让你知道何时使用、如何使用、何时不用
- 理解让你避免被炒作误导
- 理解让你在工具变化时保持竞争力
- 理解让你从消费者变成创造者
这正是从"$100训练幼儿园模型"中学到的最有价值的东西。
那很多人会疑问,怎么不用Claude code/Codex ?
可能1小时就搞出来了……
真的笑话……
听听Karpathy对Claude code/Codex 的评价:没什么卵用……AI炒作的直接批判……对AI局限性的无奈……
AI工具,很有用,例如Copilot自动补全CRUD表单(真香现场),正在写数据库增删改查表单。
基本上一开始输入第一行代码,GitHub Copilot直接就识别出他要干啥了,自动补全了整个表单结构:
- 数据模型定义
- 表单验证逻辑
- 数据库操作函数
- 错误处理代码
但对于精明的Coder,其实这不是简单的代码补全,而是理解了你的意图后的智能生成。
CRUD操作是Web开发中的"万年老梗",训练数据里到处都是模式高度标准化,变化空间有限,属于"高频模式、常
见框架、标准实现"的核心舒适区,这就是AI的主场啊!
说AI无用,像Karpathy手写NanoChat代码(打脸现场),NanoChat这个教育项目的目标很明确:用$100在4小时内训练一个基础对话模型。
听起来简单,实际涉及:
- 从零搭建LLM训练pipeline
- 优化单8XH100节点的分布式训练
- 自定义tokenizer和数据处理流程
- 在$100预算约束下的极致优化(这个最变态)
你以为Karpathy没用AI工具吗?
是用了,真的没用……
试了好几次用Claude code和GPT5-Codex辅助开发,Claude code用来写方向或搭建架构吧,不行;GPT5-Codex
直接搞吧,也不行。
这明显是超纲了……
等于是叫上帝变一块自己举不起的石头。
因为结果发现,AI建议的代码完全不适用于这个特殊场景,引入了一堆不必要的依赖或低效实现,根本理解不了"$1
00预算约束"这个特殊context。
总之反而增加了理解和修正的工作量,属于帮倒忙。
「repo is too far off the data distribution」(repo 与数据分布相距太远)。
这句话直接指出了问题根源,这二者隔了一个「银河」,是人与大模型之间的距离,而不是大模型与大模型之间的
距离,这中间隔了一个「大佬」,这「大佬」却是银河。
NanoChat已经超纲了,因为它是训练数据中根本就缺乏类似的代码模式,AI没法"学习",因为从未见过的架构设
计,独特约束(比如极致成本控制)完全超出AI的理解范围。
完全手写代码,只用tab补全。手写速度反而比跟AI来回扯皮更快,代码质量和控制力更强,还能避免了AI引入的技
术债务。
everything I do is just too far off the data distribution,这句话引发了广泛共鸣。
真实的、有价值的项目往往都是独特的,而这恰恰是AI工具的盲区。
很多人都会问,明明长得一样?
为啥同一技术(LLM驱动的编码工具)在不同场景表现差异这么大?
