
AI视频生成的“考官”来了!Q-Save:让视频评估既有“分数”又有“理由”

在Sora横空出世,Kling(可灵)、Hunyuan(混元)、Veo等视频生成模型“神仙打架”的今天,我们似乎每天都在被AI生成的视频刷屏。有的视频逼真到让人惊叹,有的却充满了“一眼假”的肢体扭曲或物理谬误。
这也引出了一个困扰行业已久的难题:当AI生成视频的数量呈指数级增长时,谁来判断它们的好坏?
来自上海交通大学、上海创新研究院以及腾讯混元的联合团队,在论文《Q-Save:面向生成视频评估的评分与归因》中交出了一份令人瞩目的答卷。他们不仅构建了一个拥有近万条视频的超精细数据集,还提出了一种能像人类影评人一样思考的评估模型——Q-Save。
它不仅能打分,还能告诉你原因。可以说,Q-Save正是AI生成视频迈向成熟所急需的那位“铁面考官”。

论文地址:https://arxiv.org/pdf/2511.18825v1
一、告别“黑盒”打分:为什么我们需要Q-Save?
过去,评估一个AI视频的质量,学术界常用MOS(平均意见分数)。这就像老师批改试卷只给一个“60分”,却不告诉学生错在哪里。
对于开发者来说,这种评估方式十分令人困扰。问题到底出在哪里?是因为画面模糊,还是因为人物动作不连贯,又或者是生成的视频与文本描述不符?
传统评估模型,如Inception Score(IS)或 Fréchet Inception Distance(FID),往往难以捕捉视频中复杂的时空逻辑。而Q-Save的核心突破在于,它引入了 “可解释性” 。其主张评估不能止步于数字,必须包含归因。
为实现这一点,研究团队基于三大核心维度构建了全新的评估体系:
•视觉质量:画面是否清晰?光影是否自然?是否存在奇怪伪影?
•动态质量:动作是否连贯?是否符合物理规律?(例如,水是否往上流,人物是否瞬移)。
•文本对齐:视频内容是否精准还原了用户的提示词?

经 Q-Save 微调后的 Qwen3-VL-8B-Instruct 模型与基准版本在评分(Score)和解释(Interpreter)能力上的对比。
二、打造最强“题库”:不仅有视频,更有思维链
要训练出一个懂行的AI考官,首先得有高质量的“教材”。研究团队并未直接抓取网络上的常见数据,而是精心构建了Q-Save数据集。
1.极其严苛的数据筛选
团队精选了6个当前主流的视频生成模型(包括Kling 1.6/2.0, Hunyuan, Veo2, Dreamina, Wanx),生成了近10,000个视频。
