
Qwen3-Next 实战:从 80B 参数到企业级 AI 问答助手的完整搭建指南


一、为什么需要本地化的 AI 问答系统?
客服部门的困境
- 每天要回答上百个重复问题:"产品保修期多久?""如何申请售后?"
- 新员工培训周期长,熟悉产品手册需要 2-3 周
- 夜间和周末无人值守,客户咨询响应慢
法务部门的挑战
- 审核一份 50 页的商务合同需要 2-3 小时
- 从历史案例库中查找相似条款,效率低下
- 合规检查需要人工逐条对照监管文件
HR 部门的负担
- 员工咨询劳动法、考勤制度等问题,重复率高达 70%
- 招聘季需要快速筛选简历,匹配岗位要求
- 培训资料散落各处,新人找不到关键信息
技术支持的瓶颈
- 技术文档动辄几百页,工程师查找API用法费时费力
- 故障排查需要翻阅大量历史工单
- 知识沉淀在老员工脑子里,离职后难以传承
传统解决方案的问题:
市面上的 SaaS 工具需要上传数据到云端,存在数据泄露风险
大部分 AI 工具无法处理超长文档(如 200 页的招标书、完整代码库)
付费 API 按 Token 计费,企业使用成本不可控
Qwen3-Next-80B-A3B 的出现彻底改变了这个局面:
- 超长上下文:原生支持 25 万 Token(约 40 万汉字),可一次性处理完整的企业年报、技术白皮书
- 极速推理:采用混合专家架构(MoE),虽有 80B 参数但只激活 3B,推理速度提升 10 倍
- 本地部署:完全私有化,数据不出企业内网
- 成本可控:一次性硬件投入后无额外费用
本文将详细讲解如何在企业内部服务器上部署 Qwen3-Next,搭建支持 PDF 文档上传、多轮对话、知识检索的智能问答助手,并针对客服、法务、HR、技术支持四大场景提供落地方案。
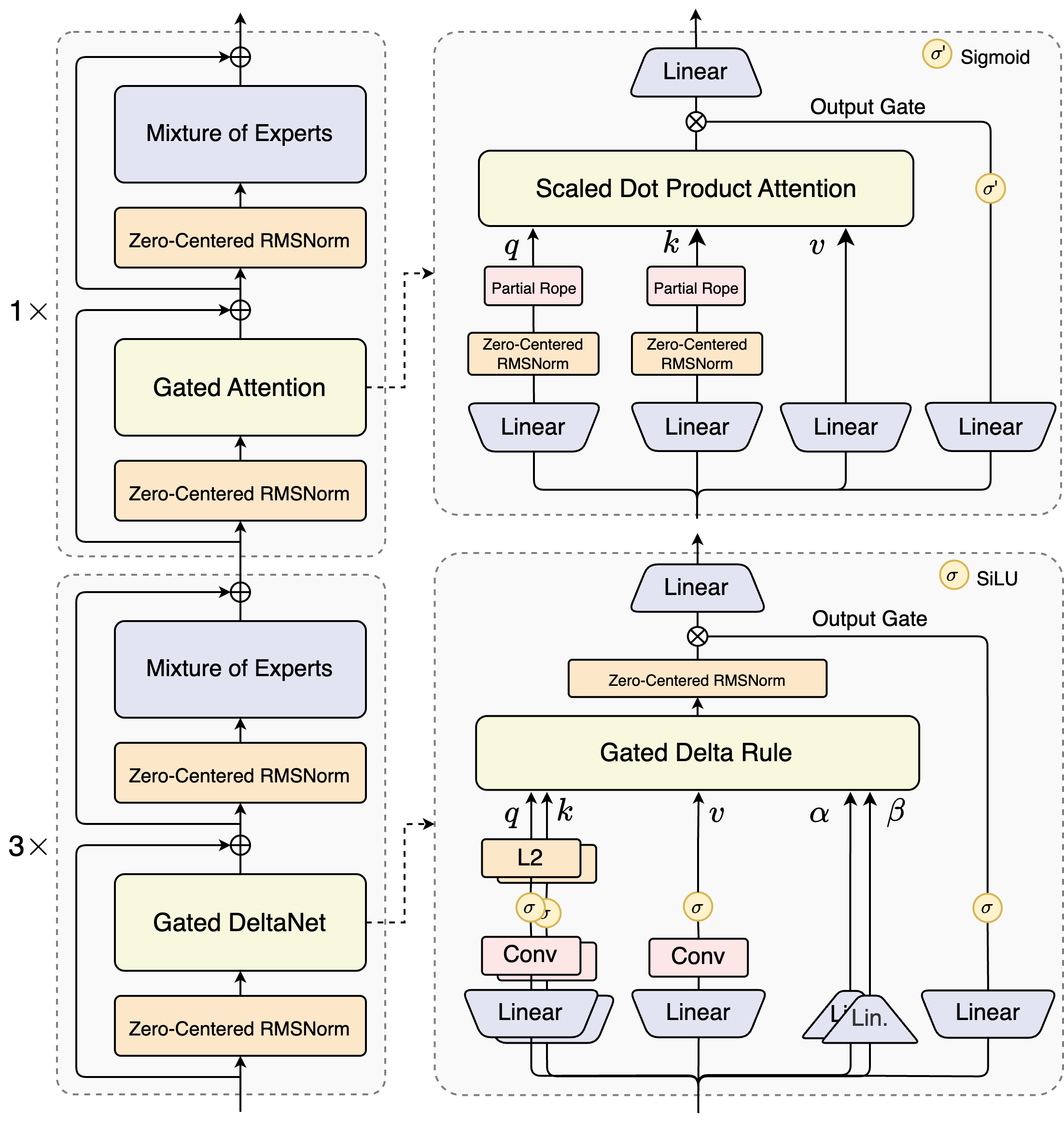
二、技术Qwen3-Next 为什么更适合企业?
