
YOLOv8【特征融合Neck篇·第14节】一文搞懂,SEPC自增强金字塔卷积!


专栏回顾:温故而知新
哈喽,各位亲爱的读者们,大家好!👋 在上一期《YOLOv8【特征融合Neck篇·第13节】一文弄懂,CARAFE上采样特征重组!》的探索中,我们一起深入研究了计算机视觉领域中一个轻量级且极为高效的通用上采样算子——CARAFE (Content-Aware ReAssembly of FEatures)。
我们首先回顾了传统上采样方法(如双线性插值、反卷积)的固有缺陷:它们要么是内容无关(Content-Agnostic)的,无法根据特征的语义信息进行自适应调整;要么是计算开销大,或容易产生棋盘格伪影。这些问题限制了FPN等架构中特征信息流动的质量。
CARAFE 的出现,为我们提供了一种全新的、优雅的解决方案。它的核心思想可以概括为两步:
- 动态预测重组核(Kernel Prediction):CARAFE 不再使用一个全局固定的上采样核,而是为输出特征图的每一个位置,根据其在输入特征图上对应邻域的内容,动态地生成一个独一无二的
k_up × k_up重组核。这个过程通过一个轻量级的“上采样核预测模块”实现,该模块包含通道压缩和内容编码,确保了其高效性。 - 内容感知特征重组(Content-Aware Reassembly):在得到每个位置的专属重组核之后,CARAFE 利用这个核,对输入特征图对应邻域内的特征进行加权求和,从而“重组”出最终的上采样结果。
我们还一起从零开始用 PyTorch 实现了 CARAFE,并剖析了其代码细节,特别是如何巧妙利用 F.unfold 和广播机制高效地实现加权求和。实验结果也雄辩地证明,无论是目标检测还是实例分割,CARAFE 都能在几乎不增加计算负担的情况下,带来显著的性能提升。
总而言之,CARAFE 优化了 FPN 中特征融合的“连接路径”(即上采样过程)。它告诉我们,高质量的信息传递,应该是智能的、内容感知的。
那么,既然“连接路径”已经升级,我们自然会思考:FPN 的“节点”(即每个层级的特征图本身)是否也能变得更强呢?今天,我们将要介绍的 SEPC,正是为了回答这个问题而来!准备好了吗?让我们进入自增强金字塔卷积的世界!✨
摘要:
在现代目标检测器中,特征金字塔网络(FPN)已成为融合多尺度特征的标准范式。然而,FPN及其变体大多关注于优化不同层级特征之间的“连接与融合”拓扑结构,却忽略了构成FPN“节点”的卷积操作本身。标准的3x3卷积在处理尺度剧烈变化的目标时,其固定、单一的感受野往往显得力不从心。本文将深入剖析一种专为增强FPN特征表达而设计的强大卷积模块——SEPC(Self-Enhancing Pyramid Convolution)。我们将从其两大核心组件——金字塔卷积(PConv)和自增强模块(SE)入手,探讨SEPC如何在一个统一的模块内实现多尺度特征提取与自适应校准,从而显著提升特征的表征能力和任务对齐性。文章还将提供详尽的PyTorch实现代码与解析,并通过实验结果展示SEPC在目标检测任务上的卓越性能。
一、引言:FPN的“阿喀琉斯之踵”
大家好!今天我们来聊一个在目标检测领域“老生常谈”却又总有新花样的话题——特征金字塔网络(FPN)。
1.1 FPN的成功与瓶颈
自从FPN横空出世,通过其经典的“自顶向下与横向连接”结构,优雅地解决了深度网络中高层语义信息与底层空间细节的融合问题,它就迅速成为了现代目标检测器的标配。随后的PANet、BiFPN、NAS-FPN等工作,都在FPN的基础上,探索了更高效的特征融合路径和拓扑结构。
这些改进无疑是成功的,它们通过设计更复杂的双向路径、引入可学习的权重来控制信息流,进一步提升了检测性能。然而,这些工作都有一个共同的焦点:优化金字塔层级之间的“连接”。
但是,我们似乎忽略了一个根本性的问题:构成FPN的每一个“节点”(即每个金字塔层级上用于处理和提炼特征的模块)本身,是否足够强大?
