
2025 中国 AI 芯片产业发展全景报告:技术突围与生态崛起


一、产业全景:规模爆发与国产化加速
(一)市场规模与增长态势
全球 AI 芯片市场正经历爆发式增长,中国已成为核心增长引擎。根据德勤与硬派研选的联合数据,2023 年国内 AI 芯片市场规模达 553 亿元,复合年增长率高达 43.89%;预计 2025 年将突破 750 亿元,2030 年更是有望达到 3000 亿元,年复合增长率维持在 30% 以上。从全球格局看,中国市场份额已从 2024 年的 29% 跃升至 2025 年的 42%,销售额从 60 亿美元猛增至 160 亿美元,增速达 112%。
表 1:中国 AI 芯片市场规模预测(2025-2030)
年份 | 市场规模(亿元) | 增长率 | 核心驱动因素 |
2025 | 680-750 | 45% | 智算中心建设、5G 普及 |
2027 | 1200-1350 | 30%-35% | 智能汽车、智能制造爆发 |
2030 | 2500-3000 | 25%-30% | 边缘计算、具身智能普及 |
(二)产业链结构与地域分布
AI 芯片位于 AIGC 产业链上游,支撑中游算法开发与下游行业应用。从产业集聚看,形成了以上海(15 家)、北京(8 家)、广东(6 家)为核心的产业集群,合计占比超 60%,集中了华为海思、寒武纪、壁仞科技等头部企业,构建了人才、技术与资本的协同生态。
二、技术路线:多元创新与瓶颈突破
(一)主流技术路线全景
国内 AI 芯片形成了 GPU、ASIC、存算一体等多路线并行的格局,各类技术针对不同场景实现差异化突破:
- GPU 路线:聚焦云端大规模训练,壁仞科技 BR100、摩尔线程 MTT S5000 等产品实现突破,其中摩尔线程 MTT S5000 是国内首批实现 FP8 算力量产的 GPU,性能提升 30%。
- ASIC 路线:专用性优势显著,华为昇腾 910B、寒武纪 MLU370 等产品在算力密度与能效比上接近国际水平。
- 存算一体:打破冯・诺依曼瓶颈,知存科技、后摩智能通过近存计算与存内计算路径,实现能效数量级提升,已应用于端侧推理场景。
- Chiplet 技术:成为突破制程限制的关键,寒武纪 MLU370 首次采用 Chiplet 技术,集成 390 亿晶体管,算力较上一代翻倍。
图 1:国产 AI 芯片技术路线演进图谱
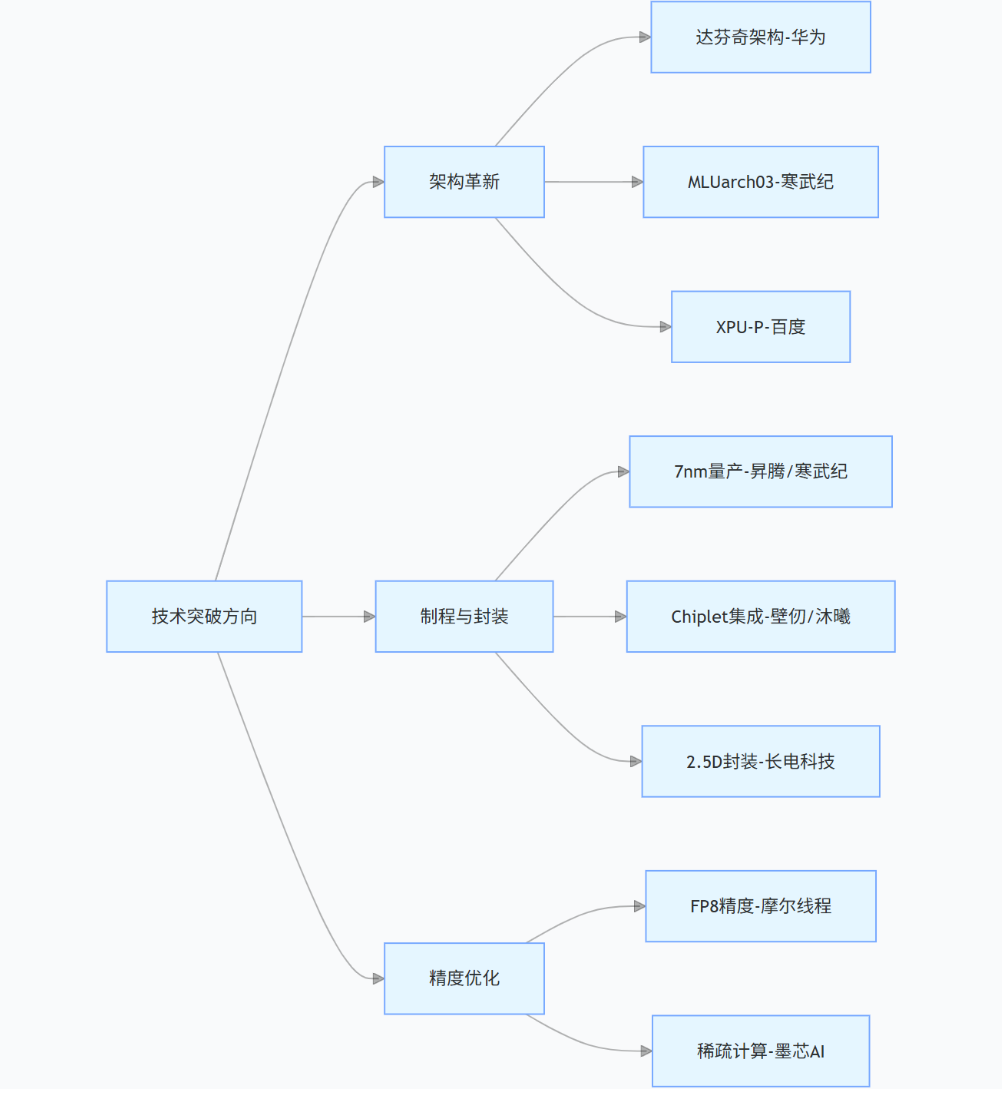
