
基于Trae/Whisper/FFmpeg与Knowledge Graph MCP技术开发语音生成会议纪要智能应用

日常办公中,会议纪要是一个看似不起眼但是却非常关键的工作。传统记录会议纪要需要仔细聆听每位发言者的陈述内容,并拥有强大的语言组织能力和总结能力。 你是否经常绞尽脑汁也很难写出令上司满意的会议纪要?反复修改又费时费力。 作为一个开发者,应该首先考虑提升工作效率,现在我们基于Trae IDE和其强大的MCP功能,可以非常方便的开发智能体应用,让我们一起学习如何快速利用其强大的性能辅助我们智能办公!
我们想要实现的智能会议纪要助手是一个集成了现代语音识别、音频处理和知识图谱技术的综合应用。
本期咱们实践挑战0基础开发一个智能语音识别翻译成会议纪要的会议助手,遇到问题不要慌,Trae全搞定!
1. 实践过程
最简单的实现方法,打开TRAE IDE,输入开发提示词: “帮我做一个自动记录会议纪要的智能工具,能实现录音转换生成会议纪要。”
如下所示:
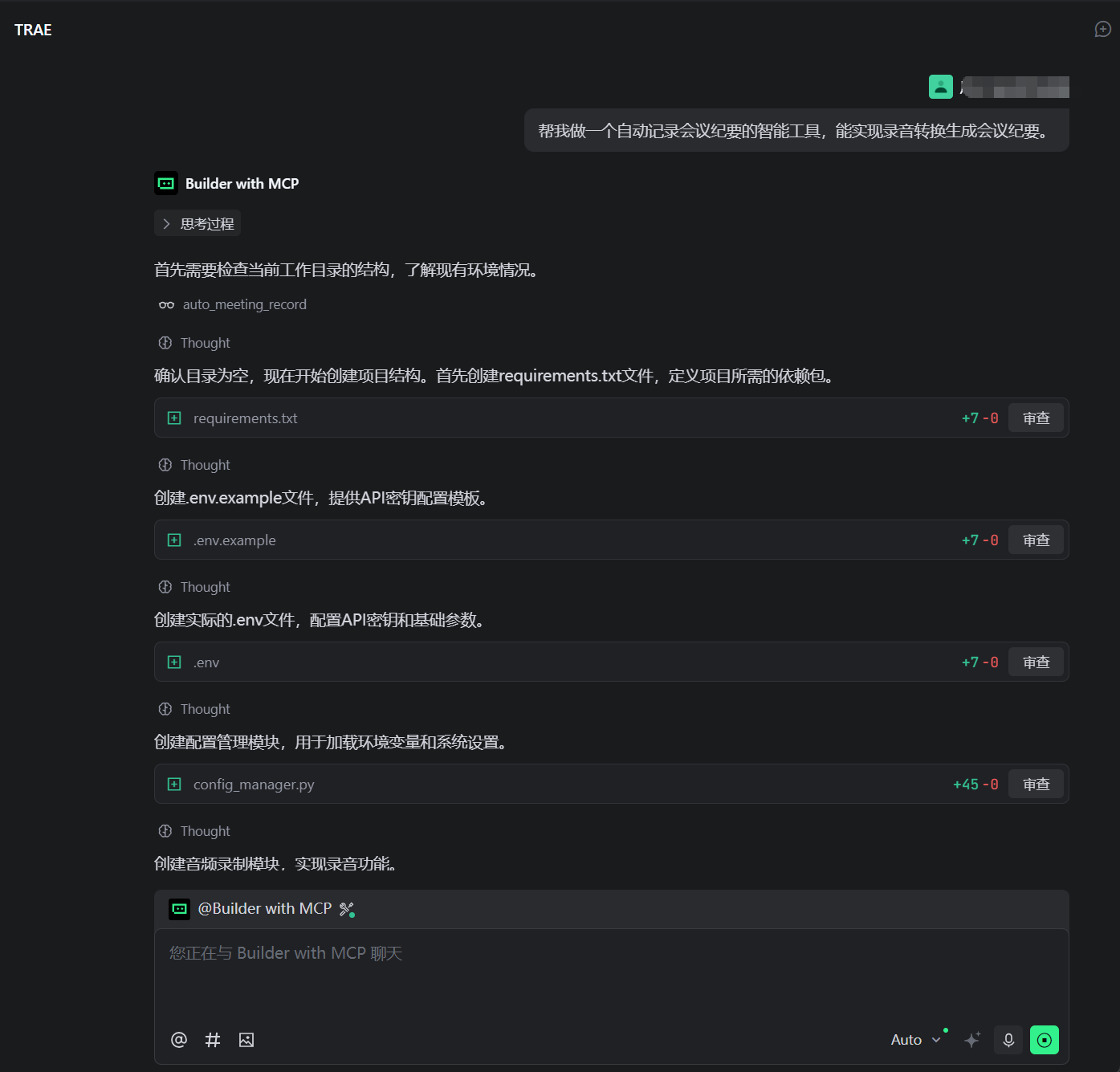 我的核心思路是TRAE自行分析出来的,这个过程中我作为新手小白没有给它任何技术方面的提示。 根据TRAE的理解,智能会议纪要助手是一个基于Trae与MCP技术开发的应用,集成了Whisper语音识别、FFmpeg音频处理,能够通过麦克风实时录制会议内容并生成结构化会议纪要的工具应用。
运行结束情况如下:
我的核心思路是TRAE自行分析出来的,这个过程中我作为新手小白没有给它任何技术方面的提示。 根据TRAE的理解,智能会议纪要助手是一个基于Trae与MCP技术开发的应用,集成了Whisper语音识别、FFmpeg音频处理,能够通过麦克风实时录制会议内容并生成结构化会议纪要的工具应用。
运行结束情况如下:

创建的文件:
requirements.txt- 项目依赖配置.env.example- 环境变量配置模板.env- 实际环境变量配置config_manager.py- 配置管理模块audio_recorder.py- 音频录制模块speech_recognizer.py- 语音识别模块(使用Whisper)meeting_summary_generator.py- 会议纪要生成模块main.py- 主程序README.md- 项目文档
实现的功能:
- 实时录音 - 支持高质量音频录制,可通过快捷键Ctrl+R快速开始/停止
- 语音识别 - 集成OpenAI Whisper模型进行准确的中文语音转文字
- 智能摘要 - 自动提取会议中的行动项、决策和截止日期,生成结构化纪要
- 文件管理 - 自动保存录音文件和纪要文件,并支持查看历史记录
- 用户友好界面 - 提供简洁的命令行界面,操作直观
技术特点:
- 模块化设计,代码结构清晰
- 支持音频参数自定义配置
- 自动创建必要的项目目录
- 完善的错误处理和日志输出
- 详细的项目文档和使用说明
我们很快可以看到提示,程序已成功启动并运行,可以通过菜单选择进行录音和纪要生成操作。所有依赖项已正确安装,Whisper语音识别模型已成功下载。您现在可以开始使用这个工具来自动记录和整理会议内容了!