在大多数FPN的实现中,用于Neck和Head的特征处理单元,通常是朴素的 3x3 卷积层。这就引出了一个关键问题。
1.2 标准卷积的“尺度局限性”
一个标准的 3x3 卷积,其感受野是固定且有限的。当它处理一张包含各种尺寸目标的图像时,问题就来了:
- 对于大目标:
3x3的感受野太小,只能“管中窥豹”,无法捕捉到目标的全局结构信息。 - 对于小目标:
3x3的感受野可能又相对过大,容易引入过多的背景噪声,干扰对小目标的识别。
虽然堆叠多个 3x3 卷积可以扩大感受野,但这是一种“静态”的扩大方式。网络一旦训练完成,其感受野的结构就固定了。它无法根据当前处理的特征内容,动态地调整其关注的尺度范围。
此外,检测任务包含分类和回归两个子任务。分类任务更关注目标的显著特征(需要较大的感受野),而回归(定位)任务则更关注目标的边缘和细节(需要较小的感受野)。一个单一的 3x3 卷积很难同时完美地服务于这两个相互冲突的需求。这就是所谓的 任务不对齐(Task Misalignment) 问题。
1.3 SEPC的破局之道:强化“节点”而非“连接”
SEPC (Self-Enhancing Pyramid Convolution) 的作者们另辟蹊径,他们认为,与其继续在“连接”上做文章,不如从“根”上解决问题——设计一个更强大的、具备多尺度感知能力的卷积单元,替换掉FPN中那些朴素的卷积层。
SEPC的核心思想是:在一个卷积模块内部,就完成多尺度信息的提取、融合与校准。它不再是一个被动的信息处理器,而是一个能够“自我增强”的主动学习单元。
接下来,就让我们一起揭开SEPC的神秘面纱,看看它是如何通过“金字塔卷积”和“自增强”两大杀手锏,来炼就更强大的特征表达的!🤩
二、SEPC核心原理深度剖析
SEPC的设计充满了“分而治之”与“统筹兼顾”的哲学智慧。它将复杂的特征增强任务分解为两个简单而高效的步骤,分别由两个核心组件完成:PConv 和 SE。
2.1 核心思想:分离与增强
- 分离(多尺度特征提取):首先,使用不同大小和空洞率的卷积核并行地处理输入特征,从不同的“视角”和“尺度”上提取信息。这一步由 PConv (Pyramid Convolution) 完成。
- 增强(特征校准):然后,将从不同尺度提取到的特征进行智能融合,并根据特征内容自适应地对融合后的结果进行“校准”和“增强”,使其对当前任务更有利。这一步由 SE (Self-Enhancing) 模块 完成。
下面,我们来逐一拆解这两个组件。
2.2 组件一:PConv (金字塔卷积) - 捕获多尺度信息
PConv是SEPC实现多尺度感知的基础。它的想法非常直观:既然单一尺寸的卷积核有局限,那我们为什么不同时使用多个不同尺寸的卷积核呢?