答案不在于工具本身质量有问题和使用者技术水平差异。
真正的原因是任务特性与训练数据的匹配程度,这就是"数据分布"这个概念的关键意义所在。
数据分布这道看不见的墙
LLM是通过学习大量代码的统计模式来工作的。
要搞懂"数据分布",得先理解几个关键概念:
- 向量空间映射:LLM把所有代码都映射到高维向量空间里,相似的代码模式在空间中是相邻的
- 分布内:跟训练数据很像,在向量空间的高密度区域(AI的舒适区)
- 分布外:训练数据中罕见或根本没有,在向量空间的稀疏区域(AI的盲区)
生成过程的真实本质:
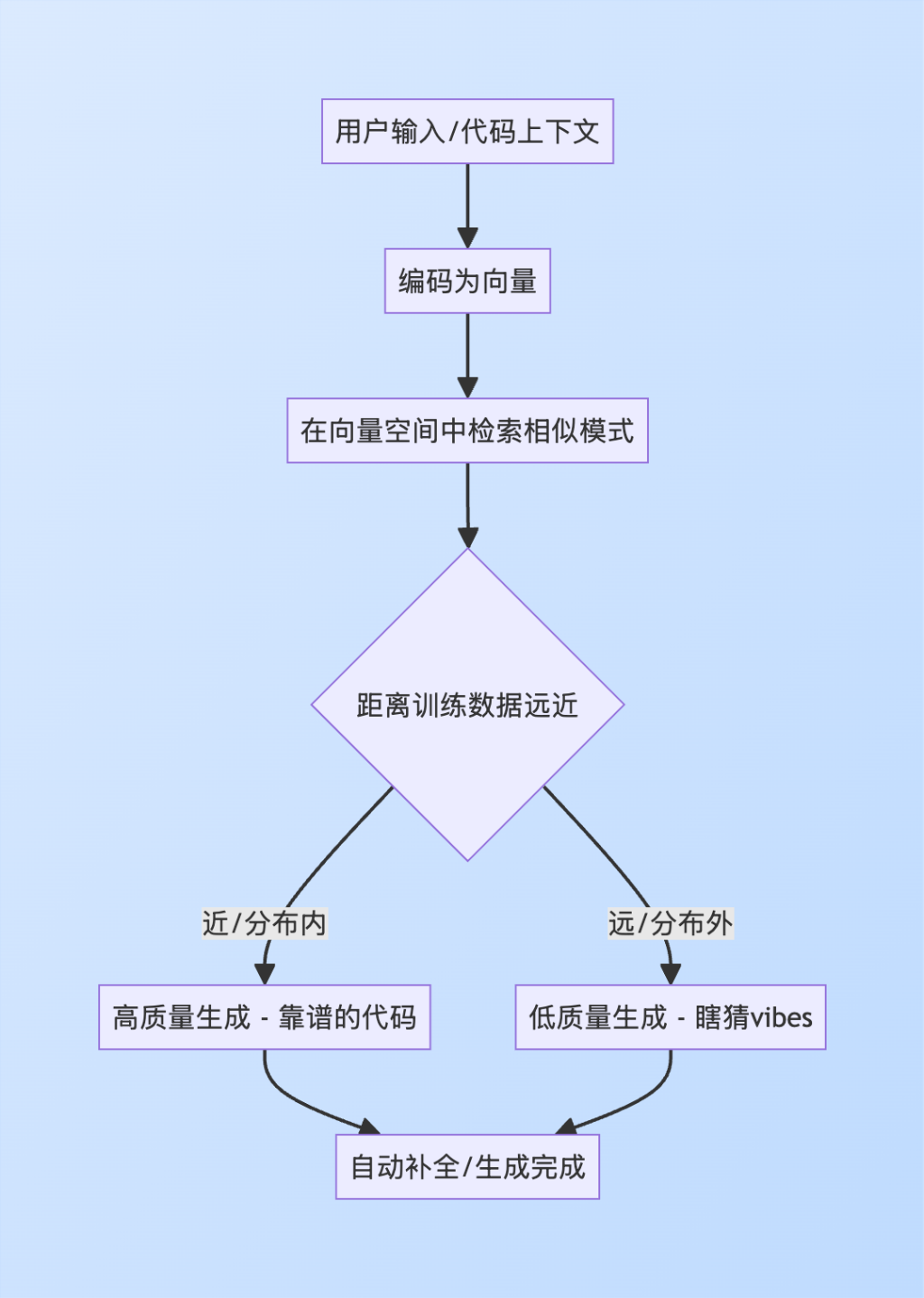
LLM并不是真正"理解"代码,而是在高维空间里做相似度检索和统计组合。
距离训练数据越远,生成质量越不可控,这就是"vibes"的来源——不是基于逻辑推理,而是基于统计模式的"感
觉"。
说白了就是瞎猜,本质还是概率。
就是盲拳打死老师傅,项目一定要老项目,新项目,就成了老师傅被蹂躏。
以下这些场景AI工具表现真香:
场景类型 | 典型案例 | 为啥有效 |
|---|---|---|
标准Web框架 | React hooks、Express路由 | 训练数据里到处都是示例 |
CRUD操作 | 数据库增删改查 | 最常见的开发模式,闭着眼都能写 |
算法题 | LeetCode标准解法 | 高度结构化,变化有限 |
常见UI组件 | 登录表单、导航栏 | 模式固定,实现标准 |
代码重构 | 风格修复、性能优化 | 大量before/after训练数据 |
实际案例(分布内的高效场景):
- 标准REST API实现:GET/POST/PUT/DELETE的标准套路
- 流行框架的典型用法:比如React的useState、useEffect
- 数据库ORM操作:Sequelize、TypeORM的标准查询
- 代码风格修复:ESLint规则自动应用
在这些场景中,AI工具的价值主张很明确:减少重复劳动,让你专注于业务逻辑而不是写样板代码。
AI工具的崩溃边界——分布外场景,NanoChat不是普通的Web应用或算法实现,而是一个高度专业化的LLM训练系统:
- 架构独特性:
- 自定义的分布式训练pipeline
- 针对单8XH100节点的极致优化
- 非标准的数据处理流程
- 创新的成本控制策略
- 训练数据稀缺性:
- 从零构建LLM训练系统的代码极少
- $100预算约束是独特需求
- 4小时训练目标需要特殊优化
