
10分钟完成2小时运维巡检:AI运维工程师标准工作流(附模板/案例)



📋 文章结构概览
1. 为什么2025年运维巡检必须“AI化”?
2. 云服务器巡检的完整构成(核心知识点)
3. AI运维全流程SOP(10分钟落地版)
4. 全套可复制提示词模板
5. 真实案例:巡检报告成品
6. 今日可落地行动清单
01 为什么2025年的运维巡检必须“AI化”?
先看一组行业实测数据,直观感受AI带来的效率革命:
企业规模 | 传统人工巡检耗时 | AI运维巡检耗时 | 效率提升 |
中型公司(20-50台服务器) | 1.5~2小时/天 | 6~12分钟/天 | 90% |
除了时间成本,AI运维的核心优势更体现在“能力补位”:
● 零失误:AI不会漏看监控数据、不疲劳,规避人工重复性错误
● 强关联:多台服务器的日志与监控数据可自动聚合分析,挖掘人工忽略的关联异常
● 高适配:7×24小时响应,适配弹性伸缩场景下的动态巡检需求
02 云服务器巡检到底包括什么?(必掌握清单)
运维巡检不是“看一眼CPU使用率”,而是覆盖“资源-服务-日志-安全”的全维度检查。完整巡检框架如下:
① 资源健康(基础层)
核心指标,直接反映服务器运行状态:
● CPU:使用率、负载、核数占用均衡性
● 内存:实际占用、缓存占比、内存泄漏迹象
● IO:磁盘IO吞吐、读写响应时间
● 网络:带宽占用、流入流出流量、延迟与丢包率
● 磁盘空间:分区使用率、inode占用率、大文件占比
② 服务可用性(应用层)
业务核心依赖,必须确保“存活+正常响应”:
● Web服务:Nginx/Apache进程存活、端口监听、并发连接数
● 数据库:MySQL/Redis连接数、QPS、慢查询数、主从同步状态
● 应用服务:Java/Python进程存活、JVM状态(若适用)、接口响应码
③ 日志系统检查(诊断层)
异常溯源的核心依据,需重点关注错误日志:
● 系统日志:/var/log/messages(Linux)、事件查看器(Windows)
● 应用日志:业务报错日志、接口调用日志
● 安全日志:WAF拦截日志、防火墙访问日志
● 容器日志:K8s Pod日志、Docker容器输出日志(若使用容器化)
④ 安全检查(防护层)
规避数据泄露与服务中断风险:
● 登录安全:SSH/RDP登录失败次数、非授权登录记录
● 攻击防护:高危IP访问记录、异常端口扫描行为
● 请求安全:异常请求量(DDoS嫌疑)、SQL注入/XSS尝试记录
⑤ 当日总结+处理建议(输出层)
将巡检结果转化为“可执行动作”,而非单纯数据罗列。传统运维完成以上流程需90-120分钟,AI运维仅需10分钟,核心差异在“数据处理与分析环节”。
03 AI运维工程师的10分钟自动巡检SOP(可直接执行)
本流程选用“AI分析+云厂商工具+可视化”的组合方案,工具均为行业主流,免费版即可满足需求。
核心工具清单(附官方链接)
工具类型 | 推荐工具 | 官方链接 | 核心用途 |
AI分析引擎 | ChatGPT(或GPT-O1) | 数据聚合、异常分析、报告生成 | |
