
告别串行等待:借助 RapidFire AI 实现 20 倍速 LLM 微调实验
在大型语言模型的微调与优化中,您的团队是否也曾因受限于时间和算力限制,被迫放弃对多种配置的深入探索难以充分探索多种配置?现在,这一瓶颈已被打破。Hugging Face TRL 现已正式集成 RapidFire AI,它能以近乎零代码改动的方式,助您在单 GPU 上并行运行数十种微调实验,将实验迭代速度提升最高提升至20倍,让您更快地找到最优模型。
借助 RapidFire AI 实现 20 倍速 TRL 微调
Hugging Face TRL 现已正式集成 RapidFire AI,助力加速您的微调及训练后实验流程。TRL 用户如今可发现、安装并运行 RapidFire AI,这是无需大幅修改代码、无需增加 GPU 资源开销,即可对比多种微调 / 训练后配置以定制大语言模型的最快方式。
核心价值:告别漫长的串行实验
在对 LLM 进行微调或训练后优化时,团队往往缺乏足够时间和 / 或预算对比多种配置 —— 尽管这种对比能显著提升评估指标。RapidFire AI 支持您(即便在单 GPU 环境下)并行启动多个 TRL 实验配置,并通过全新的、自适应的数据块调度与执行方案,近乎实时地进行对比。根据 TRL 官方页面引用的内部基准测试,与逐次对比配置的传统方式相比,该方案可将实验吞吐量提升约 16-24 倍,助您更快达成更优指标。
