
使用 NVL72 机架规模系统上的宽专家并行扩展大型 MoE 模型
现代 AI 工作负载已远超出单 GPU 推理服务范畴。模型并行(一种高效跨多个 GPU 分配计算任务的技术)已成为可扩展、最先进部署方案的基础。性能最优的模型正越来越多地采用混合专家(MoE,Mixture-of-Experts)架构 —— 该架构比稠密模型更高效,原因是其每 token 仅激活部分训练参数。然而,扩展 MoE 模型会带来更复杂的并行处理、通信传输和调度调度需求,必须经过精心优化才能解决。
专家并行(EP,Expert Parallelism)是将专家模块战略性分布到多个 GPU 的技术,对克服上述挑战、释放可扩展性能至关重要。随着 DeepSeek-R1 等拥有 256 个专家模块、6710 亿参数的模型持续迭代,业界亟需全新工具 —— 例如 NVIDIA TensorRT-LLM 的宽专家并行(Wide-EP,Wide Expert Parallelism)技术。该技术可提升大规模部署效率,同时优化性能表现与总拥有成本(TCO,Total Cost of Ownership)。
本文将详细解析大规模 EP 技术如何影响性能表现,并重塑 NVL72 机架规模系统场景下的推理经济学。
如何实现大规模专家并行
专家并行(EP)是一种模型并行技术,通过将 MoE 模型的专家模块分布到多个 GPU,充分利用聚合计算能力与内存带宽。在小规模场景中,EP 技术通过平衡设备间工作负载,可减轻内存压力并维持高利用率。
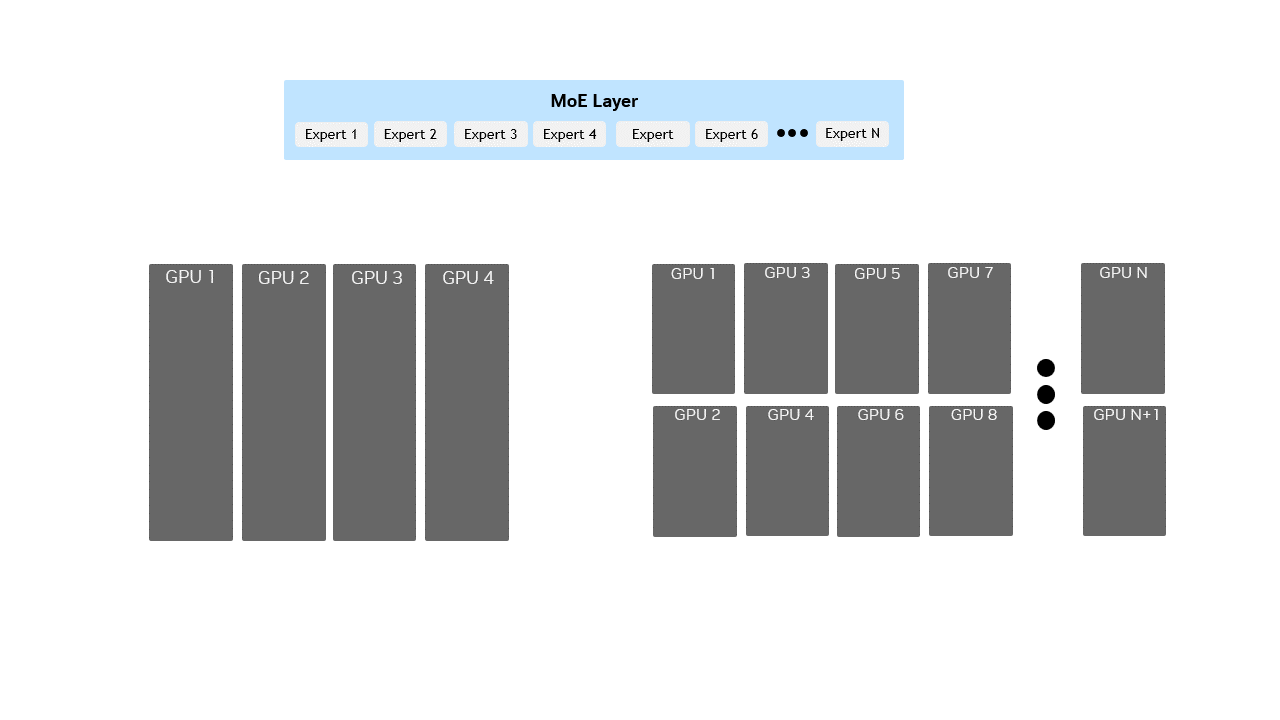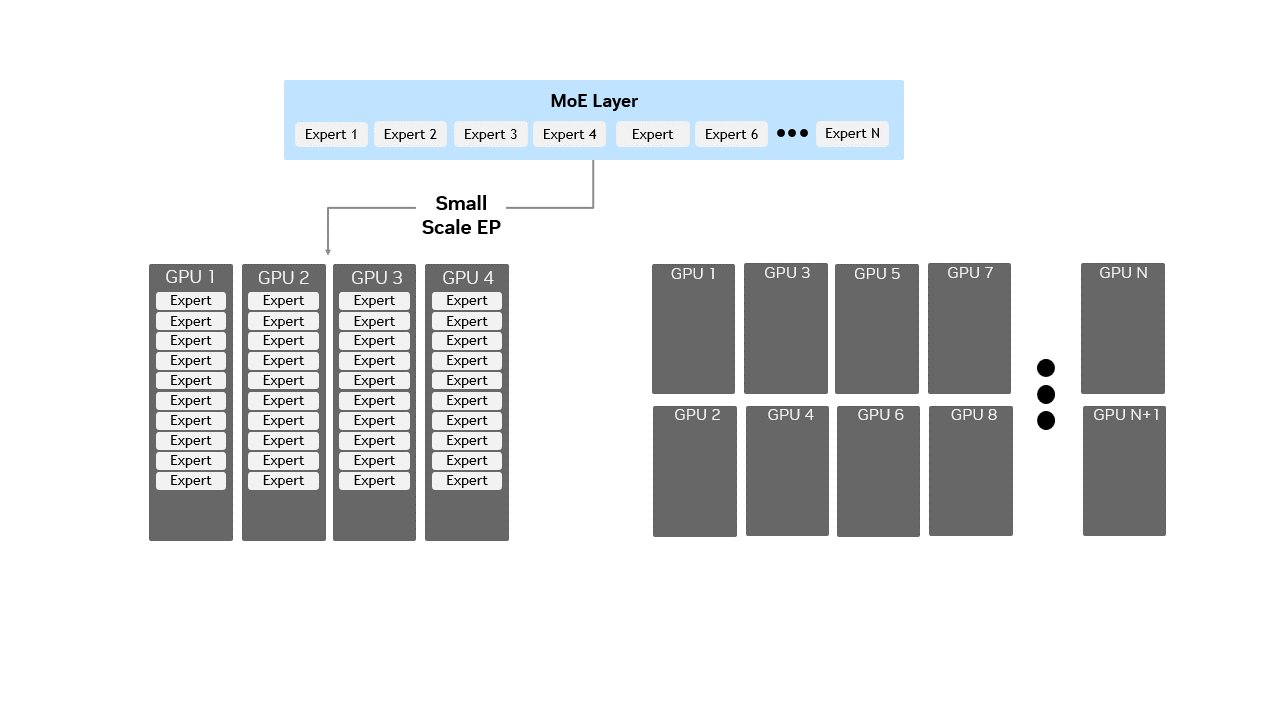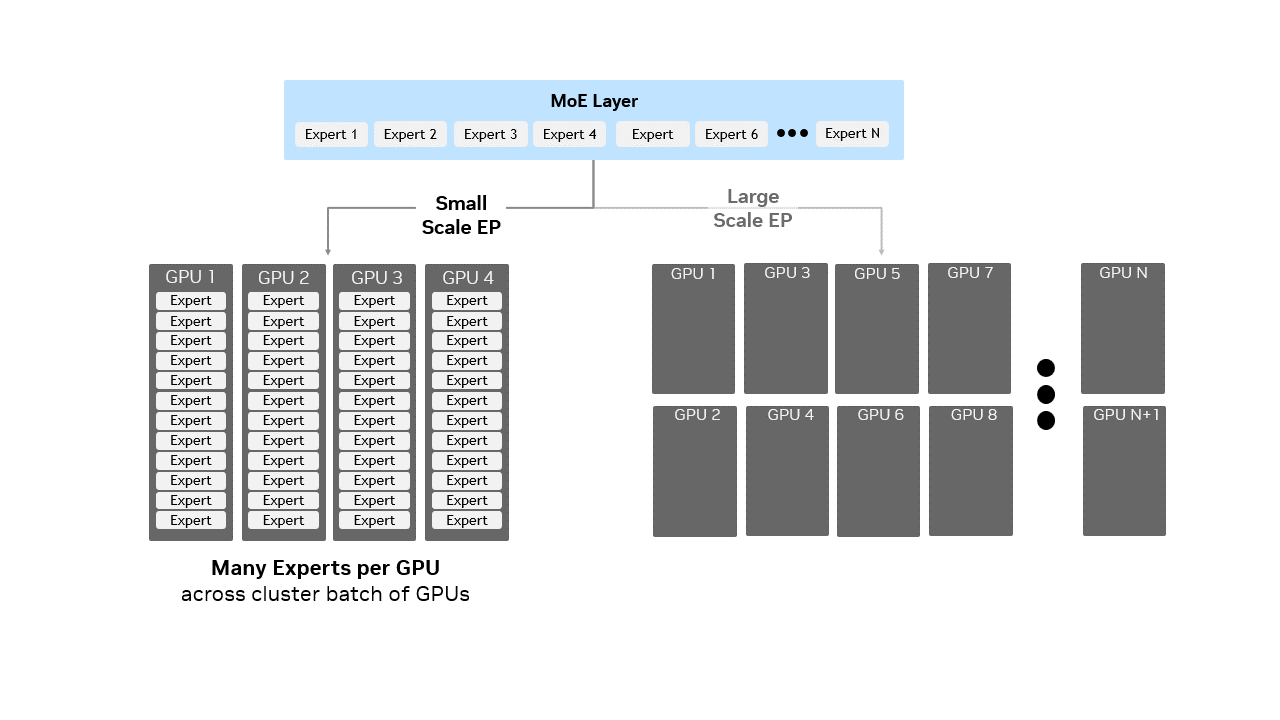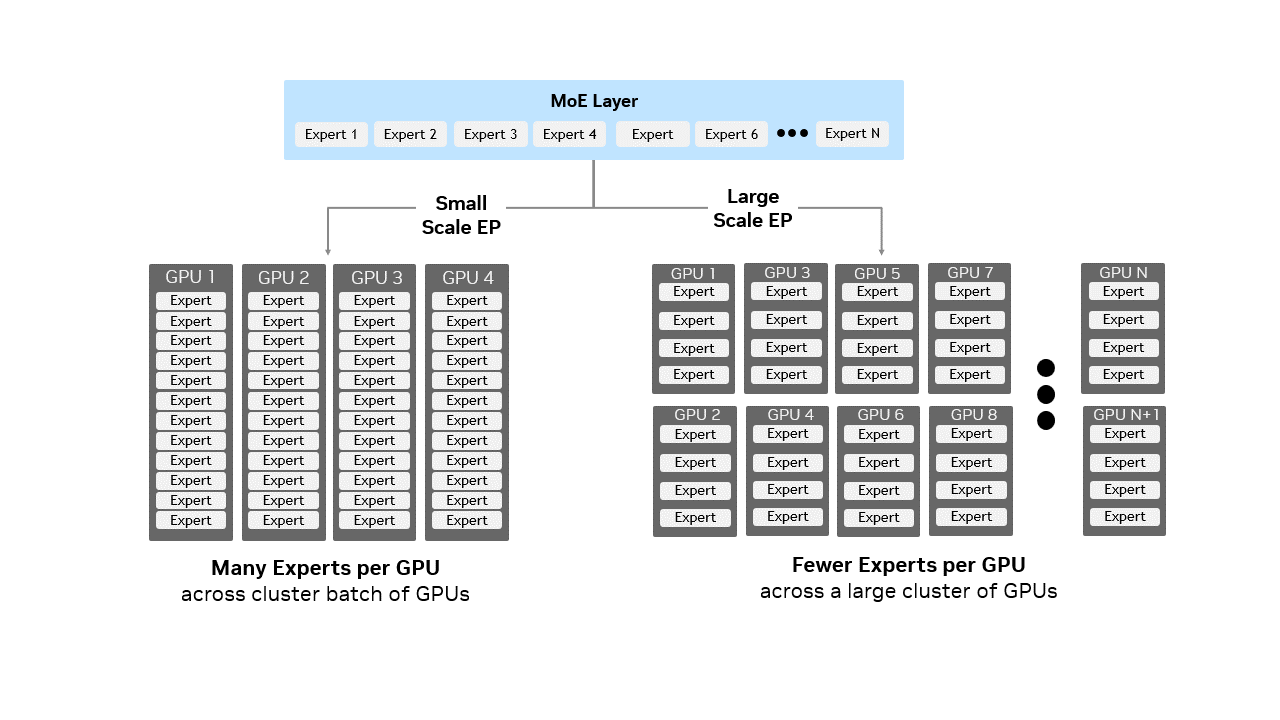