2.2.1 PConv的结构设计
PConv由多个并行的卷积分支组成。每个分支都是一个带有不同空洞率(Dilation Rate)的深度可分离卷积(Depth-wise Separable Convolution),以在扩大感受野的同时保持较低的计算成本。
一个典型的PConv结构如下:
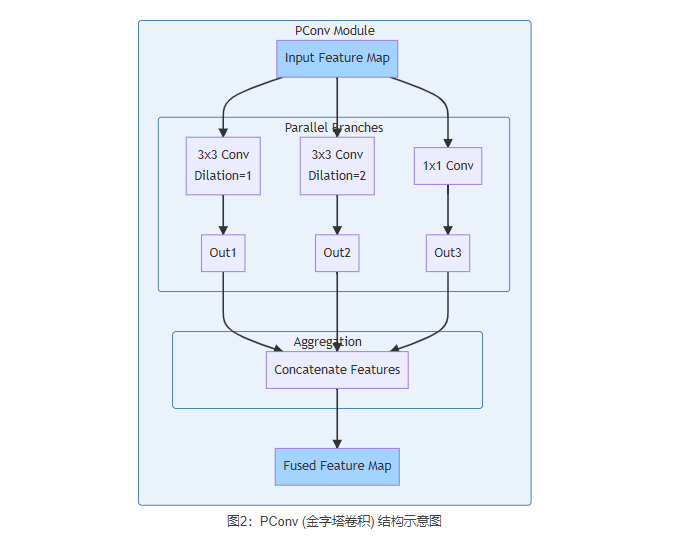
图2:PConv (金字塔卷积) 结构示意图
工作流程:
-
输入特征
X被同时送入多个平行的卷积分支。 -
多分支卷积:
- 分支一:使用一个标准的
3x3卷积(空洞率为1),捕捉局部细节信息。 - 分支二:使用一个
3x3的空洞卷积(例如,空洞率为2),在不增加参数的情况下,获得更大的感受野,捕捉更广阔的上下文。 - 分支三:使用一个
1x1卷积,进行通道维度的信息交互和提炼。 - (在实际应用中,可以设计更多的分支,比如更大空洞率的卷积或不同尺寸的卷积核)
- 分支一:使用一个标准的
-
特征拼接:将所有分支的输出特征图在通道维度上进行拼接(Concatenate)。
-
输出:得到一个包含了多种尺度信息的、通道数更丰富的融合特征图。
2.2.2 不同尺度卷积核的作用
PConv的设计,使得单个模块就拥有了类似“空间金字塔池化 (SPP)”的能力,但它比SPP更灵活,因为它是以卷积的方式实现的。
- 小感受野分支 (e.g., 3x3, dilation=1):擅长捕捉目标的精细轮廓、纹理和边缘信息,这对于 精确定位(回归) 至关重要。
- 大感受野分支 (e.g., 3x3, dilation=2):擅长捕捉目标的整体结构和周围的上下文信息,这对于准确分类至关重要。
- 1x1 卷积分支:作为一种“点态”的感受野,它专注于通道间的线性组合,可以看作是对特征的再加权和提炼。
通过PConv,网络不再需要“赌”哪种尺寸的感受野是最好的,而是“全都要”!它将不同尺度的信息并行提取出来,为下一步的智能融合做好了准备。
2.3 组件二:SE (自增强模块) - 实现特征校准
PConv虽然提取了多尺度信息,但它只是简单地将这些信息拼接在一起。这些信息中,哪些是重要的?哪些是次要的?如何将它们最好地组合起来以适应当前的任务?这就是SE模块要解决的问题。
2.3.1 SE模块的工作流程
SE模块借鉴了SENet(Squeeze-and-Excitation Network)的思想,但做出了关键的调整,使其更适合于特征融合与校准。
graph TD
subgraph SE Module
Input_PConv[Input from PConv] --> PointwiseConv1[1x1 Conv (Fusion)];
PointwiseConv1 --> GlobalAvgPool["Global Average Pooling<br>(Squeeze)"];
GlobalAvgPool --> FC1["Fully Connected Layer<br>(Bottleneck)"];
FC1 --> ReLU;
ReLU --> FC2["Fully Connected Layer<br>(Expansion)"];
FC2 --> Sigmoid;
Sigmoid --> AttentionWeights[Channel-wise Weights];
PointwiseConv1 --> ElementwiseMul["Element-wise Multiplication<br>(Excitation/Calibration)"];
AttentionWeights --> ElementwiseMul;
ElementwiseMul --> Output[Enhanced Feature Map];
end
style Input_PConv fill:#bde0fe
style Output fill:#bde0fe
图3:SE (自增强) 模块工作流程图
工作流程:
- 融合(Fusion):首先,使用一个
1x1卷积将PConv输出的拼接特征进行融合,将其通道数恢复到期望的输出通道数(例如256)。这一步本身就是一次信息整合。 - 压缩(Squeeze):对融合后的特征图
U进行全局平均池化(Global Average Pooling),将其每个通道的空间信息压缩成一个单一的数值。这得到一个1 x 1 x C的通道描述符,它具有全局的感受野。 - 激励(Excitation):将这个通道描述符送入一个两层的全连接网络(一个降维的FC层,一个ReLU激活,一个升维的FC层)。这个“瓶颈”结构学习了通道之间的非线性依赖关系。
- 生成权重:最后,通过一个
Sigmoid激活函数,生成一组范围在0到1之间的、与通道数相同的权重s。这组权重代表了每个通道的“重要性”或“激活度”。 - 校准(Calibration):将这组权重