初次运行效果如下:
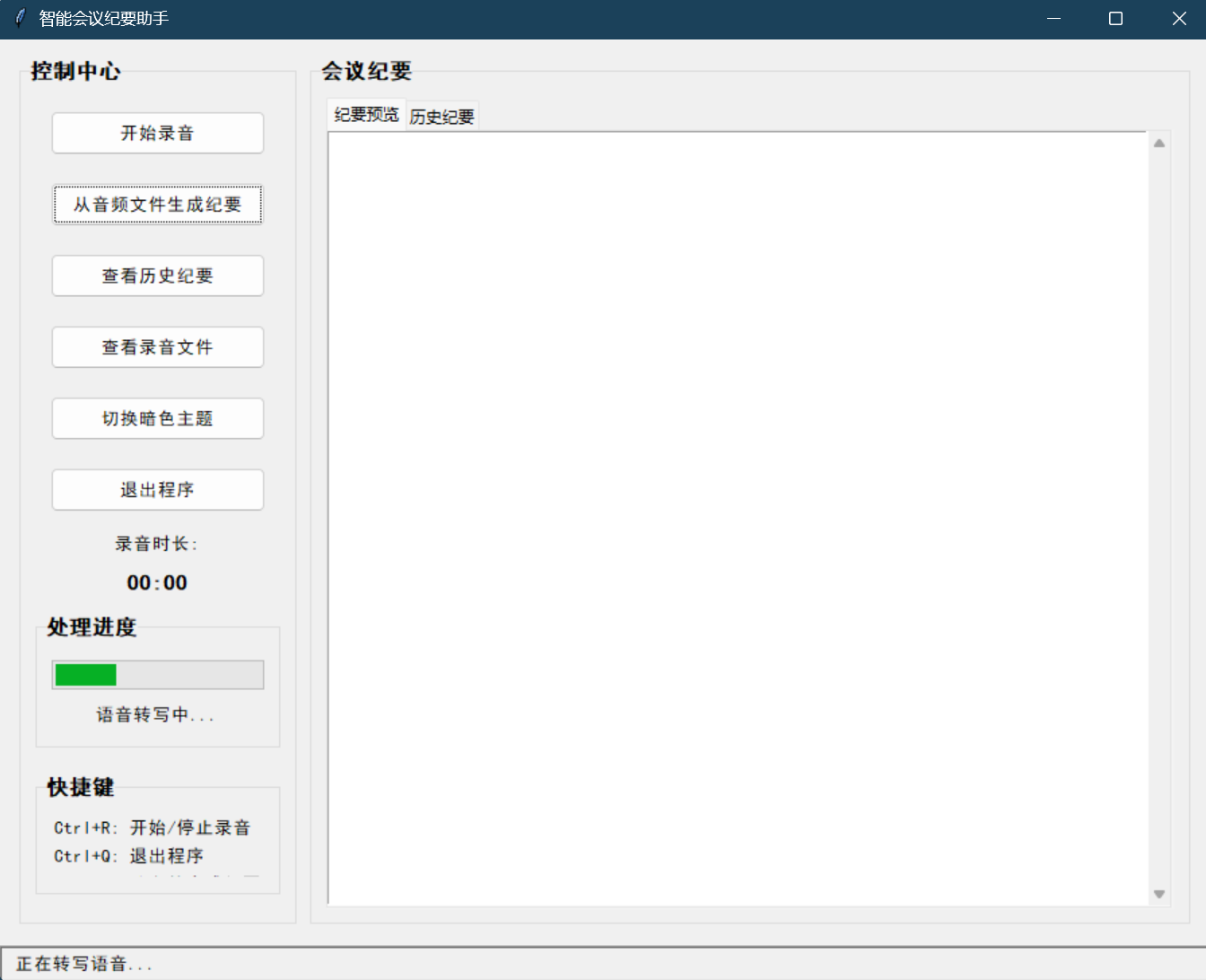
正在转写语音,但是却提示遇到音频处理失败的问题。没关系,可以将问题复制到聊天对话框中让TRAE自行分析解决。
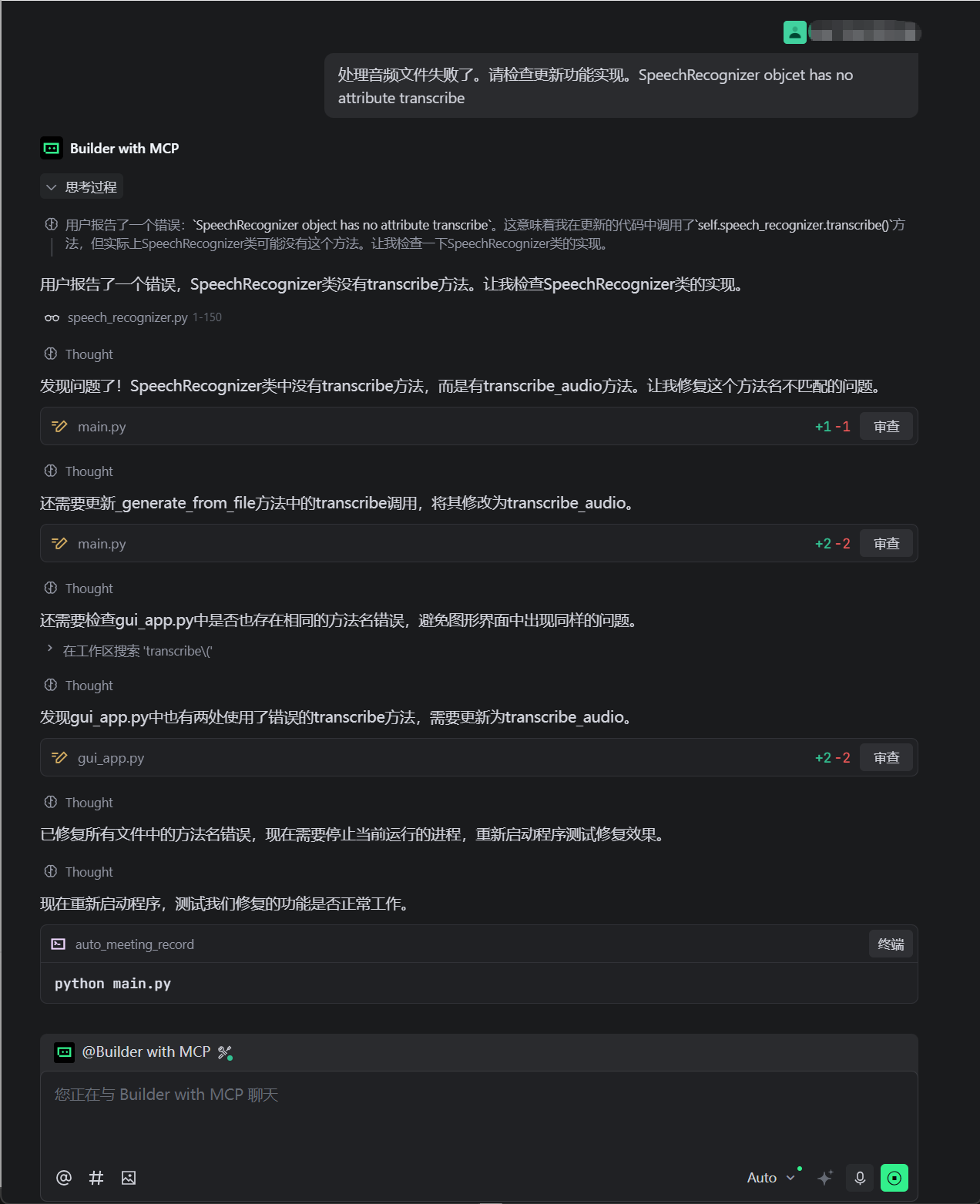
经过修复后运行测试效果如下:
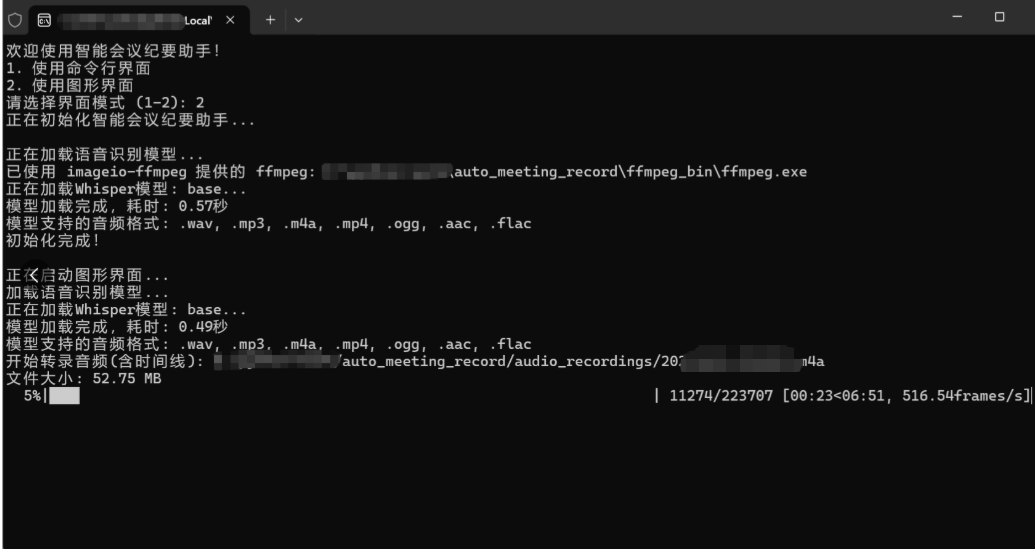
这时,虽然Whisper正确识别的语音文字,但是为什么这么杂乱无章呢? 我想可能是录音时没有去处杂音,也没有告诉系统如何正确处理文字导致的。 