
LangChain v1 实战:用本地模型搭建会议纪要自动化系统


一、国内企业会议管理的真实痛点
在国内企业日常运营中,会议纪要整理是个让人头疼的问题
- 会议频繁,记录混乱:销售周会、项目复盘、客户沟通,每天都有大量会议,手写记录往往零散、不规范
- 整理耗时:会后需要人工梳理要点、提取行动项、分配负责人,一场1小时会议可能需要30分钟整理
- 信息丢失:口头讨论的决策、临时分配的任务,容易因为记录不及时而遗漏
- 归档困难:纪要散落在个人笔记、微信聊天、飞书文档里,后续追溯困难
本文将基于 LangChain v1 框架 + 本地开源大模型 + 飞书文档 API,搭建一套完全可控的会议纪要自动化系统,实现:
1. 将零散的会议记录转化为结构化纪要
2. 自动提取决策事项和行动清单
3. 人工审核后一键同步到飞书文档
全程使用国内可访问的技术栈,数据不出域,成本可控。
二、方案逻辑
整个系统分为三层:
输入层:
● 用户通过简单的 Web 界面粘贴会议原始记录
● 可选填写会议标题、日期、参会人员等元数据
处理层:
● 使用本地部署的开源大模型(如 Qwen、ChatGLM)理解会议内容
● 通过 LangChain v1 的结构化输出功能,强制模型按固定格式返回数据
● 生成包含摘要、决策、行动项的标准化纪要
输出层:
● 在 Web 界面预览生成的 Markdown 格式纪要
● 人工确认无误后,调用飞书文档 API 自动追加到指定团队文档
组件 | 选择 | 理由 |
大模型 | Qwen2.5 (本地部署) | 开源免费,中文能力强,可私有化部署 |
应用框架 | LangChain v1 | 提供标准化的 Agent 构建方式和结构化输出 |
前端界面 | Streamlit | Python 原生,无需前端开发经验 |
文档集成 | 飞书开放平台 API | 国内主流协作工具,API 文档完善 |
LangChain v1 的关键改进(相比旧版本):
● 统一的 Agent 创建方式:不再有多种混乱的模式,只用 create_agent 一种标准流程
● 结构化输出保证:通过 Pydantic 模型定义数据格式,模型必须按此返回,避免解析失败
● 内容块标准化:无论用哪家模型(通义、文心、豆包),消息格式完全一致
● 中间件机制:可以在模型调用前后插入审批、日志、敏感信息过滤等环节
三、实操流程:从零搭建完整系统
步骤 1 准备本地模型环境
安装 Ollama(本地模型运行工具)
Ollama 是目前最简单的本地大模型部署方案,类似 Docker 的使用体验。
访问 Ollama 官网下载对应系统的安装包(支持 Windows/Mac/Linux):
https://ollama.com/download
安装后在命令行验证:
下载通义千问模型
在命令行执行:
这会自动从 Ollama 官方库下载 Qwen2.5 的 7B 参数版本(约 4GB)。如果网络较慢,可以使用国内镜像源:
下载完成后启动模型服务:
服务默认运行在 http://localhost:11434,保持该窗口开启。
测试模型可用性
新开一个命令行窗口,测试模型是否正常响应:
如果返回类似“我是通义千问,一个由阿里云开发的大型语言模型”的回复,说明模型已就绪。
步骤 2 配置飞书文档权限
要让程序能自动写入飞书文档,需要完成三个步骤:
- 创建飞书企业自建应用
- 获取文档写入权限
- 生成访问凭证
创建飞书自建应用
登录飞书开放平台(https://open.feishu.cn/):
点击右上角开发者后台,接着创建企业自建应用
填写应用名称(如会议纪要助手)
选择应用图标,点击创建
添加文档权限范围
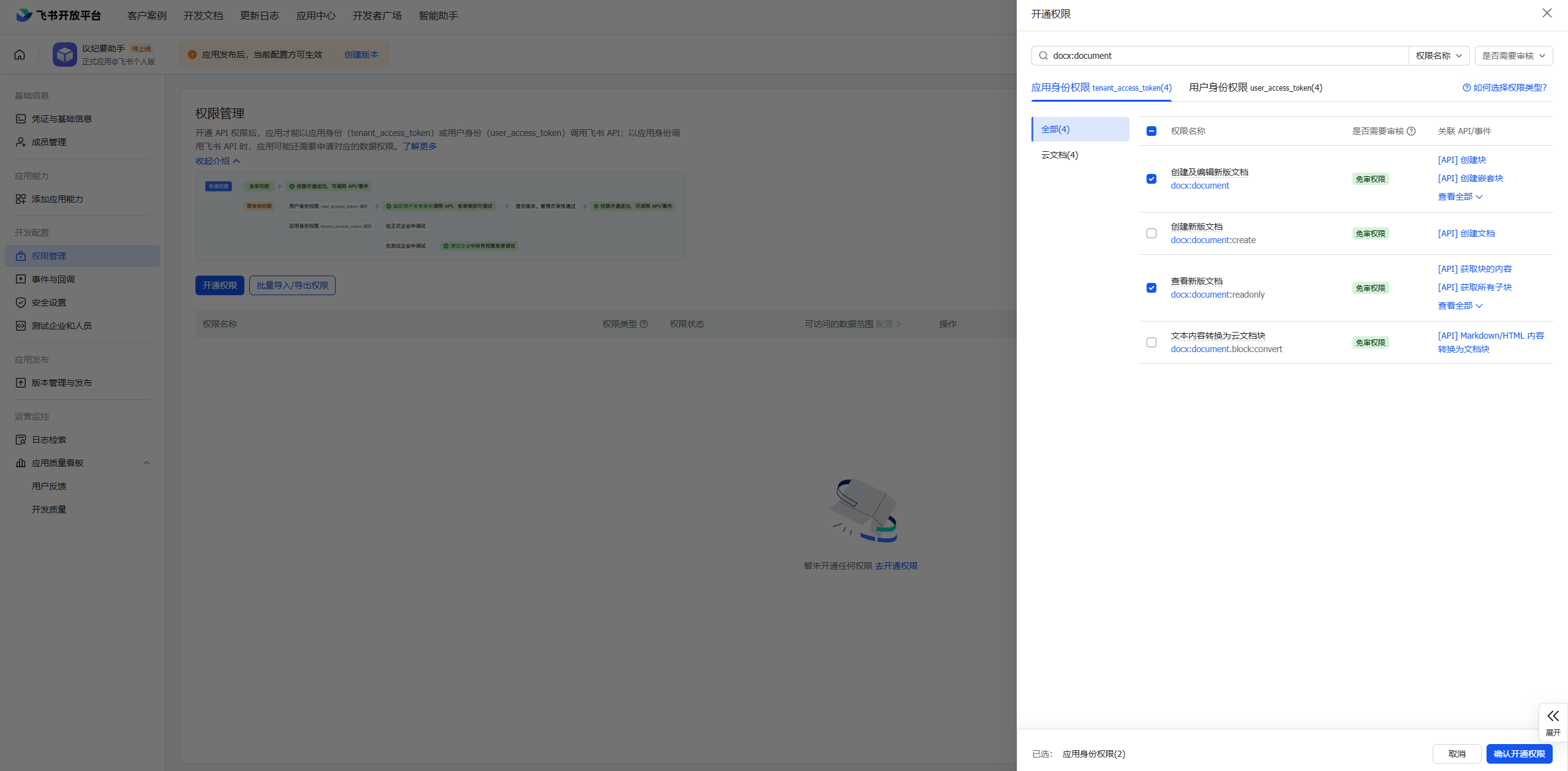
在应用管理页面:
进入“权限管理”标签
搜索并开通以下权限:
docx:document (查看、编辑文档)
docx:document:readonly (查看文档)
在“版本管理和发布”创建1.0.0版本
获取访问凭证
在"凭证与基础信息"页面,记录以下两个值:
App ID(应用唯一标识)
App Secret(应用密钥)
创建目标飞书文档并获取 ID
在飞书中新建一个空白文档(云文档类型):
命名为"团队会议纪要汇总"
打开文档,查看浏览器地址栏
地址格式为:https://xxx.feishu.cn/wiki/xxxxxxxxxxxxxx
复制 /wiki/ 后面的长字符串,这就是文档 ID
将该文档分享给应用机器人(在文档设置中添加机器人为协作成员)。
步骤 3 安装项目依赖
创建项目文件夹并进入
创建虚拟环境
安装核心依赖包
各依赖包作用说明:
streamlit:提供 Web 用户界面。
langchain 系列:作为 Agent 框架和模型封装。
pydantic:用于定义数据结构模型。
python-dotenv:管理环境变量(用于存放飞书密钥)。
requests:用于调用飞书 API。
步骤 4 定义会议纪要的数据结构
在项目文件夹创建 models.py 文件,定义标准化的输出格式,通过 Pydantic 模型强制模型按此结构返回数据。
核心数据结构
ActionItem 模型 (行动项):
- 责任人 (owner): 谁来做 (必填)。
- 具体任务 (task): 做什么 (必填)。
- 截止日期 (due_date): 什么时候完成 (必填)。
RecapDoc 模型 (完整纪要):
- 包含会议元信息 (标题、日期、参会人)。
- 内容摘要。
- 决策事项列表。
- 行动项列表 (List[ActionItem])。