s逐通道地乘回到第一步融合后的特征图U上。这个过程就相当于根据全局信息,动态地、自适应地增强那些有用的特征通道,抑制那些无用的特征通道。
2.3.2 与SENet的联系与区别
- 联系:核心思想都源于“Squeeze-and-Excitation”,即利用全局信息来学习通道注意力。
- 区别:在经典的SENet中,SE模块通常被插入到ResNet的Bottleneck结构中,用于校准单个卷积的输出。而在SEPC中,SE模块的输入是PConv产生的多尺度融合特征。因此,这里的SE模块扮演的角色更像是对“多尺度信息融合”这一过程进行智能调控和校准,其作用域和意义更加丰富。它学习的是“如何最好地组合不同感受野提取出的信息”。
2.4 强强联合:完整的SEPC模块
将PConv和SE模块组合在一起,就构成了完整的SEPC模块。
SEPC = PConv + 1x1 Fusion Conv + SE Attention
整个流程可以总结为:
- 输入特征 X
- 并行多尺度提取:通过PConv的多个分支,得到
[F_1, F_2, ..., F_n] - 拼接:
F_cat = Concat(F_1, F_2, ..., F_n) - 融合:
F_fused = Conv_1x1(F_cat) - 自适应校准:
F_out = SE(F_fused)
至此,SEPC模块就完成了一次高质量的、内容自适应的、多尺度感知的特征提取与增强。是不是非常巧妙呢?🎉
三、SEPC在检测器中的应用
SEPC的设计初衷就是为了强化FPN,因此它的应用方式也非常直接和彻底。
3.1 “侵入式”替换策略
不同于那些只在FPN某个位置添加新模块的“小修小补”,SEPC采取的是一种“全面升级”的策略。作者建议,将目标检测器中Neck部分(如FPN)和Head部分(用于分类和回归的分支)的所有卷积层,全部替换为SEPC模块。
这种“侵入式”的应用方式,保证了从特征融合到最终预测的整个信息流,都能享受到SEPC带来的多尺度感知和自增强能力。
3.2 统一Neck和Head的特征提取
一个有趣的设计是,SEPC在Neck和Head中是共享权重的。这意味着,用于在FPN中融合特征的SEPC模块,和用于在Head中进行分类/回归预测的SEPC模块,是同一个模块(或者说它们的参数是共享的)。
这么做有几个好处:
- 减少参数量:避免了为Neck和Head分别设计和训练两套独立的卷积模块。
- 隐式深度监督:Head中的任务损失(分类损失和回归损失)可以通过共享的权重,直接反向传播和监督Neck中特征的提取过程,使得Neck学习到的特征表示对最终的任务更加友好。
- 促进任务对齐:因为同一个SEPC模块既要负责融合特征,又要负责最终的预测,它会被“逼着”去学习一种对分类和回归都更有利的通用特征表示。
3.3 提升任务对齐性(Task Alignment)
我们之前提到,分类任务和回归任务对特征的需求不同。SEPC通过其内在机制,很好地缓解了这个问题:
- PConv并行提取了适合定位的细节特征(小感受野分支)和适合分类的语义特征(大感受野分支)。
- SE模块则根据输入内容,动态地调整这些特征的权重。当处理一个需要精确定位的区域时,它可能会给小感受野分支的特征赋予更高的权重;而当处理一个需要准确分类的区域时,大感受野分支的特征可能会被增强。
这种自适应的特性,使得SEPC能够生成对两个子任务都更加“公平”和“有效”的特征,从而提升了整体的检测性能。
四、PyTorch从零实现与代码解析
理论的精髓,最终要落实到代码上。💻 让我们一起来实现SEPC模块,感受其设计的魅力。我们将分步实现PConv和SEPC。
4.1 PConv (金字塔卷积) 模块实现
import torch
import torch.nn as nn
class PConv(nn.Module):
def init(self,
in_channels, # 输入通道数
out_channels, # 输出通道数
kernel_sizes=[3, 3, 3], # 各分支卷积核大小
dilations=[1, 2, 3]): # 各分支空洞率
"""
PConv (Pyramid Convolution) 模块
Args:
in_channels (int): 输入特征图的通道数
out_channels (int): 每个分支输出的通道数
kernel_sizes (list of int): 每个分支的卷积核大小
dilations (list of int): 每个分支的空洞率
"""
super(PConv, self).init()
self.in_channels = in_channels
self.out_channels = out_channels
self.kernel_sizes = kernel_sizes