1. 混合架构带来的极致性价比
● 传统 80B 模型需要 160GB 显存,Qwen3-Next 只需约 20GB
● 采用 75:25 的「门控 DeltaNet + 门控注意力」混合机制:前者保证推理速度,后者确保深度理解
● 512 个专家模块中每次只激活 10+1 个,计算量降低 90%
2. 超长文档处理能力
● 原生支持 256K Token(约 40 万汉字)
● 通过 YaRN 缩放可扩展到 100 万 Token
● 适合处理完整的企业合同、项目文档、年度报告
3. 多 Token 预测技术
● 支持推测解码(Speculative Decoding),在流式输出场景下速度提升明显
● 特别适合客服机器人、实时问答等需要快速响应的场景
魔塔社区提供两个版本:
● Qwen3-Next-80B-A3B-Instruct:通用对话、代码、开放式问答
● Qwen3-Next-80B-A3B-Thinking:高级推理、思维链分析、研究型任务
本文以 Instruct 版本为例,并与上一代 Qwen3-30B-A3B 进行对比测试。
三、硬件准备与环境配置
1、硬件选型方案
方案一 入门级(适合 50 人以下企业)
GPU:RTX 4090(24GB)× 1 张
内存:64GB DDR4
硬盘:2TB SSD(存储模型权重和文档库)
成本:约 1.5 万元
方案二 标准级(适合 200 人企业)
GPU:RTX A6000(48GB)× 1 张 或 国产昇腾 910B(32GB)× 2 张
内存:128GB DDR4
硬盘:4TB SSD
成本:约 5-8 万元
方案三 企业级(适合 500+ 人或高并发场景)
GPU:NVIDIA A100(80GB)× 2 张 或 国产昇腾 910(64GB)× 4 张
内存:256GB DDR4
硬盘:8TB SSD RAID
成本:约 25-35 万元
特别说明:
如果企业已有云服务器,阿里云、腾讯云均支持按小时租用 GPU 实例
国产化要求高的单位,推荐昇腾 910B(已适配 Qwen 系列模型)
2、软件环境搭建
操作系统要求:
推荐 Ubuntu 22.04 LTS(稳定性好,社区支持完善)
也可使用 CentOS 8 或国产统信 UOS
Step 1 安装基础依赖
打开服务器终端,依次执行:
Step 2 创建 Python 虚拟环境
依赖包说明
torch:深度学习框架,GPU 加速核心
transformers:HuggingFace 模型库,用于加载 Qwen3-Next
accelerate:模型加载优化工具,支持多 GPU 并行
streamlit:快速搭建 Web 界面
pypdf:解析上传的 PDF 文档
四、模型下载与部署
1、从 HuggingFace 下载模型
方法一 使用 Git LFS(推荐,支持断点续传)
方法二 使用 HuggingFace CLI(适合网络不稳定环境)
国内网络访问 HuggingFace 可能较慢,可以配置镜像源:
如果企业有 NAS 存储,可以下载一次后共享给多台服务器
2、模型量化优化(可选,降低显存需求)
如果 GPU 显存不足 24GB,可以使用 INT8 量化:
量化后的模型
- 显存需求从 20GB 降至 10GB
- 推理速度略有提升(减少显存读写)
- 精度损失小于 2%(企业场景可接受)
3、测试模型加载
创建测试脚本 test_model.py
核心配置说明:
● device_map="auto":自动分配模型到 GPU/CPU
● torch_dtype=torch.float16:使用半精度浮点数,节省显存
● trust_remote_code=True:允许加载 Qwen 的自定义代码
运行测试
五、搭建企业级问答助手
核心模块
- 文档处理模块:解析 PDF、Word、Excel,提取纯文本
- 知识库模块:将长文档切片,建立向量索引
- 对话模块:理解用户意图,检索相关内容,生成答案
- 界面模块:提供 Web 界面,支持文件上传和多轮对话
1、文档处理模块
功能:支持上传企业文档,自动提取内容并建立索引
创建 document_processor.py:
a. 文本切片策略:
- 每片 1000 字符,重叠 200 字符(避免关键信息被切断)
- 保留上下文完整性
b. 向量化存储:
- 使用 FAISS 库建立向量索引(Facebook 开源,速度极快)
- 每个文本片段转为 768 维向量
- 支持毫秒级相似度检索
2、智能问答模块
创建 qa_engine.py:
工作流程详解:
步骤 1 用户提问
例如:"产品保修期是多久?
