
YOLOv8【特征融合Neck篇·第13节】一文弄懂,CARAFE上采样特征重组!


专栏回顾:温故而知新
哈喽,各位小伙伴们,大家好!👋 在上一期《YOLOv8【特征融合Neck篇·第12节】一文搞懂,Feature Pyramid Transformer特征金字塔变换器!》的分享中,我们一起探索了如何将强大的 Transformer 架构融入到特征金字塔网络(FPN)中,从而诞生了 Feature Pyramid Transformer (FPT)。
我们知道,传统的 FPN 通过自上而下和横向连接的方式,有效地融合了多尺度特征,极大地提升了目标检测的性能。然而,这种特征交互方式在很大程度上仍然是局部的,依赖于相邻层级的特征传递。
FPT 的出现,为我们打开了一扇新的大门!🚪 它创造性地引入了 自注意力机制(Self-Attention) 来处理不同尺度特征图之间的信息交互。其核心思想是:将来自不同金字塔层级的特征“扁平化”为序列,然后送入 Transformer 编码器中。这样做的好处是:
- 全局感受野:Transformer 的自注意力机制能够捕捉特征图上任意两个像素之间的依赖关系,无论它们相距多远。这使得 FPT 能够建立跨越所有尺度的 长距离依赖关系,让小物体特征也能“看到”全局的上下文信息,大物体特征也能关注到细节。
- 动态特征交互:与 FPN 固定的融合路径不同,FPT 中的特征交互是 动态的、内容感知的。模型可以根据输入图像的内容,自适应地学习哪些尺度的特征应该进行更紧密的交互,从而实现更高效、更智能的特征融合。
- 更强的表征能力:通过 Transformer 的多头自注意力和前馈网络,FPT 能够对融合后的特征进行深度提炼和转换,生成语义信息更丰富、表征能力更强的特征金字塔。
我们还探讨了 FPT 在设计上的一些挑战,比如如何处理不同分辨率特征图的尺寸对齐问题,以及如何设计有效的位置编码来保留空间信息。总而言之,FPT 的出现,不仅是 Transformer 在检测领域的一次成功应用,更为我们展示了利用全局建模能力来优化多尺度特征融合的巨大潜力。
回顾了 FPT 的全局视野,今天,我们将把目光重新聚焦于 FPN 中一个看似微小但至关重要的环节——上采样。准备好了吗?让我们一起进入 CARAFE 的世界,看看它是如何用“内容感知”的方式,对特征进行精巧的重组!✨
一、引言:上采样的“前世今生”
大家好!今天我们要聊的话题,是深度学习模型中一个“润物细无声”却又不可或缺的操作——上采样(Upsampling)。
摘要:在计算机视觉的密集预测任务(如目标检测、语义分割)中,上采样是恢复特征图分辨率、融合多尺度信息的关键步骤。然而,传统的上采样方法如最近邻插值、双线性插值或反卷积,或多或少存在着内容无关、感受野过小或计算开销大等问题。本文将深入剖析 CARAFE(Content-Aware ReAssembly of FEatures),一种轻量级、高效且通用的上采样算子。我们将从其核心思想、网络架构、代码实现到性能对比,全方位解析 CARAFE 如何通过动态预测上采样核并进行内容感知的特征重组,从而在几乎不增加额外参数量和计算成本的情况下,显著提升各类视觉任务的性能。
1.1 为何需要上采样?