图 1 混合专家(MoE)层中小规模与大规模专家并行(EP)的对比示意图:小规模 EP 在少量 GPU 上每个 GPU 打包多个专家模块,而大规模 EP 在大量 GPU 上每个 GPU 分布较少专家模块,直观呈现了专家模块分布方式如何适配更大集群的高效推理需求。
随着 DeepSeek-R1 等模型扩展至数千亿参数、数百个专家模块,这类技术必须扩大应用范围 —— 即本文所指的 “大规模 EP”。本文定义的大规模 EP,特指将专家模块分布到 8 个及以上 GPU 的部署方式。该方式可提升聚合带宽以实现更快的权重加载,并支持更大的有效批次大小,进而提高整体 GPU 利用率。
大规模 EP 面临的内存和计算挑战
MoE 模型的核心优势之一是推理过程中仅激活少量专家模块,显著降低每 token 的计算需求。为实现这一特性,MoE 模型需在 “每 token 每层” 的维度动态加载被激活专家的权重。在高吞吐量、延迟受限的场景中,权重加载开销可能迅速成为 “MoE 分组通用矩阵乘法(GroupGEMMs,Group General Matrix Multiplications)” 这类计算过程的主要瓶颈。
MoE 分组通用矩阵乘法(GroupGEMMs)类似于将所有 token 同时引导至同一收银通道,以便通过单次高效批次完成处理。实际应用中,它是一种将每个专家模块的 token 批量整合为单次大型计算的矩阵乘法技术。该技术虽能提升算术强度,但要求在乘法运算前将每个专家模块的权重加载至片上内存 / 寄存器中。
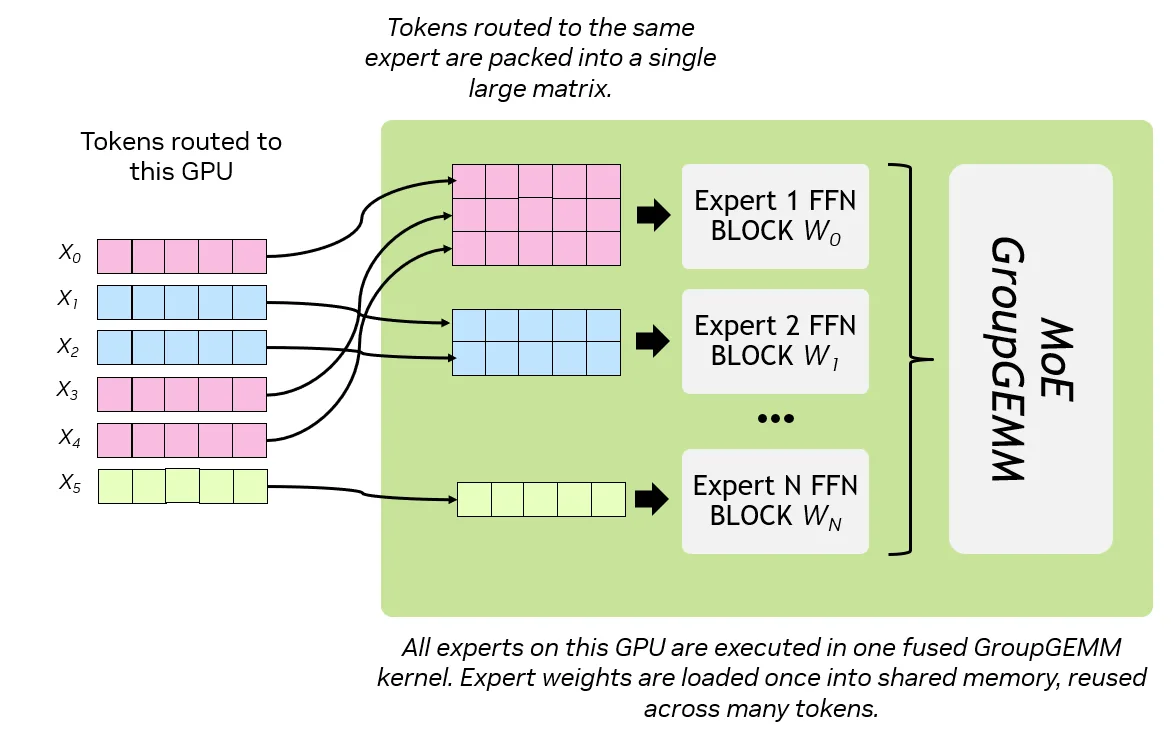