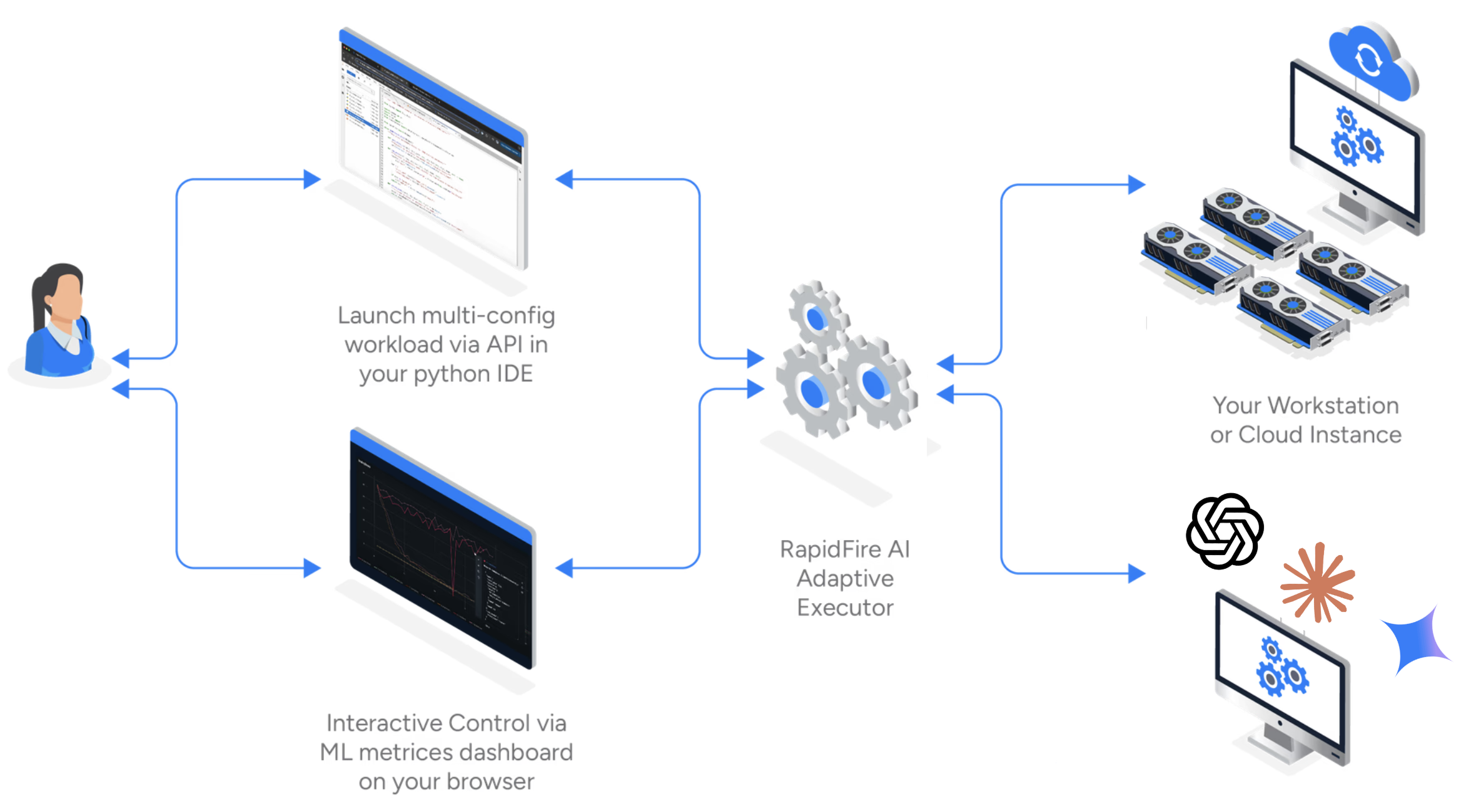
RapidFire AI 在您的集成开发环境、指标仪表盘与多 GPU 执行后端之间建立实时三方通信。
开箱即用的核心功能
- 即插即用型 TRL 封装器:使用
RFSFTConfig、RFDPOConfig和RFGRPOConfig,可近乎零代码替换 TRL 的 SFT/DPO/GRPO 配置。
- 自适应数据块并行训练:RapidFire AI 将数据集分片为指定数量的数据块,并在数据块边界处循环切换配置,既能更早开展公平对比,又能最大化 GPU 利用率。
- 交互式控制操作:通过仪表盘即可对运行中的任务执行停止、恢复、删除以及克隆-修改操作。克隆操作支持热启动,让您能快速基于潜力配置进行迭代,无需为表现不佳的配置浪费资源,可集中算力于优质配置——整个过程无需重启任务、无需手动协调独立 GPU 或集群、无额外资源开销。
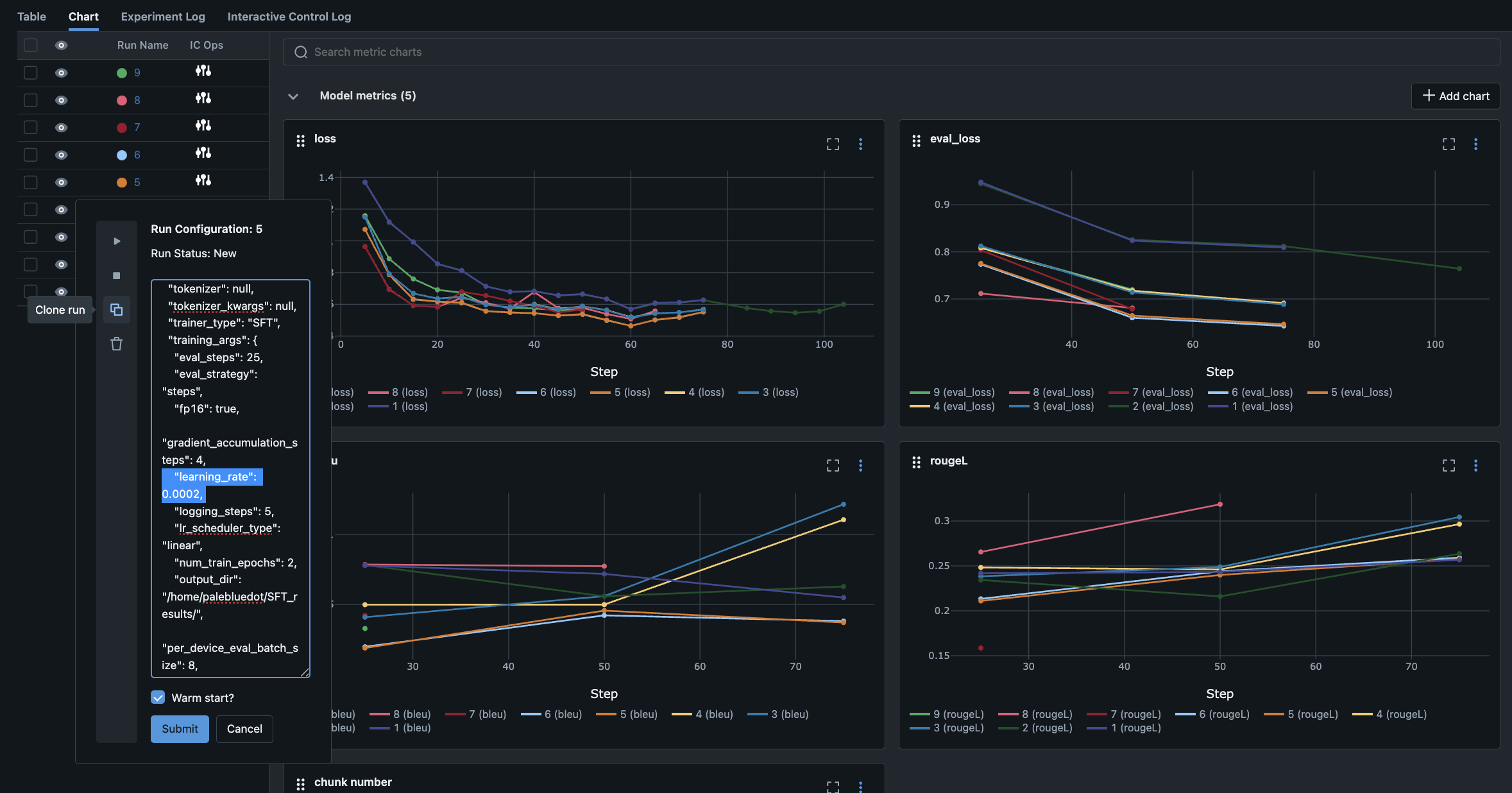
- 多 GPU 编排:RapidFire AI 调度器通过高效的共享内存机制,自动在可用 GPU 上编排配置并协调数据块训练。您只需专注于模型和评估指标,无需关注底层架构搭建。
- 基于 MLflow 的仪表盘:实验启动后,实时指标、日志和交互式控制操作一站式呈现。即将支持 Trackio、W&B 和 TensorBoard 等更多仪表盘工具。
工作原理