在现代的卷积神经网络(CNN)中,为了提取更高级、更抽象的语义信息,我们通常会堆叠大量的卷积层和池化层。这个过程就像是不断地对输入图像进行“提纯”和“浓缩”,特征图的空间分辨率会越来越低,而通道数(语义信息)会越来越多。这种“下采样(Downsampling)”的设计对于图像分类等任务非常有效。
然而,对于目标检测、语义分割、实例分割这类**密集预测(Dense Prediction)**任务而言,我们不仅需要知道图像里“有什么”,还需要知道它们“在哪里”。这意味着最终的输出需要恢复到较高的空间分辨率,以便进行像素级的分类或定位。
因此,上采样就登上了历史舞台。它的核心任务就是将低分辨率、高语义的特征图,恢复成高分辨率的特征图。在特征金字塔网络(FPN)这类架构中,上采样更是扮演着将高层语义信息传递给底层细节信息的关键桥梁角色。
1.2 传统上采样方法的局限性
在 CARAFE 出现之前,主流的上采样方法可以分为两大类:基于插值的方法和可学习的方法。但它们都存在一些固有的缺陷。
1.2.1 插值法(Interpolation)
这是最简单、最常用的一类方法。
- 最近邻插值 (Nearest Neighbor Interpolation):简单粗暴,直接复制最近邻像素的值。优点是速度极快,但缺点是会产生严重的棋盘格效应和锯齿,图像质量很差。
- 双线性插值 (Bilinear Interpolation):考虑了待插入点周围4个最近邻像素点的值,并根据距离进行加权平均。效果比最近邻平滑得多,是目前最广泛使用的上采样方法之一。
局限性分析:
插值法的最大问题在于它们是 内容无关的(Content-Agnostic)。无论是对一张人脸图片还是一张风景图片,双线性插值的计算方式都是完全相同的。它只关心像素的“位置”,而不关心像素的“内容”。这导致了一个致命缺陷:它的感受野非常小(对于双线性插值,感受野只有 2x2)。这意味着,在进行上采样时,一个像素点的计算完全无法利用更大范围的上下文信息,自然也无法生成高质量、语义丰富的特征图。
1.2.2 可学习的方法(Learnable)
为了克服插值法的局限性,研究者们提出了可学习的上采样层。
- 反卷积 (Deconvolution / Transposed Convolution):它本质上是一种特殊的卷积操作。通过在像素之间填充0,然后进行标准的卷积,从而扩大特征图的尺寸。
- 亚像素卷积 (Sub-pixel Convolution):也叫“像素重组”(Pixel Shuffle)。它先通过一个标准的卷积将通道数扩大
r²倍(r是上采样因子),然后通过周期性地“洗牌”(Shuffle),将这C*r*r个通道的特征图重组为一个C通道、空间分辨率扩大r倍的特征图。
局限性分析:
- 反卷积:虽然引入了可学习的参数,但它容易在输出中产生“棋盘格伪影”(Checkerboard Artifacts),这是因为其卷积核在应用时存在重叠区域,导致输出不均匀。此外,它的参数量和计算量相对较大。
- 亚像素卷积:在一定程度上缓解了棋盘格问题,但其感受野仍然受限于前面的卷积层,通常也较小。
1.3 CARAFE 的诞生:我们真正需要什么样的上采样?
总结一下,一个理想的上采样算子应该具备以下特点:
- 大的感受野:能够利用大范围的上下文信息来指导上采样过程。
- 内容感知:能够根据不同的语义内容,动态地、自适应地生成上采样权重。
- 轻量级:引入的额外参数和计算开销应该尽可能小,以便于广泛应用。
正是基于这些思考,旷视科技的研究员们提出了 CARAFE (Content-Aware ReAssembly of FEatures)。它的核心思想非常直观且优雅:为每一个目标位置,动态地预测一个独一无二的、依赖于局部内容的“重组核”(Reassembly Kernel),然后利用这个核来指导如何从原始特征图中“采集”信息并“重组”成新的特征。
接下来,就让我们一起深入 CARAFE 的内部,看看它是如何巧妙地实现这一目标的吧!🤩
二、CARAFE 核心原理深度剖析
CARAFE 的设计哲学是将上采样过程分解为两个关键步骤:首先,预测如何进行重组;其次,根据预测的指导来执行重组。这分别对应了它的两个核心模块:上采样核预测模块 和 内容感知重组模块。
2.1 整体架构概览
假设我们要将一个尺寸为 C × H × W 的输入特征图 X 上采样 σ 倍,得到一个尺寸为 C × σH × σW 的输出特征图 X'。CARAFE 的整体流程如下图所示:
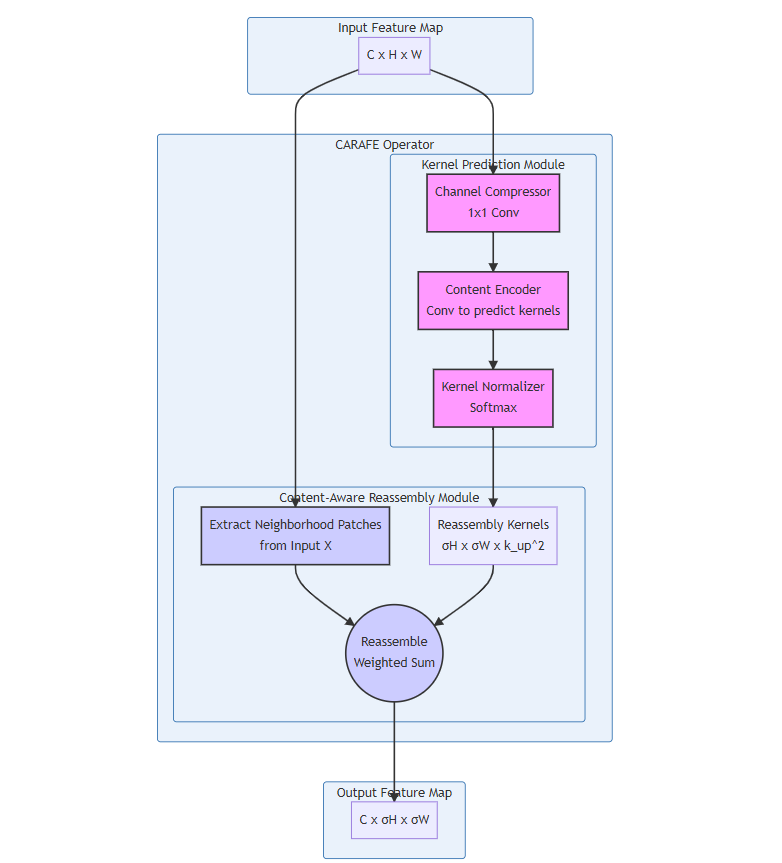
图2:CARAFE 整体架构流程图
从图中可以看出,整个流程分为两条路径:
- 上方路径(Kernel Prediction):输入特征图
X经过该模块,为输出特征图的每一个位置都生成一个k_up × k_up大小的重组核。 - 下方路径(Feature Reassembly):利用上方路径生成的重组核,在输入特征图
X上的相应位置提取一个k_up × k_up的邻域,然后进行加权求和,得到最终的输出像素。
下面我们来详细拆解这两个模块。
2.2 上采样核预测模块(Kernel Prediction Module)
这个模块的目标是生成内容感知的重组核。它的设计非常精巧,充分考虑了效率和性能的平衡。
2.2.1 通道压缩器(Channel Compressor)
- 目的:减少后续计算的参数量和计算量。
- 实现:使用一个
1×1卷积。将输入特征图X的通道数从C压缩到C_m。通常C_m会远小于C(例如,C_m = 64)。 - 公式:
X_comp = Conv_1x1(X),其中X_comp尺寸为C_m × H × W。
这一步是至关重要的优化,因为它使得 CARAFE 的计算成本与输入特征的通道数 C 解耦,变得更加轻量。
2.2.2 内容编码器(Content Encoder)
-
目的:根据压缩后的特征,为每个目标位置生成对应的重组核。
-
实现:使用一个
k_encoder × k_encoder的卷积层。这一步是实现“内容感知”和“大感受野”的关键。k_encoder决定了在预测重组核时,模型能“看到”多大的范围。这个卷积层的输出通道数被设计为σ² * k_up²。σ是上采样因子。k_up是我们希望的重组核的大小(例如5×5)。
-
维度变化:输入是
C_m × H × W,经过Conv_k_encoder后,输出是一个尺寸为(σ² * k_up²) × H × W的张量。 -
空间重塑:为了方便后续处理,这个张量会被重塑(Pixel Shuffle 的逆操作)成
k_up² × σH × σW。现在,我们可以清楚地看到,对于输出特征图上的每一个位置(i, j),我们都有一个长度为k_up²的向量,这个向量就代表了k_up × k_up的重组核(在应用 Softmax 之前)。
2.2.3 核归一化(Kernel Normalizer)
- 目的:确保重组核的权重和为1,使其成为一个有效的加权平均操作。
- 实现:对
k_up²这个维度应用Softmax函数。 - 公式:对于输出位置
l'=(i', j')的重组核W_l',我们对其进行归一化:W'_l' = Softmax(W_l')。
经过这三步,我们就成功地为输出特征图的每一个 σH × σW 位置,都生成了一个独特的、内容感知的 k_up × k_up 重组核!🎉
2.3 内容感知重组模块(Content-Aware Reassembly Module)
这个模块负责执行真正的“重组”工作。
-
输入:
- 原始的、高维度的特征图
X(尺寸C × H × W)。 - 预测并归一化后的重组核
W'(尺寸k_up² × σH × σW)。
- 原始的、高维度的特征图
-
工作流程:
- 对于输出特征图
X'上的每一个位置l'=(i', j'): - 首先,找到它在输入特征图
X上的中心对应位置l = (i, j),其中i = floor(i'/σ),j = floor(j'/σ)。 - 以
l为中心,在X上提取一个k_up × k_up大小的邻域(Patch),记作N(l)。这个邻域包含了k_up²个特征向量,每个向量都是C维的。 - 获取该位置对应的重组核
W'_l'(一个k_up × k_up的权重矩阵)。 - 将邻域
N(l)中的k_up²个特征向量与重组核W'_l'的k_up²个权重进行加权求和。
- 对于输出特征图
-
公式:输出特征
X'_{l'}的计算方式为: $$X'{l'} = \sum{n=1}^{k_{up}^2} W'{l'}(n) \cdot X{l+ \Delta n}$$ 其中Δn表示从邻域中心l到第n个邻居的偏移量。
这个过程对所有 C 个通道都应用相同的重组核。这既保证了内容感知,又避免了巨大的计算开销。
2.4 CARAFE 工作流程总结
让我们用一个流程图来总结一下 CARAFE 的精髓:
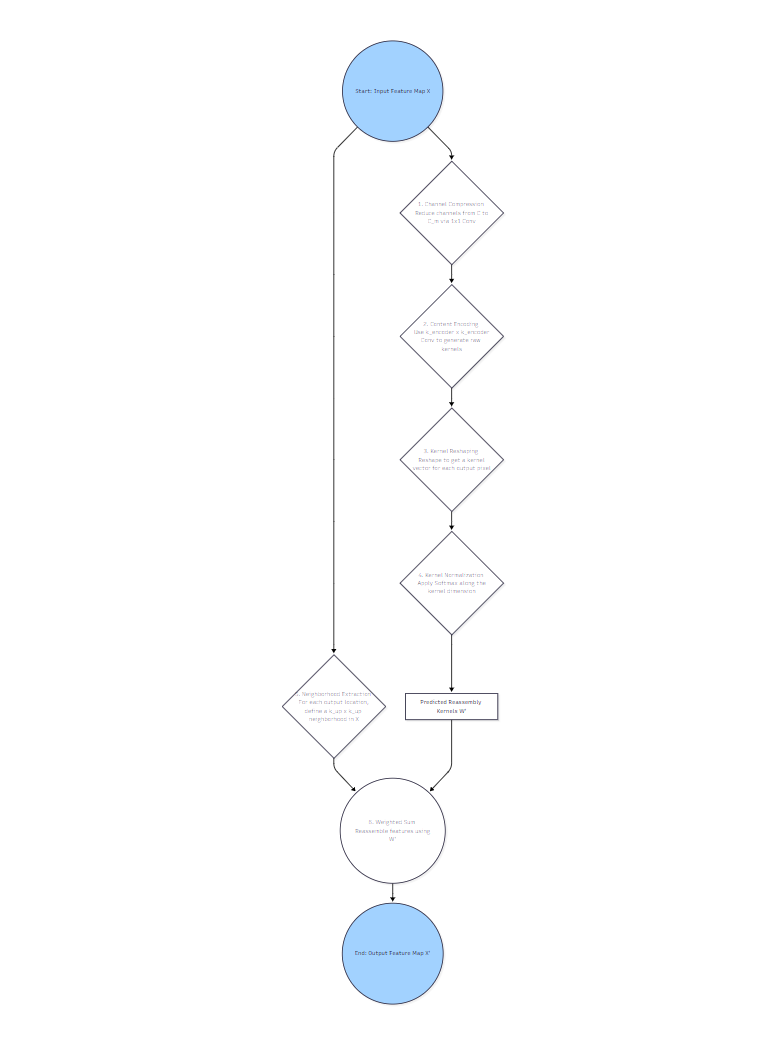