图 2 token 路由与 GroupGEMM 处理示意图:发送至 GPU 的输入 token 被路由至多个专家模块;同一专家模块的 token 被打包为矩阵,由该专家的前馈块处理。MoE GroupGEMM 内核通过单次融合执行所有专家块运算,将权重加载至共享内存并重复利用,实现跨多个 token 的高效、高吞吐量计算。
大规模 EP 通过在专家并行配置中引入更多 GPU,解决了部分 MoE GroupGEMM 瓶颈,有效减少了每个 GPU 承载的专家模块数量。具体带来以下优化效果:
- 更低的权重加载压力(每个 GPU 承载的专家权重规模更小)
- GroupGEMM 内核更易实现权重复用(更高的算术强度 —— 每字节加载权重可支持更多浮点运算次数(FLOPs))
- 内核内部计算 / 内存平衡更优
尽管大规模 EP 解决了小规模 EP 的部分局限,但也引入了新的系统级约束,增加了大型 MoE 模型的扩展难度。TensorRT-LLM 的 Wide-EP 技术通过算法层面优化计算与内存瓶颈,同时在系统和架构层面解决工作负载管理问题,有效应对了这些约束。
下文将详细说明 Wide-EP 技术与 GB200 NVL72 的结合,如何为可扩展、高效的 MoE 推理提供基础支撑。
系统设计与架构
扩展专家并行技术不仅需要增加 GPU 数量,更依赖于能保持内存移动与通信传输高效性的系统设计与架构。互连带宽与拓扑结构构成核心基础,确保激活值与权重能在设备间顺畅传输。
在此基础上,经过优化的软件与内核通过通信原语、带宽感知调度和负载均衡技术,管理专家模块间的通信流量。这些能力共同保障了大规模 EP 的实用性与高效性。
通过 NVLink 减轻分布式专家通信开销
大规模 EP 的最大瓶颈之一是通信开销。在推理的解码阶段,分布式部署的专家模块必须交换信息,以整合系统中多个 GPU 的输出结果。例如,当将 DeepSeek-R1 的 256 个专家模块分布到 64 个 GPU(每 token 激活 8 个专家模块)时(见下文图 3),通信成本取决于特定层激活的专家模块及其权重存储位置。