RapidFire AI 将数据集随机划分为“数据块”,并在数据块边界处让不同 LLM 配置在 GPU 上循环运行。您能更快获取所有配置的增量评估指标反馈。通过高效的基于共享内存的适配器 / 模型暂存 / 加载机制实现自动保存 Checkpoint,确保训练过程流畅、稳定且一致。利用交互式控制操作可在训练中动态调整:及早停止表现不佳的配置,克隆潜力配置并微调参数。
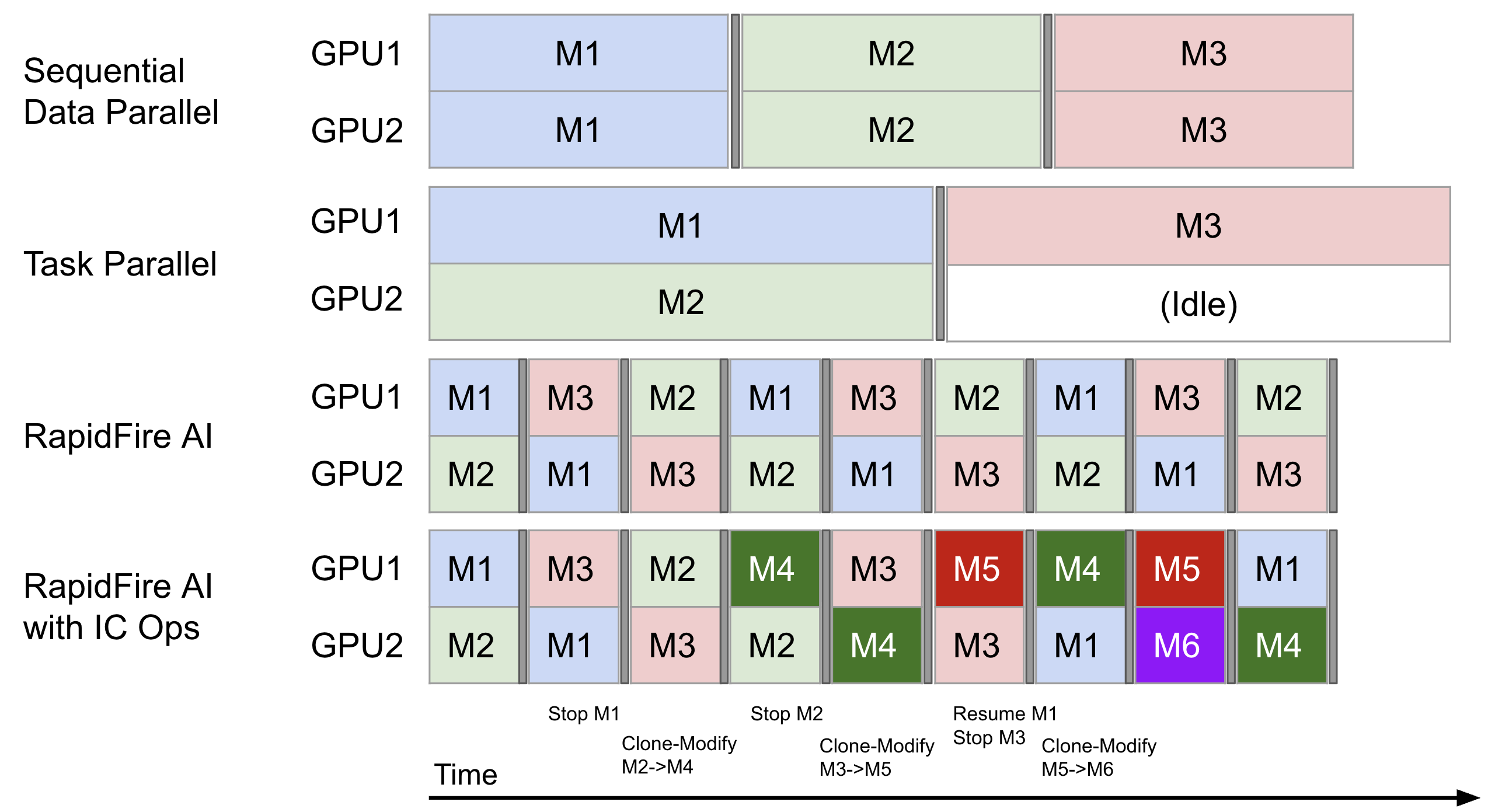
串行模式 vs. 任务并行模式 vs. RapidFire AI:自适应调度器可最大化多配置、多 GPU 场景下的 GPU 利用率。最下方一行展示了交互式控制操作的实际应用——在训练中停止、克隆和修改任务。
快速上手
安装 RapidFire AI,一分钟内即可启动运行:
仪表盘将在 http://localhost:3000 启动,您可在此监控和控制所有实验。
支持的 TRL 训练器
- 基于
RFSFTConfig的 SFT(监督微调) - 基于
RFDPOConfig的 DPO(直接偏好优化) - 基于
RFGRPOConfig的 GRPO(梯度对齐偏好优化)
这些配置均设计为即插即用替代品,您可保留原有的 TRL 使用逻辑,同时获得更高的并行性和对微调 / 训练后应用的控制能力。
极简 TRL SFT 示例
以下示例展示如何在单 GPU 上并行训练多种配置:
python
运行后效果