self.dilations = dilations
# 分支数必须与卷积核列表和空洞率列表的长度一致
self.num_branches = len(kernel_sizes)
assert self.num_branches == len(dilations)
# 创建多个并行的深度可分离卷积分支
self.branches = nn.ModuleList()
for i in range(self.num_branches):
# 为了保持计算效率,使用深度可分离卷积
# 它由一个深度卷积 (depthwise conv) 和一个逐点卷积 (pointwise conv) 组成
branch = nn.Sequential(
# 深度卷积:每个输入通道对应一个卷积核,不改变通道数
nn.Conv2d(
in_channels,
in_channels,
kernel_size=kernel_sizes[i],
padding=kernel_sizes[i] // 2 * dilations[i], # 关键:计算padding以保持分辨率
dilation=dilations[i],
groups=in_channels # groups=in_channels 即为深度卷积
),
nn.BatchNorm2d(in_channels),
nn.ReLU(inplace=True),
# 逐点卷积:1x1卷积,用于融合通道信息和调整通道数
nn.Conv2d(
in_channels,
out_channels,
kernel_size=1
),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
)
self.branches.append(branch)
def forward(self, x):
"""
PConv 的前向传播
Args:
x (Tensor): 输入特征图,形状 (B, C_in, H, W)
Returns:
Tensor: 拼接后的输出特征图,形状 (B, C_out * num_branches, H, W)
"""
# 对每个分支进行前向传播
branch_outputs = [branch(x) for branch in self.branches]
# 在通道维度上拼接所有分支的输出
return torch.cat(branch_outputs, 1)
4.2 完整的SEPC模块实现
class SEPC(nn.Module):
def __init__(self,
in_channels, # 输入通道数
out_channels, # 最终输出通道数
pconv_inter_channels=64, # PConv每个分支的中间输出通道数
kernel_sizes=[3, 3, 3], # PConv卷积核大小
dilations=[1, 2, 3], # PConv空洞率
se_ratio=16): # SE模块中FC层的压缩率
"""
SEPC (Self-Enhancing Pyramid Convolution) 模块
Args:
in_channels (int): 输入特征图的通道数
out_channels (int): 最终输出的通道数
pconv_inter_channels (int): PConv每个分支输出的通道数
kernel_sizes (list of int): 传递给PConv的卷积核大小
dilations (list of int): 传递给PConv的空洞率
se_ratio (int): SE模块瓶颈结构的压缩率
"""
super(SEPC, self).__init__()
# 1. PConv 模块
self.pconv = PConv(
in_channels=in_channels,
out_channels=pconv_inter_channels,
kernel_sizes=kernel_sizes,
dilations=dilations
)
# PConv 输出的总通道数
pconv_out_channels = pconv_inter_channels * len(kernel_sizes)
# 2. 1x1 卷积用于融合 PConv 的输出
self.fusion_conv = nn.Sequential(
nn.Conv2d(pconv_out_channels, out_channels, kernel_size=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
# 3. SE (自增强) 模块
# Squeeze-and-Excitation 结构
self.se_module = nn.Sequential(