图4:CARAFE 详细工作流程
CARAFE 的设计真的是充满了智慧!它没有像反卷积那样引入一个巨大的、全局共享的卷积核,而是巧妙地为每个位置动态生成一个小的、局部的重组核。这使得它既能适应局部内容的变化,又能保持轻量级。
三、CARAFE 的 PyTorch 从零实现与解析
理论说完了,是时候上代码了!💻 光说不练假把式,通过代码实现,我们可以更深刻地理解 CARAFE 的每一个细节。下面是一个完整、带有详细中文注释的 PyTorch 实现。
3.1 完整 PyTorch 代码
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn.modules.utils import _pair
class CARAFE(nn.Module):
def init(self,
in_channels, # 输入特征图的通道数
out_channels, # 输出特征图的通道数 (通常等于 in_channels)
kernel_size=3, # 内容编码器卷积核大小 (k_encoder)
up_factor=2, # 上采样因子 (σ)
up_kernel_size=5):# 重组核大小 (k_up)
"""
CARAFE 模块的初始化函数
Args:
in_channels (int): 输入特征图的通道数 C
out_channels (int): 输出特征图的通道数 (在 CARAFE 中,通常与 in_channels 相同)
kernel_size (int): 内容编码器中的卷积核大小 k_encoder
up_factor (int): 上采样因子 σ
up_kernel_size (int): 重组核的大小 k_up
"""
super(CARAFE, self).init()
# 参数校验
assert isinstance(kernel_size, int) or isinstance(kernel_size, tuple)
assert isinstance(up_kernel_size, int) or isinstance(up_kernel_size, tuple)
self.in_channels = in_channels
self.out_channels = out_channels
self.kernel_size = kernel_size
self.up_factor = up_factor
self.up_kernel_size = up_kernel_size
# 计算通道压缩后的通道数 C_m
# 论文中建议 C_m = 64
self.compressed_channels = 64
# 1. 上采样核预测模块 (Kernel Prediction Module)
# 1.1 通道压缩器 (Channel Compressor)
# 使用 1x1 卷积将通道数从 C 压缩到 C_m
self.channel_compressor = nn.Conv2d(in_channels, self.compressed_channels, kernel_size=1)
# 1.2 内容编码器 (Content Encoder)
# 使用 k_encoder x k_encoder 卷积生成重组核
# 输出通道数为 (σ * k_up)^2
self.content_encoder = nn.Conv2d(
self.compressed_channels,
self.up_factor * self.up_factor * self.up_kernel_size * self.up_kernel_size,
kernel_size=self.kernel_size,
padding=self.kernel_size // 2 # 保持分辨率不变
)
# 1.3 核归一化器 (Kernel Normalizer)
# 使用 PixelShuffle 来实现空间重塑,并用 Softmax 进行归一化
self.pixel_shuffler = nn.PixelShuffle(self.up_factor)
# 用于 Softmax 归一化
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
"""
CARAFE 的前向传播函数
Args:
x (Tensor): 输入特征图,形状为 (B, C, H, W)
Returns:
Tensor: 上采样后的输出特征图,形状为 (B, C, σH, σW)
"""
batch_size, channels, height, width = x.size()
# === 1. 上采样核预测 ===
# 1.1 通道压缩
compressed_x = self.channel_compressor(x)
# 1.2 内容编码
# 输出形状: (B, (σ^2 * k_up^2), H, W)
encoded_kernels = self.content_encoder(compressed_x)
# 1.3 空间重塑 (利用 PixelShuffle)
# 将形状从 (B, (σ^2 * k_up^2), H, W) 变为 (B, k_up^2, σH, σW)
reshaped_kernels = self.pixel_shuffler(encoded_kernels)
# 1.4 核归一化
# 在 k_up^2 维度上进行 Softmax
normalized_kernels = self.softmax(reshaped_kernels)
# === 2. 内容感知重组 ===
# 为了进行加权求和,我们需要从输入特征图 x 中提取邻域 (patches)
# 使用 F.unfold 可以高效地实现这个操作
# unfold 的参数: kernel_size, dilation, padding, stride
# 我们需要提取 k_up x k_up 的邻域
unfolded_x = F.unfold(
x,
kernel_size=self.up_kernel_size,
padding=self.up_kernel_size // 2
)
# unfold 输出形状: (B, C * k_up^2, H * W)
# 我们需要将其变形为 (B, C, k_up^2, H, W) 以便后续计算
unfolded_x = unfolded_x.view(
batch_size,
channels,
self.up_kernel_size * self.up_kernel_size,
height,
width
)
# 现在,我们将邻域特征上采样到目标尺寸,以便与重组核对齐
# 使用最近邻插值,因为我们只是想复制数据,而不是混合它们
unfolded_x_resampled = F.interpolate(
unfolded_x,
scale_factor=self.up_factor,
mode='nearest'
)
# 变形后形状: (B, C, k_up^2, σH, σW)
# 将归一化后的核 `normalized_kernels` 的维度进行扩展,以匹配邻域特征
# 从 (B, k_up^2, σH, σW) -> (B, 1, k_up^2, σH, σW)
normalized_kernels = normalized_kernels.unsqueeze(1)
# 关键一步:执行加权求和
# (B, C, k_up^2, σH, σW) * (B, 1, k_up^2, σH, σW) -> 逐元素相乘
# 然后在 k_up^2 维度上求和
output = torch.sum(unfolded_x_resampled * normalized_kernels, dim=2)
# 输出形状: (B, C, σH, σW)
return output
— 使用示例 —
if name == ‘main’:
# 创建一个模拟的输入特征图
# B=2, C=256, H=32, W=32
input_tensor = torch.randn(2, 256, 32, 32)
# 初始化 CARAFE 模块
# 上采样因子 σ=2, 重组核 k_up=5, 内容编码器核 k_encoder=3
carafe_upsampler = CARAFE(in_channels=256, out_channels=256, up_factor=2, up_kernel_size=5, kernel_size=3)
print("CARAFE 模块结构:")
print(carafe_upsampler)
# 执行上采样
output_tensor = carafe_upsampler(input_tensor)
