
电子硬件人必看!用 NVIDIA 工具链快速搭建实时视觉检测系统
做电子/智能硬件研发、生产的你,是不是总被这些问题卡脖子?PCB 板上的微小缺孔、焊接瑕疵靠人工难发现,漏检误检直接影响产品良率;生产线提速后,质检环节跟不上节奏,成了产能瓶颈;想定制检测模型,却被标注数据、模型优化、部署落地等难题劝退……
现在,这些痛点有了高效解决方案!借助 NVIDIA TAO 6 和 DeepStream 8 这套 AI 工具链,不用高深的算法知识,就能快速搭建一套精准、实时的视觉检测系统 —— 从 PCB 缺陷识别到组件装配校验,全流程自动化质检,既能把人工从重复劳动中解放出来,又能提升检测效率和准确率,帮电子硬件行业从业者实实在在提高工作效率。
本文将详细指导如何使用 NVIDIA TAO 和 NVIDIA DeepStream 构建端到端实时视觉检测流水线,核心步骤包括:、
- 利用 TAO 进行自监督学习,充分挖掘领域特定无标签数据的价值
- 通过 TAO 知识蒸馏优化模型,提升吞吐量和运行效率
- 借助 DeepStream 推理构建器(低代码工具)部署模型,快速将模型想法转化为可投入生产的独立应用或可部署微服务
如何利用 NVIDIA TAO 实现基于视觉基础模型的定制化模型开发规模化
NVIDIA TAO 支持端到端工作流,可针对特定领域场景训练、适配和优化大型视觉基础模型。作为一套定制化视觉基础模型的框架,TAO 通过其微调功能,帮助用户在保证高准确率的同时优化模型性能。
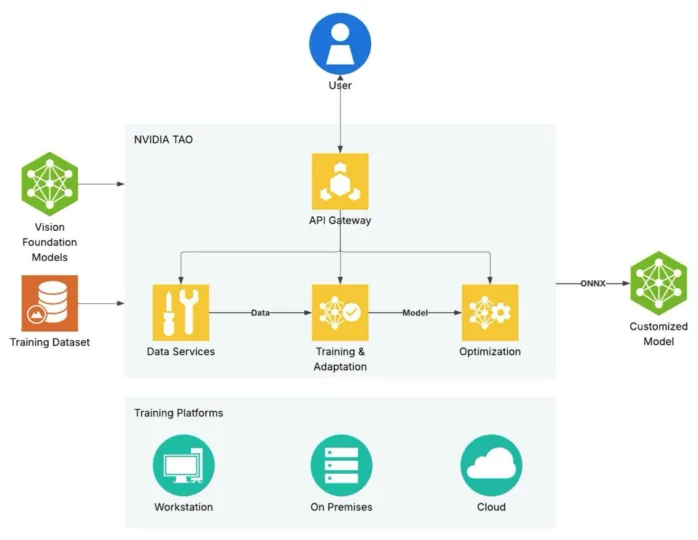
图 1 展示了 NVIDIA TAO 的端到端工作流程概览
视觉基础模型(VFM)是基于大规模多样化数据集训练的大型神经网络,能够捕捉通用且强大的视觉特征表示。这种通用性使其成为多种 AI 感知任务(如图像分类、目标检测、语义分割)的灵活模型骨干。
TAO 提供了一系列功能强大的基础骨干网络和任务头,可针对工业视觉检测等核心工作负载微调模型。TAO 6 中的两大核心基础骨干网络为 C-RADIOv2(开箱即用准确率最高)和 NV-DINOv2。此外,TAO 还支持第三方模型(需其视觉骨干网络和任务头架构与 TAO 兼容)。
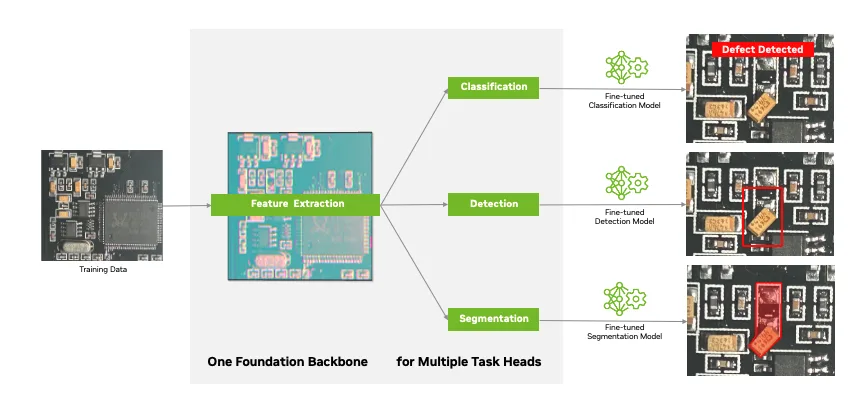