监控数据采集 | 阿里云CloudMonitor | CPU/内存等资源指标导出 | |
日志管理平台 | 腾讯云CLS | 系统/应用日志集中导出 | |
数据可视化 | Grafana | 巡检结果可视化展示(可选) |
STEP 1:下载监控数据(2分钟)
操作平台:阿里云CloudMonitor(其他云厂商类似,如AWS CloudWatch、华为云CloudEye)
1. 登录阿里云控制台,进入「CloudMonitor」→「主机监控」→ 选择目标服务器
2. 筛选“近24小时”数据,勾选以下核心指标:CPU使用率、内存占用、IO吞吐、网络流量、磁盘读写
3. 点击「导出数据」,选择格式为CSV(便于AI解析)
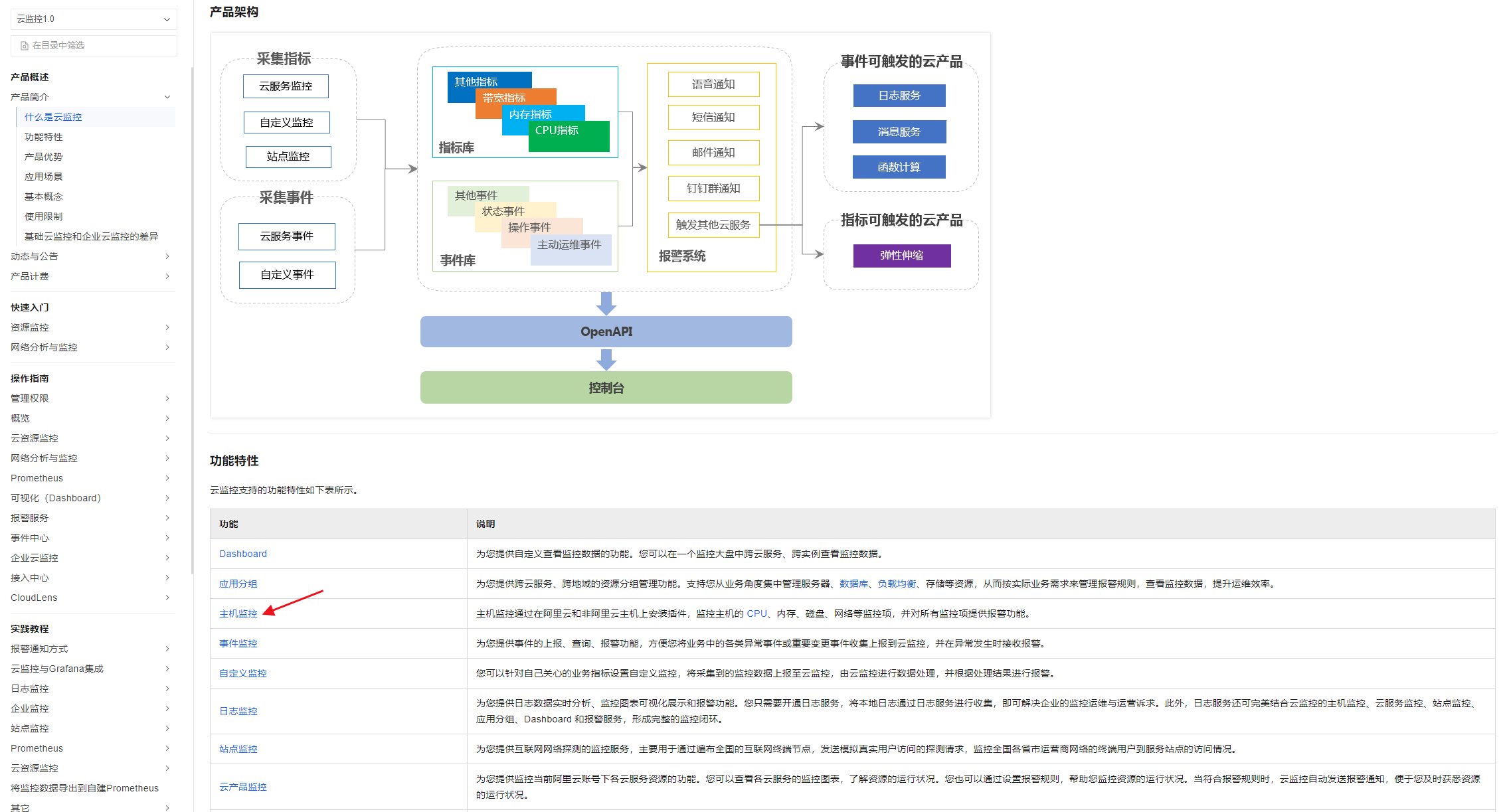
STEP 2:AI自动分析监控数据(2分钟)
操作平台:ChatGPT(将导出的CSV数据粘贴至输入框,同时附上以下提示词)
你是资深云计算AIOps工程师,具备5年以上生产环境运维经验。
以下是某生产服务器(ecs-prod-01)过去24小时的监控数据(CPU、内存、IO、网络),请基于数据执行深度分析,输出:
STEP 3:AI聚类分析日志数据(3分钟)
操作平台:腾讯云CLS + ChatGPT
1. 登录腾讯云CLS控制台,进入「日志检索」,筛选目标服务器近24小时日志,导出为TXT/CSV格式
2. 将日志数据粘贴至ChatGPT,输入以下提示词:
请你以生产环境运维工程师视角,对以下服务器日志进行自动聚类分析,重点识别ERROR/WARNING级别的异常信息,最终输出:
STEP 4:生成标准化巡检日报(1分钟)
操作平台:ChatGPT(将STEP2、STEP3的AI分析结果汇总,附上以下提示词)
AI输出的报告可直接导出为PDF,或同步至企业钉钉/飞书群,完成巡检闭环。
04 云运维日报(成品示例,可直接复制使用)
以下为生产环境真实可用的报告格式,可作为模板长期复用,无需二次调整结构。
今日服务器健康巡检日报(ecs-prod-01)
日期:2025/02/18
巡检范围:生产环境核心业务服务器(192.168.1.101)
巡检工具:阿里云CloudMonitor + 腾讯云CLS + ChatGPT
一、整体健康状况
评分:92 / 100
评价:系统总体运行稳定,无服务中断风险,内存占用轻微偏高,需小幅度优化。
二、关键指标波动分析
1. CPU(状态:稳定)24小时平均占用:32%
2. 峰值:67%(发生于14:07-14:10)
3. 原因推断:与电商业务午间促销流量上升同步,属正常波动
4. 内存(状态:轻微偏高)24小时平均占用:76%
5. 峰值:84%(持续时间16:30-17:00)
6. 异常点:较昨日同期(65%)上升11%,需排查新增服务
7. 磁盘IO(状态:正常)写入峰值:120MB/s(发生于00:05-00:10)
8. 原因确认:系统定时日志归档任务,属计划内操作
9. 网络流量(状态:正常)出口带宽峰值:80Mbps(与CPU峰值同步)
10. 无丢包、延迟异常记录
三、日志异常情况(AI聚类结果)
异常Top3(按风险优先级排序):