(二)核心技术参数对比
国产芯片在关键指标上已实现对英伟达中高端产品的追赶,部分参数甚至实现超越:
表 2:主流 AI 芯片核心参数对比(2025)
厂商 / 型号 | 制程 | 显存 | 带宽 | FP16 算力 | INT8 算力 | 功耗 | 应用场景 |
华为昇腾 910B | 7nm 改进 | 64GB HBM2e | 1.6TB/s | 320 TFLOPS | 640 TOPS | 400W | 大模型训练 |
寒武纪 MLU370 | 7nm | 64GB HBM2e | 1.2TB/s | 128 TFLOPS | 512 TOPS | 350W | 推理优化 |
阿里平头哥 PPU | 7nm | 96GB HBM2e | 700GB/s | 280 TFLOPS | 560 TOPS | 400W | 云边协同推理 |
英伟达 A100 | 7nm | 80GB HBM2e | 2.0TB/s | 312 TFLOPS | 1248 TOPS | 400W | 大模型训练 |
英伟达 H20 | 8nm | 96GB HBM3 | 800GB/s | 290 TFLOPS | 580 TOPS | 550W | 受限市场训练推理 |
数据来源:央视报道、CSDN 博客
(三)技术瓶颈与攻坚方向
尽管取得显著进展,产业仍面临三大核心挑战:
- EDA 工具制约:7nm 以上节点设计依赖 Synopsys/Cadence 工具,华大九天 Argus 在 7nm 规则库覆盖度仅 60%,导致寒武纪 3nm 级芯片研发停滞。
- 先进封装产能:2.5D/3D 封装产能不足,Chiplet 设计面临信号完整性分析误差增加 30% 的问题。
- 软件生态短板:工具链完善度不足,模型兼容性较英伟达 CUDA 生态存在差距,制约硬件性能释放。
三、企业格局:梯队竞争与生态构建
(一)第一梯队:全栈布局的行业龙头
- 华为海思:昇腾系列构建 “芯片 - 框架 - 应用” 全栈生态,昇腾 910B 已部署 300 多套 Cloud Matrix 超节点架构,支撑国内超算中心建设。2025 年其智算芯片市场份额达 18%,仅次于英伟达。
- 寒武纪:专注 AI 加速卡与终端处理器,思元 370-X8 双芯卡实测 ResNet-50 性能为同尺寸主流 GPU 的 2 倍,能效比领先 30%。目前已推出云边端全系列产品,2024 年营收同比增长 52%。