# 全局平均池化 (Squeeze)
nn.AdaptiveAvgPool2d(1),
# 全连接层 (Excitation)
nn.Conv2d(out_channels, out_channels // se_ratio, kernel_size=1), # 使用1x1 Conv代替FC层
nn.ReLU(inplace=True),
nn.Conv2d(out_channels // se_ratio, out_channels, kernel_size=1),
nn.Sigmoid()
)
def forward(self, x):
"""
SEPC 的前向传播
Args:
x (Tensor): 输入特征图, 形状 (B, C_in, H, W)
Returns:
Tensor: 增强后的输出特征图, 形状 (B, C_out, H, W)
"""
# 1. 通过 PConv 提取多尺度特征
pconv_out = self.pconv(x)
# 2. 融合多尺度特征
fused_features = self.fusion_conv(pconv_out)
# 3. 通过 SE 模块计算通道注意力权重
# 形状: (B, C_out, 1, 1)
attention_weights = self.se_module(fused_features)
# 4. 将权重应用到融合后的特征上 (校准)
# 利用广播机制进行逐通道相乘
enhanced_features = fused_features * attention_weights
return enhanced_features
— 使用示例 —
if name == ‘main’:
# 模拟输入,通常FPN的特征通道数为256
# B=4, C=256, H=64, W=64
input_tensor = torch.randn(4, 256, 64, 64)
# 初始化 SEPC 模块
# 输出通道数也为 256
sepc_block = SEPC(in_channels=256, out_channels=256)
print("SEPC 模块结构:")
print(sepc_block)
# 执行前向传播
output_tensor = sepc_block(input_tensor)
# 打印输入和输出的形状
print(f"\n输入张量形状: {input_tensor.shape}")
print(f"输出张量形状: {output_tensor.shape}") # 应该保持 (4, 256, 64, 64)
# 检查输出形状是否正确
assert input_tensor.shape == output_tensor.shape, "输出形状与输入形状不匹配!"
print("\nSEPC 模块运行成功! ✅")
4.3 代码逐行解析
4.3.1 PConv 初始化与前向传播
-
__init__:-
self.branches = nn.ModuleList(): 使用ModuleList来存储多个并行的卷积分支,这是PyTorch中管理多个子模块的标准做法。 -
深度可分离卷积:为了控制参数量,每个分支内部都采用了深度可分离卷积。
nn.Conv2d(..., groups=in_channels): 这是实现深度卷积(depthwise convolution)的关键。groups参数将输入通道分成多个组,当groups等于in_channels时,每个输入通道都有自己独立的卷积核,只处理自己的空间信息,不与其他通道混合。padding = kernel_size // 2 * dilation: 这是一个至关重要的计算。对于空洞卷积,为了保持卷积后的特征图尺寸不变,padding的大小需要与dilationrate 相乘。这个公式保证了无论空洞率是多少,特征图的分辨率都能得以维持。nn.Conv2d(..., kernel_size=1): 这是逐点卷积(pointwise convolution),它负责融合深度卷积处理后的通道信息,并可以调整通道数到out_channels。
-
-
forward:branch_outputs = [branch(x) for branch in self.branches]: 利用列表推导式,简洁地完成了对所有分支的并行计算。torch.cat(branch_outputs, 1): 核心操作,dim=1表示在通道维度上进行拼接,将所有分支的结果汇集到一起。
4.3.2 SEPC 初始化与前向传播
-
__init__:-
self.pconv = PConv(...): 直接实例化我们刚刚定义的PConv模块作为第一个处理阶段。 -
self.fusion_conv = nn.Sequential(...): 定义一个1x1的卷积层,用于将PConv拼接后的多通道特征融合,并降维到最终需要的out_channels。 -