假设在 2-GPU 设备上运行上述代码:与串行训练(配置 1→等待→配置 2→等待)不同,两种配置将并行训练:
方案 | 做出对比决策所需时间 | GPU 利用率 |
|---|---|---|
串行模式(传统方式) | 约 15 分钟 | 60% |
RapidFire AI(并行模式) | 约 5 分钟 | 95%+ |
在两种配置完成第一个数据块的训练后,您即可基于对比结果做出决策——无需等待两者依次遍历完整数据集,相同资源下决策效率提升 3 倍。打开 http://localhost:3000 即可查看实时指标,并根据观测结果通过交互式控制操作实时停止、克隆或调整任务。
基准测试:真实场景提速效果
以下是团队从串行对比切换至 RapidFire AI 超并行实验后,达成相近最优训练损失(覆盖所有尝试配置)的时间对比:
场景 | 串行模式耗时 | RapidFire AI 耗时 | 提速倍数 |
|---|---|---|---|
4 种配置,1 块 GPU | 120 分钟 | 7.5 分钟 | 16 倍 |
8 种配置,1 块 GPU | 240 分钟 | 12 分钟 | 20 倍 |
4 种配置,2 块 GPU | 60 分钟 | 4 分钟 | 15 倍 |
基准测试基于 NVIDIA A100 40GB GPU,使用 TinyLlama-1.1B 和 Llama-3.2-1B 模型。
来源:https://huggingface.co/blog/rapidfireai