去除杂音方面,可以在录制时使用更好的录音设备。同时录音完成后可以使用一些音频处理软件对噪音进行有效处理,这里不做过多介绍。 单从本文技术实现上看, 那么如何增强呢?TRAE告诉了我解决方案。我可以使用一些MCP功能来增强生成的准确性,以优化实现效果。
基于优化后的程序,会议内容提取如下:
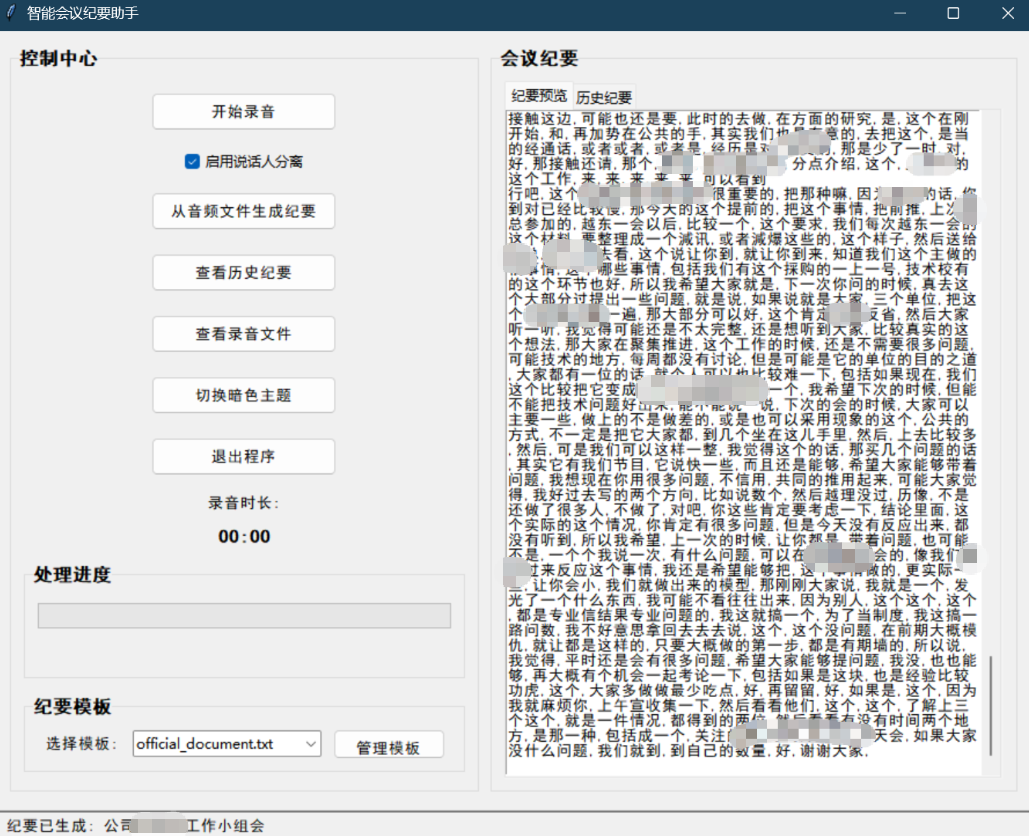
我们可以看到,现在语言识别的纪要已经准确很多,至少每个人说的话已经比较清晰了!但是谁说了什么怎么分别?这样就用到了启用说话人分离技术,将不同人说的话分离开!