# 打印输入和输出的形状
print(f"\n输入张量形状: {input_tensor.shape}")
print(f"输出张量形状: {output_tensor.shape}") # 应该是 (2, 256, 64, 64)
# 检查输出形状是否正确
expected_shape = (2, 256, 32 * 2, 32 * 2)
assert output_tensor.shape == expected_shape, f"形状不匹配! 期望 {expected_shape}, 得到 {output_tensor.shape}"
print("\nCARAFE 上采样成功! ✅")
3.2 逐行代码解析
这份代码完美地复现了 CARAFE 的两个核心模块。让我们来逐一解析。
3.2.1 __init__ 初始化函数
self.channel_compressor: 一个nn.Conv2d层,kernel_size=1。它负责将输入的in_channels压缩到固定的compressed_channels(论文建议64),实现了计算成本与输入通道数的解耦。self.content_encoder: 这是实现“内容感知”和“大感受野”的核心。它是一个标准的nn.Conv2d,卷积核大小为kernel_size(k_encoder)。它的输出通道数被精确地设计为self.up_factor * self.up_factor * self.up_kernel_size * self.up_kernel_size(σ² * k_up²)。padding参数确保了卷积后特征图的空间尺寸不变。self.pixel_shuffler: 这里我们巧妙地使用了nn.PixelShuffle来实现高效的空间重塑。PixelShuffle的标准用法是将(B, C*r*r, H, W)变为(B, C, H*r, W*r)。在这里,我们把它看作是将(B, (k_up²)*σ², H, W)变为(B, k_up², σH, σW),完美地为输出特征图的每个位置准备好了k_up²维的核向量。self.softmax: 用于对重组核进行归一化。dim=1表示沿着k_up²这个维度操作。
3.2.2 forward 前向传播函数
这部分是 CARAFE 真正工作的地方,逻辑非常清晰:
-
核预测路径:
compressed_x = self.channel_compressor(x): 执行通道压缩。encoded_kernels = self.content_encoder(compressed_x): 生成编码后的核。reshaped_kernels = self.pixel_shuffler(encoded_kernels): 空间重塑,得到(B, k_up², σH, σW)的张量。normalized_kernels = self.softmax(reshaped_kernels): 归一化,得到最终的重组核W'。
-
特征重组路径:
unfolded_x = F.unfold(...): 这是最高效的提取邻域(Patches)的方式。unfold函数会滑动一个up_kernel_size × up_kernel_size的窗口,将每个窗口内的内容拉成一个列向量。最终输出一个(B, C * k_up², H * W)维张量。unfolded_x.view(...): 我们将unfold的结果重塑成(B, C, k_up², H, W),这样物理意义更清晰:对于每个像素点,我们都有一个C × k_up²的矩阵,代表其邻域信息。F.interpolate(..., mode='nearest'): 这是一个关键的技巧。为了让(H, W)尺寸的邻域信息能够与(σH, σW)尺寸的重组核对齐,我们用最简单的最近邻插值将邻域信息张量“放大”σ倍。这相当于说,在原始H × W图像中(i,j)位置提取的邻域,将用于指导其对应的σ × σ输出区域的重组。torch.sum(unfolded_x_resampled * normalized_kernels, dim=2): 这是最后也是最核心的计算。通过广播机制,normalized_kernels(形状(B, 1, k_up², σH, σW)) 会与unfolded_x_resampled(形状(B, C, k_up², σH, σW)) 进行逐元素相乘,然后沿着dim=2(即k_up²维度)求和。这完美地实现了我们之前描述的加权求和公式,得到了最终的输出!