(二)第二梯队:场景驱动的特色玩家
- 阿里平头哥:PPU 芯片获央视曝光,96GB 显存、700GB/s 片间带宽超越英伟达 A800,已在中国联通三江源智算中心部署 16384 张算力卡,提供 1945P 算力。
- 地平线:聚焦智能驾驶,征程 6P 算力达 560TOPS,覆盖 L2 + 至 L4 级需求,已搭载小鹏、理想等车企新款车型,2025 年车规级芯片市占率突破 15%。
- 壁仞科技:BR100 系列在多地智算中心落地,支持千亿参数大模型训练,集群扩展性达万卡级别。
(三)第三梯队:技术突围的初创企业
沐曦股份、摩尔线程等专注 GPU 赛道,其中摩尔线程 MTT S5000 实现 FP8 量产,科创板 IPO 已过会;黑芝麻智能 A2000 在智能座舱场景实现规模化应用,算力达 200TOPS。
表 3:国产 AI 芯片企业梯队分布
梯队 | 代表企业 | 核心优势 | 代表产品 |
第一梯队 | 华为海思、寒武纪 | 全栈技术、生态完善 | 昇腾 910B、MLU370 |
第二梯队 | 平头哥、地平线 | 场景深度绑定、性价比高 | PPU、征程 6P |
第三梯队 | 摩尔线程、沐曦 | 技术创新、细分赛道突破 | MTT S5000 |
四、应用落地:四大场景的规模化突破
(一)智算中心:算力基建的核心载体
2024 年中国智能算力规模达 725.3EFLOPS,同比增长 74.1%,市场规模 190 亿美元。国产芯片加速替代,华为昇腾、昆仑芯等万卡级集群已落地,支持 LLM 训练与推理。典型案例包括:
- 中国联通三江源绿电智算中心:部署 22832 张国产算力卡,总算力 3479P,其中平头哥贡献 16384 张算力卡。
- DeepSeek 一体机:整合十大国产 AI 芯片,实现 “开箱即用” 的智算部署模式。
(二)智能驾驶:舱驾一体成主流
智能驾驶芯片向高算力、多任务方向演进,舱驾一体架构成为量产主流。地平线征程 6P(560TOPS)、华为昇腾 610(200TOPS)等产品覆盖 L2 + 至 L4 需求。调研显示,45% 从业者认为智能座舱芯片是最可能突破的领域。2025 年国内车载 AI 芯片市场规模预计突破 200 亿元,2030 年将达 500 亿元。
(三)机器人:物理 AI 的算力支撑