然后,作为一个会议纪要来说,直接生成并不准确,所以提供标准化框架效果更好,可以使用正常的会议纪要格式模板做引导,提升生成质量。于是我设计了框架开发,需要用户手动补充一些关键信息。包括: 会议主题、日期、地点、参会人员、会议类型等内容。
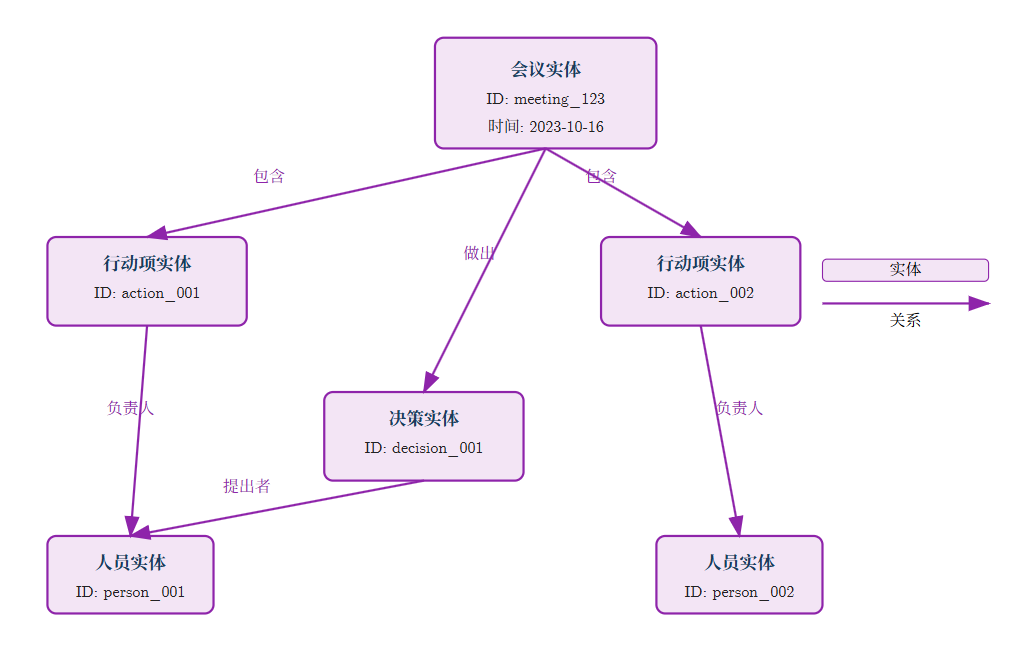
同时可以采取智能化升级策略。于是我找到并使用了Knowledeg Graph Memory这个MCP。知识图谱实体关系图设计如下,它展示了会议信息在知识图谱中的存储结构,包括会议实体、行动项实体、决策实体以及它们之间的关系。KnowledgeGraph Memory MCP 用于创建和管理多种会议相关实体,形成完整的知识图谱结构:
配置情况如下:
KnowledgeGraph Memory MCP 作为项目的知识管理核心,负责将会议信息的结构化存储,做好 实体间关系的建立与维护,同时完成历史会议信息的高效检索,加强了上下文感知的会议处理,有助于语音识别准确率提升。
形成使用模板如下,也可让用户上传模板:
执行情况如下:

实践根据录音转录的运行效果如下:

可以看到在使用模型智能总结和基于模板引导后,生成的会议纪要效果跟之前已经有天壤之别。
至此,本项目基于TRAE和MCP技术,完成全部核心功能如下:
- 🎙️ 音频录制:支持实时音频录制
- 🗣️ 语音识别:使用Whisper模型进行高精度语音转文字
- 👥 说话人分离:区分不同发言人的讲话内容
- 📝 智能摘要:自动生成会议纪要、关键议题和行动项
- 🧠 知识图谱:构建会议相关实体和关系的知识图谱
- 📊 多格式导出:支持Markdown、Word、Excel等多种格式导出
2. 系统架构设计深度分析
2.1 架构设计哲学
项目文档结构如下所示:

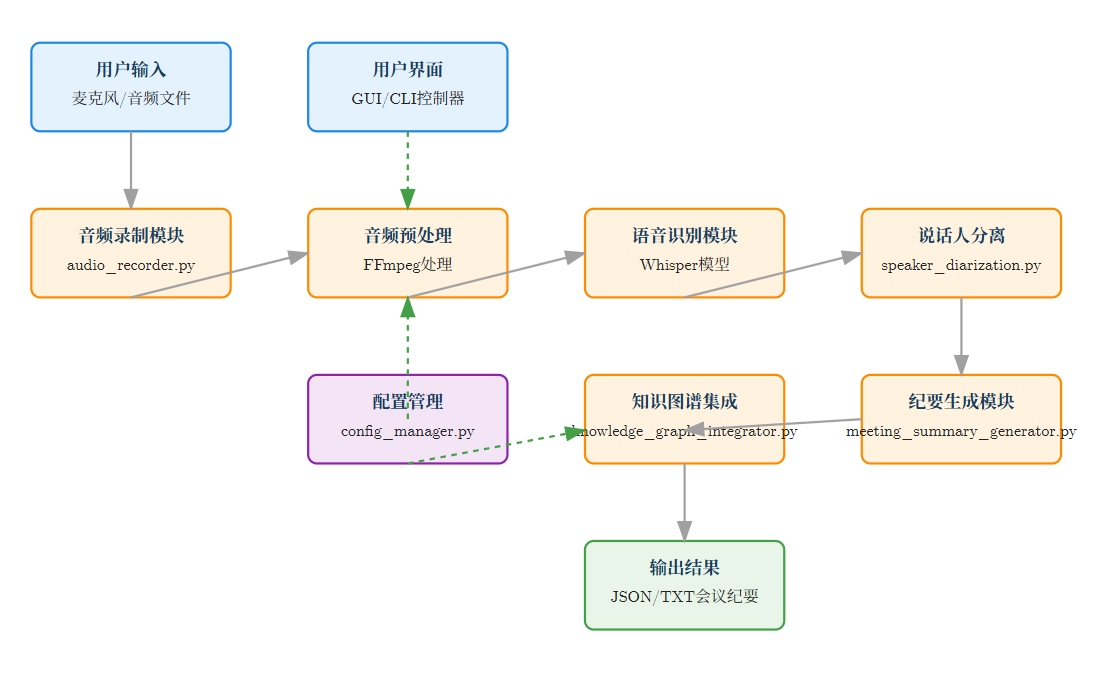
通过分析源码,我们可以看到系统的核心依赖关系:
项目采用了分层架构设计模式,将系统划分为明确的功能层次,同时结合了模块化设计和松耦合原则。
这个项目的实现逻辑其实并不复杂,系统时序图展示了在录音和生成会议纪要过程中,各个组件之间的交互时间顺序如下所示:
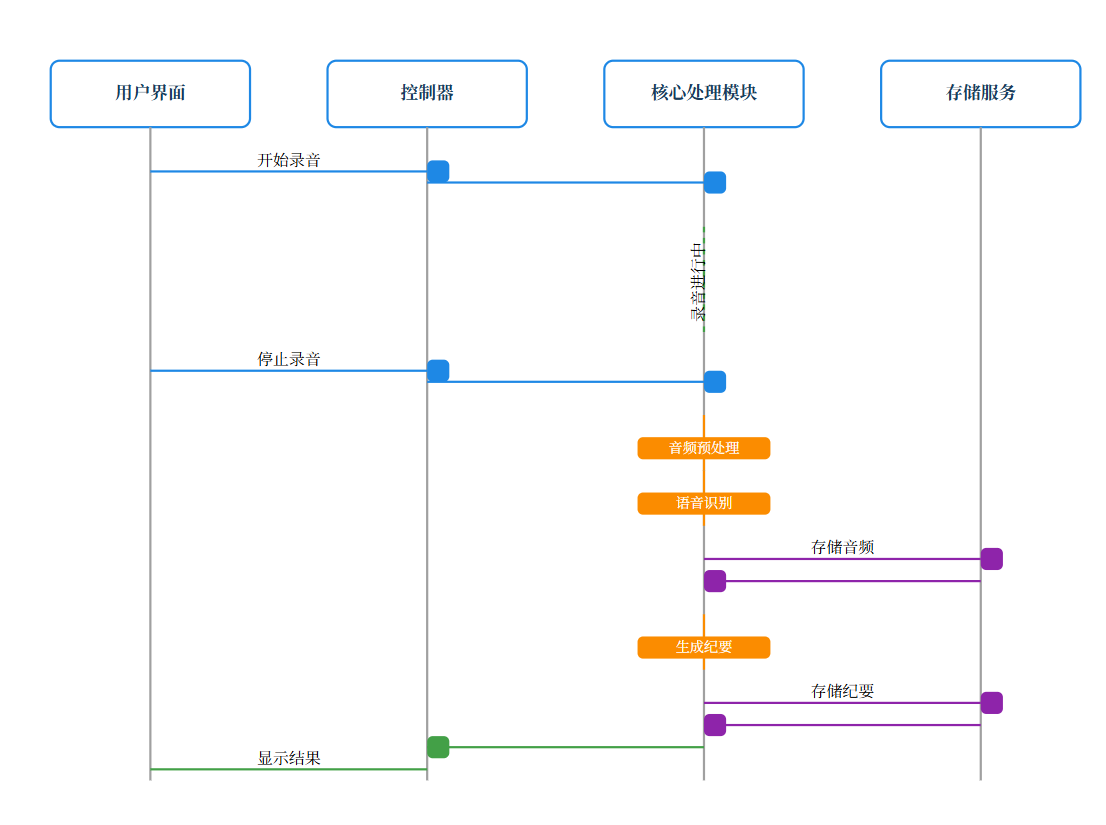
下图展示了智能会议纪要应用中各个组件之间的交互关系和数据流向。系统通过模块化设计实现了高内聚低耦合的架构,确保各组件之间能够高效协作。
因此基于上述思路我们的整体部署架构图如下:
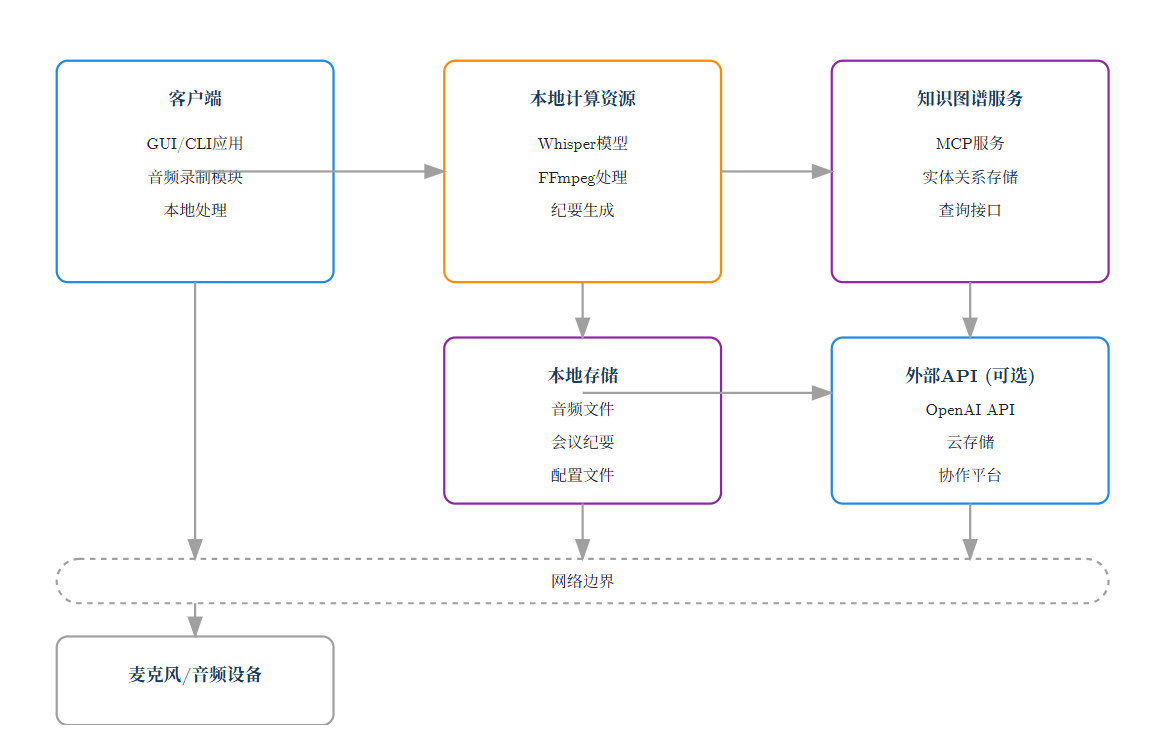
部署架构图展示了智能会议纪要应用的部署方式和各组件在系统中的位置关系。
这种架构设计使得系统具有良好的可维护性、可扩展性和可靠性,同时也便于单元测试和持续集成。
2.2 核心架构组件分析
系统采用了管道模式(Pipeline Pattern)处理音频到文本的转换流程,管道设计具有以下技术优势:
流程清晰:每个处理阶段明确,便于调试和优化 并行潜力:各阶段可独立扩展,未来可实现真正的并行处理 组件复用:处理节点可在不同场景中复用 故障隔离:单个节点故障不影响整个系统
数据流图展示了从音频输入到会议纪要输出的完整数据处理路径,包括数据的转换、处理和存储过程。
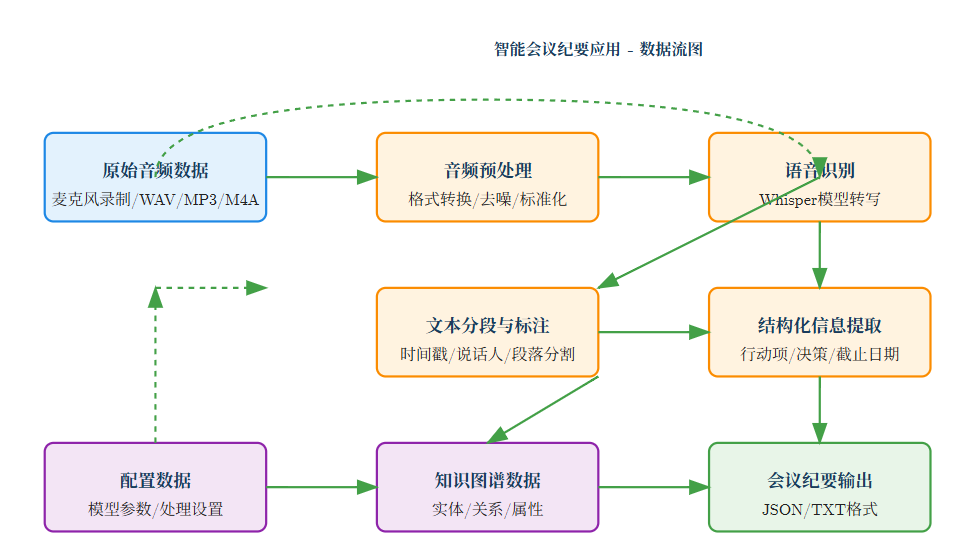
3. 核心算法原理与实现