图 2 展示了 TAO 微调工作流:从基础骨干网络通过数据集学习图像特征,再通过任务头层(分类、检测、分割)利用这些特征图生成最终预测结果
为提升模型准确率,TAO 支持多种模型定制技术,包括监督微调(SFT)和自监督学习(SSL)。监督微调需要收集针对特定计算机视觉下游任务的标注数据集,但高质量标注数据的收集是一项复杂的人工流程,耗时且成本高昂。
其次,NVIDIA TAO 6 支持通过自监督学习挖掘海量无标签图像的潜力,在标注数据稀缺或获取成本高的场景下,加速模型定制流程。
这种方法也被称为领域自适应,能够利用无标签数据构建强大的基础模型骨干网络(如 NV-DINOv2),再结合任务头,通过规模更小的标注数据集微调,适配各类下游检测任务。
在实际应用中,该工作流允许模型从大量无标签图像中学习缺陷的细微特征,再通过有针对性的监督微调优化决策能力,即使在定制化的真实世界数据集上,也能实现最先进的性能。
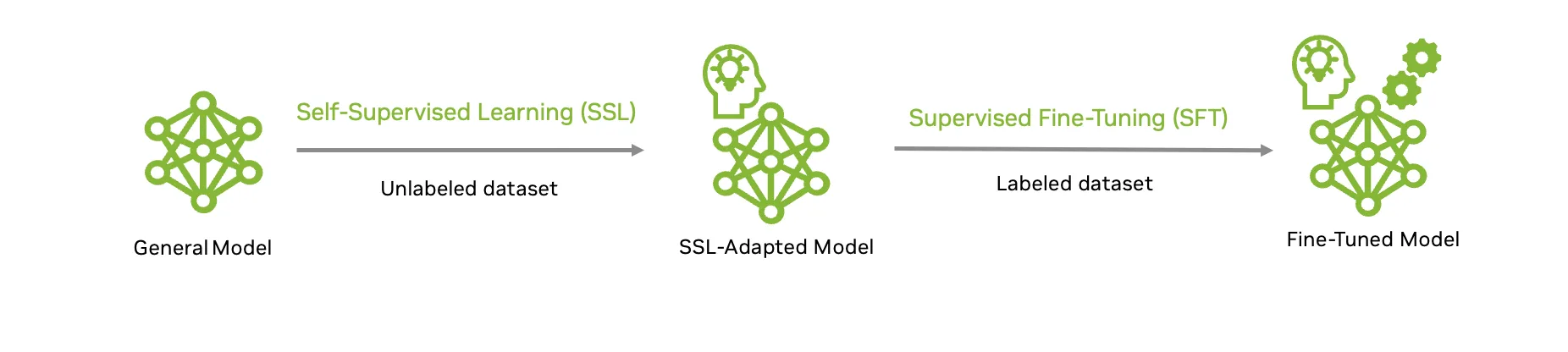
图 3 展示了将大规模训练的基础模型有效适配和微调至特定下游任务的两个阶段
通过基础模型微调提升 PCB 缺陷检测准确率
为具象化展示效果,NVIDIA将 TAO 基础模型适配工作流应用于印刷电路板(PCB)缺陷检测:利用大规模无标签 PCB 图像微调视觉基础模型。实验以基于 7 亿张通用图像训练的通用模型 NV-DINOv2 为起点,通过自监督学习,使用约 70 万张无标签 PCB 图像定制适配 PCB 应用场景,使模型从通用泛化能力转向精准的领域专用能力。
领域自适应完成后,NVIDIA利用标注 PCB 数据集,通过线性评估优化任务特定头以提升准确率,并通过全量微调进一步调整骨干网络和分类头。该数据集包含约 600 个训练样本和 400 个测试样本,将图像分为合格(OK)和缺陷(Defect)两类,其中缺陷类型包括缺失、偏移、倒置、焊接不良和异物等。
特征图显示,即使在下游微调前,经过领域自适应的 NV-DINOv2 也能清晰区分组件与前景 - 背景(图 4、图 5),尤其擅长将集成电路(IC)引脚等复杂组件与背景分离 —— 这是通用模型无法实现的。

OK类别的特征图对比:领域适应的NV-DINOv2(左)vs 通用NV-DINOv2(右)

缺陷类别的特征图对比:领域适应的NV-DINOv2(左)vs 通用NV-DINOv2(右)
实验结果显示,模型分类准确率从 93.8% 提升至 98.5%,显著提升 4.7%。
