
YOLOv8【特征融合Neck篇·第12节】一文搞懂,Feature Pyramid Transformer特征金字塔变换器!


💖 一、温故知新:上期内容回顾 (Multi-Scale Feature Aggregation)
哈喽,亲爱的小伙伴们!欢迎回到我们的专栏!👋 在上一期《YOLOv8【特征融合Neck篇·第11节】Multi-Scale Feature Aggregation多尺度特征聚合 - 从局部融合到全局优化!》内容中,我们一起深入探讨了多尺度特征聚合 (Multi-Scale Feature Aggregation) 的奥秘。在开启今天激动人心的 Transformer 之旅前,让我们先花几分钟时间,回顾一下上期的核心知识点,为今天的学习打下坚实的基础。温故而知新,可以为师矣!
1.1 多尺度特征聚合的核心思想
在计算机视觉任务中,尤其是目标检测,目标的尺寸往往是多种多样的。一个模型如果只在单一尺度的特征图上进行预测,很难同时兼顾大、中、小所有尺寸的目标。这就像我们看世界,离得近看得清细节(对应高分辨率、浅层特征),离得远看得见轮廓(对应低分辨率、深层特征)。
多尺度特征聚合的核心思想,正是模仿人类的这种视觉机制,将来自骨干网络 (Backbone) 不同深度的、包含尺度信息的特征图进行有效整合,从而为后续的检测头 (Head) 提供一个信息更加丰富、语义表达能力更强的“全景图”。
它的目标非常明确:
- 融合高层语义与底层细节:深层特征图语义信息强,但空间细节丢失严重;浅层特征图细节丰富,但语义信息不足。聚合的目的就是让它们“取长补短”。
- 增强对不同尺寸目标的适应性:通过聚合,模型可以在不同的特征层上,分别“专注”于检测不同尺寸范围的目标。
1.2 关键技术盘点
为了实现有效的特征聚合,研究者们提出了许多精妙的技术,我们在上期重点讨论了以下几点:
- 多分辨率特征提取:这一切的基础是骨干网络能够产生一系列不同分辨率的特征图,例如 ResNet 中的 C2, C3, C4, C5 特征层。
- 尺度间信息传递:这是聚合的关键。最经典的方式莫过于 FPN (Feature Pyramid Network) 提出的“自顶向下” (Top-down) 路径,通过上采样将高层语义信息传递给底层。后续的 PANet、BiFPN 等则引入了“自底向上” (Bottom-up) 或双向路径,让信息流动更加充分。
- 特征对齐策略:不同层级的特征图分辨率不同,在融合前必须进行对齐。最常用的方法是上采样 (Upsampling)(如最近邻插值、双线性插值)和下采样 (Downsampling)(如步长卷积、池化)。
- 聚合权重学习:简单的特征相加或拼接 (Concatenation) 并不总是最优的。更高级的聚合方法,如 ASFF (Adaptively Spatial Feature Fusion) 和 BiFPN (Bidirectional FPN),引入了可学习的权重,让网络自适应地决定每个尺度特征的重要性,进行加权融合。
- 目标尺寸适应性:通过将不同尺寸的 Anchor 或预测任务分配到聚合后的不同金字塔层级,实现了对目标尺寸的天然适应性。
1.3 价值与局限性思考
多尺度特征聚合无疑是现代目标检测器中不可或缺的一环,它极大地提升了模型处理多尺度变化的能力,是 FPN 及其众多变种的核心贡献。
然而,传统的基于 CNN 的聚合方式也存在一些固有的局限性:
- 感受野限制:卷积操作本质上是一种局部运算。尽管通过堆叠卷积层可以扩大感受野,但要真正建立全局的长距离依赖关系 (Long-range Dependency),仍然非常困难。这导致在理解包含多个分离部分的大目标,或理解复杂的场景上下文时,模型可能会“力不从心”。
- 信息传递效率:特征在金字塔的不同层级间传递时,通常需要经过多步的卷积和采样操作。这个过程可能会导致信息“稀释”或“失真”。
- 内容无关性:标准的卷积和池化操作对于输入内容是“一视同仁”的,它们缺乏动态调整的能力来根据图像内容聚焦于关键区域。
正是这些局限性,为我们今天的主角——Feature Pyramid Transformer (FPT) 的登场,埋下了伏笔。FPT 试图用 Transformer 强大的全局建模能力,来彻底革新特征金字塔的信息交互方式。准备好了吗?让我们一起揭开它的神秘面纱!