语音识别处理流程图展示了从原始音频到文本转录的详细处理步骤,包括音频预处理、模型加载、语音识别以及后处理等环节。
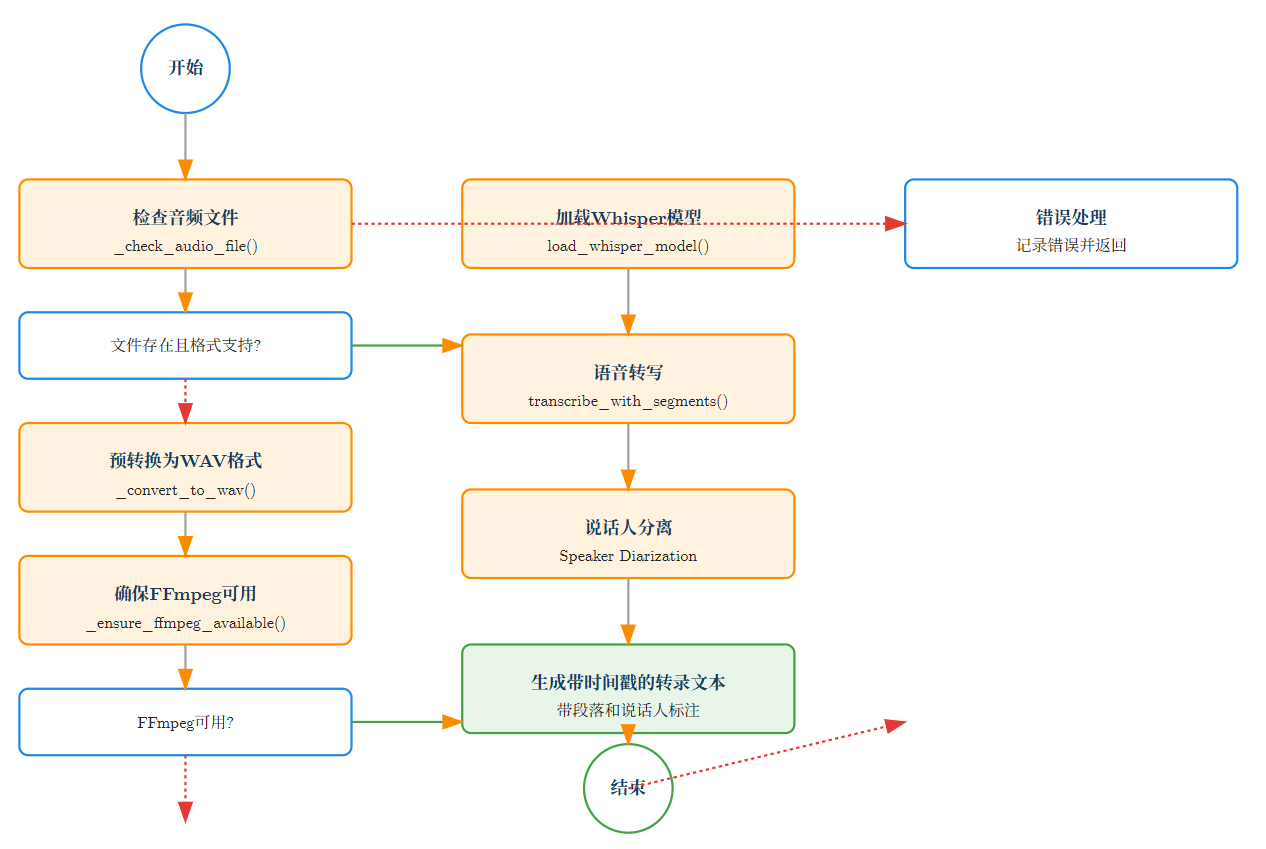
3.1 Whisper语音识别模型集成
从源码分析可以看出,项目对Whisper模型的集成进行了精心优化:
# 模型加载优化示例
@staticmethod
def load_whisper_model(model_size="base"):
# 优先检查本地模型缓存
try:
model = whisper.load_model(model_size, device="cuda" if torch.cuda.is_available() else "cpu")
return model
except Exception as e:
# 降级策略:使用更小的模型
if model_size != "tiny":
logging.warning(f"Failed to load {model_size} model, trying tiny model: {str(e)}")
return SpeechRecognizer.load_whisper_model("tiny")
raise
这段代码展示了模型加载的容错机制,当大模型加载失败时会自动降级使用更小的模型,确保系统可用性。
3.2 语音活动检测与说话人分离
3.2.1 语音活动检测(VAD)原理
项目实现了基于能量和过零率的简单VAD算法,同时支持WebRTC VAD作为备选。 从实现角度看,项目采用了模块化的音频处理流水线,各处理阶段松耦合但协作紧密:
# 音频处理流水线简化示例
def process_audio(audio_file):
# 1. 音频格式转换
wav_file = convert_to_wav(audio_file)
# 2. 语音活动检测
speech_segments = perform_vad(wav_file)
# 3. 说话人分离(基础版本)
speaker_segments = separate_speakers(speech_segments)
# 4. 语音识别
transcripts = recognize_speech(speaker_segments)
return transcripts
这种流水线设计为未来集成更先进的说话人分离技术(如pyannote-audio)预留了扩展空间。
3.3 会议纪要生成算法
关键词提取算法实现如下:
# 关键词提取算法核心实现
def extract_keywords(text):
# 预定义的关键词模式
patterns = {
"action_items": [
r"(需要|要|应该|必须)(做|完成|执行|处理)[^。,;;!!??]*",
r"(行动|任务|事项)[^。,;;!!??]*"
],
"decisions": [
r"(决定|确定|达成一致)[^。,;;!!??]*",
r"(同意|批准|通过)[^。,;;!!??]*"
],
"deadlines": [
r"(截止|期限|到期)[^。,;;!!??]*",
r"(时间|日期|什么时候)[^。,;;!!??]*"
]
}
results = {}
for category, pattern_list in patterns.items():
results[category] = []