2.人类视角的“上帝审判”
他们招募了60名经过严格培训的评估员。值得注意的是,此处的标注并非简单的“好/坏”判断,而是要求评估员写下 “自然语言解释” 。
•训练集:每个视频由3人分别评估。
•测试集:每个视频由12人共同评判,确保结果客观公正。
最终,该数据集包含了近40,000条自然语言归因解释。这些解释数据被格式化为思维链风格,格式如下:
Q:请评价这个视频。
A:<think>分析:视频中人物的面部细节模糊,且背景在第3秒出现了不自然的闪烁,这属于视觉伪影...</think> 评分:Poor(差)
这种“先思考,后打分”的数据结构,是训练模型逻辑推理能力的关键。
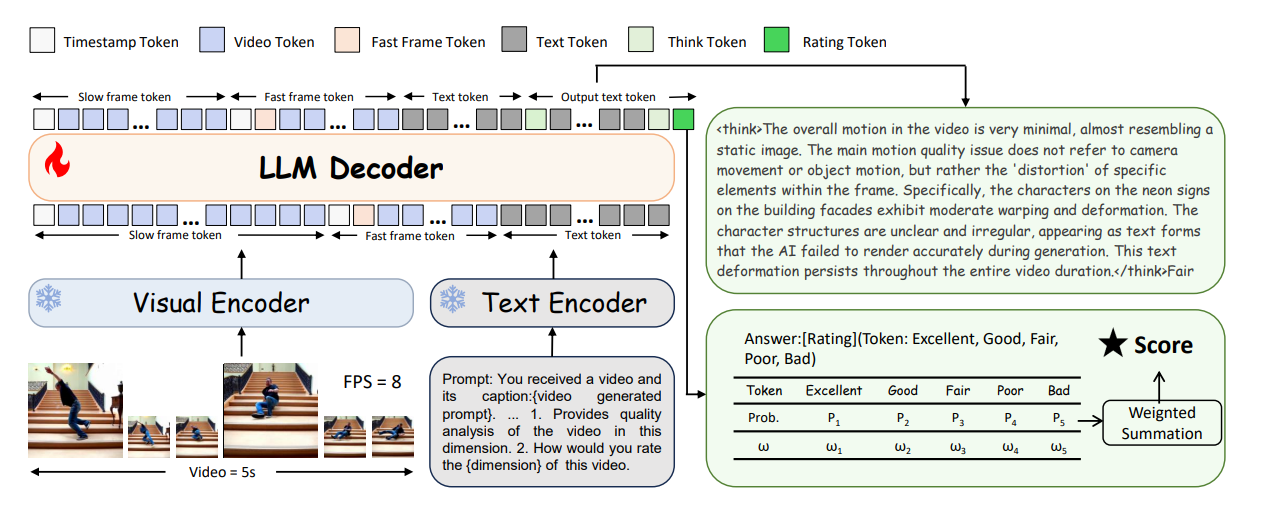
模型结构与视频预处理流程。
三、技术解密:Q-Save模型是如何工作的?
有了数据,接下来就是打造模型。Q-Save基于强大的Qwen-VL(通义千问-视觉语言模型)底座,并在架构和训练策略上进行了精妙创新。
1.像人眼一样看视频:SlowFast 策略
视频文件通常较大,若每一帧都用高分辨率处理,算力消耗将十分巨大;而压缩过度又会丢失细节。
Q-Save借鉴了人类视觉神经系统的SlowFast概念:
•慢速路径:“精读”模式。处理少量帧,但保持高分辨率,专门用于捕捉视觉细节(如清晰度、瑕疵)。
•快速路径:“速览”模式。处理大量帧,但使用低分辨率,专门用于捕捉动作变化(如流畅度、卡顿)。
通过自适应识别“慢帧”和“快帧”,模型在保证精度的同时,显著降低了计算成本。
2.三阶段“魔鬼训练”法
为使模型既能准确打分,又能写出令人信服的评语,团队设计了一套三阶段训练策略:
第一阶段:SFT冷启动(Cold Start)
通过监督微调(SFT),让模型学习基本的答题格式,学会在输出分数前,先用<think>标签包裹分析内容。
第二阶段:RL热身(RL Warmup)—— 关键一招
此阶段是Q-Save性能提升的核心。团队引入了强化学习(Reinforcement Learning),具体采用了分组相对策略优化(GRPO)算法。
模型像不断刷题一样尝试生成评价,系统则根据两个标准给予“奖励”:
•准确性奖励(Accuracy Reward):分数是否准确?
•格式奖励(Format Reward):推理过程是否符合要求?