🌟 二、今日主角:Feature Pyramid Transformer (FPT) 核心思想与动机
欢迎来到本期的核心部分!在这一章,我们将正式请出今天的主角——Feature Pyramid Transformer (FPT)。FPT 是将 Transformer 架构创造性地引入特征金字塔领域的杰出代表,它的出现为解决传统 CNN Neck 的瓶颈提供了全新的思路。
2.1 CNN 特征金字塔的“瓶颈”
正如我们上期回顾中提到的,以 FPN 为代表的基于 CNN 的特征融合网络 (Neck) 已经取得了巨大成功。它们通过构建“自顶向下”和“横向连接”的结构,实现了高层语义信息与底层细节信息的融合。
然而,这种融合方式更像是一种“和稀泥”式的相加或拼接。想象一下,从最高层(比如P5)传递下来的信息,需要经过多次上采样和卷积,才能到达最底层(比如P3)。在这个过程中,信息不可避免地会变得模糊和泛化。同时,卷积的局部性(inductive bias,归纳偏置)使得它天然不擅长捕捉图像中相距很远的两个像素之间的关联。
举个例子,假设图片中有一个人正在打网球。人的特征和网球拍的特征可能分布在特征图的不同区域。传统的 FPN 很难在特征层面就建立起“人”和“球拍”之间的强关联,因为它需要依赖非常深的卷积层才能将这两个区域的信息联系起来。
这就是 CNN 特征金字塔的核心瓶颈:长距离依赖建模能力的缺失。
2.2 Transformer 的“跨界”革命
与此同时,在自然语言处理 (NLP) 领域,Transformer 架构早已掀起了一场革命。其核心武器就是自注意力机制 (Self-Attention)。
自注意力机制的强大之处在于,它能够直接计算一个序列中任意两个元素之间的相互关系,并根据这种关系来更新每个元素的表示。这意味着,无论两个词在句子中相隔多远,Transformer 都能一步到位地捕捉到它们之间的依赖关系。这种能力正是我们前面提到的 CNN 所欠缺的。
受到 ViT (Vision Transformer) 等工作的启发,计算机视觉领域的研究者们开始思考:我们能否利用 Transformer 的这种强大能力来优化视觉任务呢?
2.3 FPT 的诞生:当金字塔遇见“变形金刚”
FPT 的核心思想,就是用 Transformer 来重构特征金字塔的信息融合过程。它不再满足于简单的信息传递,而是希望在金字塔的不同层级之间建立一个全局动态的、内容感知的“信息交换网络”。
FPT 的设计动机可以总结为以下几点:
- 打破局部性限制:利用自注意力机制,让特征金字塔的每一个位置都能“看到”并“关联”所有其他位置,无论它们在哪个层级、哪个空间位置。这极大地增强了模型的全局上下文理解能力。
- 实现跨尺度的深度交互:FPT 不再是单向或双向的固定路径信息流动。它将来自不同尺度的特征图(例如 P3, P4, P5)视作一个统一的序列,然后输入到一个 Transformer 编码器中。在这个编码器里,不同尺度的特征可以进行“无差别”的、深度的交互和融合。来自 P3 的一个像素,可以直接与来自 P5 的一个像素计算注意力得分,从而实现信息的直接交换。
- 内容感知的特征增强:自注意力的权重是根据输入内容动态计算的。这意味着 FPT 可以根据图像的具体内容,自适应地聚焦于最重要的特征,并增强它们的表达。例如,在处理一张包含小目标的图像时,模型可能会自动增加小目标所在区域特征的权重。
总而言之,FPT 的目标是将特征金字塔从一个相对静态的“信息传递管道”,升级为一个动态的、全局的“特征处理中心”。它用 Transformer 替换了 FPN 中原有的上采样、卷积和相加等融合操作,旨在生成表达能力更强、上下文信息更丰富的多尺度特征。
下面的流程图清晰地展示了传统 FPN 与 FPT 在设计哲学上的根本区别:
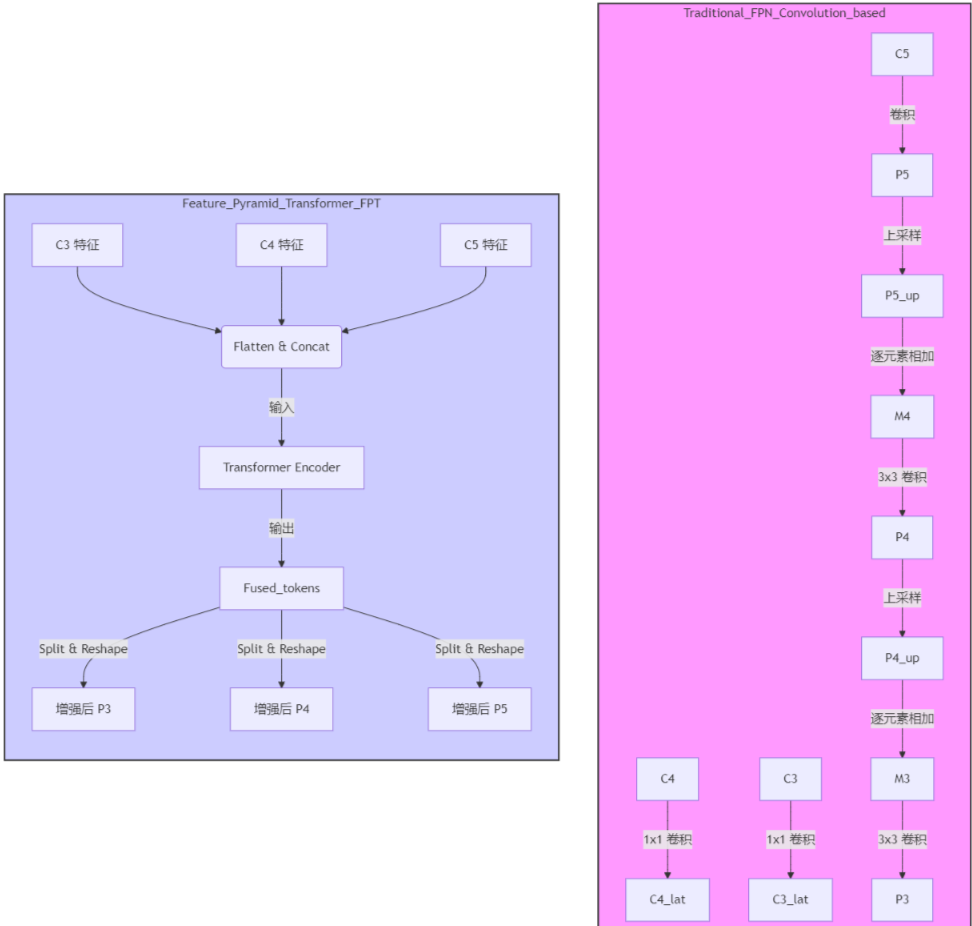
图1: 传统 FPN 与 FPT 架构对比
从图中可以直观地看出,FPN 是一种层次分明、逐步融合的结构,而 FPT 则是一种将所有尺度特征“一锅端”,进行全局融合的全新范式。这种范式的转变,正是 FPT 威力的来源。接下来,我们将深入其内部,探究它是如何具体实现的。
🚀 三、FPT 架构深度解析:构建跨尺度视觉语言
理解了 FPT 的核心动机后,是时候深入其内部,像解剖精密仪器一样,剖析它的每一个组件和工作流程了。坐稳了,我们将一起探索 FPT 如何构建一种全新的跨尺度“视觉语言”。
3.1 整体架构概览
一个典型的 FPT Neck 模块通常接收来自骨干网络(如 ResNet)的多个层级的特征图作为输入,例如 $C_3, C_4, C_5$。它的工作流程可以概括为以下几个步骤:
- Tokenization (令牌化):首先,将输入的三个二维特征图 $C_3, C_4, C_5$ 进行“令牌化”处理。具体来说,就是将每个特征图展平(Flatten)成一个一维的 token 序列。例如,一个尺寸为 $C \times H_3 \times W_3$ 的特征图 $C_3$ 会被转换成一个长度为 $H_3 \times W_3$ 的 token 序列,其中每个 token 是一个 C 维的向量。
- 统一维度与拼接:由于 Transformer 要求输入的 token 序列具有相同的维度,通常会使用一个 1x1 卷积(或线性层)将不同层级的特征(其通道数可能不同)映射到统一的维度 $d$。然后,将这三个 token 序列拼接(Concatenate)在一起,形成一个长长的、包含了所有尺度信息的总序列。