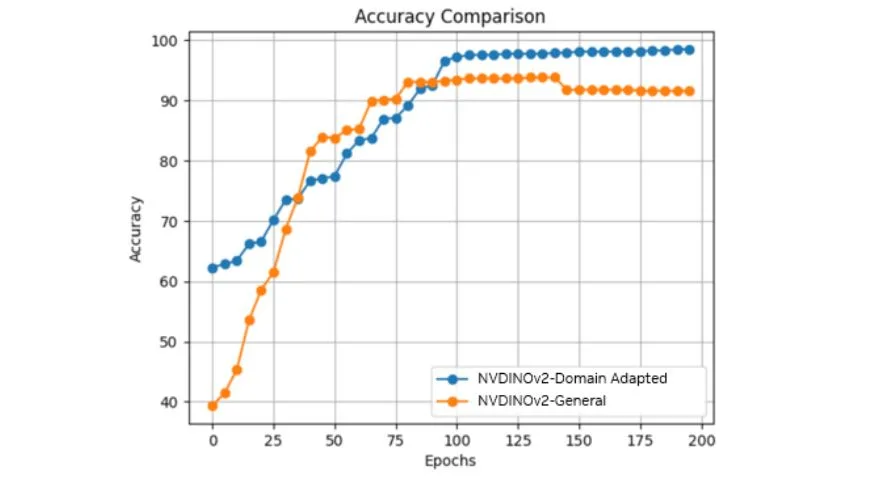
图 6 展示了训练过程中,基于通用 NV-DINOv2 和基于无标签图像领域自适应的 NV-DINOv2,准确率随训练轮次的变化趋势
经过领域自适应的 NV-DINOv2 还展现出强大的视觉理解能力,能够提取同领域内的相关图像特征。这表明,通过下游监督微调,即使使用更少的标注数据,也能实现相当或更优的准确率。
在部分场景中,收集 70 万张无标签图像仍可能存在挑战,但即使使用更小的数据集,NV-DINOv2 领域自适应仍能带来性能提升。
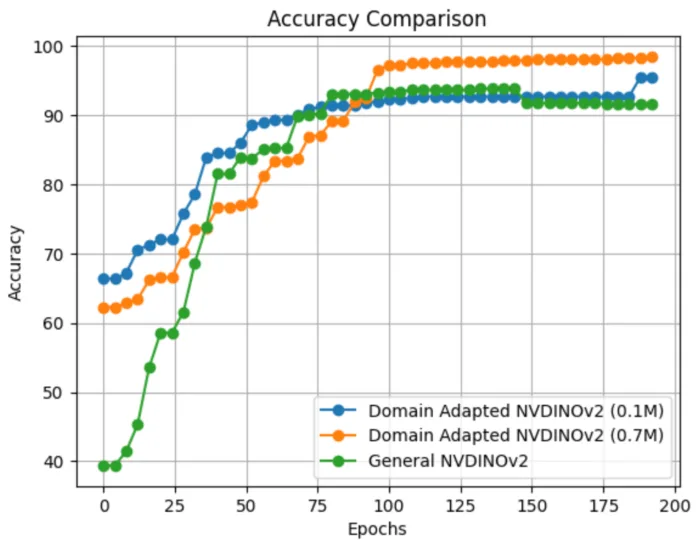
图 7 对比了通用 NV-DINOv2(绿色)、10 万张图像领域自适应的 NV-DINOv2(蓝色)和 70 万张图像领域自适应的 NV-DINOv2(橙色),在训练过程中准确率随轮次的收敛趋势
该案例证明,通过 NVIDIA TAO 结合 NV-DINOv2,利用无标签领域数据进行自监督学习,能够构建稳健、准确的 PCB 缺陷检测模型,同时减少对大量标注样本的依赖。
如何优化视觉基础模型以提升吞吐量
优化是深度学习模型部署的关键步骤。许多生成式 AI 和视觉基础模型包含数亿个参数,计算需求极高,对于工业视觉检测、实时交通监控等实时应用中使用的大多数边缘设备而言,模型体积过大且资源消耗过高。
NVIDIA TAO 利用知识蒸馏技术,从大型基础模型中提取知识并优化为更小体积的模型。知识蒸馏将大型、高精度的教师模型压缩为更小、更快的学生模型,且通常不会损失准确率。其核心原理是让学生模型不仅模仿教师模型的最终预测结果,还学习其内部特征表示和决策边界,从而使模型能够在资源受限的硬件上实际部署,并实现规模化模型优化。
NVIDIA TAO 进一步强化了知识蒸馏功能,支持多种蒸馏形式,包括骨干网络蒸馏、对数蒸馏和空间 / 特征蒸馏。TAO 的一大亮点是专为目标检测设计的单阶段蒸馏方法:通过这一简化流程,更小、更快的学生模型可在一个统一的训练阶段中,直接从教师模型同时学习骨干网络表示和任务特定预测,在不牺牲准确率的前提下,大幅降低推理延迟并减小模型体积。
单阶段蒸馏在实时 PCB 缺陷检测模型中的应用