机器人从 “自动化工具” 向 “自主化伙伴” 转型,对芯片的低延迟、高能效需求迫切。全志科技 MR527 应用于小米 “铁蛋” 四足机器人,地平线 RDK S100 开发套件支持具身智能任务。但高端人形机器人所需的 200+TOPS 极致算力仍与国际存在代差。
(四)端侧 AI:碎片化场景的蓝海
端侧市场聚焦能效比与成本平衡,覆盖智能家居、工业终端等场景。国产芯片通过低功耗 SoC 集成 NPU,实现离线语音、人脸识别等功能。智能汽车(24%)、具身智能(14%)成为端侧核心应用方向,2025 年边缘 AI 芯片市场规模预计突破 150 亿元。
五、代码实操:国产芯片的 AI 模型部署
(一)华为昇腾 910B 的大模型训练示例
基于 MindSpore 框架在昇腾 910B 上部署 LLaMA-7B 模型:
(二)寒武纪 MLU370 的图像推理部署
基于 PyTorch 在寒武纪 MLU370 上实现 ResNet-50 推理:
六、挑战与展望:突围之路的机遇与挑战
(一)核心挑战
- 供应链安全:EDA 工具断供导致海光信息设计迭代受限,寒武纪 3nm 芯片研发停滞;先进制程依赖台积电,地缘政治风险加剧。
- 生态壁垒:软件工具链完善度不足,模型兼容性较 CUDA 生态存在差距,36% 客户对国产芯片性能存疑。
- 人才短缺:高端芯片设计人才缺口超 30 万,制约企业研发能力提升。
(二)未来展望
- 技术突破方向:51% 从业者认为应优先发展 GPU 集群架构,支持千亿参数模型训练;Chiplet 与先进封装将成为突破算力瓶颈的关键。
- 政策与资本加持:国家集成电路产业投资基金持续加码,《数字中国建设整体规划》提供专项支持,预计 2025 年国内 AI 芯片研发投入将突破 200 亿元。
- 生态协同发展:华为昇腾联合 2000 + 合作伙伴构建生态,寒武纪开放 Neuware 平台,软件生态短板将逐步补齐。
图 2:2030 年国产 AI 芯片发展路线图
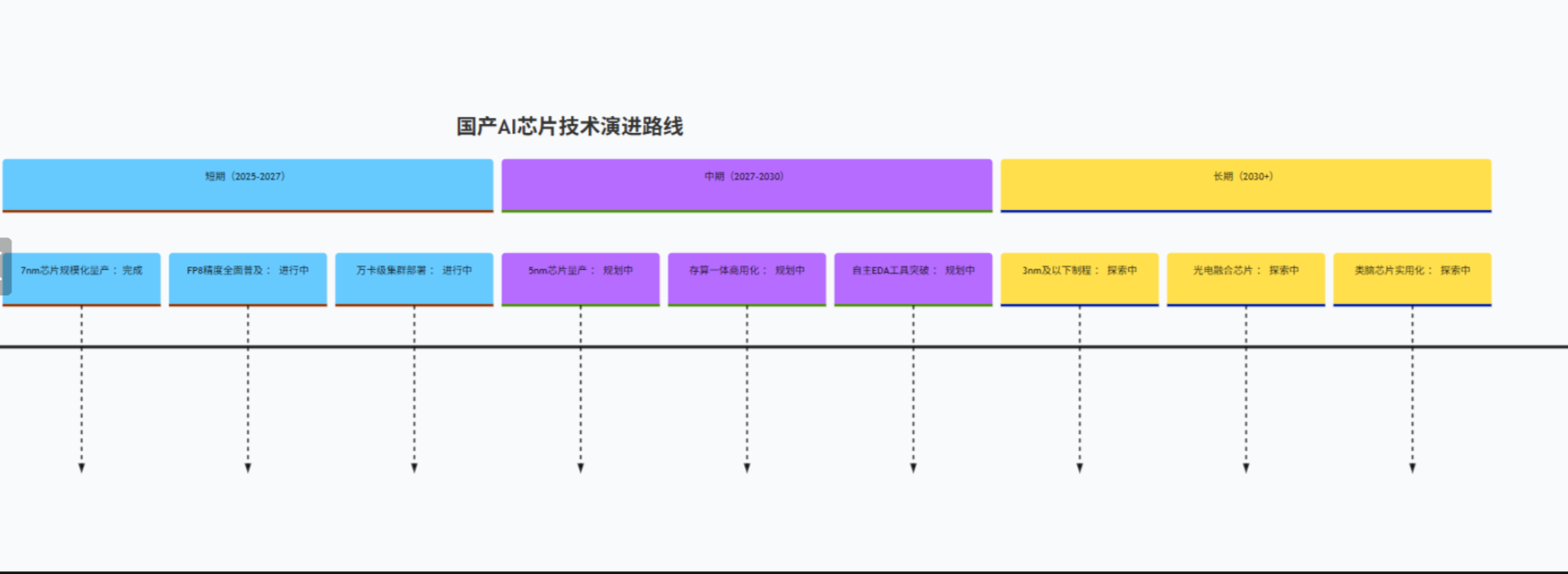
结语
2025 年的中国 AI 芯片产业正处于从 “技术跟跑” 向 “生态并跑” 的关键转型期。在政策驱动、需求牵引与技术创新的多重作用下,国产芯片已在智算、智驾等核心场景实现规模化突破,华为昇腾、寒武纪等企业构建了差异化竞争优势。尽管 EDA 工具、先进封装等瓶颈仍待突破,但随着 Chiplet、存算一体等颠覆性技术的成熟,以及软件生态的持续完善,中国 AI 芯片有望在 2030 年前实现核心技术的全面自主可控,成为全球算力竞争的关键力量。