- 添加位置编码:为了让 Transformer 感知到每个 token 的原始位置信息(它来自哪个尺度、在原始特征图的哪个坐标),需要为每个 token 添加位置编码。FPT 的位置编码是一个关键创新点,我们稍后会详细讨论。
- FPT 编码器 (Transformer Encoder):将携带位置信息的总 token 序列输入到一个标准的 Transformer 编码器中。这个编码器由多个堆叠的 Transformer 层组成,每一层都包含一个多头自注意力 (Multi-Head Self-Attention) 模块和一个前馈神经网络 (Feed-Forward Network, FFN) 模块。在这里,不同尺度的 token 会进行深度、全局的交互。
- 逆令牌化 (De-Tokenization):经过 Transformer 编码器处理后,我们得到了一个增强后的总 token 序列。现在需要将其“逆向操作”,即根据原始的尺寸将这个长序列切分回三个部分,并分别重塑 (Reshape) 成二维的特征图,得到最终的输出 $P_3, P_4, P_5$。这些输出的特征图就可以送入后续的检测头了。
3.2 核心组件 (1): 自注意力 (Self-Attention) 机制回顾
要理解 FPT,必须先深刻理解自注意力。它的本质是一个加权求和的过程,但这个“权”是动态计算的。对于序列中的每一个 token,自注意力机制会做三件事:
- 生成 Q, K, V 向量:将该 token 的输入向量,通过三个不同的线性变换,分别得到查询向量 (Query, Q),键向量 (Key, K),和值向量 (Value, V)。
- 计算注意力得分:用这个 token 的 Q 向量,去和所有 token (包括它自己) 的 K 向量进行点积运算,得到一个相似度分数。这个分数代表了“我”(Q) 对“你”(K) 的关注程度。然后通过 Softmax 将这些分数归一化,得到最终的注意力权重。公式为:
$$Attention(Q, K, V) = \text{softmax}(\frac{QK^T}{\sqrt{d_k}})V$$
- 加权求和:用计算出的注意力权重,对所有 token 的 V 向量进行加权求和,得到该 token 最终的输出。
这个过程的奇妙之处在于,Q 和 K 的交互决定了信息应该从哪里来,而 V 则是实际传递的信息内容。通过这个机制,序列中的每个 token 都融合了来自全局所有 token 的信息。
3.3 核心组件 (2): 跨尺度自注意力 (Cross-Scale Self-Attention)
在 FPT 中,自注意力机制的应用场景非常特殊。因为输入的 token 序列是由不同尺度的特征图拼接而成的,所以这里的自注意力实际上是一种跨尺度自注意力 (Cross-Scale Self-Attention)。
这意味着:
- 一个来自 $P_3$ 的 token(代表图像中的一个小区域的细节特征),它的 Q 向量会与来自 $P_3, P_4, P_5$ 所有 token 的 K 向量计算相似度。
- 这使得这个 $P_3$ 的 token 能够直接从 $P_5$ 的某个 token(代表一个大范围的语义概念)那里获取信息,来增强自身的语义表达。
- 反之,一个来自 $P_5$ 的 token 也能直接关注到 $P_3$ 的某个细节 token,来补充自己的空间信息。
这种无视尺度边界的、完全平等的全局交互,是 FPT 相比传统 FPN 最大的优势所在。它构建了一个强大的信息交换中心,让不同尺度的特征不再是孤立的,而是真正地融为一体。
3.4 核心组件 (3): 位置编码 (Positional Encoding) 的演进
原始的 Transformer 是为处理序列数据(如文本)设计的,它本身不包含位置信息。因此,需要显式地添加位置编码 (Positional Encoding) 来告诉模型 token 的位置。
在 ViT 中,使用的是一个可学习的 1D 位置编码,因为它将图像块展平成了一维序列。然而,对于 FPT 来说,情况要复杂得多,因为 token 不仅有在各自特征图内的 2D 空间位置,还有它所属的尺度 (scale) 信息。
因此,FPT 需要一种能够同时编码尺度信息和空间信息的位置编码。一个常见且有效的设计是:
- 尺度编码 (Scale Embedding):为每个尺度($P_3, P_4, P_5$)分配一个可学习的嵌入向量 (embedding)。所有来自同一尺度的 token 共享同一个尺度编码。
- 空间编码 (Spatial Encoding):对于每个特征图,使用一个 2D 的位置编码方案。这可以是固定的正弦/余弦编码,也可以是可学习的 2D 位置嵌入。它为特征图内的每个位置 $(x, y)$ 提供一个独特的位置向量。
最终,一个 token 的总位置编码是其尺度编码和空间编码的相加或拼接。
$$ \text{PositionalEncoding}{\text{total}} = \text{ScaleEmbedding}{\text{level}} + \text{SpatialEncoding}_{2D}(x, y) $$
通过这种方式,Transformer 就能清晰地分辨出每个 token 的“身份”:“我是来自 P4 特征图,坐标 (10, 5) 的特征向量”。这对于建立有意义的跨尺度和空间依赖至关重要。
3.5 FPT 的信息流动:特征如何交互与增强
现在我们可以完整地串联起 FPT 的工作流程了:
- 来自不同尺度的特征 token,携带者各自的“内容信息”,进入了 FPT 的世界。
- 它们首先被赋予了独特的“身份牌”(位置编码),标明了自己的出处(尺度和空间位置)。
- 然后,它们进入了一个“圆桌会议”(Transformer Encoder)。在会议的每一轮(每个 Transformer Layer),每个 token 都会作为“查询者”(Q),去评估与会场上所有其他 token (K) 的“议题相关性”,并根据相关性大小,有选择性地听取(加权求和)其他 token 的“发言内容”(V)。
- 经过多轮(L层)深入的讨论和信息交换后,每个 token 的“认知”(特征向量)都得到了极大的丰富和更新,它不仅包含了自己原始的信息,还融合了来自全局、所有尺度的上下文信息。
- 最后,这些满载信息的 token 回到各自的岗位(被 Reshape 回二维特征图),形成了全新的、经过深度融合的特征金字塔 $P_3, P_4, P_5$。
这个过程优雅而强大,它将特征融合提升到了一个全新的高度。接下来,最激动人心的部分来了——我们将亲手用代码实现这一切!准备好你的编辑器了吗?Let's code! 💻
💻 四、FPT 代码实战:用 PyTorch 构建特征金字塔变换器
理论讲了这么多,是时候动手实践了!💪 纸上得来终觉浅,绝知此事要躬行。在这一章,我们将使用 PyTorch 一步步构建一个 Feature Pyramid Transformer (FPT) 模块。我会提供完整的、带有详细中文注释的代码,并对关键部分进行解析,确保你不仅能看懂,还能亲手复现。
免责声明:这里的代码是一个教学性质的简化实现,旨在清晰地展示 FPT 的核心思想。在实际的科研或工程项目中,可能需要考虑更多的细节和优化,例如更高效的自注意力实现、不同的归一化层等。
4.1 环境准备与基础模块搭建
首先,请确保你已经安装了 PyTorch。
pip install torch torchvision
我们需要导入必要的库,并设置一些基础的辅助模块。
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
from typing import List
确保代码可复现
torch.manual_seed(42)
一个简单的辅助函数,用于后续模块的初始化
def _get_activation_fn(activation):
"""根据字符串返回激活函数"""
if activation == "relu":
return F.relu
elif activation == "gelu":
return F.gelu
raise RuntimeError(F"activation should be relu/gelu, not {activation}")
代码片段1: 环境准备
代码解析:
- 我们导入了
torch及其神经网络模块nn。 _get_activation_fn是一个简单的帮助函数,用于根据配置选择激活函数,增加了代码的灵活性。- 设置随机种子是为了让我们的实验结果可以复现。
4.2 FPT 核心层:Transformer 编码器实现
Transformer Encoder Layer 是 FPT 的心脏。它由一个多头自注意力模块和一个前馈网络(也叫 MLP)组成。
class TransformerEncoderLayer(nn.Module):
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1, activation="relu"):
"""
Transformer 编码器层
参数:
d_model (int): 输入特征的维度 (token的维度)
nhead (int): 多头注意力机制中的头数
dim_feedforward (int): 前馈神经网络的隐藏层维度
dropout (float): Dropout 的比例
activation (str): 使用的激活函数 ('relu' 或 'gelu')
"""
super().__init__()
# 多头自注意力模块
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout, batch_first=True)
# 前馈神经网络 (FFN)
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, d_model)
# 两个 LayerNorm 层
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
# 两个 Dropout 层
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.activation = _get_activation_fn(activation)
def forward(self, src, src_mask=None, src_key_padding_mask=None):
"""
前向传播
参数:
src (Tensor): 输入序列 (Batch, SeqLen, Dim)
src_mask (Tensor, optional): 自注意力中的 mask. Defaults to None.
src_key_padding_mask (Tensor, optional): 用于 mask 掉 padding 的部分. Defaults to None.
