
借助 NVIDIA 数据中心监控提升 GPU 集群效率
随着生成式 AI、大型语言模型(LLM)、计算机视觉等应用的快速发展,高性能计算(HPC)用户的业务规模持续扩张,对 GPU 资源的需求呈爆发式增长。因此,GPU 效率已成为基础设施优化中日益重要的焦点。在 GPU 集群规模庞大的情况下,即便是微小的效率损耗,也会演变为严重的集群瓶颈。
优化 GPU 使用率可带来多重价值:
- 显著降低运营成本;
- 让更多工作负载能够访问 GPU 资源;
- 提升开发者体验和工作吞吐量。
本文将介绍在大规模集群中减少 GPU 闲置浪费的实践流程 —— 这一举措有望节省数百万美元的基础设施成本,同时提升整体开发者生产力和资源利用率。在行业语境中,“浪费” 指 GPU 未被充分利用,主要原因包括集群管理效率不足、优化缺失或故障未及时解决等。

理解 GPU 资源浪费
GPU 资源浪费可分为多个类别,每种类别都需要针对性的解决方案。最常见的问题之一是作业占用了 GPU 资源,却未执行实质性工作,处于完全闲置状态。以下表格汇总了各类浪费问题的核心信息:
GPU 资源浪费问题 | 解决方案 | 观察到的发生频率 |
|---|---|---|
硬件故障导致的资源不可用 | 实施集群健康效率计划,对硬件进行监控、追踪并批量部署修复方案 | 低 |
GPU 硬件正常但未被占用 | 推行占用率效率计划,核心优化调度器效率 | 低 |
作业占用 GPU 但未高效利用计算资源 | 开展应用优化工作 | 高 |
作业占用 GPU 但完全未使用 | 实施闲置浪费减少计划 | 中 |
表 1:大规模基础设施中 GPU 集群效率挑战、针对性解决方案及发生频率汇总
在运营支持多样化工作负载的研究集群过程中,遇到了各类预期内和意外的 GPU 闲置原因。区分这些因素虽具挑战性,但对于确保研究人员生产力不受影响至关重要。发现导致 GPU 闲置的多个常见模式,包括:
- 纯 CPU 数据处理作业:在 GPU 节点上运行但未使用 GPU 资源;
- 配置错误的作业:因节点独占设置导致 GPU 过度分配;
- 卡死的作业:表面显示活跃但实际处于停滞状态;
- 基础设施开销:容器下载或数据获取过程中的延迟;
- 无人值守的交互式会话:遗留作业持续占用资源。
减少 GPU 资源浪费的方法
为大规模减少 GPU 闲置浪费,重点关注集群实际运行行为,而非依赖理论利用率目标。当潜在的浪费模式显现后,发现:通过一系列针对性的运营技术,而非大规模的架构调整,就能显著提升效率。
基于上述分析,优先推行了四项核心技术:
- 数据收集与分析:收集利用率数据和作业轨迹,识别导致 GPU 浪费的主要因素;
- 指标开发:制定专用的 GPU 闲置浪费指标,用于跟踪基准数据并衡量长期改进效果;
- 客户协作:直接与工作流程导致高闲置率的用户和团队合作,解决效率问题;
- 解决方案规模化:构建自助工具和自动化流水线,让改进方案能覆盖整个集群。
构建 GPU 利用率指标流水线
为构建 GPU 利用率指标流水线,将 NVIDIA 数据中心 GPU 管理器(DCGM)的实时遥测数据与 Slurm 作业元数据相结合,形成工作负载实际消耗 GPU 资源的统一视图。尽管 Slurm 提供的数据粒度为 5 分钟,但足以与更高分辨率的 DCGM 字段进行关联。