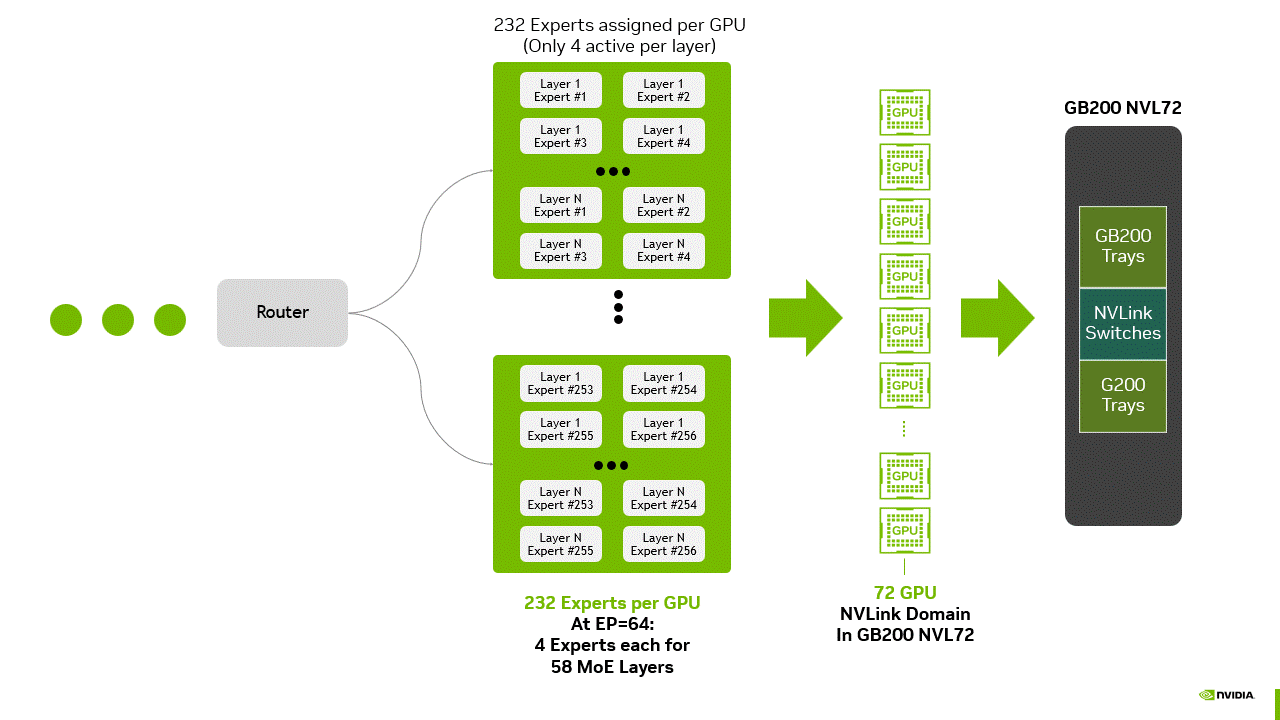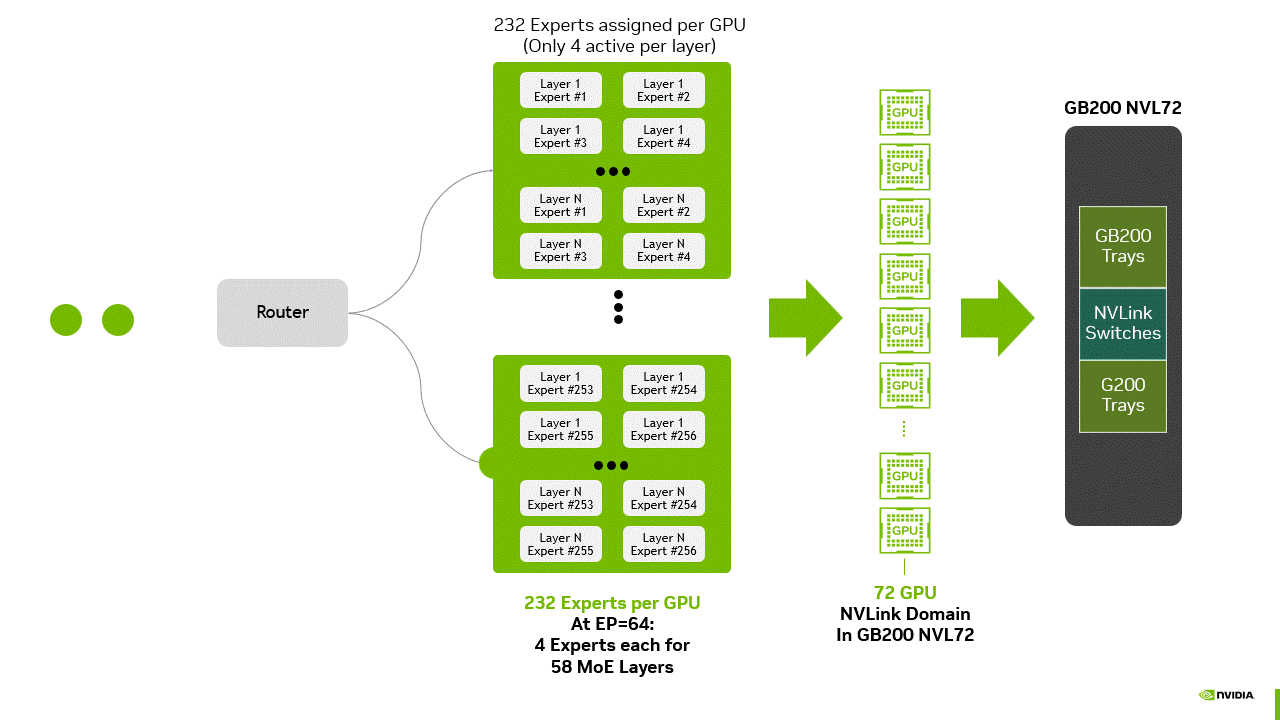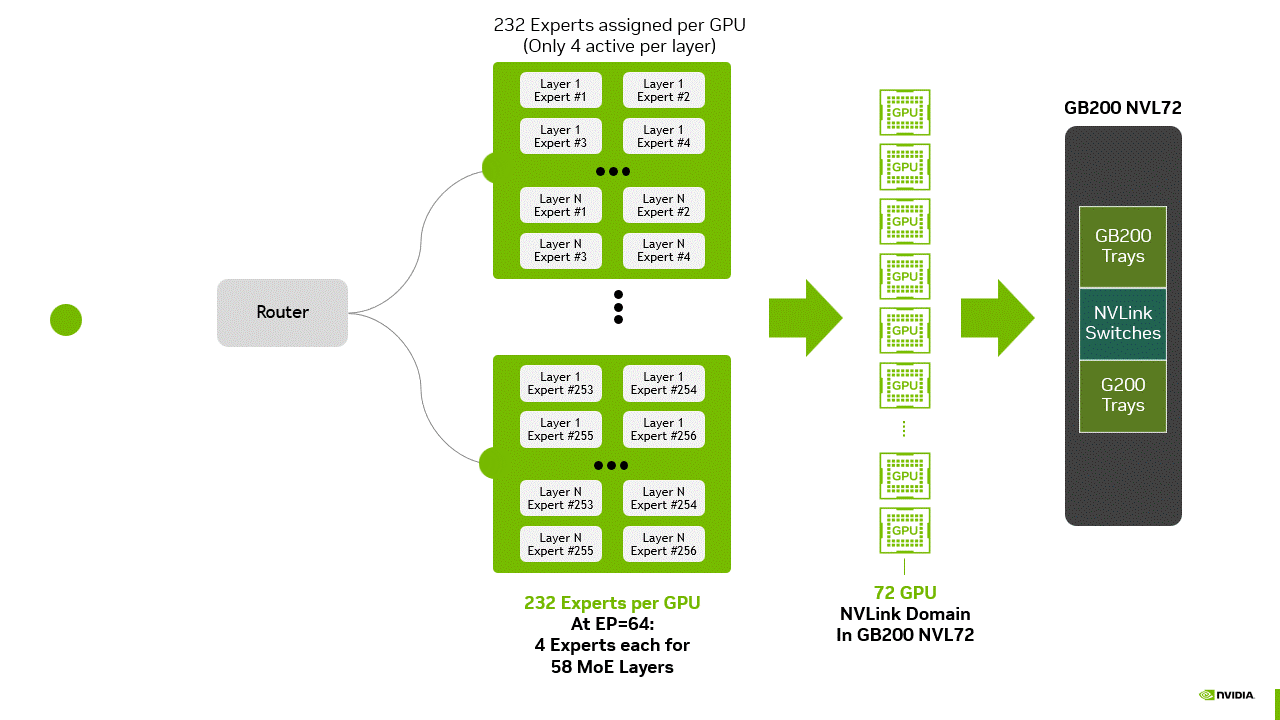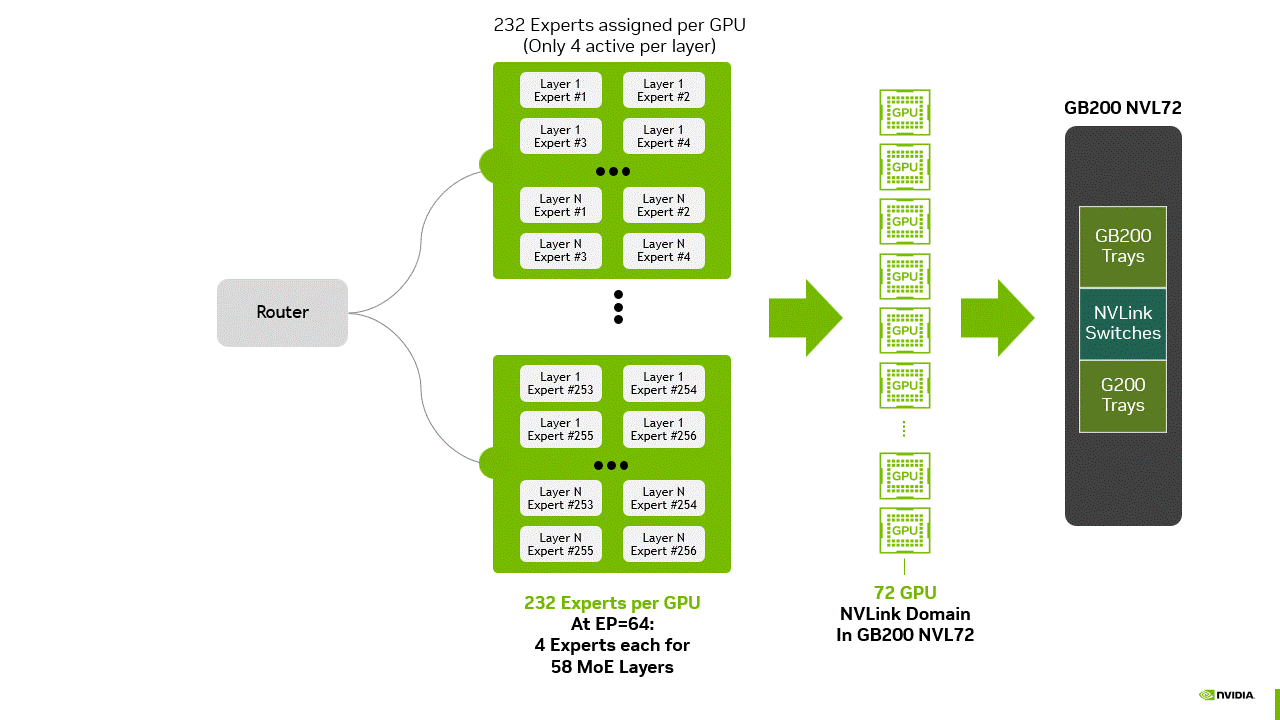
图 3 大规模 MoE 推理部署示意图:路由器将 token 分配至各 GPU,每个 GPU 包含 232 个专家块(覆盖 58 层,每层 4 个专家模块,EP=64 配置)。每层仅激活 4 个专家模块,所有 GPU 通过 GB200 NVL72 托盘与交换机连接,构成 NVLink 域,为下一代 AI 数据中心基础设施提供高效专家并行能力与高带宽通信支持。
尽管大规模 EP 减少了被激活专家的权重加载开销,但这些收益可能被 “token 收集集合通信操作” 抵消 —— 该操作需整合分布式输出结果,并在传递至下一个 Transformer 块或最终 softmax 层前重新排序 token。若缺乏 NVL72 提供的 130 TB/s 聚合带宽,这种通信模式的复杂性与开销将使大规模 EP 失去实用价值。
使用 NVIDIA 集合通信库(NCCL)优化专家路由内核
MoE 模型通过路由机制为每个 token 动态选择最合适的专家模块。这意味着每个 Transformer 块在经过专家层后,都需要执行 token 分发与聚合操作。其中涉及的全对全(all-to-all)通信操作可能迅速饱和本已受内存限制的解码阶段。