- 这些组合在训练数据中几乎不存在
当Karpathy尝试使用最先进的AI编码助手时:
- AI的建议模式:
- 倾向于使用成熟的、"过度工程化"的库
- 推荐标准但低效的实现方式
- 完全理解不了极端成本约束
- 生成的代码偏离项目核心目标
- 具体失效表现:
- 建议使用昂贵的云服务(预算直接爆炸)
- 推荐复杂的框架(增加依赖和开销)
- 忽略了"4小时快速训练"的核心约束
- 代码需要大量修改才能用
Karpathy也是没办法,只能纯手打(又押上韵了)。
复杂场景当中,AI也是无能为力。
当你最需要帮助时,AI最帮不上忙。
因为独特架构设计 → 训练数据无先例 → AI无效,又因为领域特定问题 → 训练数据覆盖不足 → AI受限,关键是研究性探索 → 本质上无先例 → AI无能。
一言以蔽之:因为没有,所以不行。
数据分布问题本身只是技术局限,但当这个局限遇上过度炒作,就产生了破坏性后果。
Karpathy也扯了大模型的泡沫,很多以为简单prompt → 完整应用。
油管上Semi-technical 做了大量"震撼"视频,输入简单的自然语言描述、AI瞬间生成完整的Web应用、界面看起来
完整可用,基础功能可以演示等等。
反正看的人都觉得UI完整,布局合理,基础的用户交互可以响应,能够完成5分钟的视频演示。
但是问题多多,如功能性、安全性、性能、分布等问题。
最重要的是责任真空问题,出了问题,谁来修BUG?
没有可指责的开发者,没有人对代码质量负责。
真出问题时,是无人理解代码逻辑,导致维护成本远超预期……
现实需求对比:
YouTube演示 | 实际开发需求 |
|---|---|
一次性生成 | 迭代式开发 |
无测试 | 完整的测试套件 |
Demo级别 | 生产级别 |
单次prompt | 长期上下文窗口 |
炫技 | 可维护性 |
AI工具在当前阶段最准确的定位是可工作的原型生成器,而不是生产就绪代码生成器。
绝大多数真实开发者需要AI工具在长期上下文窗口和多次迭代中工作
目前投资界和科技巨头的期望:
- 需要能产生"trillions of dollars"的产品
- 预期"create mass unemployment"
- 认为可以替代大部分编程工作
现实情况:
- AI工具只能在有限场景下提升效率
- 复杂项目仍需人类深度参与
- 创造力和判断力无法替代
- 支出与实际产出存在巨大差距
讲回有外行总以为:AI可以完全取代开发团队,那可是完全忽视了软件开发中人的核心价值。
AI编码工具到底是个啥?