这一过程的关键支撑是 NVIDIA DCGM Exporter 的 HPC 作业映射功能 —— 通过该功能,GPU 活动可标记精确的作业上下文。这为测量闲置时间、识别浪费来源以及将效率问题归因于特定工作流程奠定了基础。
图表说明:展示多 GPU 集群中 GPU 利用率数据的收集和处理流程。
左侧四个绿色图标代表不同的 GPU 集群,向两个数据存储库传输数据:DCGM 遥测数据库和 Slurm 作业元数据库。两个数据源均接入中央聚合流水线(以绿色圆形处理图标表示),该流水线将 GPU 活动与作业上下文对齐,最终输出标注为 “每个作业每小时 GPU 浪费指标” 的数据存储库。该流程直观呈现了如何结合 GPU 遥测数据和作业信息,量化每个工作负载的 GPU 闲置时间。
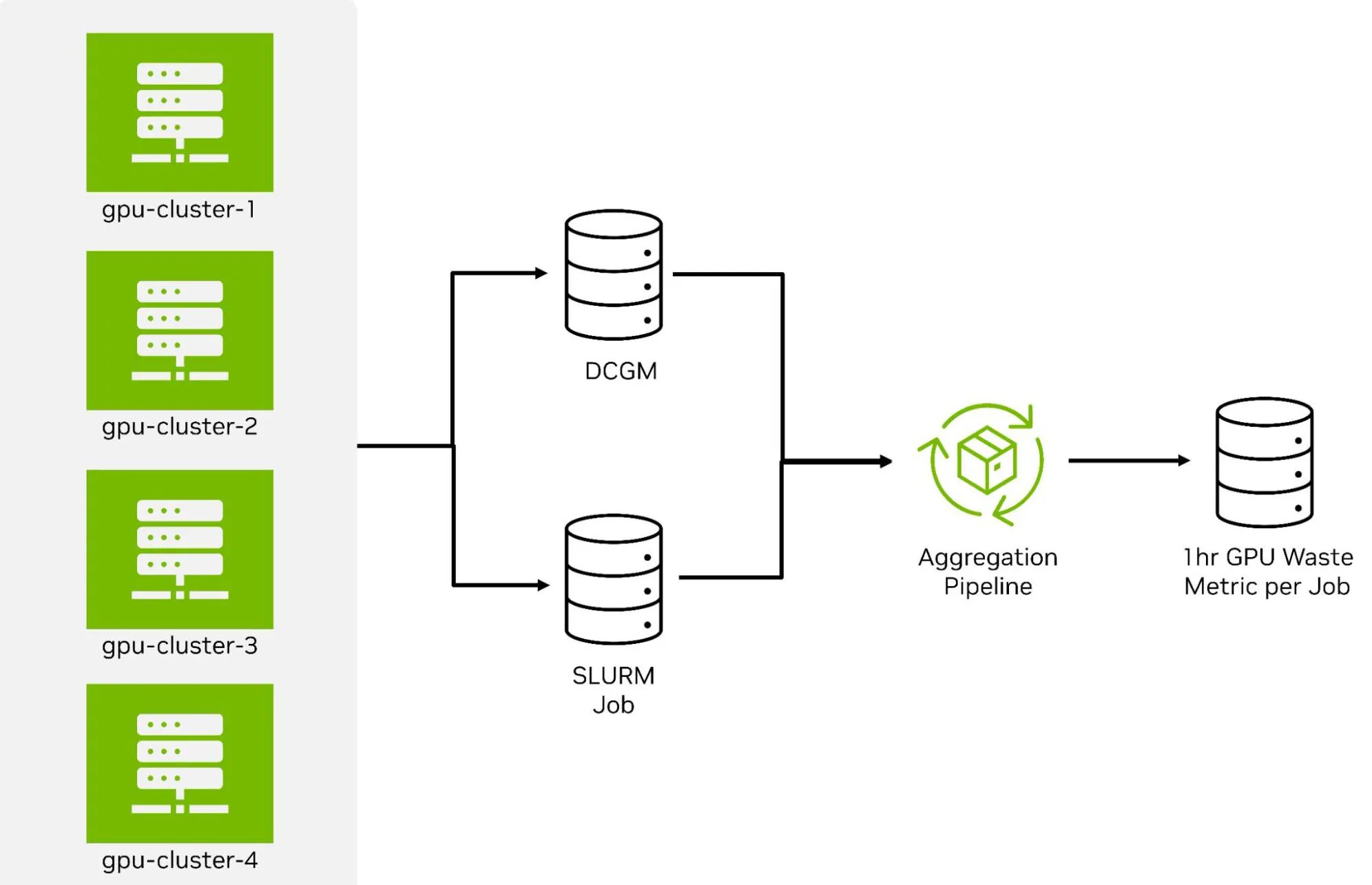
图 1:融合 DCGM 遥测数据与 Slurm 作业数据以计算单作业 GPU 闲置浪费的流水线
流水线构建完成后,下一步是分析驱动研究的 DCGM 信号,并定义 GPU 闲置行为的识别标准。以下章节将详细说明所使用的指标以及判断作业导致 GPU 闲置的标准。
借助 DCGM 实现精细化监控
DCGM 是 NVIDIA 推出的面向数据中心 GPU 的管理和监控框架,提供功能强大的工具集和 API,支持大规模 GPU 资源的观察、控制和优化。
DCGM 的核心是提供多种指标和遥测数据,这些数据以 “字段”(fields)为单位进行组织。每个字段都有唯一的标识符和字段编号 —— 涵盖从 GPU 温度、时钟速度到利用率和功耗等各类信息。完整的字段列表可参考官方文档。
这些指标通常包括以下两类核心内容:
- GPU 利用率指标:衡量 GPU 的活跃程度,包括核心计算负载、内存使用量、I/O 吞吐量和功耗等指标,帮助判断 GPU 是否在执行有效工作或处于闲置状态;
- GPU 性能指标:反映 GPU 的运行效率,包括时钟速度、热状态和节流事件等指标,用于评估性能并检测瓶颈。
在 GPU 浪费指标计算中,以 DCGM_FI_DEV_GPU_UTIL 字段作为 GPU 整体活动的主要指标。未来的分析迭代计划转向 DCGM_FI_PROF_GR_ENGINE_ACTIVE 字段,以更精确地捕捉 GPU 引擎的利用率。
作业闲置的判定标准
AI 和机器学习(ML)工作负载通常会出现 GPU 未被主动使用的情况,这既可能源于基础设施效率问题,也可能是工作负载的自然特性。观察到以下几种常见场景:
- 容器下载:在多主机间拉取容器时,作业启动可能会停滞,尤其是在高负载或镜像仓库性能不佳的情况下;
- 数据加载与初始化:训练工作流程在 GPU 计算开始前,可能需要等待从存储系统检索数据;
- 检查点读写:在检查点操作期间,GPU 利用率可能会下降;
- 模型特定行为:部分模型类型在设计上本身无法充分利用 GPU 资源。
为覆盖这些场景,我们制定了长期闲置的判定阈值,并采用了保守定义:当检测到 GPU 连续一小时完全无活动时,判定该工作负载为闲置状态。