为解决这些挑战,需要定制化 EP 通信内核。针对 GB200 NVL72,我们开发了定制化内核,以解决 CUDA 图(CUDA Graph)与多种机架规模部署场景的兼容性问题。值得关注的是,我们专门设计了高性能 NVIDIA 集合通信库(NCCL,NVIDIA Collective Communications Library)内核,用于处理大规模 EP 部署中的非静态数据量。这些定制化 EP 内核能够直接从 GPU 内存读取通信数据量,并充分利用 NVL72 的聚合内存资源。
负载均衡宽专家
负载均衡是经典的分布式系统技术,根据资源可用性分配工作任务,以最大化系统利用率同时避免单一组件过载。在大规模 EP 工作负载中,负载均衡技术用于在可用 GPU 之间分配专家模块。例如,在运行 Wide-EP 版 DeepSeek-R1(EP=64 配置,确保均匀分配)的 GB200 NVL72 机架中,我们为每个 GPU 的每层分配 4 个专家模块,单个 GPU 总共承载 232 个专家模块。
为避免出现 “热门专家模块” 过度集中于同一 GPU(导致过载),而其他 GPU 承载的 “冷门专家模块” 处于闲置状态的负载不均衡问题,Wide-EP 的专家并行负载均衡器(EPLB,Expert Parallel Load Balancer)采用特定策略,将热门专家模块与冷门专家模块重新分布。这一过程会触发权重更新,我们通过容器化设计解决了该问题 —— 允许专家模块在容器分配中灵活调度,且不破坏 CUDA 图的完整性。权重更新操作采用非阻塞方式执行,安排在正向传播间隙进行。
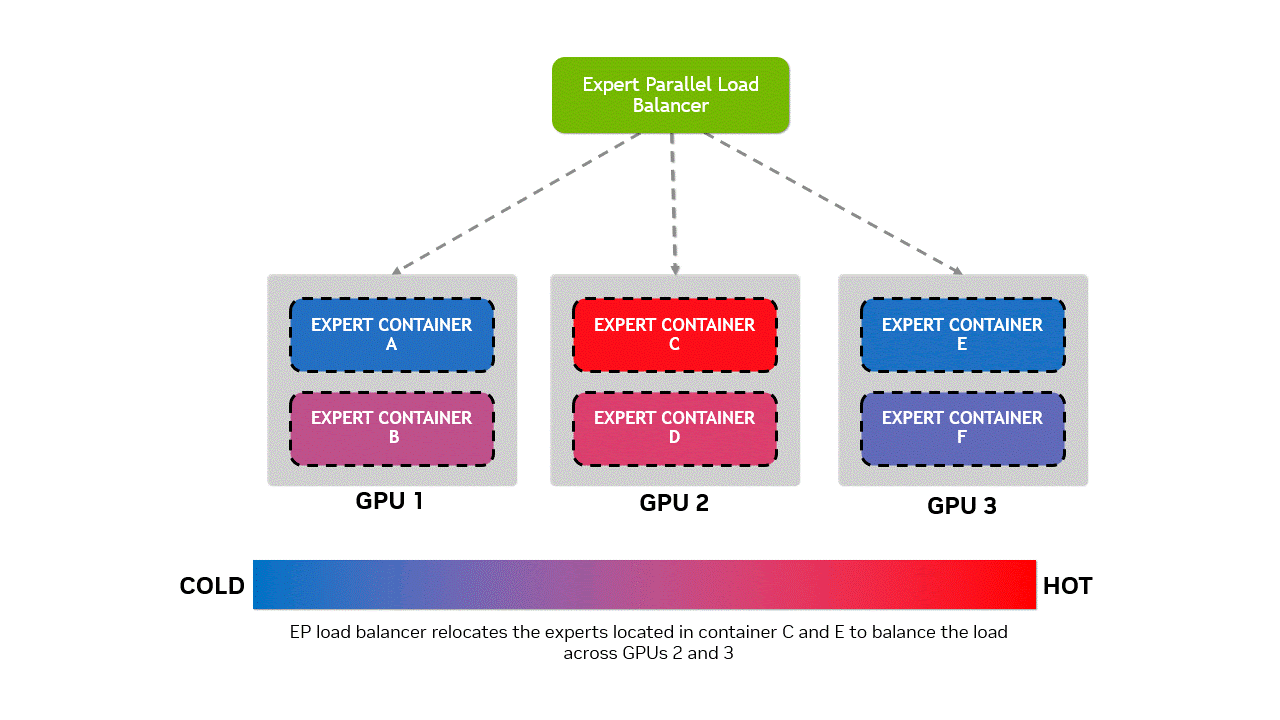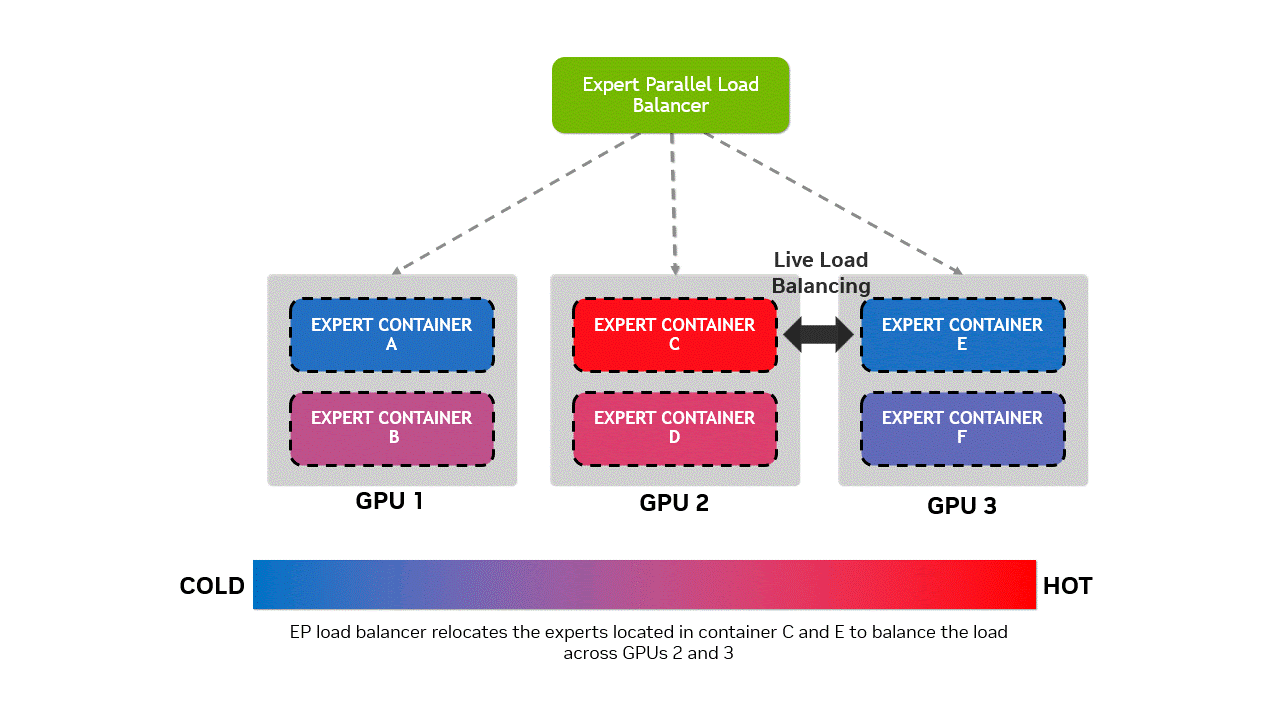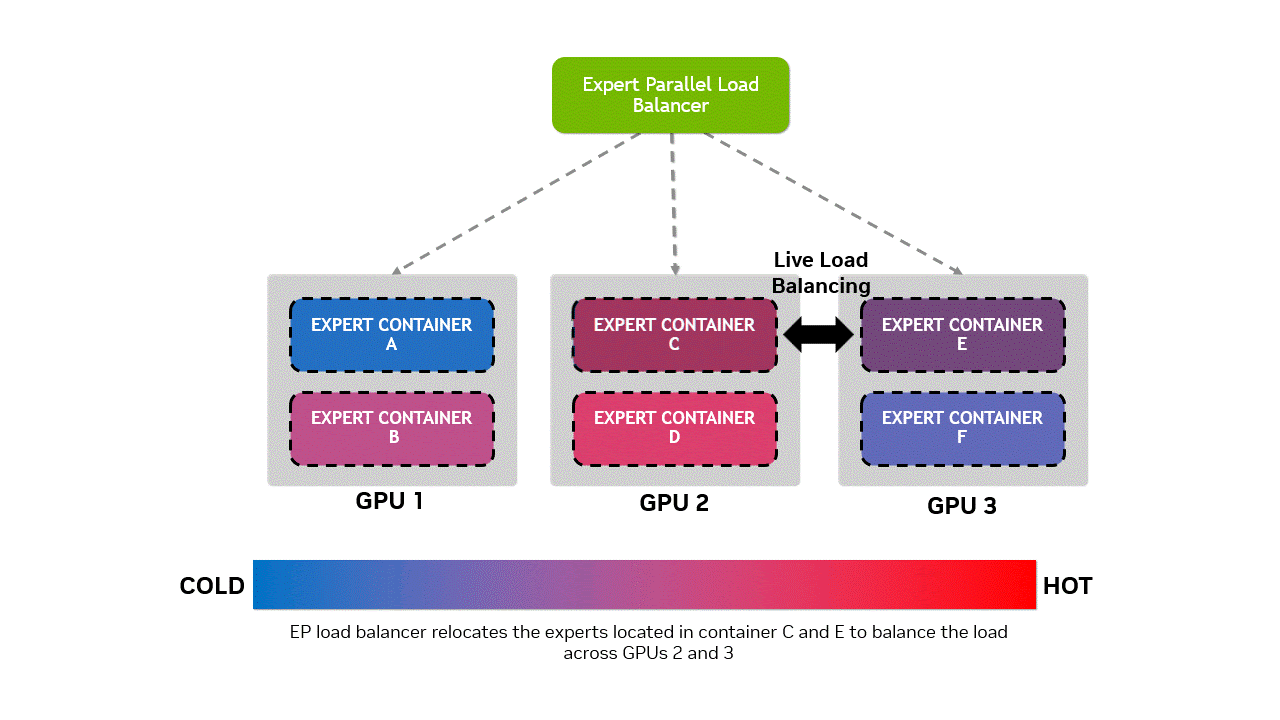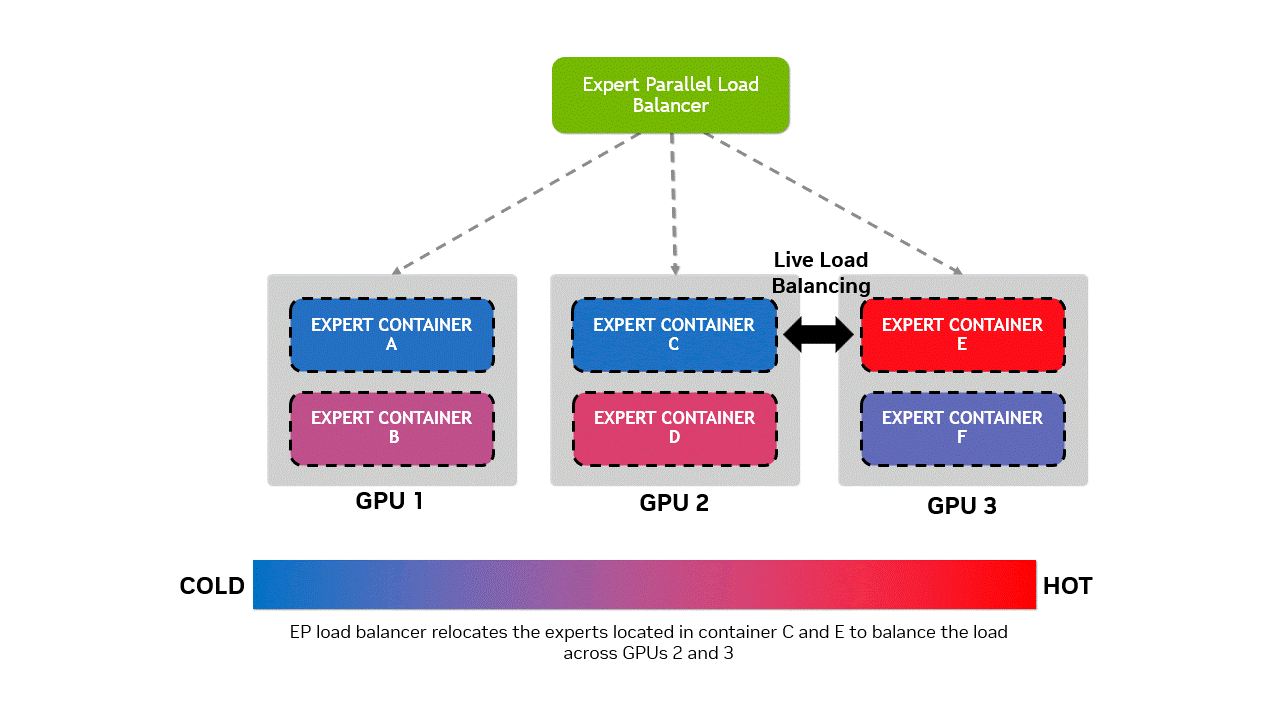