NVIDIA在 PCB 缺陷检测数据集上验证了 TAO 蒸馏功能的有效性。该数据集包含 9602 张训练图像和 1066 张测试图像,涵盖 6 类高难度缺陷:缺孔、鼠咬、开路、短路、毛刺和多余铜箔。实验使用两款不同的教师模型候选者,骨干网络均基于 ImageNet-1K 预训练权重初始化,结果采用目标检测领域标准的 COCO 平均精度(mAP)衡量。
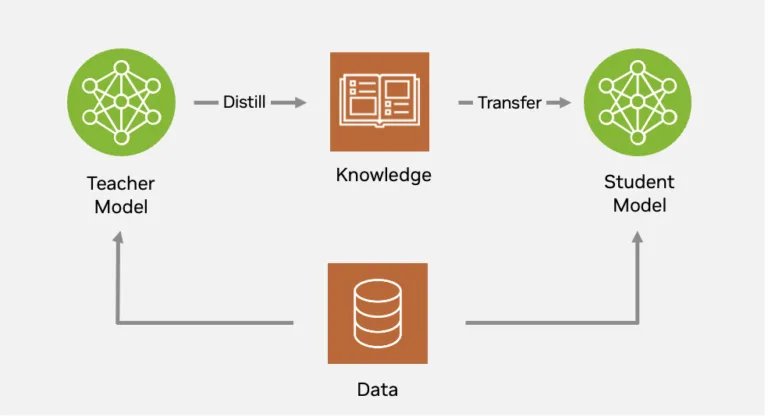
图 8 为知识蒸馏流程示意图,顺时针从底部中央依次为:数据、教师模型、知识、学生模型
在第一组实验中,NVIDIA使用 ResNet 系列骨干网络构建教师 - 学生模型组合进行蒸馏,结果显示学生模型的准确率不仅达到教师模型水平,甚至实现了超越。
基线实验通过 TAO 中 RT-DETR 模型的训练功能完成,以下是一个基础的训练配置文件示例:
执行训练命令:
可通过修改model.backbone参数(指定骨干网络名称)和model.pretrained_backbone_path参数(指定骨干网络预训练权重文件路径)更换骨干网络。
蒸馏实验通过 TAO 中 RT-DETR 模型的蒸馏功能完成,可在原始训练实验配置文件中添加以下配置项:
执行蒸馏命令示例:
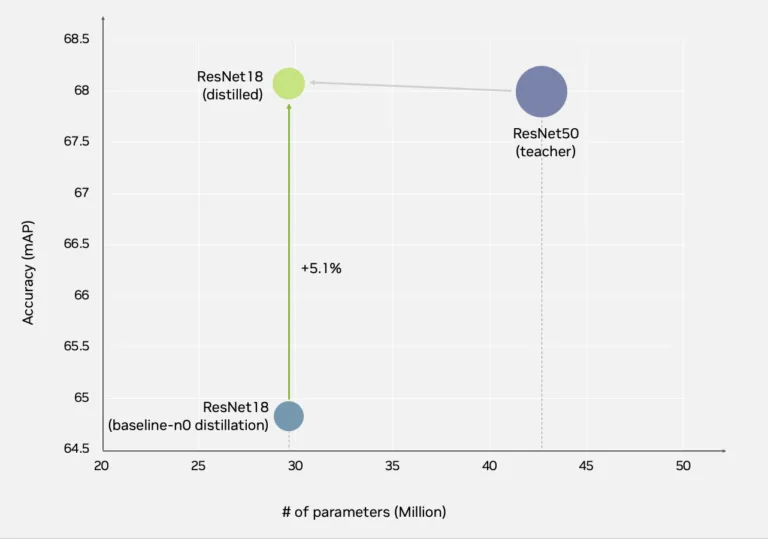
图9. 将ResNet-50模型蒸馏为更轻量的ResNet-18模型,精度提升5%
在边缘设备部署模型时,推理加速和内存限制都是关键考量因素。TAO 支持不仅在同一系列骨干网络间蒸馏检测特征,还能跨骨干网络家族进行蒸馏。
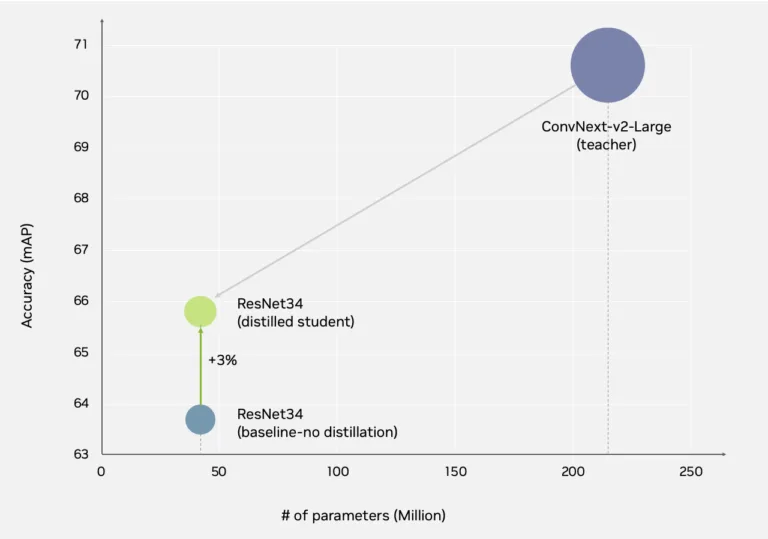
图10. 将ConvNeXt模型蒸馏为更轻量的ResNet-34模型,精度提升3%
本实验中,NVIDIA以基于 ConvNeXt 的 RT-DETR 模型作为教师模型,将其蒸馏为更轻量的基于 ResNet34 的模型。通过单阶段蒸馏,TAO 在将模型体积减小 81% 的同时,准确率提升 3%,实现了高吞吐量、低延迟推理。
如何通过 DeepStream 8 推理构建器打包和部署模型
获得经 TAO 训练和蒸馏的 RT-DETR 模型后,下一步是将其部署为推理微服务。全新的 NVIDIA DeepStream 8 推理构建器是一款低代码工具,可快速将模型想法转化为独立应用或可部署微服务。