3.3 如何在你的网络中使用 CARAFE?
在你的模型中(比如 FPN 结构),替换掉原来的上采样层非常简单:
# 传统的上采样方式
# self.upsample = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=False)
使用 CARAFE 替换
假设 FPN 的特征通道数为 256
fpn_channels = 256
self.upsample = CARAFE(in_channels=fpn_channels, out_channels=fpn_channels, up_factor=2)
在 forward 函数中直接调用
lat_feat = self.lat_conv(p5_feat)
top_down_feat = self.upsample(lat_feat)
就是这么简单!你可以像使用任何一个标准的 nn.Module 一样使用 CARAFE。👍
四、实验与性能分析
CARAFE 的设计如此优雅,那么它的实际效果如何呢?原论文在多个主流的密集预测任务上进行了详尽的实验,结果令人振奋。
4.1 在目标检测任务上的表现
在标准的 COCO 目标检测任务中,研究者将 FPN (Feature Pyramid Network) 中的上采样层(默认为最近邻插值)替换为 CARAFE。
实验设置:基于 Faster R-CNN with FPN 架构,骨干网络为 ResNet-50。
| 上采样方法 | AP | AP50 | AP75 | APS | APM | APL |
|---|---|---|---|---|---|---|
| Nearest Neighbor | 36.5 | 58.3 | 39.2 | 20.1 | 40.0 | 48.7 |
| Bilinear Interpolation | 36.6 | 58.3 | 39.4 | 20.2 | 40.1 | 49.0 |
| Deconvolution | 36.7 | 58.5 | 39.5 | 20.3 | 40.2 | 49.1 |
| CARAFE (kup=5) | 37.5 | 59.3 | 40.5 | 21.0 | 41.2 | 50.1 |
结果分析: 从上表可以清晰地看到,仅仅是将上采样算子替换为 CARAFE,就在几乎所有指标上带来了显著的提升。AP (平均精度) 提升了整整 1.0个点!尤其是在要求更严格的 AP75 和对中大目标的检测上,提升更为明显。这充分证明了内容感知的上采样对于生成高质量的特征金字塔至关重要。
4.2 在实例分割任务上的表现
实例分割任务对特征图的质量要求更高。研究者在 Mask R-CNN 架构上进行了同样的替换实验。
实验设置:基于 Mask R-CNN with FPN 架构,骨干网络为 ResNet-101。
| 上采样方法 | APmask | APmask50 | APmask75 |
|---|---|---|---|
| Nearest Neighbor | 34.9 | 56.6 | 37.0 |
| CARAFE (kup=5) | 36.2 | 58.3 | 38.6 |
结果分析: 在实例分割任务上,CARAFE 带来的提升更加惊人,掩码 AP (APmask) 提升了 1.3个点。这说明 CARAFE 生成的特征图保留了更精细的空间细节,这对于准确勾勒出物体的轮廓至关重要。
4.3 消融实验分析
为了验证 CARAFE 设计的合理性,论文还进行了一系列消融研究:
- 重组核大小 (kup):实验表明,
k_up从 3 增加到 7,性能会持续提升,但k_up=5是一个很好的性能和效率的平衡点。 - 内容编码器核大小 (kencoder):
k_encoder越大,意味着预测重组核时能看到的感受野越大。实验发现,从1x1增加到3x3会有明显提升,但继续增大的收益递减。 - 通道压缩:实验证明,使用通道压缩(将通道数降至64)与不使用压缩相比,性能几乎没有损失,但参数量和计算量大大降低。这证明了通道压缩设计的有效性。