设计优势: 结构化输出取代传统正则提取,大幅降低信息提取失败率。
步骤 5 编写模型调用逻辑
创建 llm_service.py 文件,实现与本地模型的交互。
核心流程
1.初始化模型连接:
使用 LangChain init_chat_model() 作为统一入口。
指定 model="ollama/qwen2.5:7b" 和本地 base_url。
2.绑定输出格式:
使用 withstructuredoutput(RecapDoc) 强制模型返回符合 RecapDoc 结构的 JSON。
3.构造提示词:
系统提示 (SystemMessage): 设定模型角色(会议纪要助手)和提取决策/行动项的规则。
用户提示 (HumanMessage): 包含实际会议内容和元数据。
4.调用模型生成:
invoke(messages) 发送请求。
返回结果是已验证的 Python 对象。
5.异常处理: 捕获格式错误或服务不可用异常,返回默认结构,避免程序崩溃。
避坑提示:确保 Ollama 服务在运行,首次调用需等待模型加载(10-30 秒)。
步骤 6 实现飞书文档写入
创建 feishu_service.py 文件,处理飞书 API 调用。
核心逻辑
1.获取访问令牌 (Access Token):
基于 App ID 和 App Secret 换取 Tenant Access Token。
Token 有效期 2 小时,需缓存复用。
调用 /auth/v3/tenantaccesstoken/internal/ 接口。
2.追加内容到文档:
获取文档当前内容,确定末尾位置索引 (end_index)。
构造插入请求,在 end_index - 1 位置插入文本。
调用 /docx/v1/documents/{documentid}/blocks/batchcreate 接口。
3.转换为飞书 Markdown:
将 RecapDoc 对象格式化为 Markdown 文本。
格式: 一级标题(会议名称 + 日期),列表展示决策和行动项。
行动项格式: 责任人 — 任务描述 (截止日期)。
关键参数:
插入位置是 end_index - 1,避开文档结束符。
步骤 7 搭建 Streamlit 交互界面
创建 app.py 文件,作为用户使用的 Web 应用。
界面布局
输入区 (左右分栏):
左侧大文本框:粘贴会议原始记录。
右侧元数据:会议标题、日期选择器、参会人员(逗号分隔)。
操作按钮:
"生成纪要":调用模型生成结构化纪要。
"同步到飞书":将纪要追加到飞书文档 (生成后可用)。
预览区: 实时显示 Markdown 格式的纪要预览。
核心交互逻辑