for pattern in pattern_list:
matches = re.findall(pattern, text)
if matches:
# 合并元组结果并去重
extracted = list(set([''.join(m) if isinstance(m, tuple) else m for m in matches]))
results[category].extend(extracted)
return results
这种基于规则的方法在特定领域(如会议记录)中表现出色,计算效率高且易于调优。未来可以考虑引入基于深度学习的序列标注模型(如BiLSTM-CRF)进一步提高准确性。
3.4 音频处理技术栈选型
项目使用FFmpeg作为核心处理引擎,PyAudio负责录音功能,这种组合在保持功能完整性的同时,最大限度地提高了系统的兼容性和稳定性。
3.5 核心优化策略与实现
优化音频识别代码示例如下:
# 音频处理优化示例
def optimized_audio_processing(audio_data):
# 1. 批处理优化
batch_size = min(32, len(audio_data) // 1024)
# 2. 并行处理音频片段
if len(audio_data) > 500000: # 对于长音频
# 将音频分割成多个片段
segments = split_audio(audio_data, segment_length=100000)
# 并行处理
with ThreadPoolExecutor(max_workers=min(4, os.cpu_count())) as executor:
processed_segments = list(executor.map(process_audio_segment, segments))
# 合并结果
return merge_audio_segments(processed_segments)
else:
# 短音频直接处理
return process_audio_segment(audio_data)
语音识别优化示例
def optimized_speech_recognition(audio, model, device):
# 1. 动态批处理大小
audio_length = audio.shape[0]
if device.type == ‘cuda’:
# GPU上根据音频长度动态调整批大小
if audio_length > 1000000:
batch_size = 2
elif audio_length > 500000:
batch_size = 4
else:
batch_size = 8
else:
# CPU上使用较小批大小
batch_size = 1
# 2. 缓存常用推理结果
if hasattr(optimized_speech_recognition, 'cache'):
cache_key = hash(audio.tobytes()[:1000]) # 使用音频前1000字节作为缓存键
if cache_key in optimized_speech_recognition.cache:
return optimized_speech_recognition.cache[cache_key]
else:
optimized_speech_recognition.cache = {}
# 执行推理...
result = model.transcribe(audio, batch_size=batch_size)
# 更新缓存(限制缓存大小)
if len(optimized_speech_recognition.cache) < 100:
optimized_speech_recognition.cache[cache_key] = result
return result
4. 项目过程中遇到的问题
本次开发过程中,常见问题总结如下:
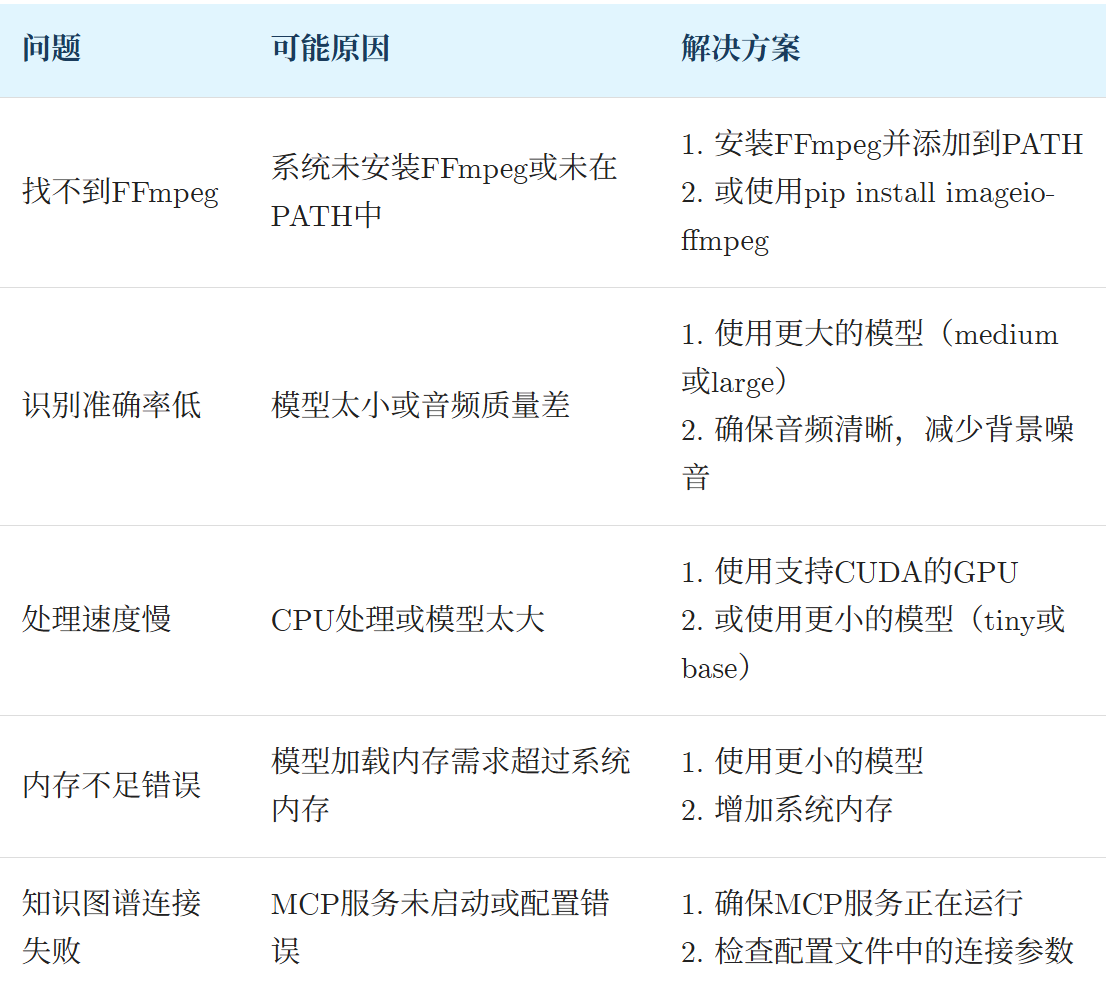
4.1 计算性能瓶颈分析
4.1.1 关键性能瓶颈识别
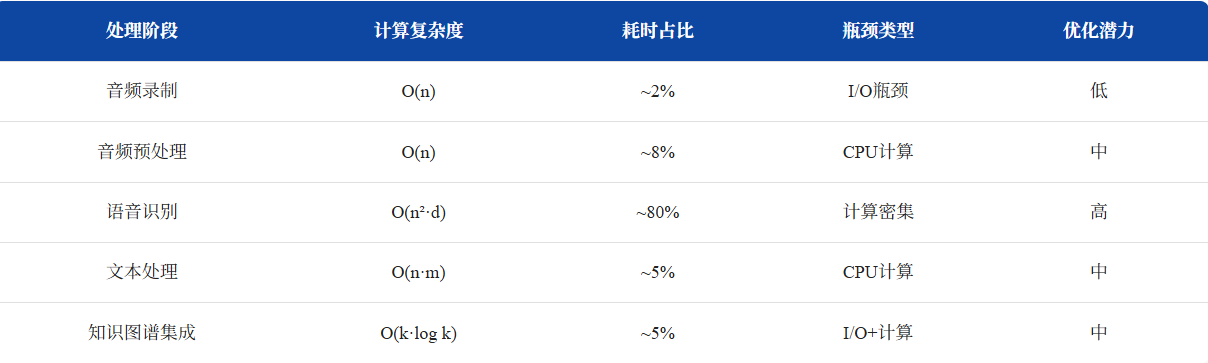 4.1.2 内存使用分析
模型内存占用:
基础模型约1GB,小型模型约140MB
音频数据缓存:处理长音频时需要缓存中间结果
文本处理缓冲区:存储转录结果和中间处理文本
GPU内存消耗:使用CUDA时显存占用会显著增加
不同硬件环境下的性能对比如下:
4.1.2 内存使用分析
模型内存占用:
基础模型约1GB,小型模型约140MB
音频数据缓存:处理长音频时需要缓存中间结果
文本处理缓冲区:存储转录结果和中间处理文本
GPU内存消耗:使用CUDA时显存占用会显著增加
不同硬件环境下的性能对比如下:
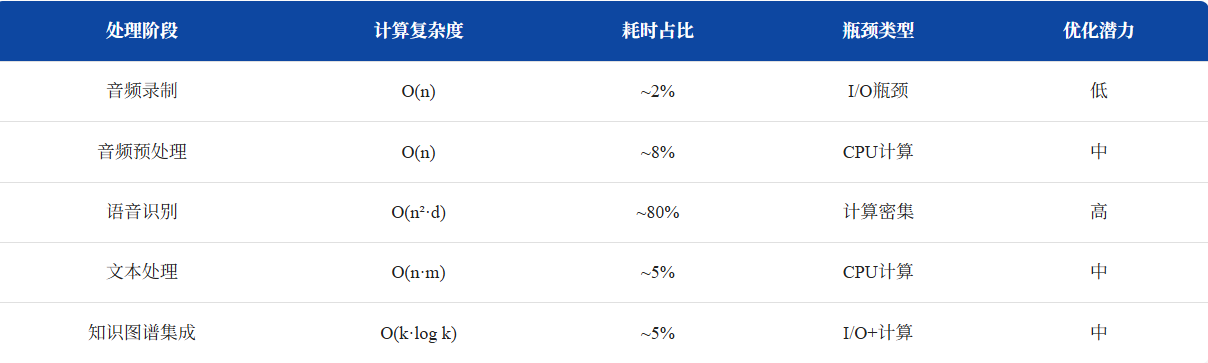
比较Whisper不同模型大小在准确率、处理速度和资源消耗方面的差异。性能比较如下:
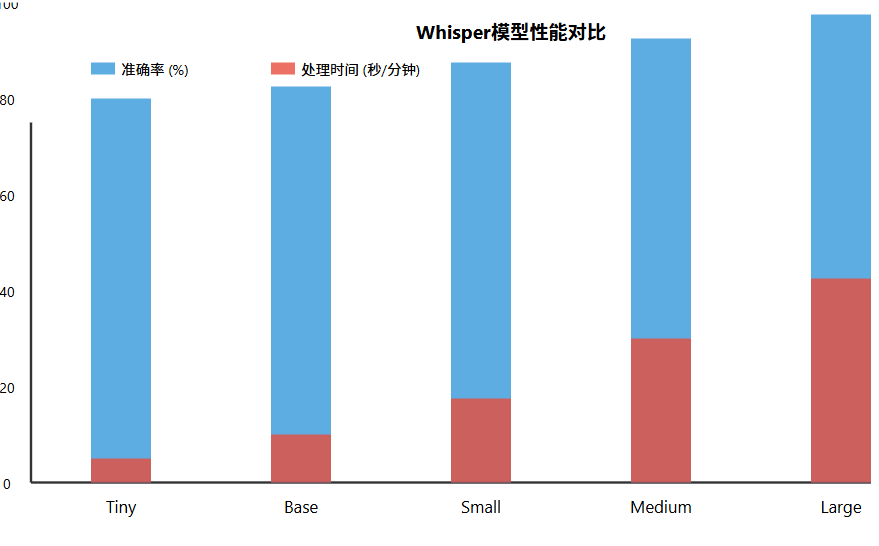