这些实验有力地证明了 CARAFE 不仅效果好,而且其内部的各个组件设计都是合理且高效的。
五、CARAFE 的优势与思考
5.1 CARAFE 的核心优势
- 巨大的感受野:与插值法(2x2)和反卷积(通常为3x3)相比,CARAFE 的感受野由
k_encoder和k_up共同决定。它能够在预测重组核时看到k_encoder的范围,并在重组时利用k_up的邻域,从而有效地利用了上下文信息。 - 内容感知:这是 CARAFE 最核心的亮点。它为每个位置动态生成独特的重组核,使得上采样过程能够适应特征的局部语义信息,智能地决定如何组合邻域像素。
- 轻量级且高效:由于通道压缩器的设计,CARAFE 的参数量和计算量都非常小,可以轻松地集成到现有网络中,而不会成为性能瓶颈。
- 通用性:CARAFE 是一个普适性的上采样算子,可以无缝替换任何网络结构中的上采样层,并在各种密集预测任务中带来性能提升。
5.2 潜在的局限性
尽管 CARAFE 非常优秀,但我们也要辩证地看待它。与简单的双线性插值相比,CARAFE 毕竟引入了额外的卷积计算和 unfold 操作,其计算延迟(Latency)会略高一些。在对推理速度要求极为苛刻的移动端或边缘设备上,这种微小的延迟差异可能也需要被纳入考量。
5.3 与其他上采样方法的比较
让我们用一个表格来清晰地总结一下:
| 特性 | 最近邻/双线性插值 | 反卷积 (Deconvolution) | 亚像素卷积 (PixelShuffle) | CARAFE |
|---|---|---|---|---|
| 感受野 | 极小 (1x1 / 2x2) | 较小 (kernel_size) | 较小 | 大 (可配置) |
| 内容感知 | 否 | 否 (核是全局共享的) | 否 | 是 (核是动态预测的) |
| 参数量 | 0 | 中等 | 中等 | 极小 (得益于通道压缩) |
| 棋盘格伪影 | 有 (最近邻) | 常见 | 较少 | 无 |
| 灵活性 | 低 | 中 | 中 | 高 (可调控核大小) |
六、总结与展望
今天,我们从上采样问题的根源出发,详细剖析了传统方法的不足,并在此基础上,深入探索了 CARAFE 的设计思想、架构实现、代码细节和实验性能。
CARAFE 以其“动态预测重组核,内容感知做聚合”的核心思想,为我们提供了一个近乎理想的上采样解决方案。它完美地平衡了性能、计算开销和通用性,证明了在神经网络设计中,对基础算子的精巧改进同样能带来巨大的回报。
CARAFE 的成功也启发我们,在未来的模型设计中,我们应该更多地思考如何让网络操作变得更加“动态”和“内容感知”。从动态卷积到我们今天讨论的动态上采样,这条路充满了无限的可能性。
希望通过今天的分享,大家对 CARAFE 有了全面而深刻的理解。它不仅仅是一个上采样算子,更是一种优雅的设计哲学的体现。感谢大家的阅读!我们下期再见!👋
下期预告:精彩继续 ✨
下一期第14节内容:SEPC自增强金字塔卷积
在探索了如何优化 FPN 中的“连接”(上采样)之后,我们下一期的目光将转向 FPN 的“节点”本身——即每个金字塔层级的特征表示能力。
我们将深入探讨 SEPC (Self-Enhancing Pyramid Convolution),一种旨在从根本上增强 FPN 特征表达能力的创新卷积模块。SEPC 的独特之处在于,它不仅仅是简单的堆叠卷积,而是通过一种巧妙的 自增强机制,在单个卷积模块内部就实现了多尺度的信息融合与提炼。
我们将一起揭开 SEPC 的神秘面纱:
- 它是如何通过金字塔卷积在不同尺度上捕捉特征的?
- 独特的自增强机制是如何工作的?它如何让特征图自己“学会”优化?
- 相比于标准的 3x3 卷积,SEPC 能为目标检测带来多大的提升?
如果你对如何设计更强大的卷积模块,进一步压榨 FPN 的性能极限感兴趣,那么下一期的内容,你绝对不容错过!敬请期待!😉
希望本文所提供的YOLOv8内容能够帮助到你,特别是在模型精度提升和推理速度优化方面。
-End-