状态管理: 使用 Streamlit session_state 存储 recap 对象和 markdown_text,保持数据不丢失。
生成纪要流程: 验证输入 → 调用 generate_recap() → 转换为 Markdown → 存入 session_state。
同步飞书流程: 检查纪要是否存在 → 添加分隔标题 → 调用 append_to_feishu_doc() → 显示成功提示。
环境变量加载: 从 .env 文件加载飞书密钥和文档 ID。
避坑提示:
第一次点击"生成纪要"因模型加载会较慢(显示"正在处理...")。
检查 .env 文件确保飞书密钥正确。
步骤 8 配置环境变量
在项目根目录创建 .env 文件,用于存储密钥和配置。
前三个是飞书相关配置,从步骤 2 获取
OLLAMA_BASE_URL:本地模型服务地址,默认端口 11434
MODEL_NAME:使用的具体模型版本
安全提示:
不要将 .env 文件上传到 Git 仓库
在项目根目录创建 .gitignore 文件,添加一行 .env
步骤 9 启动应用并测试
确认前置条件
运行前检查清单:
● Ollama 服务正在运行(ollama serve 窗口开启)
● 已下载 qwen2.5:7b 模型
● .env 文件已正确配置
● 飞书文档已分享给应用机器人
启动 Streamlit 应用
在项目目录执行:
测试流程
准备测试数据:
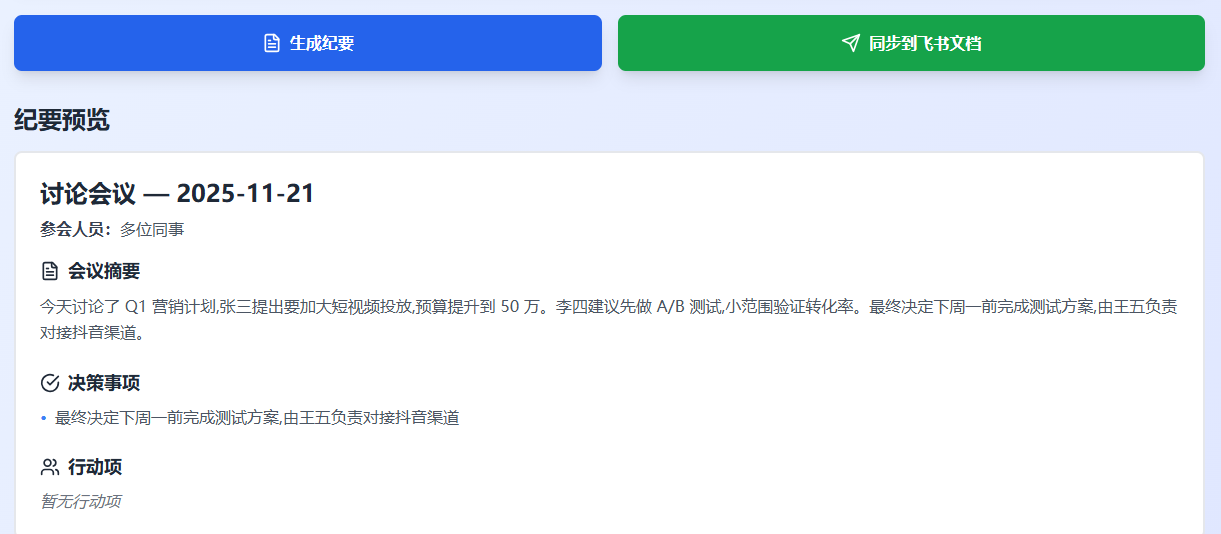
复制以下示例会议记录:今天讨论了 Q1 营销计划,张三提出要加大短视频投放,预算提升到 50 万。李四建议先做 A/B 测试,小范围验证转化率。最终决定周一前完成测试方案,由王五负责对接抖音渠道。另外产品侧反馈落地页加载慢,技术部承诺本周五优化完成。
操作步骤:
- 粘贴上述文本到左侧大文本框
- 填写标题:"Q1 营销计划讨论会"
- 选择日期:今天
- 填写参会人:"张三,李四,王五,技术部代表"
- 点击"生成纪要"按钮
- 确认内容无误后,点击"同步到飞书"
- 看到"同步成功"提示
四、场景延伸:还能用在哪些地方?
基于同样的技术架构,可以快速衍生出以下实用工具:
1.客户沟通记录整理
场景:销售、客服团队每天有大量客户对话(电话、微信)
改造方案:
输入:客户对话记录 + 客户基本信息
输出结构调整为:
存储到:企业 CRM 系统(通过 API)或飞书多维表格
2.项目周报自动生成
场景:项目经理需要每周汇总团队工作进展
改造方案:
输入:本周各成员的日报/周报文本
输出结构:
存储到:飞书项目看板或企业微信群公告
3.培训课程知识提炼
场景:企业内训、行业讲座后需要整理课程要点
改造方案:
输入:讲师 PPT 文字 + 学员笔记
输出结构:
存储到:企业知识库(如语雀、Notion 国内版)