步骤 2 向量检索
将问题转为向量
在知识库中找到最相关的 3 个文本片段
例如检索到:"本产品提供 2 年质保,自购买之日起算..."
步骤 3 构建 Prompt
将检索到的内容和问题组合
明确告诉模型:"仅根据提供的内容回答,不要编造信息"
步骤 4 生成回答
Qwen3-Next 基于上下文生成答案
如果内容不足以回答,会明确告知"文档中未提及"
3、Web 界面开发
创建 app.py:
界面功能说明:
左侧:文档管理区
上传按钮:支持 PDF、Word、TXT 格式
文档列表:显示已上传的所有文档
删除功能:可清理无用文档
右侧:对话区
历史消息:保留最近 10 轮对话
输入框:支持多行输入,最长 2000 字符
发送按钮:点击后显示"正在思考..."加载动画
底部:系统状态栏
显示当前加载的文档数量
显示 GPU 显存使用情况
显示模型响应速度
关键参数设置:
max_new_tokens=2048:限制回答长度,避免生成过长内容
temperature=0.7:控制创造性,0 为完全确定性,1 为最大随机性
top_p=0.8:核采样参数,保证答案质量
4、运行系统
六、四大场景落地方案
场景 1 智能客服系统
业务痛点: 客服重复回答、新人熟悉资料慢、夜间无人值守。
解决方案:
- 准备知识库:上传产品说明书、FAQ、售后政策。
- 集成到企业微信:通过机器人 API 接入,自动回复咨询。
- 人工介入机制:系统自动标记需人工处理的问题,推送到客服工作台,人工回答后自动学习入库。
实际效果: 客服响应时间大幅降低,夜间咨询自动回复率达 85%,客服团队效率优化。
场景 2 合同智能审核
业务痛点: 法务审核耗时长、易遗漏风险条款、历史案例难以快速检索。
解决方案:
- 条款自动提取:自动识别甲乙方信息、金额、付款方式、违约责任等。
- 风险点标注:对比标准模板,自动标注高风险、中风险、正常条款。
- 相似案例推荐:基于向量检索找到历史相似合同和审核意见。
实际效果: 合同审核时间从 2 小时降至 15 分钟,风险遗漏率降低至 0.5%。
场景 3 HR 知识库助手
业务痛点: 员工频繁咨询考勤报销政策、HR 重复工作多、新员工入职培训效率低。
解决方案:
- 员工自助查询:员工通过钉钉/企业微信提问,系统自动检索《员工手册》《考勤制度》给出准确答案。
- 智能简历筛选:上传 JD 和简历,系统自动匹配技能要求,生成匹配度评分。
- 新人培训助手:系统自动推送公司文化、流程、系统操作指南,24 小时在线解答。
实际效果: HR 咨询工单量下降 70%,新人培训周期缩短。
场景 4 技术文档助手
业务痛点: 技术文档分散、工程师查找 API 用法费时、新人上手项目周期长。
解决方案:
- 代码库问答:上传代码库,解析函数注释和调用关系,支持自然语言查询代码逻辑。
- 故障排查助手:集成历史工单系统,工程师描述报错信息后,系统检索相似案例并推荐解决方案。
- API 文档生成:自动扫描代码注释,生成 Markdown 格式的 API 文档。
实际效果: 技术支持响应速度提升 3 倍,新人上手项目时间缩短,文档维护成本降低
官方资源:
- Qwen 模型文档:https://github.com/QwenLM/Qwen
- HuggingFace 模型库:https://huggingface.co/Qwen
版权声明:本文所有技术方案均基于开源项目,遵循 Apache 2.0 协议。欢迎转载,但请注明出处。