图 4 专家容器放置优化示意图:对比三个 GPU 上的专家容器分布状态。实时 EPLB 启动前,专家模块分布不均 ——GPU 2 过载,GPU 3 利用率不足;实时 EPLB 启动后,专家模块在各 GPU 间重新分配,实现计算负载均衡。底部水平条直观展示了 GPU 从 “冷态(负载不足)” 到 “热态(过载)” 的状态变化,突显 EPLB 在资源均衡方面的优化效果。
EPLB 支持两种运行模式:
- 静态 EPLB:基于历史数据模式预计算专家模块到 GPU 的映射关系,优化专家分配效率。
- 在线 EPLB:在运行时动态重新分配专家模块,实时适配工作负载变化。
尽管静态 EPLB 相比无 EPLB 方案已有显著改进,但在线 EPLB 能为实时生产系统提供最优负载均衡效果。在在线 EPLB 的初始实现过程中,我们解决了与实时权重更新相关的多个关键技术挑战。
Wide-EP 与 TensorRT-LLM 和 NVIDIA Dynamo 的协同
大规模部署 DeepSeek R1 或 Llama 4 等 MoE 模型时,推理性能取决于两大核心支柱:解耦服务(disaggregated serving)与 Wide-EP 技术。NVIDIA Dynamo 与 TensorRT-LLM 构成支持这两大支柱的软件核心,将传统性能瓶颈转化为大规模吞吐量提升与 GPU 高效利用的契机。下表详细对比了 Dynamo 与 Wide-EP 的差异与协同效应。
组件 | NVIDIA Dynamo | TensorRT-LLM Wide-EP |
|---|---|---|
角色 | 解耦推理的编排层 | 专家并行解码的执行引擎 |
优化范围 | 协调 GPU 池间的预填充(prefill)与解码阶段 | 每 GPU 分配少量专家模块,优化每 token 的内存与计算利用率 |