想起以前上学时的VB6,20世纪90年代,可视化编程工具达到了繁荣的顶峰。
这些工具承诺让编程变得"像拖放一样简单"。
Visual Basic 6:
- 拖放式界面设计
- 事件驱动编程模型
- 可视化的控件库
- 双击按钮就能写事件处理代码
Delphi:
- 更强大的原生性能
- 数据绑定组件
- 完整的数据库支持
- 专业级的可视化开发
HyperCard(Apple出品):
- 教学友好的原型工具
- 脚本语言(HyperTalk)
- 卡片和堆栈概念
- 小学生都能学会
Microsoft Word中的VB6 applet:
- 在文档中嵌入交互式应用
- 无需独立开发环境
- 极低的入门门槛
WYSIWYG(所见即所得)What You See Is What You Get,这都是可视化设计任何界面,即时看到运行效果,还能快速原型开发,分钟级的从设计到可运行的时间。
火的原因就是大幅降低了编程门槛,显著提升了UI开发效率,非程序员也能创建简单应用,教育领域广泛应用。

为什么后来不见了?
因为屏幕尺寸从单一标准(800x600、1024x768)到多样化、移动设备的兴起(iOS、Android)、响应式设计需求。
已经到了what you saw was no longer what others got”(你看到的不再是别人得到的)。
尽管经典WYSIWYG工具衰落,但理念还在延续:
- 低代码/无代码平台(Webflow、Bubble)
- 4GL和RAD工具(OutSystems)
- QT Designer和QT布局系统
- Web的可视化框架(Bootstrap Studio)
与AI工具的对比:
维度 | WYSIWYG工具(90年代) | AI编码工具(2020年代) |
|---|---|---|
门槛 | 需要设计培训 | 自然语言就行 |
精确度 | 完全可控 | "vibes"驱动,不确定 |
适用场景 | 标准UI | 代码片段、快速原型 |
生成结果 | 确定性 | 概率性 |
本质 | 模板填充 | 统计组合 |
共同点 | 都是原型工具,不是生产工具 |
AI编码工具本质上是WYSIWYG工具的自然演进——降低了门槛(从学习设计到自然语言),但增加了不确定性(从确定性模板到概率性生成)。