返回:
Tensor: 经过编码器层处理后的输出 (Batch, SeqLen, Dim)
"""
# 1. 自注意力部分 (包含残差连接和 LayerNorm)
# PyTorch的MultiheadAttention期望的输入是 (Query, Key, Value)
src2 = self.self_attn(src, src, src, attn_mask=src_mask, key_padding_mask=src_key_padding_mask)[0]
# 残差连接: src + dropout(src2)
src = src + self.dropout1(src2)
# Layer Normalization
src = self.norm1(src)
# 2. 前馈神经网络部分 (包含残差连接和 LayerNorm)
src2 = self.linear2(self.dropout(self.activation(self.linear1(src))))
# 残差连接
src = src + self.dropout2(src2)
# Layer Normalization
src = self.norm2(src)
return src
代码片段 2: Transformer Encoder Layer 实现
代码解析:
-
__init__函数中,我们初始化了所有需要的模块:MultiheadAttention, 两个Linear层(构成 FFN),两个LayerNorm层和一些Dropout层。注意batch_first=True这个参数,它让我们的输入可以保持(Batch, SeqLen, Dim)的直观形式。 -
forward函数严格遵循了标准 Transformer 编码器的流程:- 自注意力 -> Add & Norm: 输入
src通过自注意力层,然后将输出与原始输入src相加(残差连接),最后通过LayerNorm。self.dropout1用来防止过拟合。 - FFN -> Add & Norm: 上一步的输出再经过前馈神经网络,同样进行残差连接和
LayerNorm。
- 自注意力 -> Add & Norm: 输入
-
这个模块的输入和输出形状完全相同,因此可以方便地堆叠多层。
4.3 FPT Neck 整体实现与解析
现在,我们将利用上面构建的 TransformerEncoderLayer 来组装完整的 FPT Neck。这部分包含了我们之前讨论的令牌化、位置编码、编码器和逆令牌化等所有步骤。
class FeaturePyramidTransformer(nn.Module):
def __init__(self, in_channels: List[int], d_model: int, nhead: int, num_encoder_layers: int,
dim_feedforward: int, dropout=0.1, activation="relu"):
"""
Feature Pyramid Transformer (FPT) Neck 实现
参数:
in_channels (List[int]): 输入的多个特征图的通道数列表, e.g., [512, 1024, 2048]
d_model (int): Transformer 的工作维度
nhead (int): 多头注意力头数
num_encoder_layers (int): Transformer Encoder 的层数
dim_feedforward (int): FFN 的隐藏层维度
dropout (float): Dropout 比例
activation (str): 激活函数
"""
super().__init__()
self.d_model = d_model
# 1. 输入投影层: 将不同通道数的输入特征图统一到 d_model 维度
self.input_proj = nn.ModuleList([
nn.Sequential(
nn.Conv2d(cin, d_model, kernel_size=1),
nn.GroupNorm(32, d_model), # 使用 GroupNorm 增加稳定性
) for cin in in_channels
])
# 2. Transformer 编码器
encoder_layer = TransformerEncoderLayer(d_model, nhead, dim_feedforward, dropout, activation)
self.encoder = nn.TransformerEncoder(encoder_layer, num_layers=num_encoder_layers)
# 3. 位置编码: 为不同尺度的特征图创建可学习的位置编码
self.scale_level_embed = nn.Parameter(torch.Tensor(len(in_channels), d_model))
# 初始化权重
self._reset_parameters()
def _reset_parameters(self):
"""初始化权重"""
nn.init.normal_(self.scale_level_embed)
def forward(self, features: List[torch.Tensor]):
"""
前向传播
参数:
features (List[Tensor]): 来自骨干网络的特征图列表, e.g., [C3, C4, C5]
返回:
List[Tensor]: 经过 FPT 增强后的特征图列表, [P3, P4, P5]
"""
# 用于存储处理后的 token 序列和其空间尺寸
tokens_list = []
spatial_shapes = []
# --- 步骤 1 & 2: Tokenization & 添加位置编码 ---
for i, feat in enumerate(features):
# 获取特征图尺寸
bs, c, h, w = feat.shape
spatial_shapes.append((h, w))
# 1a. 维度统一
proj_feat = self.input_proj[i](feat)
# 1b. Flatten: (bs, d_model, h, w) -> (bs, h*w, d_model)
flat_feat = proj_feat.flatten(2).permute(0, 2, 1)
# 2. 添加位置编码
# 创建 2D sin/cos 位置编码
pos_embed_2d = self.build_2d_sincos_position_embedding(w, h, self.d_model).to(flat_feat.device)
# 添加尺度编码和 2D 空间编码
# self.scale_level_embed[i][None, None, :] 会将尺度编码广播到整个特征图的所有 token
final_feat = flat_feat + pos_embed_2d + self.scale_level_embed[i][None, None, :]
tokens_list.append(final_feat)
# --- 步骤 3: 拼接所有 token ---
all_tokens = torch.cat(tokens_list, dim=1)