用于分析 GPU 集群效率的服务与工具
GPU 浪费指标确立后,重点转向数据的实用化 —— 不仅要发现闲置行为,还要以直观的方式呈现,让研究人员和平台团队能快速定位效率问题的根源。为此,我们构建了多个可视化层和运营工具,将底层遥测数据转化为清晰的信号和自动化干预方案。
GPU 浪费指标主要通过两个核心界面呈现:
- 用户门户:NVIDIA 内部门户,机器学习研究人员可查看集群、用户和作业级别的 GPU 使用情况,更轻松地识别闲置模式;
- OneLogger:统一监控层,将作业阶段与 GPU 遥测数据相关联,让用户更清晰地了解效率问题的出现环节。
这些工具共同提升了 GPU 浪费问题的透明度和可操作性。
工具 1:闲置 GPU 作业清理器(Idle GPU Job Reaper)
NVIDIA开发了一项服务,用于识别并清理不再使用 GPU 的作业 —— 本质上为集群提供 “自动清理” 功能。由于集群运行的工作负载高度多样化,且无统一的抽象层,允许用户调整清理器的阈值,以匹配其作业的预期闲置特性。这使得系统能够区分可预测的闲置阶段和真正的资源浪费。
该服务的核心流程如下:
- 通过 DCGM 指标监控 GPU 利用率;
- 标记长期闲置的作业;
- 终止这些作业并回收闲置 GPU;
- 记录并报告回收的资源容量和用户配置,为进一步优化提供数据支持。
这种方式确保了集群中预期和意外的闲置模式都能得到一致处理。
工具 2:作业检查工具(Job Linter)
NVIDIA开发了作业检查工具,用于检测配置错误的工作负载 —— 例如,作业请求独占节点上的所有 GPU,但仅使用其中一部分,导致剩余设备闲置。该工具的未来版本计划扩展覆盖范围,以检测更多类型的配置错误模式。
工具 3:失效作业处理工具(Defunct Jobs Tooling)
集群中的限时作业常常导致用户提交一连串后续作业,这些作业即使不再需要,仍会在队列中等待并占用预留资源。此外,用户作业中的任何故障都会因大量重复运行而加剧影响。这些失效的作业提交会消耗调度周期并产生不必要的开销。为此,NVIDIA开发了相关工具,用于自动检测并取消此类冗余作业,减少浪费并提升整体调度效率。
经验总结与后续计划
在大规模集群中,微小的效率问题会迅速放大。一旦合适的指标到位,仅通过提升透明度,就能推动团队形成更强的责任意识和更优的操作行为。除了指标之外,研究人员还需要可操作的指导,以提升其工作负载的效率。只有广泛采用这些实践方法,才能实现集群层面的效率提升。监控工具需要直接融入日常工作流程才能发挥实效 —— 在作业提交时和实验跟踪界面中提供利用率洞察,被证明是至关重要的。
通过这些举措,NVIDIA将 GPU 浪费率从约 5.5% 降至 1% 左右。这一显著改进不仅转化为可观的成本节约,还为高优先级工作负载释放了更多 GPU 资源。这些成果表明,运营层面的效率问题一旦被发现并解决,就能为集群回收大量可用资源。
此次测量过程还暴露了多个导致闲置的基础设施短板。NVIDIA计划通过一系列改进进一步减少浪费,例如加快容器加载速度、优化数据缓存、支持长期运行的作业以及增强调试工具等。