两者都面临同一个根本局限:生成的是可演示但需重构的原型代码,而非生产就绪的代码。
AI编码工具的准确定义是:Working Mockup Generator(可工作的原型生成器)。
可以做的:
- 生成看起来完整的用户界面
- 实现基础的交互逻辑
- 快速验证想法和概念
- 学习新框架的入门示例
- 生成样板代码减少重复劳动
能做的(或做不好的):
- 生成可靠、优化的生产代码
- 处理复杂的业务逻辑
- 保证安全性和性能
- 生成可维护的架构
- 替代深度思考和设计
那什么时候是用可以用AI?什么时候不能用AI?
可以看看这个决策图:
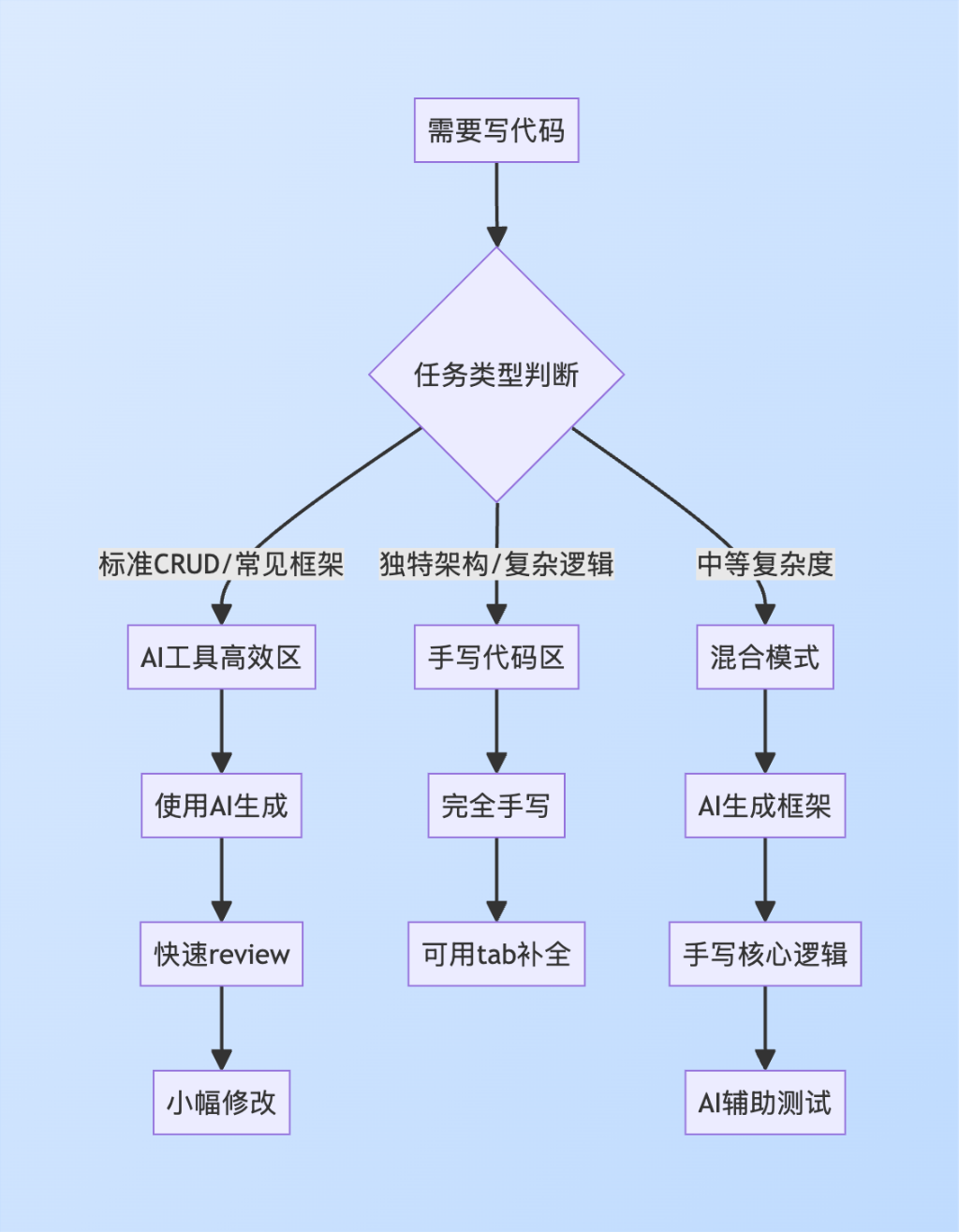
具体场景决策表
场景 | 推荐策略 | AI贡献度 | 理由 |
|---|---|---|---|
CRUD表单 | AI生成 | 80-90% | 高度标准化,训练数据丰富 |
REST API路由 | AI生成 | 70-80% | 模式固定,变化有限 |
数据库Schema | 混合模式 | 40-60% | 结构可AI生成,优化需人工 |
业务逻辑 | 手写为主 | 10-20% | 独特需求,AI难理解 |
算法实现 | 视复杂度 | 30-70% | 标准算法AI强,创新算法手写 |
UI组件 | AI生成 | 60-80% | 常见组件AI擅长 |
测试用例 | AI辅助 | 50-70% | AI能生成框架,边缘case需人工 |
性能优化 | 手写为主 | 20-30% | 需要深度理解和profiling |
安全代码 | 手写为主 | 10-20% | 安全关键,不能依赖AI |
架构设计 | 完全手写 | 0-10% | 需要深度思考和权衡 |
Karpathy提到的"老虎机效应",就是警告反复调整prompt试图让AI生成正确代码的行为。
无他,就是在用AI时,每次调整prompt需要时间,等待AI重新生成需要时间,review新代码需要时间,总时间可能超过手写代码。
并且最重要的是每次生成结果不同,可能越改越差(AI写代码的通病,上下文问题),最后难以控制输出质量。