SLA 感知能力 | 支持 SLA 感知的自动扩展与动态速率匹配(首 token 响应时间 TTFT、每次 token 响应时间 ITL) | 通过高效专家调度最大化批次规模,最小化延迟 |
流量适应能力 | 通过 Dynamo 规划器实时响应输入序列长度(ISL)/ 输出序列长度(OSL)波动 | 负载均衡专家模块分配,优化计算利用率 |
硬件协同能力 | 通过 Kubernetes + 规划器逻辑,扩展至解耦 GPU 域 | 利用高带宽域(如 NVL72)实现高效专家模块通信 |
表 1 NVIDIA Dynamo 与 TensorRT-LLM Wide-EP 的专家并行推理能力对比,重点展示两者在角色定位、优化范围、SLA 感知、流量适应及硬件协同方面的特性。
性能表现与工作负载经济学
当 GB200 NVL72 机架通过 NVLink 扩展形成一致性内存域后,大规模 EP 的优化效果取决于以下关键因素:
- 模型规模与专家模块数量:专家模块较少的小型模型从 Wide-EP 中获益有限,因为通信开销可能超过权重加载减少与分布式计算带来的收益。
- 系统延迟与并发目标:当吞吐量受延迟约束时,大规模 EP 的优势最为显著 —— 可在保持延迟不变的前提下,提升每 GPU 吞吐量。
- 硬件能力:聚合内存带宽、GPU 间带宽及实际计算性能,决定了系统能否达到最优并行度。
实际应用中,DeepSeek-R1 等模型是大规模 EP 的理想应用场景 ——TensorRT-LLM 的 Wide-EP 技术与 GB200 NVL72 机架规模系统结合,实现了效率与吞吐量的最佳平衡。下图帕累托前沿曲线展示了不同 EP 配置的性能表现。
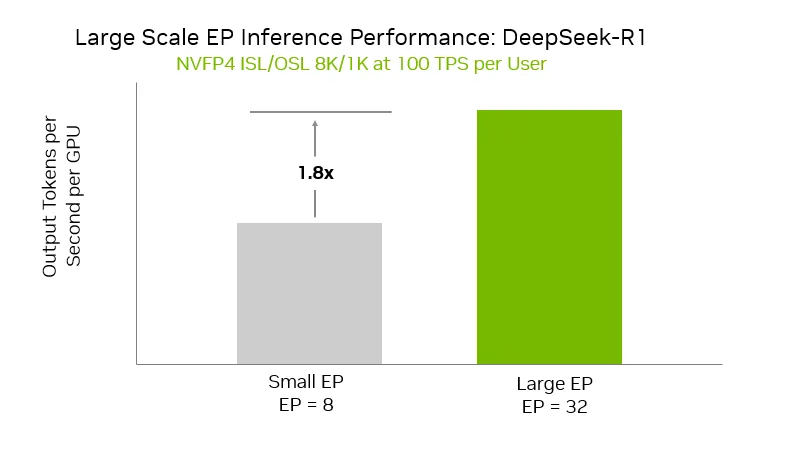