self.se_module = nn.Sequential(...): 定义了自增强模块。nn.AdaptiveAvgPool2d(1): 实现了全局平均池化,无论输入特征图H,W是多大,输出都是1x1。nn.Conv2d(...): 这里用1x1的卷积层来代替全连接层(FC),这是在处理2D特征图时的常见且高效的做法。一个C_in -> C_out的1x1卷积等效于一个作用在每个像素点上的FC层。nn.Sigmoid(): 将输出值压缩到0-1之间,生成归一化的注意力权重。
-
-
forward:pconv_out = self.pconv(x): 第一步,提取多尺度特征。fused_features = self.fusion_conv(pconv_out): 第二步,融合特征。attention_weights = self.se_module(fused_features): 第三步,根据融合后的内容计算注意力权重。enhanced_features = fused_features * attention_weights: 第四步,也是最关键的一步。利用PyTorch的广播机制,(B, C, H, W)的特征图与(B, C, 1, 1)的权重相乘,权重会自动扩展为(B, C, H, W),实现了对每个通道的独立加权,完成了特征校准。
4.4 如何在FPN Head中使用SEPC
假设你有一个标准的检测头,通常由4个 3x3 卷积层和一个最终的预测层组成。你可以这样用SEPC来替换它:
# 传统的检测头中的卷积堆叠
# convs = []
# for i in range(4):
# convs.append(nn.Conv2d(256, 256, kernel_size=3, padding=1))
# self.cls_convs = nn.ModuleList(convs)
# self.reg_convs = nn.ModuleList(convs) # 通常分类和回归分支结构相同
使用SEPC替换后的检测头
假设我们只需要一个SEPC模块,并重复使用它
在实际的论文实现中,可能会有更复杂的权重共享策略
self.shared_sepc = SEPC(in_channels=256, out_channels=256)
分类分支
cls_tower = []
for _ in range(4):
cls_tower.append(self.shared_sepc)
# 可能在每个SEPC后添加ReLU等
cls_tower.append(nn.ReLU(inplace=True))
self.cls_convs = nn.Sequential(*cls_tower)
回归分支(同样使用共享的SEPC)
reg_tower = []
for _ in range(4):
reg_tower.append(self.shared_sepc)
reg_tower.append(nn.ReLU(inplace=True))
self.reg_convs = nn.Sequential(*reg_tower)
在前向传播中
cls_feat = self.cls_convs(fpn_feat)
reg_feat = self.reg_convs(fpn_feat)
通过这种方式,你的检测头现在具备了强大的多尺度感知和自适应增强能力。👍
五、实验与性能分析
SEPC的强大效果在多个基准上得到了验证,尤其是在具有挑战性的COCO数据集上。
5.1 在COCO检测任务上的表现
研究者们在多种主流检测器(如RetinaNet, Mask R-CNN, Cascade R-CNN)上应用了SEPC,并与基线模型进行了对比。
实验设置:基于Cascade R-CNN + ResNet-50 的基线。
| 模型 | AP | AP50 | AP75 | APS | APM | APL |
|---|---|---|---|---|---|---|
| Baseline (Standard Conv) | 41.0 | 59.8 | 44.7 | 23.3 | 44.8 | 53.7 |
| Baseline + SEPC | 43.3 | 61.7 | 47.1 | 25.2 | 47.1 | 56.5 |
| 提升 | +2.3 | +1.9 | +2.4 | +1.9 | +2.3 | +2.8 |
结果分析:
- 显著的AP提升:仅仅通过将卷积替换为SEPC,模型的平均精度(AP)就提升了2.3个点!这是一个非常巨大的进步。
- 对各尺寸目标均有效:从对小目标(APS)、中目标(APM)到大目标(APL)的AP指标来看,SEPC都带来了全面的提升。特别是对 大目标的提升(+2.8) 尤为明显,这直接验证了PConv中大感受野分支的有效性。