使用推理构建器仅需提供 YAML 配置文件、Dockerfile 和可选的 OpenAPI 定义,工具将自动生成 Python 代码,连接数据加载、GPU 加速预处理、推理和后处理各阶段,并可暴露 REST 接口用于微服务部署。
该工具专为自动化生成推理服务代码、API 层和部署制品而设计(基于用户提供的模型和配置文件),无需手动开发服务器、请求处理和数据流相关的样板代码 —— 通过简单配置,推理构建器即可处理这些复杂工作。
视频:学习如何使用 NVIDIA DeepStream 推理构建器部署 AI 模型(https://youtu.be/yj11L8rFC30)
部署步骤
- 定义配置
- 创建
config.yaml文件,描述模型和推理流水线 - (可选)如需明确 API schema 定义,可添加
openapi.yaml文件 - 执行 DeepStream 推理构建器
- 提交配置文件至推理构建器
- 工具将利用推理模板、服务器模板和工具(如编解码器)自动生成项目代码
- 输出包含推理逻辑、服务器代码和辅助工具的完整包(
infer.tgz推理服务包) - 查看生成的代码
- 解压后的项目结构清晰,包含:
- 配置目录:
config/ - 服务器逻辑:
server/ - 推理库:
lib/ - 工具集:资源管理器、编解码器、响应器等
- 构建 Docker 镜像
- 使用参考 Dockerfile 容器化服务
- 执行命令:
docker build -t my-infer-service - 通过 Docker Compose 部署
- 执行命令:
docker-compose up启动服务 - 服务将在容器内加载模型
- 提供服务
- 推理微服务已正式运行
- 终端用户或应用可向暴露的 API 端点发送请求,直接获取模型预测结果
实时视觉检测的其他应用场景
除 PCB 缺陷检测外,TAO 和 DeepStream 还可应用于汽车、物流等行业的异常检测。
开始构建实时视觉检测流水线
借助 NVIDIA DeepStream 和 NVIDIA TAO,开发者正在突破视觉 AI 的应用边界 —— 从快速原型开发到大规模部署均可高效实现。
DeepStream 8.0 为开发者提供推理构建器等强大工具,简化流水线创建流程,并提升复杂环境下的跟踪准确率;TAO 6 通过领域自适应、自监督学习及知识蒸馏,充分释放基础模型的潜力。这意味着更短的迭代周期、更高效的无标签数据利用,以及可直接投入生产的推理服务。
准备好开始探索了吗?