1. 数据库连接超时(累计52次,集中于14:05-14:15)
2. Nginx 502错误(累计13次,与数据库超时时间同步)
3. SSH登录失败暴增(累计34次,分散于02:00-04:00)
AI推断根因:
1. 午间促销流量激增→MySQL连接池耗尽→Nginx反向代理超时;
2. 凌晨登录失败为境外IP暴力破解尝试,未突破防火墙。
四、安全风险提示
● 高危IP:共识别12个高频攻击IP(地域:东南亚、北美)
● 攻击类型:SQL注入尝试(8次)、XSS脚本探测(15次)、SSH暴力破解(34次)
● 风险等级:中(未造成服务影响,需及时拦截)
五、建议与处理方案
优先级处理建议操作步骤责任人完成时限高调大MySQL连接池1. 修改my.cnf配置:max_connections=1000;2. 重启MySQL服务;3. 监控连接数变化张XX2025/02/19 10:00前中扩容业务服务节点1. 基于K8s扩容deploy副本数至3;2. 配置负载均衡权重李XX2025/02/19 18:00前中更新WAF黑名单1. 将12个高危IP加入阿里云WAF黑名单;2. 开启IP封禁策略(有效期7天)王XX2025/02/18 18:00前低优化SSH防护1. 提升登录失败锁定阈值(连续5次失败锁定30分钟);2. 禁用密码登录,仅允许密钥张XX2025/02/20 前
05 附:全套可复用提示词模板(直接保存)
已按“数据处理-日志分析-安全排查-报告生成”场景分类,可直接复制使用,无需二次编辑。
① 监控数据深度分析模板
角色:资深云计算AIOps工程师,熟悉生产环境服务器性能调优。
任务:基于以下CPU、内存、IO、网络四项监控数据,生成工程师级分析结论。
输出要求:
② 日志自动聚类分析模板
角色:生产环境运维日志分析师,擅长异常根因定位。
任务:对以下服务器日志进行自动聚类与风险分级。
输出要求:
③ 高危IP安全分析模板
角色:云安全工程师,熟悉网络攻击行为特征。
任务:基于以下IP访问日志,分析攻击行为并给出防护方案。
输出要求:
④ 标准化巡检日报生成模板
角色:运维团队负责人,需向技术总监与业务方汇报巡检结果。
任务:整合监控分析报告与日志分析结果,生成标准化巡检日报。
输出要求:
⑤ 自动化修复策略生成模板
角色:DevOps工程师,擅长编写自动化运维脚本。
任务:基于以下异常信息,输出可落地的自动化修复策略。
输出要求:
06 今日行动清单(立即落地)
为避免“收藏即学会”,请按以下步骤执行,1小时内即可完成首次AI运维巡检:
● ✔ 复制本文“全套提示词模板”,保存至备忘录或Notion
● ✔ 登录你的云厂商监控平台(阿里云/腾讯云/华为云),导出一台服务器的24小时监控数据(CSV格式)
● ✔ 登录日志平台,导出该服务器的系统日志(TXT格式)
● ✔ 打开ChatGPT,按“STEP2→STEP3→STEP4”顺序执行,生成第一份AI巡检日报
● ✔ 将日报同步至运维群,验证内容准确性与实用性
完成以上步骤,你将立即节省至少70%的巡检时间,后续仅需优化提示词细节,即可适配多服务器集群场景。