- 定位精度提升:AP75(在IoU阈值为0.75时的精度,更考验定位能力)提升了2.4个点,说明SEPC生成的特征对于精确回归边界框也大有裨益。
5.2 消融实验:PConv和SE的贡献
为了搞清楚SEPC中每个组件的作用,作者进行了消融实验。
| 组件 | AP | 提升 |
|---|---|---|
| Baseline | 41.0 | - |
| Baseline + PConv | 42.4 | +1.4 |
| Baseline + PConv + SE (即SEPC) | 43.3 | +2.3 |
结果分析:
- PConv是性能提升的主力:单独使用PConv(即只进行多尺度特征提取和融合,但不进行自适应校准),就能带来1.4个点的AP提升。这证明了在特征提取阶段就融入多尺度信息是极其有效的。
- SE模块起到“画龙点睛”的作用:在PConv的基础上,再加入SE自增强模块,性能进一步提升了0.9个点。这说明,对融合后的多尺度特征进行智能的、内容感知的校准,能够进一步压榨出性能潜力。
这两个组件相辅相成,共同造就了SEPC的强大。
5.3 可视化分析
论文中的可视化热力图(Feature Map Visualization)也表明,相比于标准卷积,SEPC能够生成更集中、更完整的目标激活区域,并且能更好地抑制背景噪声,这为后续的分类和回归提供了更高质量的特征基础。
六、SEPC的优势与思考
6.1 SEPC的核心优势
- 内建的多尺度能力:通过PConv,SEPC将多尺度处理能力“内化”到了单个卷积模块中,从根本上解决了标准卷积感受野单一的问题。
- 自适应特征校准:通过SE模块,SEPC能够根据输入内容动态地调整各尺度特征的重要性,实现了对特征的智能增强和任务对齐。
- 强大的性能提升:作为一个即插即用的模块,SEPC能够稳定且显著地提升多种检测器的性能,尤其是在处理尺度变化较大的场景时。
- 统一的设计哲学:通过在Neck和Head中全面使用SEPC并共享权重,实现了端到端的、统一的、任务导向的特征学习。
6.2 潜在的计算开销考量
我们必须承认,相比于一个标准的 3x3 卷积,SEPC的结构更复杂,其参数量和计算量(FLOPs)都会更高。PConv的多个分支、SE模块的FC层都带来了额外的开销。
因此,在追求极致速度的轻量级模型或移动端应用中,需要在使用SEPC带来的高精度和其增加的计算成本之间做出权衡。然而,对于那些以精度为首要目标的场景,SEPC无疑是一个非常有吸引力的选择。
6.3 设计哲学:从“手工调参”到“自适应学习”
SEPC的设计,也反映了深度学习模型设计的一个重要趋势:减少需要人工设计和调整的组件(如感受野大小),转变为让网络自己去学习和适应的动态模块。网络不再是固定的信息处理器,而是一个能够根据数据进行自我优化的智能体。
七、总结与展望
今天,我们一起进行了一次深入的“FPN节点强化之旅”。我们了解到,除了优化FPN的连接拓扑,我们还可以通过设计更强大的卷积单元——SEPC,来从根本上提升特征金字塔的表达能力。
SEPC通过其两大核心组件——PConv和SE模块,巧妙地实现了多尺度特征提取与自适应内容增强的统一。它不仅解决了标准卷积的尺度局限性,还缓解了检测任务中的任务不对齐问题。详尽的代码实现和惊艳的实验结果,都证明了SEPC是一个设计优雅且效果卓越的模块。
SEPC的成功启发我们,在未来的检测器设计中,对基础算子(如卷积)的创新,依然是推动性能突破的关键驱动力。
感谢大家的阅读!希望今天的分享能为大家在改进自己的模型时,提供新的思路和灵感!我们下期再见!👋
下期预告:精彩继续
【第15节】RepGhost Ghost特征融合网络
在体验了SEPC这种通过“做加法”(增加模块复杂度)来换取高性能的设计之后,我们下一期的目光将转向一个完全不同的方向——网络的高效轻量化。
我们将要探索 RepGhost,一个旨在用更少的计算和参数,实现更高推理效率的特征融合网络。它创造性地结合了两种强大的轻量化技术:
- GhostNet:如何用廉价的线性变换来“幻化”出更多的特征图?
- RepVGG:如何通过“结构重参数化”技术,让模型在训练时拥有复杂的多分支结构(以提升性能),而在推理时却能等价转换为一个极简的单路结构(以实现极致加速)?
我们将一起揭开RepGhost的神秘面纱:
- GhostNet的核心思想是什么?它如何节省计算量?
- 什么是“结构重参数化”?它为什么能做到“训练和推理架构不一致”?
- RepGhost如何将这两者结合,应用在Neck设计中,实现轻量级与性能的完美平衡?
如果你对模型压缩、推理加速和部署优化充满兴趣,那么下一期的内容,你绝对不容错过!让我们一起见证“鱼与熊掌兼得”的魅力!敬请期待!😉
希望本文所提供的YOLOv8内容能够帮助到你,特别是在模型精度提升和推理速度优化方面。
-End-