# --- 步骤 4: 输入到 Transformer Encoder ---
# (bs, N1+N2+N3, d_model) -> (bs, N1+N2+N3, d_model)
enhanced_tokens = self.encoder(all_tokens)
# --- 步骤 5: 逆令牌化 (De-Tokenization) ---
output_features = []
start_idx = 0
for (h, w) in spatial_shapes:
num_tokens = h * w
# 切分出对应尺度的 token
level_tokens = enhanced_tokens[:, start_idx : start_idx + num_tokens]
start_idx += num_tokens
# Reshape 回二维特征图: (bs, h*w, d_model) -> (bs, d_model, h, w)
level_feat = level_tokens.permute(0, 2, 1).reshape(bs, self.d_model, h, w)
output_features.append(level_feat)
return output_features
@staticmethod
def build_2d_sincos_position_embedding(w, h, embed_dim=256, temperature=10000.):
"""构建 2D Sinusoidal 位置编码"""
grid_w = torch.arange(w, dtype=torch.float32)
grid_h = torch.arange(h, dtype=torch.float32)
grid_w, grid_h = torch.meshgrid(grid_w, grid_h, indexing='ij')
assert embed_dim % 4 == 0, 'Embed dimension must be divisible by 4 for 2D sin-cos position embedding'
pos_dim = embed_dim // 2
# 计算 sin/cos 的频率
omega = torch.arange(pos_dim / 2, dtype=torch.float32) / (pos_dim / 2 - 1)
omega = 1. / (temperature ** omega)
# 计算不同维度的位置编码值
out_w = grid_w.flatten()[:, None] @ omega[None, :]
out_h = grid_h.flatten()[:, None] @ omega[None, :]
# 拼接并 reshape
pos_emb = torch.cat([torch.sin(out_w), torch.cos(out_w), torch.sin(out_h), torch.cos(out_h)], dim=1)
pos_emb = pos_emb.reshape(h, w, embed_dim).permute(2, 0, 1) # (d_model, h, w)
pos_emb = pos_emb.flatten(1).permute(1, 0) # (h*w, d_model)
return pos_emb[None, :, :] # (1, h*w, d_model)
代码片段 3: FPT Neck 完整实现
代码解析:
-
__init__:input_proj: 这是我们的“守门员”。由于骨干网络输出的 $C_3, C_4, C_5$ 特征图通道数很可能不同(例如 ResNet50 是[512, 1024, 2048]),我们需要用 1x1 卷积将它们统一到 Transformer 的工作维度d_model。encoder: 我们直接使用了 PyTorch 提供的nn.TransformerEncoder,它能方便地将我们自定义的TransformerEncoderLayer堆叠起来。scale_level_embed: 这是我们的尺度编码。我们创建了一个可学习的nn.Parameter,其大小为(尺度数量, d_model)。
-
forward:- 循环处理每个输入特征: 遍历输入的
features列表。 - Tokenization:
proj_feat.flatten(2).permute(0, 2, 1)是一个非常标准的操作,将(B, C, H, W)的图像格式转换为(B, H*W, C)的序列格式,这正是 Transformer 喜欢的。 - 位置编码: 我们调用
build_2d_sincos_position_embedding来生成固定的 2D 空间位置编码。然后,将内容特征flat_feat、空间位置编码pos_embed_2d和尺度编码scale_level_embed三者相加。这里利用了 PyTorch 的广播机制,尺度编码(1, 1, d_model)和空间编码(1, h*w, d_model)会被自动扩展并加到(bs, h*w, d_model)的flat_feat上。 - 拼接:
torch.cat(tokens_list, dim=1)将所有尺度的 token 序列沿着序列长度的维度拼接起来,形成一个大序列。 - Encoder 处理: 将这个大序列喂给
self.encoder。 - De-Tokenization: 这是 Tokenization 的逆过程。我们根据之前保存的
spatial_shapes,从增强后的大序列中依次切分出属于每个尺度的部分,并使用reshape将其恢复为(bs, d_model, h, w)的图像格式。
- 循环处理每个输入特征: 遍历输入的
-
build_2d_sincos_position_embedding:- 这是一个静态方法,实现了经典的 2D 正余弦位置编码。它的原理与 1D 版本类似,但将一半的维度分配给 x 坐标,一半分配给 y 坐标,从而在一个向量中同时编码了二维空间位置。
4.4 接入检测网络:一个完整的使用示例
现在我们来模拟一下如何将这个 FPT Neck 模块接入到一个目标检测模型中。
if __name__ == '__main__':
# --- 模型配置 ---
# 假设骨干网络输出的特征通道数
backbone_out_channels = [512, 1024, 2048]
# FPT Neck 的配置
d_model = 256 # Transformer 的工作维度
nhead = 8 # 多头注意力头数
num_encoder_layers = 4 # Transformer 层数
dim_feedforward = 1024 # FFN 隐藏层维度
# --- 实例化 FPT Neck ---
fpt_neck = FeaturePyramidTransformer(
in_channels=backbone_out_channels,
d_model=d_model,
nhead=nhead,
num_encoder_layers=num_encoder_layers,
dim_feedforward=dim_feedforward
)
print("FPT Neck 实例化成功!")