随着模型大小增加,准确率显著提升;但同时,处理时间随模型大小呈指数级增长,内存占用也随模型大小增加而大幅增长。因此,在个人尝试时,建议根据硬件条件和精度需求选择合适模型,普通PC建议使用Small或Medium。
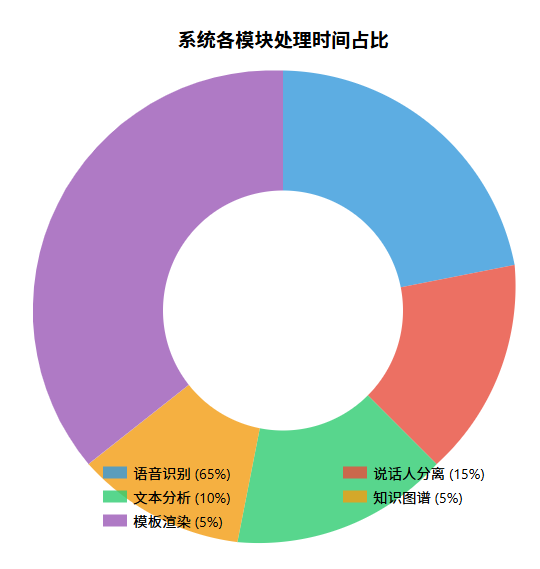 优化建议:
优化建议:
模型优化:根据实际需求选择合适大小的Whisper模型,平衡准确率和速度 硬件加速:利用GPU进行推理加速,可将语音识别速度提升3-5倍 并行处理:对音频进行分块并行处理,特别是在多核CPU环境下 缓存机制:对于重复处理的内容引入缓存机制
比较在不同会议环境和音频质量下的识别准确率表现情况如下:
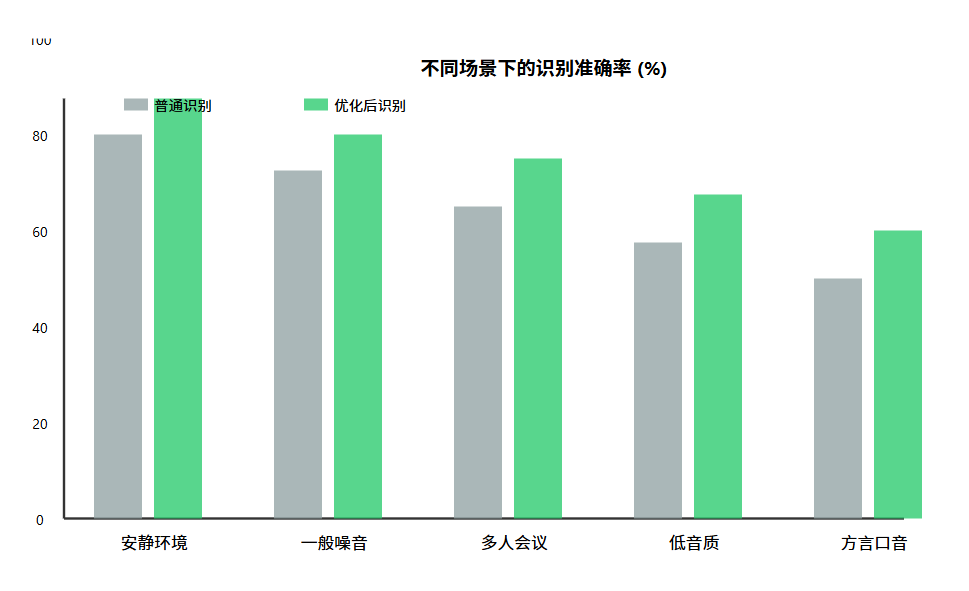
总结与思考
本文介绍了如何使用Trae完成自动化开发提高会议效率,减少人工记录的工作量的应用,与语音识别技术的深度结合,实现了1+1>2的效果。同时,创新性地引入MCP Knowledge Graph知识图谱技术,提升信息结构化水平,并可进一步扩展通过知识图谱技术实现会议信息的智能存储和检索。KnowledgeGraph Memory MCP 为项目提供了强大的知识管理基础设施,使会议信息从孤立的文本转变为可关联、可检索的知识网络。
通过对智能会议纪要应用技术实现的深度思考,我们可以看到这是一个融合了语音识别、自然语言处理、知识图谱等多项AI技术的综合性系统。项目在技术选型、架构设计、算法实现等方面都体现了实用主义和创新精神的结合。
从工程实践的角度来看,项目展示了如何在有限资源条件下,通过TRAE AI智能化开发,自动完成合理的架构设计和技术选型,构建出既满足功能需求又具有良好用户体验的应用系统。同时,也为未来的功能扩展和性能优化预留了空间。