图 5 大规模 EP 性能对比图:对比 DeepSeek-R1 模型在小规模 EP(rank 8)与大规模 EP(rank 32)配置下的性能 —— 在用户吞吐量保持 100 token / 秒的前提下,大规模 EP(rank 32)的每 GPU 输出 token 速率达到小规模 EP(rank 8)的 1.8 倍。两种配置均采用解耦服务与多 token 预测(MTP)技术。
与小规模 EP 配置(EP8)相比,大规模 EP 配置(EP32)的每 GPU 吞吐量提升高达 1.8 倍,突显了大规模 EP 与 Wide-EP 技术的性能增益潜力。此外,还可结合多 token 预测(MTP)的推测解码技术进一步提升每用户 token 吞吐量 —— 该功能已与 Wide-EP 完全兼容。
总结
GB200 NVL72 上的 Wide-EP 技术为大型 MoE 模型的扩展提供了切实可行的方案。通过将专家模块分布到更多 GPU,不仅减轻了权重加载压力、提升了 GroupGEMM 效率,还利用 GB200 NVL72 的 130 TB/s 一致性 NVLink 域抵消了通信开销。测试结果显示,大规模 EP 配置的每 GPU 吞吐量较小规模 EP 提升高达 1.8 倍。这些性能增益重塑了吞吐量、延迟与利用率的平衡关系,为大规模推理提供了更高效率。
其更广泛的影响体现在系统经济学层面:通过提升并发能力与 GPU 效率,NVL72 上的 Wide-EP 技术提高了 “token / 秒 / GPU” 指标,降低了大型模型的服务成本。对开发者而言,这意味着可通过探索 TensorRT-LLM 中的 Wide-EP 技术找到最优部署配置;对研究人员而言,这为优化调度策略、负载均衡与解码算法创造了空间;对基础设施团队而言,这突显了 GB200 NVL72 如何改变万亿参数模型部署的总拥有成本(TCO)结构。