print(fpt_neck)
# --- 模拟输入 ---
# 假设 batch_size = 2
bs = 2
# 模拟来自 ResNet 的 C3, C4, C5 特征图
# 尺寸通常是下采样 8, 16, 32 倍
# 例如输入图像是 800x800
input_c3 = torch.randn(bs, backbone_out_channels[0], 100, 100)
input_c4 = torch.randn(bs, backbone_out_channels[1], 50, 50)
input_c5 = torch.randn(bs, backbone_out_channels[2], 25, 25)
dummy_inputs = [input_c3, input_c4, input_c5]
print("\n--- 模拟输入尺寸 ---")
for i, f in enumerate(dummy_inputs):
print(f"输入 C{i+3} 尺寸: {f.shape}")
# --- 前向传播测试 ---
output_features = fpt_neck(dummy_inputs)
print("\n--- FPT 输出尺寸 ---")
for i, p in enumerate(output_features):
print(f"输出 P{i+3} 尺寸: {p.shape}")
# --- 验证输出维度 ---
for p in output_features:
# 输出的通道数应该都等于 d_model
assert p.shape[1] == d_model
print("\n✅ 所有测试通过!FPT Neck 正常工作。")
代码片段 4: 完整使用示例
代码解析与结果:
- 我们首先定义了模型的超参数,如
d_model、nhead等。 - 然后,我们创建了三个随机的张量来模拟来自骨干网络的 $C_3, C_4, C_5$ 特征图。注意它们的通道数和尺寸都不同。
- 将这些模拟输入送入我们实例化的
fpt_neck。 - 最后,我们打印输出特征图的尺寸。你会看到,输出的 $P_3, P_4, P_5$ 在空间尺寸上与输入保持一致,但它们的通道数都被统一为了
d_model(在这里是 256)。这证明我们的 FPT Neck 成功地处理了多尺度输入,并生成了融合后的特征金字塔。
预期输出:
FPT Neck 实例化成功!
FeaturePyramidTransformer(...)
— 模拟输入尺寸 —
输入 C3 尺寸: torch.Size([2, 512, 100, 100])
输入 C4 尺寸: torch.Size([2, 1024, 50, 50])
输入 C5 尺寸: torch.Size([2, 2048, 25, 25])
— FPT 输出尺寸 —
输出 P3 尺寸: torch.Size([2, 256, 100, 100])
输出 P4 尺寸: torch.Size([2, 256, 50, 50])
输出 P5 尺寸: torch.Size([2, 256, 25, 25])
✅ 所有测试通过!FPT Neck 正常工作。
这段代码为你提供了一个坚实的基础,你可以基于它进行修改、扩展,甚至将其集成到你自己的目标检测框架中去。动手试试吧,亲自感受 Transformer 在视觉任务中的力量!🥳
⚖️ 五、性能、效率与优化:FPT 的权衡与未来
任何强大的技术都不是“银弹”,FPT 也不例外。它在带来强大性能的同时,也引入了新的挑战。在这一章,我们将客观地分析 FPT 的优劣,并探讨其未来的发展方向。
5.1 FPT 的性能优势:为何它如此强大?
FPT 在多个基准测试上都展示了超越传统 FPN 及其变种的潜力。其性能优势主要源于我们之前反复强调的几点:
- 全局上下文建模:自注意力机制打破了卷积的局部感受野限制,能够捕捉图像中任意两个像素之间的长距离依赖关系。这对于理解大目标、复杂场景以及物体间的关系至关重要。
- 动态与内容感知:注意力权重是根据输入动态生成的,使得 FPT 能够“智能”地聚焦于对当前任务最重要的特征区域,并抑制无关噪声。
- 彻底的跨尺度融合:FPT 将所有尺度的特征放在一个平等的舞台上进行交互,信息交换是直接且彻底的,避免了传统 FPN 逐级传递可能造成的信息损失和延迟。
- 强大的表示能力:Transformer 作为一个强大的特征提取器,已经被证明能够学习到比 CNN 更具泛化能力的特征表示。将这种能力用于特征融合,自然能够生成质量更高的特征金字塔。
5.2 计算复杂度的挑战与优化策略
FPT 最大的“阿喀琉斯之踵”在于其计算复杂度。
标准的自注意力机制的计算复杂度和内存消耗是关于输入序列长度 $N$ 的二次方,即 $O(N^2)$。在 FPT 中,输入序列的 $N$ 是所有特征图像素数量的总和,即 $N = \sum_i (H_i \times W_i)$。当处理高分辨率图像时,这个 $N$ 会变得非常大,导致计算量和显存占用急剧增加。
例如,对于一个800x800 的输入图像,C3 特征图 (100x100) 就有 10000 个 token,C4 (50x50) 有 2500 个,C5 (25x25) 有 625 个。总 token 数 $N = 13125$。计算 $N \times N$ 的注意力矩阵将是一个巨大的负担。
为了应对这个挑战,研究者们提出了多种优化策略:
- 窗口化/局部注意力 (Windowed/Local Attention):借鉴 Swin Transformer 的思想,不计算全局注意力,而是在每个尺度内部划分不重叠的窗口(例如 7x7),只在窗口内计算自注意力。为了实现跨窗口信息交流,可以采用窗口移动 (shifted window) 的策略。
- 稀疏注意力 (Sparse Attention):设计一种稀疏的注意力模式,让每个 token 只与一部分“关键”的 token 进行交互,而不是全部。例如,可以只关注全局的几个下采样后的 token,或者只关注空间上邻近的 token。
- 线性注意力 (Linear Attention):发展一系列近似算法,将自注意力的复杂度从 $O(N^2)$ 降低到 $O(N)$。这类方法(如 Linformer, Performer)通过数学变换避免了显式地计算 $N \times N$ 的注意力矩阵。
- 下采样 (Downsampling):在送入 Transformer 之前,可以对 Key 和 Value 序列进行下采样(例如通过平均池化或步长卷积),从而减小注意力矩阵的尺寸。这是 PVT (Pyramid Vision Transformer) 中采用的核心思想。
将这些优化策略应用到 FPT 中,可以在保持其大部分性能优势的同时,显著降低计算成本,使其在实际应用中更具可行性。
5.3 FPT 的变种与未来发展方向
FPT 的出现打开了一扇新的大门,激发了大量后续研究。它的未来发展可能集中在以下几个方向:
- 更高效的架构:持续探索新的、更高效的注意力机制,进一步平衡性能和效率,是 FPT 走向更广泛应用的关键。
- 与 CNN 的深度结合:纯粹的 Transformer 架构可能缺乏 CNN 的一些优秀归纳偏置(如平移不变性)。如何将两者的优点(CNN的局部建模效率和 Transformer 的全局建模能力)更优雅、更深度地结合起来,是一个非常有前景的研究方向。
- 多模态融合:Transformer 天然适合处理多种序列数据。未来的 FPT 变种可能会探索如何将图像特征与其他模态(如文本描述、音频信号)的信息在特征金字塔层面进行融合。
- 神经架构搜索 (NAS):利用 NAS 技术自动搜索最优的 FPT 架构,例如决定在哪些尺度之间应用 Transformer、使用多少层、注意力头的数量等,可能会发现比人工设计更强大的结构。
毫无疑问,Feature Pyramid Transformer 及其思想将继续在计算机视觉领域发光发热,推动目标检测乃至更多视觉任务的边界不断向前拓展。
🎓 六、总结与展望
在本篇长文中,我们进行了一次穿越“特征金字塔”和“变形金刚”世界的深度旅行。让我们一起回顾一下这次旅程的收获吧!
- 我们从回顾多尺度特征聚合开始,理解了传统 FPN 类方法的优势与内在局限性——即对长距离依赖建模的不足。
- 接着,我们引出了主角 FPT,阐述了它如何利用 Transformer 的自注意力机制来打破这一瓶颈,其核心动机在于实现全局的、动态的、跨尺度的特征交互。
- 我们深度剖析了 FPT 的架构,详细解读了令牌化、创新的位置编码、跨尺度自注意力以及逆令牌化等关键步骤,并通过 Mermaid 图清晰地展示了其数据流。
- 最激动人心的是,我们通过PyTorch 代码实战,从零开始构建了一个完整的 FPT Neck 模块。每一行代码都配有详尽的中文注释和解析,确保了知识的落地和可操作性。
- 最后,我们客观地讨论了 FPT 的性能、效率挑战以及优化策略,并展望了其未来的发展方向,看到了它在视觉领域的巨大潜力。
FPT 不仅仅是一个具体的模型,它更代表了一种设计范式的转变:从依赖卷积的局部、层次化信息传递,转向基于注意力的全局、扁平化信息交互。这一转变深刻地影响了现代检测器的设计哲学。
希望通过今天的学习,你不仅掌握了 FPT 的原理和实现,更能从中获得启发,去思考如何在自己的研究或项目中,利用 Transformer 这一强大的工具来解决更复杂的视觉问题。技术的浪潮滚滚向前,保持好奇,不断学习,是我们每个技术人最宝贵的品质!为你点赞!🌟
🔔 七、蓄势待发:下期内容预告 (CARAFE)
在今天的学习中,我们探讨了如何利用 Transformer 进行复杂的特征融合。而在特征金字塔中,除了融合,上采样 (Upsampling) 也是一个至关重要的环节。传统的上采样方法,如最近邻插值和双线性插值,虽然计算高效,但它们是内容无关 (content-agnostic) 的,无法根据特征的语义信息来智能地进行放大,常常会导致细节模糊或产生伪影。
为了解决这个问题,一个轻量级且高效的“智能上采样”算子应运而生,它就是我们下一期的主角——CARAFE (Content-Aware ReAssembly of FEatures)!
在第13节中,我们将一起探索:
- 内容感知重组:CARAFE如何做到“看懂”特征内容,并为每个像素动态生成最适合它的重组核?
- 轻量级实现:它如何在实现智能上采样的同时,保持极低的参数量和计算开销?
- 特征重分配机制:深入理解 CARAFE 的核心——上采样核预测模块和内容感知重组模块的工作原理。
- 无缝集成:我们将展示 CARAFE 如何作为一个即插即用的模块,轻松替换现有检测器中的上采样层,并带来显著的性能提升。
如果你对如何让特征图的“放大”过程变得更智能、更高效感兴趣,那么下一期的内容绝对不容错过!让我们一起期待与 CARAFE 的相遇吧!下次再见!👋😊
希望本文所提供的YOLOv8内容能够帮助到你,特别是在模型精度提升和推理速度优化方面。
-End-