通过持续的奖惩反馈,模型的逻辑分析能力得到大幅强化。
第三阶段:SFT冷却(SFT Cooling)
强化学习有时会导致模型输出不稳定或过于发散。因此,团队将第二阶段生成的优质数据重新整理,再次进行监督微调,以稳固模型的输出能力,确保其既聪明又可靠。
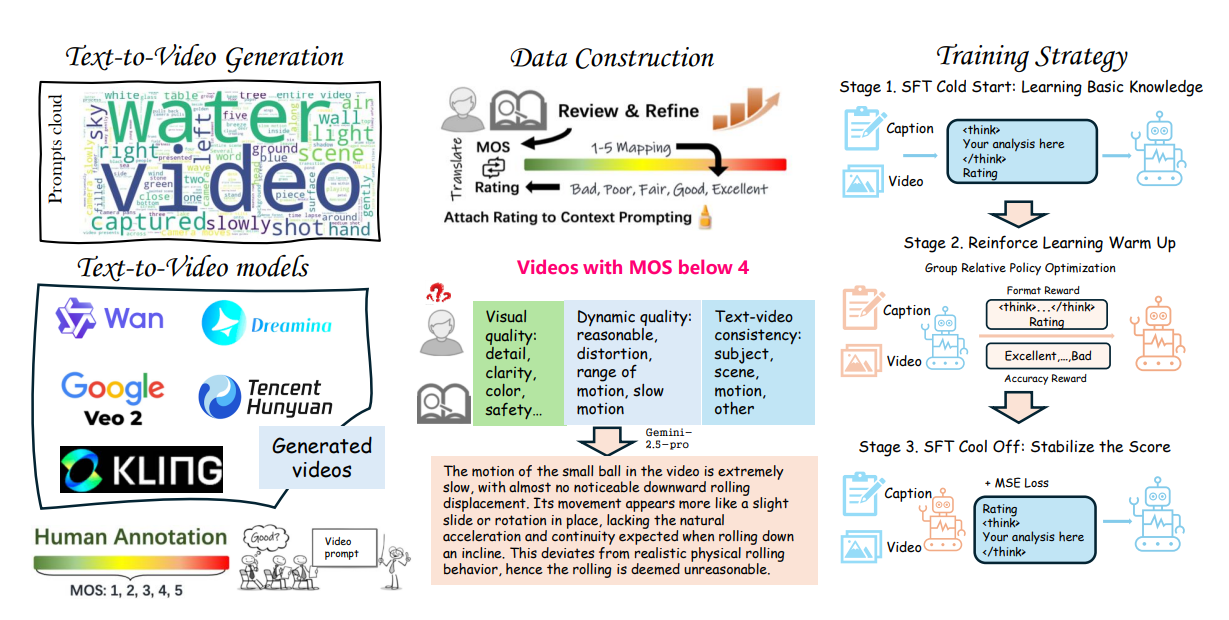
Q-Save 数据集构建流程与训练策略概述。
四、战绩斐然:全面超越现有基准
在实验环节,Q-Save展现出了卓越的性能。
与FastVQA、Q-Align、VideoScore-v2等知名模型的对比中,Q-Save在视觉质量、动态质量、文本对齐三个维度上,无论是实例级,还是模型级的评估指标(SRCC和PLCC相关性系数),均位列第一。
特别是在模型级相关性方面,视觉质量和文本对齐维度甚至达到了SRCC 1.000的完美分数,这意味着Q-Save对模型优劣的排名与人类专家的判断完全一致。
更值得注意的是,在跨数据集验证中,即使面对从未见过的视频(如VideoGen-RewardBench等外部基准),Q-Save依然表现出强大的泛化能力。这证明它并非死记硬背,而是真正学会了如何“鉴赏”视频。
五、结语:Q-Save对未来的意义
《Q-Save:面向生成视频评估的评分与归因》不仅仅是一篇技术论文,它更为AIGV行业设定了一个新的标准。
•对于开发者:未来优化视频模型将不再是盲目调参。Q-Save能明确指出问题所在,例如:“你的模型在‘物体恒常性’上表现不足”,从而指引明确的优化方向。
•对于应用端:在大模型推理时,可将Q-Save作为“奖励模型”(Reward Model),自动筛选出生成质量最佳的视频呈现给用户。
•迈向可信AI:通过提供可解释的评估,我们能更好地理解AI的能力边界,减少幻觉和错误内容的传播。
Q-Save如同一位严谨的质检员,正为即将到来的AI视频爆发时代保驾护航。当AI学会评价AI,并能清晰阐述其理由时,我们距离真正的通用人工智能,或许又近了一步。
